一种基于深度判别特征的网络流量分类系统及方法与流程
本发明涉及一种基于深度判别特征的网络流量分类系统及方法,属于计算机网络,网络流量分类技术领域。
背景技术:
网络流量分类作为增强网络可控性的基础技术之一,在网络监管和网络安全中发挥着至关重要的作用。例如,网络服务提供商通过对网络流量进行分类来分析网络流量分布,进而进行更好的qos(qualityofservice)控制;企业网络通过流量识别技术来控制应用访问;一些国家政府对非法或敏感流量的合法拦截需要首先了解通过其网络传输的内容类型。在网络安全方面,网络流量分类是入侵检测系统的核心部分,其可发现网络中的异常流量,以便于及时采取有效的防御措施。鉴于以上各种需求,实现准确高效的流量分类与识别具有极其重要的意义。
当前,网络流量分类方法主要可以被归纳为四个类别:基于端口的方法、基于包负载内容的方法、基于统计学习的方法和基于深度学习的方法。
基于端口的方法通过检查网络数据包的传输层端口号,然后根据互联网数字分配机构(iana)定制的端口号与应用的对应关系来对网络流量进行分类。虽然基于端口的分类方法简单、快速,但是随着端口混淆、网络地址转换(nat)、端口转发、协议嵌入和随机端口分配等技术的出现,使得其分类性能显著下降。
考虑到基于端口的分类方法的不足,相关研究人员提出了基于包负载内容的分类方法。该类方法以深度包检测(dpi)技术为代表,其通过分析数据包应用层载荷内容来对已知的应用签名进行匹配。dpi技术具有识别准确率高的优点,但是与此同时其面临着以下不足:(1)当加密技术被应用于载荷数据时,dpi技术将失去作用;(2)dpi技术无法识别未知特征值,当网络应用的特征值发生变化时,相应的特征值库必须及时更新;(3)由于需要对每个数据包的负载内容进行检查,dpi技术的时间和空间开销巨大;(4)对数据包负载内容进行检查面临着隐私保护的问题。
在过去的十多年中,人们对有关机器学习技术在流量分类方面的应用进行了广泛研究。其中,机器学习算法与流统计特征相结合的方法受到了极大的关注。这种方法假定每个应用的流统计特性(例如:最大包长度、最小包长度、包到达时间间隔和流持续时间)是不同的,因此可以通过使用各种机器学习算法训练分类器来对网络流量进行分类与识别。虽然基于流统计特征的方法在协议或者应用族等粗粒度的分类上取得的不错的效果,但是在面向具体网络应用的分类中效果并不理想。这是由于在面向具体的网络应用进行流量分类时,简单的流统计特征不能有效地区分来自不同应用的流量。
近年来,随着深度学习技术在计算机视觉、语音和自然语言处理等方面的成功应用,相关研究人员开始将深度学习技术应用于网络流量分类。借助于深度学习技术强大的特征学习和表征能力,其在网络流量分类任务上取得了良好的效果。与传统基于统计的方法相比,这种方法使用深层结构的神经网络(如堆叠式自动编码器或cnn)自动从原始输入数据中学习特征,从而不需要繁琐的特征工程或专家知识的参与。虽然基于深度学习的方法已经在网络流量分类领域取得了很大的成功,但是网络流量分类任务中存在的类内数据多样性和类间数据相似性问题仍然没有被很好地解决。这是由于大部分已有的方法仅仅是将深度网络模型作为特征提取器来使用,而没有考虑设计新的更有效的目标函数。
已有的基于深度学习技术的网络流量分类方法往往仅将深度网络模型作为特征提取器来使用,不能有效地解决网络流量分类任务中存在的类内数据多样性和类间数据相似性问题,从而很难达到更加准确地对网络流量进行分类。
技术实现要素:
本发明技术解决问题:克服现有技术的不足,提供一种基于深度判别特征的网络流量分类系统及方法,能够更加准确地对网络流量进行分类。
本发明技术解决方案:
一种基于深度判别特征的网络流量分类系统,包括:预处理模块和模型学习模块;
预处理模块:以不同应用产生的长度不一的网络流作为输入,将每条网络流表示为固定大小的流矩阵,以满足卷积神经网络(cnn)的输入格式要求;将经过预处理的满足cnn输入格式要求的流矩阵称为网络流样本,其中,每个应用产生的网络流对应一个类别,不同应用产生的网络流属于不同的类别;
