一种基于对话系统对用户问句提出反问的方法和装置与流程
本说明书实施例涉及对话系统技术领域,更具体地,涉及一种基于对话系统对用户问句提出反问的方法和装置。
背景技术:
最近,人们越来越关注如何用机器学习来更好地构建对话系统。对话系统通过计算机算法实现人与机器的交流,包括问答型、任务型和闲聊型三个类型。对于上述几种类型的对话系统,通常由用户提出问题,并由对话系统进行回复。在一些情况中,用户提出的问题往往是模糊的,对话系统很难直接从标问库中找到匹配的标准问题、并基于该标准问题的答案进行回复。在该情况中,需要由对话系统对用户提出反问,以明确用户的问题,从而便于找到匹配的标准问题。在现有技术中,用于对用户问句提出反问的模型通常采用监督学习模型,如rnn模型等,为了训练该反问模型,通常需要对多个用户输入问题进行聚类,并基于该聚类结果对用户的输入问题进行标注,以将用户问句进行结构化表示,如将用户的问题标注为几个部分:场景,意图,关键信息等,从而基于该标注样本进行对所述反问模型的训练。
因此,需要一种更有效的基于对话系统对用户问句提出反问的方案。
技术实现要素:
本说明书实施例旨在提供一种更有效的基于对话系统对用户问句提出反问的方案,以解决现有技术中的不足。
为实现上述目的,本说明书一个方面提供一种基于对话系统对用户问句提出反问的方法,所述对话系统中预设有与n个标准问题对应的m个反问模块,其中m≥n,每个反问模块中包括从相应的标准问题拆分的第一子句和第二子句,所述方法包括:
获取第一用户的第一问句;
对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配;
在所述第一问句与该反问模块中的第一子句的匹配、且所述第一问句与该反问模块中的第二子句不匹配的情况中,基于该反问模块中的第二子句获取针对所述第一问句的反问句,以基于所述m个反问模块获取针对所述第一问句的多个反问句。
在一个实施例中,每个所述反问模块中包括分别与业务和用户意图相关的两个子句。
在一个实施例中,每个所述反问模块中还预设有与所述第二子句对应的第二反问句,其中,基于该反问模块中的第二子句获取针对所述第一问句的反问句包括,从该反问模块中获取所述第二反问句作为针对所述第一问句的反问句。
在一个实施例中,每个所述反问模块中还预设有与所述第一子句对应的第一组关键词和与所述第二子句对应的第二组关键词,其中,分别确定所述第一问句与所述第一子句和第二子句是否匹配包括,分别确定所述第一问句与所述第一组关键词和所述第二组关键词是否匹配。
在一个实施例中,所述n个标准问题为与第一领域对应的标准问题,所述方法还包括,在获取第一用户的第一问句之后,确定所述第一问句所属的领域,其中,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配包括,在确定所述第一问句与所述第一领域对应的情况中,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配。
在一个实施例中,所述对话系统中包括强化学习模型,所述方法还包括,在基于所述m个反问模块获取针对所述第一问句的多个反问句之后,将所述多个反问句输入所述强化学习模型;通过所述强化学习模型基于所述多个反问句执行第一回合的第t次循环,其中,所述第t次循环包括以下步骤:
获取所述第一回合的第t个状态,所述第t个状态包括所述第一问句、由强化学习模型在所述第一回合中已输出的针对所述第一问句的反问句;
将所述第t个状态输入所述强化学习模型;
通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户。
在一个实施例中,所述第一回合包括t次循环,所述方法还包括,在通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户之后,获取第t~t次循环的每次循环中第一用户相对于所述强化学习模型的输出的反馈。
在一个实施例中,所述方法还包括,在获取第t~t次循环的每次循环中的第一用户的反馈之后,基于所述第t个状态、所述预定数目的反问句、以及第t~t次循环的每次循环中的第一用户的反馈,训练所述强化学习模型。
在一个实施例中,所述方法还包括,
