一种基于激光雷达和摄像头的物体识别方法和装置与流程
本发明涉及识别领域,具体涉及一种基于激光雷达和摄像头的物体识别方法和装置。
背景技术:
本发明提供一种基于激光雷达和摄像头的物体识别方法和装置,通过激光雷达结合摄像头来采集待识别物体的数据,训练成经验库,在实际使用时,通过激光雷达和摄像头的数据来识别出目标物体,本发明使用多个经验库结合的方法来增强识别效果。本发明可以用来识别交警、各种路标牌、路障、红绿灯等特定物体。相比于很多传统的识别方法,本发明能够至少一定程度上区分出交警海报照片和交警本人,区分出广告灯箱中的模特和道路上相同样子的行人等待识别内容。
技术实现要素:
一种基于激光雷达和摄像头的物体识别装置,其特征在于,包括:激光雷达,摄像头,软件系统。
所述激光雷达是通过发射激光来进行测距以获取点云数据的激光设备。
所述摄像头是固定在某个或某几个方向上的一个或多个摄像头。
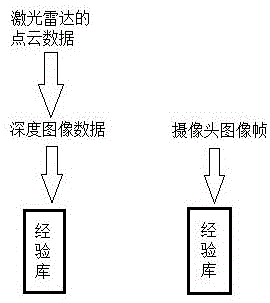
所述软件系统是根据激光雷达的点云数据和摄像头的图像帧来识别出物体的经验系统。
优选地,校准激光雷达和摄像头的朝向角度,使两者同步满足互相覆盖或部分覆盖,并满足一定相对成角,如果有必要则生成摄像头的配置信息(包含内容例如摄像头编号和角度偏移)。
优选地,当激光雷达或摄像头可能被移动或转向时,可以对激光雷达和摄像头分别添加陀螺仪(电子陀螺仪)来方便动态校准,此时软件系统可以根据两个陀螺仪的轴向读数来计算两个设备的实际成角偏移。
一种基于激光雷达和摄像头的物体识别方法,其特征在于,包括:
步骤一:使用激光雷达对特定待识别的物体进行扫描得到点云数据,并根据此点云数据生成深度图像信息,并同时根据摄像头采集图像帧信息。
步骤二:使用所述深度图像信息来生成卷积神经网络经验库或神经网络经验库。
步骤三:使用所述图像帧信息来生成卷积神经网络经验库或神经网络经验库。
步骤四:实际操作时软件系统根据用户端激光雷达当前获得的点云数据生成深度图像信息。
步骤五:对生成的深度图像信息进行图像检索,使用深度信息生成的经验库,来找到满足条件的图像信息。
步骤六:软件系统对摄像头捕捉到的图像帧信息在“步骤五”中找到的深度图像信息的满足匹配情况的位置的对应图像帧位置进行检索,再次确认满足匹配条件则认为是发现了目标物。
优选地,使用本发明装置对待识别物体进行采样时,可以对采样信息进行预处理以模拟较远的各种距离时的激光雷达获得的点云数据信息和摄像头捕捉到的图像帧信息,也可以进行多种距离的采样以省去部分对较远的各种距离的数据采样结果的模拟计算。
优选地,作为一种可选的实施方式,在将待识别物体的点云数据转化成深度图像时,可以根据待识别物体点云数据的值域范围来调整深度信息到深度图像的转换域值(范围值),也可以根据激光雷达的探测范围来设置深度信息到深度图像的转换域值(范围值)。
优选地,作为一种可选的实施方式,可以将采样得到的点云数据进行转化(例如每隔两个点取一个点)来模拟待识别物体在距离较远处的点云数据采样,以减少采样次数或增多样本数量,此时摄像头收集到的图像帧数据也要根据点云数据的转化情况来相应的缩放以模拟距离较远处的摄像头收集到的图像帧数据信息。
优选地,所述“步骤三”生成的经验库是区别于“步骤二”生成的经验库的另一个经验库,此经验库是根据摄像头收集到的待识别物体的图像帧信息建立的,而“步骤二”生成的经验库是根据点云数据转换成的深度图像信息建立的。
优选地,作为一种可选的实施方式,这里可以根据具体实现方案来变换生成深度图像信息的转换域值(范围值),例如使用激光雷达的探测范围来设置深度信息到深度图像的转换域值(范围值),或使用待识别物体点云数据的值域范围来调整深度信息到深度图像的转换域值(范围值)。