模型学习模块:将已收集的所有应用产生的网络流样本作为训练集,以训练集中的网络流样本作为输入,在度量学习正则化项和交叉熵损失项共同构成的目标函数的监督下,对cnn进行训练,使得cnn对输入的网络流样本学习得到更具判别性的特征表示,从而使得分类结果更加准确。
所述预处理模块具体处理流程如下:
(1)网络流为具有相同ip五元组<源ip,源端口,目的ip,目的端口,传输层协议>的一组连续的数据包;对于基于tcp连接的网络流来说,前3个数据包是相同的用来建立tcp连接的握手数据包,若网络流长度,即包含的数据包个数小于4,则丢弃,否则跳转至步骤(2);
(2)截取每条网络流前n个数据包和每个数据包的前m个字节,将每条网络流表示为特征向量;优选截取网络流的前32个数据包,并且对于每个数据包,截取从传输层头开始的512个字节,若网络流长度小于32或者ip包长度小于512,则用0填充,将网络流表示成大小为32*512的矩阵;
(3)将步骤(2)中所得矩阵的每个元素除以255来对该矩阵进行归一化处理;
(4)将步骤(3)中所得矩阵大小重新调整为128*128;
经过以上预处理过程,每条网络流被表示为了大小为128*128的流矩阵。
所述模型学习模块中,目标函数如下:
j=min(j1(x,y,θce)+λj2(x,θml))(1)
其中,j1和j2分别为交叉熵损失项和度量学习正则化项,所述交叉熵损失项指在最小化给定训练样本上的经验风险;λ是一个用来控制j1和j2相对重要性的权衡系数;x={xi|i=1,2,...,n}是训练样本集,y={yi|i=1,2,...,n}是训练样本集对应的标签集合,n是训练样本集中包含的样本个数;
所述交叉熵损失项如下:
其中,
所述模型学习模块中,度量学习正则化项的目标是寻找一个合适的保持输入数据对之间距离结构的相似性度量,采用对比嵌入(contrastiveembedding)函数作为正则化项,度量学习正则化项的输入是样本对,具体如下:
对比嵌入以成对样本对(xi,xj)作为输入,其中,
d(xi,xj)=||f(xi)-f(xj)||2(4)
其中,||·||2是l2正则操作;
式(3)中的第一项用来最小化来自同一类别的样本对之间的距离,对于来自不同类别的样本对,它们之间的距离大于一个预定义的边距m,因此式(3)中的第二项用来惩罚那些来自不同类别且距离小于m的样本对。
所述样本对生成过程如下:
(1)初始化样本对集合pairs为空:pairs←{};
(2)从训练集中得到训练样本的标签集合:label_set←set(y);
(3)对于label_set中的每个类别标签l,分别计算所有标签为l的样本的类别中心:
其中m为标签为l的样本数量;
(4)对于训练集中的每个样本xi,随机从{0,1}中选择一个值赋值给样本对指示器
(5)若样本对指示器
(6)若样本对指示器
(7)随机从label_set中选择一个不等于yi的标签y′;
(8)随机选择一个标签为y′的样本x′;
(9)将(x′,center[yi],
最终,给定训练数据集、权衡系数λ和边距m,使用标准的随机梯度下降算法对式(1)进行优化。
所述模型学习模块中,神经网络模型采用2维深度卷积神经网络结构。
本发明的一种基于深度判别特征的网络流量分类方法,包括以下步骤:
步骤1:网络流数据预处理。将不同应用产生的长度不一的网络流作为输入,对于每条网络流,截取其前32个数据包,并且对于每个数据包,截取从传输层头开始的512个字节,若网络流长度小于32或者ip包长度小于512,则用0填充,将每条网络流表示成大小为32*512的矩阵;再将该矩阵中的每个元素除以255来对其进行归一化处理;最后将所得矩阵大小重新调整为128*128,即每条网络流被表示为了大小为128*128的流矩阵,此流矩阵称为网络流样本;