在获取第t~t次循环的每次循环中的第一用户的反馈之后,在基于所述t次循环的每次循环中的第一用户的反馈,确定所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问句的情况中,接收所述第一用户的意图;
从所述n个标准问题中获取与所述第一用户的意图对应的第一标准问题;
基于所述第一用户的意图,配置与所述第一标准问题对应的第一反问模块;
在所述对话系统中添加所述第一反问模块。
本说明书另一方面提供一种基于对话系统对用户问句提出反问的装置,所述对话系统中预设有与n个标准问题对应的m个反问模块,其中m≥n,每个反问模块中包括从相应的标准问题拆分的第一子句和第二子句,所述装置包括:
第一获取单元,配置为,获取第一用户的第一问句;
第一确定单元,配置为,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配;
第二获取单元,配置为,在所述第一问句与该反问模块中的第一子句的匹配、且所述第一问句与该反问模块中的第二子句不匹配的情况中,基于该反问模块中的第二子句获取针对所述第一问句的反问句,以基于所述m个反问模块获取针对所述第一问句的多个反问句。
在一个实施例中,每个所述反问模块中还预设有与所述第二子句对应的第二反问句,其中,所述第二获取单元还配置为,从该反问模块中获取所述第二反问句作为针对所述第一问句的反问句。
在一个实施例中,每个所述反问模块中还预设有与所述第一子句对应的第一组关键词和与所述第二子句对应的第二组关键词,其中,所述第一确定单元还配置为,分别确定所述第一问句与所述第一组关键词和所述第二组关键词是否匹配。
在一个实施例中,所述n个标准问题为与第一领域对应的标准问题,所述装置还包括,第二确定单元,配置为,在获取第一用户的第一问句之后,确定所述第一问句所属的领域,其中,所述第一确定单元还配置为,在确定所述第一问句与所述第一领域对应的情况中,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配。
在一个实施例中,所所述对话系统中包括强化学习模型,所述装置还包括,输入单元,配置为,在基于所述m个反问模块获取针对所述第一问句的多个反问句之后,将所述多个反问句输入所述强化学习模型;执行单元,配置为,通过所述强化学习模型基于所述多个反问句执行第一回合中的第t次循环,其中,所述执行单元包括:
获取子单元,配置为,获取所述第一回合的第t个状态,所述第t个状态包括所述第一问句、由强化学习模型在所述第一回合中已输出的针对所述第一问句的反问句;
输入子单元,配置为,将所述第t个状态输入所述强化学习模型;
确定子单元,配置为,通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户。
在一个实施例中,所述第一回合包括t次循环,所述装置还包括,第三获取单元,配置为,在通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户之后,获取第t~t次循环的每次循环中第一用户相对于所述强化学习模型的输出的反馈。
在一个实施例中,所述装置还包括,训练单元,配置为,在获取第t~t次循环的每次循环中的第一用户的反馈之后,基于所述第t个状态、所述预定数目的反问句、以及第t~t次循环的每次循环中的第一用户的反馈,训练所述强化学习模型。
在一个实施例中,所述装置还包括,
接收单元,配置为,在获取第t~t次循环的每次循环中的第一用户的反馈之后,在基于所述t次循环的每次循环中的第一用户的反馈,确定所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问句的情况中,接收所述第一用户的意图;
第四获取单元,配置为,从所述n个标准问题中获取与所述第一用户的意图对应的第一标准问题;
配置单元,配置为,基于所述第一用户的意图,配置与所述第一标准问题对应的第一反问模块;
添加单元,配置为,在所述对话系统中添加所述第一反问模块。
本说明书另一方面提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述任一项方法。