可选地,作为一种可选的实施方式,对生成的深度信息图像进行卷积神经网络的检索,返回匹配率满足某一阈值或达到判定规则的图像信息。
进一步地,所述返回匹配率满足某一阈值的图像信息中包含相对于深度图像左上角的位置偏移的矩形信息。
优选地,根据“步骤五”中通过搜索获得的深度图像中检索出的图像信息的矩形信息,来搜索摄像头捕捉到的图像帧信息的对应位置,使用图像信息经验库进行卷积神经网络的检索。
优选地,如果图像帧信息的图像搜索也满足匹配率超过某阈值或达到判定规则,则认为是找到了待识别物体。
优选地,所述深度图像信息可以是一个二维数据信息。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1基于深度图像信息生成的经验库和基于摄像头图像帧生成的经验库的概念示意图。
图2机械式激光雷达和摄像头的一种分布、朝向示意图,顶视图。
图3固态激光雷达和摄像头的一种分布、朝向示意图,顶视图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例1
步骤1:首先对激光雷达和摄像头进行设备校准,当使用的是机械式激光雷达的时候,假设摄像头的fov(fieldofview视域)是90度角,则可以在摄像头的图像中心的深度方向(通常是z轴或左手坐标系的z轴)与激光雷达坐标系在垂直水平面的轴向的0度角(轴向角度),90度角,180度角,270度角分别部署摄像头,并且将摄像头的id和相对角度信息储存到相关配置文件中,配置文件中也可以预存各个摄像头与激光雷达的偏移信息或相对坐标信息。
步骤2:使用激光雷达对特定待识别的物体进行扫描得到点云数据,并根据此点云数据生成深度图像信息,并同时根据0度角的摄像头采集图像帧信息,将这些图像信息用于经验库的数据依据。
进一步地,在生成深度图像信息时,需要根据激光雷达的测距范围(例如150米)和待识别物体的大小(例如1米半径的球)生成一个深度图像的转换域值(范围值),例如150米的测距范围,待识别物体的大小是1米半径的球(深度方向2米),则可以使用范围是10-15000(150除以15000的长度是厘米也就是以厘米长度为深度精度)的值来做为将深度数值转换成图像颜色数值(即一个二维数据)的范围值。
步骤3:使用“步骤1”中生成的数据进行处理,对于点云数据每隔两个点取一个点(或求这两个点的平均信息生成一个新点),然后对摄像头采集到的图像帧进行缩小(缩小到原来宽度和高度的一半),获得的新点云数据和图像帧数据作为新的采样数据,用来作为经验库的数据依据。
进一步地,可以对点云数据每隔n个点取一个点(或求这n个点的平均信息生成一个新点),然后对摄像头采集到的图像帧进行缩小(缩小到原来宽度和高度的n分之一),获得的新点云数据和图像帧数据作为新的采样数据,用来作为经验库数据依据。
步骤4:使用深度图像信息和摄像头的图像帧信息分别通过神经网络相关技术和\或卷积神经网络相关技术生成两个经验库。
步骤5:实际使用时,对激光雷达生成的点云数据生成四张深度图像信息。
进一步地,作为一种可选的实施方式,在确定每个深度图像信息的数值时,可以使用点云数据中每个点的距离值来除以之前提到的深度转换成图像颜色数值的范围值来得到结果值(类似于灰度图中的亮度)。
进一步地,作为一种可选的实施方式,此处可以将深度图像信息分成四份来分别检索,四份分别是垂直水平面的轴向角度(-45度到45度),(45度到135度),(135度到225度),(225度到315度)的范围。分成四份之后,还要对相连图像的接缝处各生成一张图片来进行一次检索,例如每个接缝处各取左右图像的一定角度(例如15度角)合成一张图片来检索,这里说的左右接缝就是将360度环形图像信息分开的四处地方的接缝左右图像。