本说明书另一方面提供一种计算设备,包括存储器和处理器,其特征在于,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述任一项方法。
通过根据本说明书实施例的对话系统方案,只需要基于标准问题获取反问模块,而不需要通过大量的人力进行对训练样本的标注,而在基于标准问题获取反问模块中,只需要关注本标准问题,而不需要进行聚类、结构化等复杂操作,给相关的技术人员带来很大的便利性。另外,通过本说明书实施例中提出的反问模块框架,可在该框架中对反问模块随时扩展,并且即插即用,给相关的业务人员带来很大的便利性。另外,通过训练基于该反问模块框架的强化学习模型,从而可基于用户的反馈在线更新模型。
附图说明
通过结合附图描述本说明书实施例,可以使得本说明书实施例更加清楚:
图1示出根据本说明书实施例的对话系统示意图;
图2示出根据本说明书实施例的一种基于对话系统对用户问句提出反问的方法流程图;
图3示出根据本说明书实施例的反问模块的示意图;
图4示出通过强化学习模型进行挑选的方法流程图;
图5示出通过根据本说明书实施例的通过强化学习模型输出反问句的示意过程;
图6示出了在对话系统中增加反问模块的方法;
图7示出根据本说明书实施例的一种基于对话系统对用户问句提出反问的装置700。
具体实施方式
下面将结合附图描述本说明书实施例。
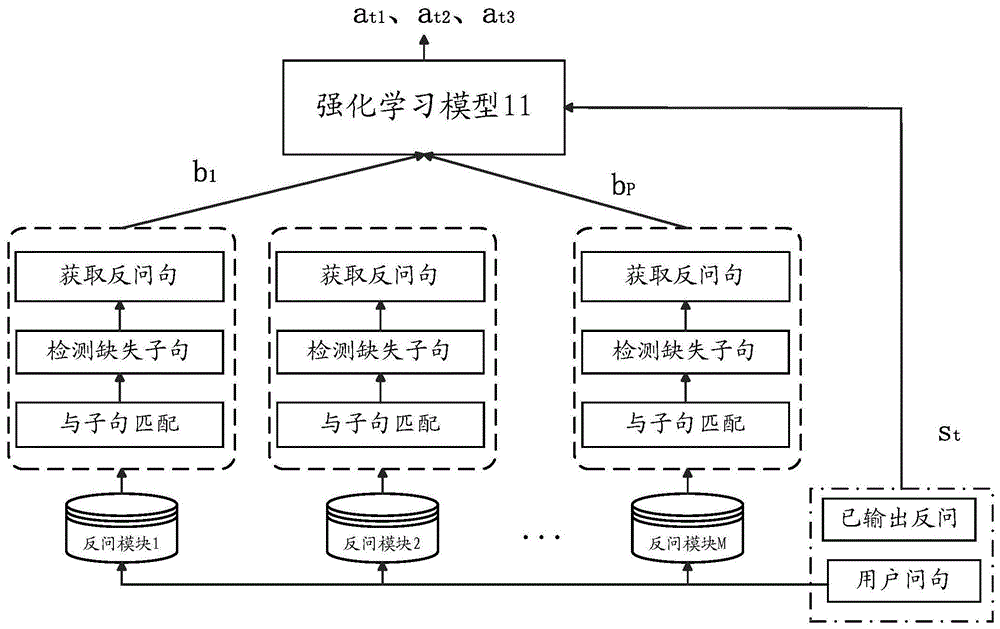
图1示出根据本说明书实施例的对话系统示意图。如图1中所示,所述对话系统中包括强化学习模型11。所述对话系统中预设了与n个标准问题对应的m个反问模块:反问模块1,反问模块2,…,反问模块m,每个反问模块中包括第一部分和第二部分两部分,其中,第一部分包括从相应的标准问题拆分的业务子句,第二部分包括从相应的标准问题拆分的意图子句。当用户向该对话系统输入其询问问题之后,对话系统中基于每个反问模块中的业务子句和意图子句执行图中所示的三个步骤:与子句匹配,检测缺失子句,获取反问句。在针对m个反问模块获取多个(例如p个)反问句之后,将该多个反问句作为多个候选动作b1、b2、…、bp输入强化学习模型11,并将所述用户询问问句和模型在本回合中已输出的反问作为状态st输入所述强化学习模型11,从而所述模型基于状态st从所述多个反问句中确定预定数目的反问句(at1、at2、at3),以用于输出给用户。在进行该输出之后,可获取用户的反馈,例如,所述用户的反馈为点击或不点击由所述模型输出的反问句。在用户进行所述反馈之后,用户可提出新的问句,从而所述对话系统可进行下一轮的反问推送。在该下一轮的推送中,可将用户询问问句和在上一轮中已经推送给用户的反问作为与该下一轮推送对应的状态输入所述强化学习模型,以输出用于向该用户推送的反问。
可基于用户对系统提出的反问的反馈进行对所述强化学习模型的优化,从而使得所述强化学习模型的预测更加准确。
如果在经过预定轮数的多轮反问推送之后,从用户的反馈获知仍没有符合用户意图的反问,则可以直接获取用户的意图,该意图例如由用户直接输入,或者在该对话系统指示用户输入意图之后由用户输入,从而,基于用户输入的意图,可对相应的标准问题重新进行拆分,以生成新的反问模块并添加到对话系统中。
可以理解,上文中参考图1的描述仅是示意性的,而不是限定性的,下面将详细描述上述对用户问句提出反问的方法。
图2示出根据本说明书实施例的一种基于对话系统对用户问句提出反问的方法流程图,所述对话系统中预设有与n个标准问题对应的m个反问模块,其中m≥n,每个反问模块中包括从相应的标准问题拆分的第一子句和第二子句,所述方法包括:
步骤s202,获取第一用户的第一问句;
步骤s204,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配;
步骤s206,在所述第一问句与该反问模块中的第一子句的匹配、且所述第一问句与该反问模块中的第二子句不匹配的情况中,基于该反问模块中的第二子句获取针对所述第一问句的反问句,以基于所述m个反问模块获取针对所述第一问句的多个反问句。
在现有技术中,通常在对话系统中都预设有多个标准问题,在本说明书实施例中,可对标准问题进行拆分以获取与该标准问题对应的第一子句和第二子句,例如,可基于标准问题中的业务和诉求分别获取与业务对应的第一子句和与用户意图(诉求)对应的第二子句。例如对于标准问题“开通花呗收钱需要审核多久”,可从其获取“开通花呗收钱”和“审核多久”两个子句,其中,“开通花呗收钱”与业务相关,“审核多久”与用户提问的意图(诉求)相关。可以理解,对标问的拆分不限于只拆分成一种形式,另外,对标问的拆分不限于基于业务和用户意图进行,例如,对于标问“花呗自动还款扣款顺序”,可以获取子句“花呗”和“自动还款”,也可以获取子句“花呗自动还款”和“扣款顺序”等等,例如,可基于用户的提问方式进行相应的对标问的拆分。从而,可基于n个标准问题获取m个反问模块,其中m≥n。
图3示出根据本说明书实施例的反问模块的示意图。如图3所示,该反问模块包括模块标识,例如图中的“11384”,该模块标识例如可以与标准问题编号相对应,以表示该反问模块是与相应的标准问题相对应的。另外,该反问模块中包括第一子句单元31和第二子句单元32,该第一子句单元31例如包括:与业务对应的子句1:“开通花呗收钱”;与该子句1对应的关键词:*(开通|申请)*花呗收钱*;以及与该子句对应的反问句1:“开通花呗收钱?”。类似地,第二子句单元32例如包括:与业务对应的子句2:“审核多久”;与该子句对应的关键词:*审核*(多久|多长时间)*;以及与该子句对应的反问句2:“需要审核多久?”。其中,对于反问模块中的关键词和反问句的使用将在下文详细描述。
首先,步骤s202,获取第一用户的第一问句。
所述对话系统通常包括提问界面,第一用户可通过在该提问界面通文字或语音等形式向对话系统提出问题。例如,所述第一问句为“需要审核多久”,该问题对于对话系统来说缺乏相关的业务,因此属于模糊问题,从而,为了明确该问题对应的业务,对话系统可通过图2所示的方法提出反问,以使得该问题变得更加清楚。
步骤s204,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配。
例如,对于图3所示的标识为“11384”的反问模块,分别确定第一用户的第一问句“需要审核多久”与第一子句单元中的子句1“开通花呗收钱”是否匹配,以及“需要审核多久”与第二子句单元中的子句2“审核多久”是否匹配。
在一个实施例中,如图3所示的反问模块中所示,在该反问模块的每个子句单元中预设有与相应子句对应的一组关键词,例如,如上文所述,与其中子句1对应的一组关键词包括,*(开通|申请)*花呗收钱*,与其中子句2对应的一组关键词包括,*审核*(多久|多长时间)*。从而,对于每个子句,通过确定第一问句是否包括与该子句对应的一组关键词中的每两个*之间的关键词,而确定该第一问句与该子句是否匹配,其中“|”表示其两边的关键词可任选一个。例如,对于子句2,通过确定第一问句中是否包括关键词集合{审核、多久}、或者关键词集合{审核、多长时间},从而确定该第一问句与子句2是否匹配。显然,第一问句“需要审核多久”中包括关键词集合{审核、多久},从而可确定第一问句与子句2相匹配。可通过同样地方式确定,第一问句与该模块中的子句1不匹配。
可以理解,用于确定第一问句与反问模块中的子句是否匹配不限于通过上述关键词匹配的方式进行,在一个实施例中,可通过各个词嵌入向量获取第一问句的嵌入向量、以及各个子句的嵌入向量,从而可通过比较第一问句的嵌入向量与各个子句的嵌入向量的相似性,从而确定第一问句与各个子句是否匹配。在一个实施例中,可基于各个反问模块获取训练样本训练相应的匹配模型,从而,通过将该第一问句输入与该反问模块对应的匹配模型,可直接输出第一问句与该反问模块中的两个子句是否匹配。
在步骤s206,在所述第一问句与该反问模块中的第一子句的匹配、且所述第一问句与该反问模块中的第二子句不匹配的情况中,基于该反问模块中的第二子句获取针对所述第一问句的反问句,以基于所述m个反问模块获取针对所述第一问句的多个反问句。
例如如上文所述,第一问句与图3所示模块11384中的子句2匹配,与其中的子句1不匹配,这里假设第一子句为所述子句2,第二子句为所述子句1,则基于子句1获取针对所述第一问句的反问句。在一个实施例中,可将子句1本身作为针对所述第一问句的反问句,例如,针对所述第一问句,可向第一用户提出反问“开通花呗收钱?”。在一个实施例中,可将子句1对应的标准问题作为针对所述第一问句的反问句,例如,针对所述第一问句,可向第一用户提出反问“开通花呗收钱需要审核多久?”。在一个实施例中,如图3中所示,在反问模块的每个子句单元中可预设相应的反问句,例如,在第一子句单元中,可预设相应的反问句“开通花呗收钱?”,从而,在确定第一问句与其中的子句2匹配、与子句1不匹配之后,可直接从与子句1对应的第一子句单元中获取相应的反问句“开通花呗收钱?”,以向第一用户提出反问。