进一步地,作为一种可选的实施方式,也可以只生成一张深度图像信息,此时只对唯一的左右接缝处进行单独的检索处理(此时接缝处可以在-45度角位置),即连接左右接缝处的图像生成一张图像来检索,以保证刚好被接缝处分开的物体也能够获得整体的检索,此处说的左右接缝处就是将360度环形图像信息分开的地方。
步骤6:对生成的深度图像信息进行图像检索,使用深度信息生成的经验库,来找到满足条件的图像检索信息,此图像检索信息包括相对于深度图像左上角的矩形信息。
步骤7:用“步骤6”中得到矩形信息找到摄像头图像帧中的对应位置(此处也可以按照图像大小的某个比例来将矩形放大得到的扩展后的搜索矩形,例如整体图像的64分之一的大小放大)进行图像帧经验库的检索,如果检索到满足匹配条件或匹配率超过阈值则认为是发现了目标物。
实施例2
当固态激光雷达和摄像头搭配时,尽量选择视角(或者说视场角度或fov)相同的设备。
步骤1:首先对激光雷达和摄像头进行设备校准,当使用的是固态激光雷达时,可以对一个固态激光雷达只部署一个摄像头,并且调整摄像头图像中心的深度方向(通常是z轴或左手坐标系的z轴)与固态激光雷达点云数据中心的坐标系在垂直水平面的轴向的0度方向的同方向。
步骤2:使用激光雷达对特定待识别的物体进行扫描得到点云数据,并根据此点云数据生成深度图像信息,并同时使用摄像头采集图像帧信息。
进一步地,在生成深度图像信息时,需要根据激光雷达的测距范围(例如90米)和待识别物体的大小(例如1米半径的球)生成一个深度图像的转换域值(范围值),例如90米的测距范围,待识别物体的大小是1米半径的球(深度方向2米),则可以使用范围是10-9000(90除以9000的长度是厘米也就是以厘米长度为深度精度)的值来做为深度转换成图像颜色数值的范围值。
步骤3:使用“步骤1”中生成的数据进行处理,对于点云数据每隔两个点取一个点(或求这两个点的平均信息生成一个新点),然后对摄像头采集到的图像帧进行缩小(缩小到原来宽度和高度的一半),获得的新点云数据和图像帧数据作为新的采样数据,用来作为经验库数据依据。
进一步地,可以对点云数据每隔n个点取一个点(或求这n个点的平均信息生成一个新点),然后对摄像头采集到的图像帧进行缩小(缩小到原来宽度和高度的n分之一),获得的新点云数据和图像帧数据作为新的采样数据,用来作为经验库数据依据。
步骤4:使用深度图像信息和摄像头的图像帧信息分别通过神经网络相关技术和\或卷积神经网络相关技术生成两个经验库。
步骤5:实际使用时,对激光雷达生成的点云数据生成深度图像信息(类似于3d视锥投影的过程)。
进一步地,作为一种可选的实施方式,在确定每个深度图像信息的数值时,可以使用点云数据中每个点的距离值来除以之前提到的深度转换成图像颜色数值的范围值来得到结果值(类似于灰度图中的亮度)。
进一步地,此种方案由于生成非360度环视的点云数据,所以不需要像“实例1”中那样对深度图像边缘的拼接等操作。
步骤6:对生成的深度图像信息进行图像检索,使用深度信息生成的经验库,来找到满足条件的图像信息,此图像信息包括相对于深度图像左上角的矩形信息。
步骤7:用“步骤6”中得到矩形信息找到摄像头图像帧中的对应位置(此处也可以按照图像大小的某个比例来将矩形放大得到的扩展后的搜索矩形,例如整体图像的64分之一的大小放大)进行图像帧经验库的检索,如果检索到满足匹配条件(例如匹配率超过阈值)则认为是发现了目标物。
以上是本发明的具体实施方式,但本发明的保护范围不应局限于此。任何熟悉本领域的技术人员在本发明所揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内,因此本发明的保护范围应以权利要求书所限定的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!