在一个实施例中,在对话系统中对多个标准问题按领域进行分类,从而,相应地,对各个问题相应的反问模块按领域进行分类。例如,所述n个标准问题为与花呗领域对应的标准问题,即,所述m个反问模块为与花呗领域对应的反问模块。从而,在获取第一用户的第一问句之后,确定该第一问句所属的领域。例如,可通过对各个领域设置各自的一组关键词,并通过对第一问句进行与各个领域的关键词匹配,从而确定第一问句的领域。例如,如果第一问句为“开通花呗收钱”,从而通过关键词匹配,可确定第一问句属于花呗领域。在确定第一问句属于花呗领域之后,从而可基于与花呗领域对应的m个反问模块进行上述步骤s204和s206。
在一个实施例中,所述n个标准问题为对话系统中包括的各个领域的标准问题,从而,所述m个反问模块与各个领域对应。如上文所述,如果第一问句为“需要审核多久”,对于该问句,通过关键词匹配,并不能确定其对应的领域,从而需要基于各个领域的m个反问模块进行上述步骤s204和s206。
可以理解,基于对话系统中的m个反问模块可获取针对所述第一问句的多个反问句。例如,针对所述第一问句“需要审核多久”,通过上述步骤还可以从其它反问模块获取以下反问句:“实名认证?”、“大病保险理赔?”、“开通借呗?”等等。在该情况中,为了从该多个反问句中挑选出预定数目(例如3个)反问句输出给第一用户,可通过图1中所示的强化学习模型进行所述挑选。
图4示出通过强化学习模型进行挑选的方法流程图,所述强化学习模型中预先从所述对话系统获取了通过图2所示方法获取的多个反问句,所述方法为基于强化学习模型的一个回合中的第t次循环,所述方法包括:
步骤s402,获取该回合的第t个状态,所述第t个状态包括所述第一问句、由强化学习模型在本回合中已输出的针对所述第一问句的反问句;
步骤s404,将所述第t个状态输入所述强化学习模型;
步骤s406,通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户。
所述基于强化学习模型的一个回合(episode)例如包括t次循环,则t可以为1到t中的任一自然数,所述一个回合为用户与对话系统进行的连续多轮对话,其中每次循环对应于该强化学习模型的一次输出,该t次循环中的连续两次循环可对应于同一个问句,例如由强化学习模型针对用户的同一个问句提出多轮反问,或者,该t次循环中的连续两次循环可对应于不同的问句,该不同的问句在主题上是相关的,体现了用户的一致的意图。在第一用户输入第一问句之后,该对话系统在通过图2所示方法获取所述多个反问句之后,可将该多个反问句输入该强化学习模型,以针对该第一问句进行反问句推送,以明确第一用户的意图。例如,参考图1,基于所述第一问句、图中的m个反问模块,通过图2所示方法可获取p个针对所述第一问句的反问句b1、b2、…、bp,可将所述多个反问句输入所述强化学习模型,以作为用于挑选反问句的候选反问句。图4所示方法即为多次推送中的一次推送(即该回合中的一次循环)。该回合例如在第一用户指示对话结束之后结束,或者在第一用户在预定时段中没有回复的情况下结束。
在步骤s402,获取该回合的第t个状态,所述第t个状态包括所述第一问句、由强化学习模型在本回合中已输出的针对所述第一问句的反问句。
参考图1中所示,在强化学习模型的该回合的该第t次循环中用于输入模型的所述第t个状态st包括第一问句、以及由强化学习模型在本回合中已输出的反问句两项。例如,在该回合的第1次循环中,强化学习模型还未进行输出,因此,s1中仅包括用户提出的第1个问句,在第2次循环中,s2中包括用户提出的第2个问句、以及该强化学习模型在第1次循环中已向用户输出的预定数目(例如1个、或者多个)的反问句。
图5示出通过根据本说明书实施例的通过强化学习模型输出反问句的示意过程。图5中示意示出一个回合中的第1~3次循环,可以理解,该3次循环仅是示意性的,所述回合不限于包括3次循环。如图5中所示,在该回合的第1次循环中,对应的状态s1中仅包括用户提出的第1个问句(图中以白色框示出),例如,用户向对话系统输入“淘宝”,针对该问句,对话系统例如输出三个反问句a11(要开通淘宝么?)、a12(如何关闭淘宝?)和a13(什么是淘宝)。在第2次循环中,用户例如又提出问题“想问下怎么在淘宝上卖东西?”,从而对应的状态s2中除了用户提出的第2个问句之外,还包括模型在本回合中已输出的反问句(图中以灰色框所示),这里,模型在本回合中已输出的反问句包括所述a11、a12和a13。在第3次循环中,对应的状态s3中类似地包括用户提出的第3个问句和模型已输出的反问句(图中以灰色框所示),这里,模型在本回合中已输出的反问句包括a11、a12、a13、a21、a22和a23。在一个实施例中,在强化学习模型的该回合的该第t次循环中用于输入模型的所述第t个状态st包括第一问句、以及由强化学习模型在本回合第t-1次循环中已输出的反问句。例如,在图5所示的第3次循环中,对应的状态s3的灰色框中可仅包括a21、a22和a23。
在步骤s404,将所述第t个状态输入所述强化学习模型。在步骤s406,通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户。
所述强化学习模型例如为基于策略梯度算法的模型,在该情况中,模型包括关于状态s和动作a的策略函数π(a|s,θ),其中,θ为该强化学习模型的模型参数,π(a|s,θ)为在状态s下采用动作a的概率。在本说明书实施例中,通过图2所示方法可获取多个针对所述第一问句的反问句b1、b2、…、bp,作为用于确定输出动作的多个候选动作。对于所述第t次循环,可通过该模型的策略函数基于状态st和多个候选动作bi分别计算各个bi的概率,从而可将概率最大的预定数目的(例如3个)候选动作确定为模型输出动作at1、at2、at3,并将其输出给所述第一用户。如图5中所示,在该回合中,在第1次循环中,由所述模型输出三个反问句a11、a12、a13,在第2次循环中,由所述模型输出三个反问句a21、a22、a23,在第3次循环中,由所述模型输出三个反问句a31、a32、a33。在每次由模型输出反问句之后,都将该输出的反问句输出给(显示给)所述第一用户,从而可基于用户的反馈获取相应的回报值,例如,在第1次循环中,基于第一用户的反馈,可获取与各个输出动作分别对应的回报值r11、r12、r13。例如,所述第一用户针对反问句a11没有进行点击,则与a11对应的回报值为0,所述第一用户针对反问句a32进行点击,则与a32对应的回报值r32为1。
可以理解,所述强化学习模型不限于使用策略梯度算法,而可以使用其它算法,如q学习算法、行为-评判算法(actor-critic)等,在此不一一详述。
如上文所述,在模型的一个回合结束之后,可通过该回合中的输入输出数据及反馈数据训练模型。例如,如上文所述,第一用户在第3次循环中点击了反问句a32,在第1次和第2次循环中未对模型输出的任何反问句进行点击,从而与反问句a32对应的回报值r32等于1,与a11、a12、a13、a21、a22、a23、a31、a33对应的回报值都为零。则可通过如下公式(1)进行模型参数更新:
其中,
从而,通过如公式(2)所示基于r32计算
类似地,假设第t个状态为图5中的状态s3,对于该第3次循环中的动作a32,可通过如下公式(3)计算公式(1)中的
从而,通过如公式(2)所示基于r32计算
针对图5所示的强化学习模型的一个回合中的3次循环,如果第一用户未对该回合中由模型输出的任一反问句进行点击,即,第一用户针对由模型输出的每个反问句的回报值都为0,在该情况中,基于公式(1),该次回合的数据将无法用于训练模型。
针对上述情况,图6示出了在对话系统中增加反问模块的方法,包括:
步骤s602,在基于所述t次循环的每次循环中的第一用户的反馈,确定所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问句的情况中,接收所述第一用户的意图;
步骤s604,从所述n个标准问题中获取与所述第一用户的意图对应的第一标准问题;
步骤s606,基于所述第一用户的意图,配置与所述第一标准问题对应的第一反问模块;
步骤s608,在所述对话系统中添加所述第一反问模块。
首先,在步骤s602,在基于所述t次循环的每次循环中的第一用户的反馈,确定所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问句的情况中,接收所述第一用户的意图。
例如,如上文所述,当第一用户对于所述强化学习模型的每次循环的输出都未进行点击的情况下,也就是说,所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问,此时,第一用户可能主动向对话系统输入其意图,从而该对话系统可接收到该第一用户的意图,或者,可由对话系统通过询问第一用户以使得该第一用户向对话系统输入其意图,或者,可事后由业务人员进行人工判断以向对话系统输入所述第一用户的意图。
例如,第一用户向对话系统输入的问句为“花呗自动还款”,对话系统基于与标准问题“花呗自动还款扣款顺序”对应的已有的反问模块(花呗、自动还款),不能获取与“扣款顺序”相关的反问句,从而不能由所述强化学习模型输出与“扣款顺序”相关的反问句。从而,第一用户对于模型输出的任一反问句可能都未进行点击。在该情况中,可从外部(第一用户或业务人员)接收该第一用户输入“花呗自动还款”的意图为“扣款顺序”。
在步骤s604,从所述n个标准问题中获取与所述第一问句和意图的结合对应的第一标准问题。
例如,基于“扣款顺序”(用户意图)的结合,例如通过将该“扣款顺序”与每个标准问题对应的一组关键词进行匹配,从而,可从所述n个标准问题中获取相应的第一标准问题“花呗自动还款扣款顺序”。
步骤s606,基于所述第一用户的意图,配置与所述第一标准问题对应的第一反问模块。
例如,对于上述第一标准问题“花呗自动还款扣款顺序”,基于所述第一用户的意图,可获取与该第一标准问题对应的两个子句“花呗自动还款”和“扣款顺序”,从而可配置与第一标准问题对应的第一反问模块,使得,该模块中的第一子句单元与“花呗自动还款”对应,该模块中的第二子句单元与“扣款顺序”对应。
在步骤s608,在所述对话系统中添加所述第一反问模块。
也就是说,如果所述对话系统中初始包括上述m个反问模块,通过添加该第一反问模块,从而使得该对话系统共包括m+1个反问模块。在添加了该第一反问模块之后,在继续通过所述对话系统用于获取针对用户问句的反问时,可立即使用该m+1个反问模块进行图2和图4所示的方法,也就是说,根据本说明书实施例的对话系统中的反问模块架构可随着用户的反馈容易地扩展,并且可在扩展之后即插即用。
可以理解,对所述反问模块的扩展不限于通过上述方式进行扩展,例如,当业务领域增加时,或者当用户的热点话题发生变化时,可能都导致对话系统中标准问题的增加,在该情况下,可基于增加的标准问题获取相应的增加的反问模块,从而对反问模块框架进行扩展。
图7示出根据本说明书实施例的一种基于对话系统对用户问句提出反问的装置700,所述对话系统中预设有与n个标准问题对应的m个反问模块,其中m≥n,每个反问模块中包括从相应的标准问题拆分的第一子句和第二子句,所述装置包括:
第一获取单元701,配置为,获取第一用户的第一问句;
第一确定单元702,配置为,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配;
第二获取单元703,配置为,在所述第一问句与该反问模块中的第一子句的匹配、且所述第一问句与该反问模块中的第二子句不匹配的情况中,基于该反问模块中的第二子句获取针对所述第一问句的反问句,以基于所述m个反问模块获取针对所述第一问句的多个反问句。
在一个实施例中,每个所述反问模块中还预设有与所述第一子句对应的第一反问句和与所述第二子句对应的第二反问句,其中,所述第二获取单元703还配置为,从该反问模块中获取所述第二反问句作为针对所述第一问句的反问句。
在一个实施例中,每个所述反问模块中还预设有与所述第一子句对应的第一组关键词和与所述第二子句对应的第二组关键词,其中,所述第一确定单元702还配置为,分别确定所述第一问句与所述第一组关键词和所述第二组关键词是否匹配。
在一个实施例中,所述n个标准问题为与第一领域对应的标准问题,所述装置还包括,第二确定单元704,配置为,在获取第一用户的第一问句之后,确定所述第一问句所属的领域,其中,所述第一确定单元还配置为,在确定所述第一问句与所述第一领域对应的情况中,对于所述m个反问模块中的每个反问模块,分别确定所述第一问句与其中的所述第一子句和第二子句是否匹配。
在一个实施例中,所述对话系统中包括强化学习模型,所述装置还包括,输入单元705,配置为,在基于所述m个反问模块获取针对所述第一问句的多个反问句之后,将所述多个反问句输入所述强化学习模型;执行单元706,配置为,通过所述强化学习模型基于所述多个反问句执行第一回合中的第t次循环,其中,所述执行单元706包括:
获取子单元7061,配置为,获取所述第一回合的第t个状态,所述第t个状态包括所述第一问句、由强化学习模型在所述第一回合中已输出的针对所述第一问句的反问句;
输入子单元7062,配置为,将所述第t个状态输入所述强化学习模型;
确定子单元7063,配置为,通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户。
在一个实施例中,所述第一回合共包括t个循环模块,所述装置还包括,
第三获取单元707,配置为,在通过所述强化学习模型从所述多个反问句中确定针对所述第一问句的预定数目的反问句,以输出给所述第一用户之后,获取第t~t次循环的每次循环中第一用户相对于所述强化学习模型的输出的反馈。
在一个实施例中,所述装置还包括,训练单元708,配置为,在获取第t~t次循环的每次循环中的第一用户的反馈之后,基于所述第t个状态、所述预定数目的反问句、以及第t~t次循环的每次循环中的第一用户的反馈,训练所述强化学习模型。
在一个实施例中,所述装置还包括,
接收单元709,配置为,在获取第t~t次循环的每次循环中的第一用户的反馈之后,在基于所述t次循环的每次循环中的第一用户的反馈,确定所述强化学习模型的t次输出都不包括符合所述第一用户的意图的反问句的情况中,接收所述第一用户的意图;
第四获取单元710,配置为,从所述n个标准问题中获取与所述第一用户的意图对应的第一标准问题;
配置单元711,配置为,基于所述第一用户的意图,配置与所述第一标准问题对应的第一反问模块;
添加单元712,配置为,在所述对话系统中添加所述第一反问模块。
本说明书另一方面提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述任一项方法。
本说明书另一方面提供一种计算设备,包括存储器和处理器,其特征在于,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述任一项方法。
通过根据本说明书实施例的对话系统方案,只需要基于标准问题获取反问模块,而不需要通过大量的人力进行对训练样本的标注,而在基于标准问题获取反问模块中,只需要关注本标准问题,而不需要进行聚类、结构化等复杂操作,给相关的技术人员带来很大的便利性。另外,通过本说明书实施例中提出的反问模块框架,可在该框架中对反问模块随时扩展,并且即插即用,给相关的业务人员带来很大的便利性。另外,通过训练基于该反问模块框架的强化学习模型,从而可基于用户的反馈在线更新模型。
需要理解,本文中的“第一”,“第二”等描述,仅仅为了描述的简单而对相似概念进行区分,并不具有其他限定作用。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
上述对本说明书特定实施例进行了描述。其它实施例在所附权利要求书的范围内。在一些情况下,在权利要求书中记载的动作或步骤可以按照不同于实施例中的顺序来执行并且仍然可以实现期望的结果。另外,在附图中描绘的过程不一定要求示出的特定顺序或者连续顺序才能实现期望的结果。在某些实施方式中,多任务处理和并行处理也是可以的或者可能是有利的。
本领域普通技术人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执轨道,取决于技术方案的特定应用和设计约束条件。本领域普通技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执轨道的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!