步骤2:将已收集的所有应用产生的网络流样本作为训练集,以训练集中的网络流样本作为输入,在自定义的目标函数的监督下,对深度卷积神经网络进行训练,该自定义的目标函数是交叉熵损失项和度量学习正则化项的加权和,其中交叉熵项保证不同类别网络流样本之间的差异性,度量学习正则化项通过寻找一个合适的保持输入网络流样本对之间距离结构的相似性度量,来使得在特征空间下同类样本分布更加聚合即,欧式距离更小,不同类样本分布更加离散即,欧式距离更大;训练完成后的神经网络对输入的流矩阵学习得到更具判别性的特征表示,从而使得分类结果更加准确。
本发明与现有技术相比的优点在于:
(1)不同应用由于使用相同的网络协议或使用相同的服务等原因,其产生的网络流具有相似性;与此同时,同一应用可能使用多种网络协议完成不同的业务功能,其产生的网络流具有多样性。基于以上原因,在使用深度学习技术进行网络流量分类时,需要设计新的能够对网络流提取更具判别性特征的目标函数。本发明通过将度量学习与传统的深度学习技术相结合,对深度网络模型提出了新的目标函数。在该目标函数中,对比嵌入正则化项的引入使得在对输入数据提取的特征向量所在的特征空间中,来自同一类别的数据距离更小,来自不同类别的数据距离更大。这种更具判别性的特征有助于更加准确地进行分类。
(2)通过将度量学习正则化项与传统的交叉熵损失相结合,提出了新的目标函数。在该目标函数的作用下,提取到的特征更加具有判别性,即在特征空间下,数据具有更小的类内距离和更大的类间距离。
(3)本发明针对已有的基于深度学习的网络流量分类方法没有充分考虑网络流量数据中存在的类内数据多样性和类间数据相似性的问题,提出了一种基于深度判别特征的网络流量分类系统,能够更加准确地对网络流量进行分类。
附图说明
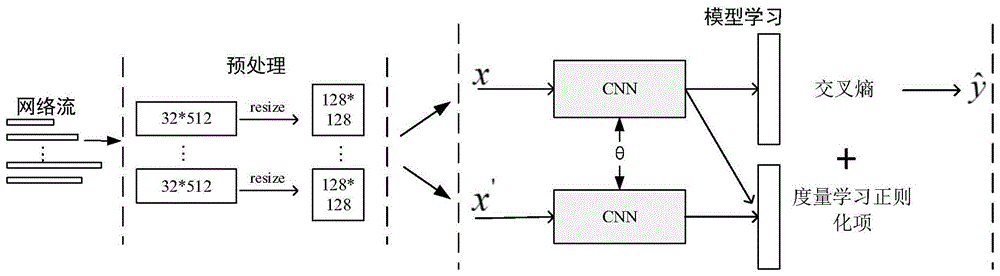
图1为本发明系统的总体框图。
具体实施方式
下面结合附图及实施例对本发明进行详细说明。
如图1所示,本发明具体实施如下:
总体框架见图1,包括两个模块:预处理和模型学习。
(1)预处理模块:预处理模块将长度不一的网络流(即,具有相同ip五元组<源ip,源端口,目的ip,目的端口,传输层协议>的一组连续的数据包)表示为固定大小的流矩阵,以满足卷积神经网络(cnn)的输入格式要求。
(2)模型学习模块:在度量学习正则化项和交叉熵损失的共同监督下,对深度卷积神经网络进行训练。
具体实施如下:
步骤1:预处理模块
预处理模块以原始的网络流作为输入,将每条网络流表示为固定大小的流矩阵。具体处理流程如下:
(1)若网络流长度(即,包含的数据包个数)小于4,则丢弃,否则跳转至(2);
(2)截取网络流的前32个数据包,并且对于每个数据包,截取从传输层头开始的512个字节,若网络流长度小于32或者ip包长度小于512,则用0填充,将网络流表示成大小为32*512的矩阵;
(3)将(2)中所得矩阵的每个元素除以255来对该矩阵进行归一化处理;
(4)将(3)中所得矩阵大小重新调整为128*128。
经过以上预处理过程,每条网络流被表示为了大小为128*128的流矩阵。
步骤2:模型学习
模型学习模块以步骤1中所得到的流矩阵作为输入,在目标函数的监督下对深度卷积神经网络进行训练。其主要包含目标函数定义和样本对生成两个关键步骤。
1.1.目标函数定义.
提出的目标函数定义如下:
j=min(j1(x,y,θce)+λj2(x,θml))(1)
其中,j1和j2分别为交叉熵损失项和度量学习正则化项。λ是一个用来控制j1和j2相对重要性的权衡系数,取值λ∈(0,1。x={xi|i=1,2,...,n}是训练样本集,y={yi|i=1,2,...,n}是训练样本集对应的标签集合,n是训练样本集中包含的样本个数。
①交叉熵损失项
该交叉熵损失项旨在最小化给定训练样本上的经验风险,定义如下:
其中,
②度量学习正则化项
度量学习的目标是寻找一个合适的可以保持输入数据对之间距离结构的相似性度量。这里使用对比嵌入(contrastiveembedding)函数作为目标函数中的正则化项,其定义如下:
与传统的经验风险函数不同,对比嵌入以成对数据(xi,xj)作为输入。其中,
d(xi,xj)=||f(xi)-f(xj)||2(4)
其中,||·||2是l2正则操作。
式(3)中的第一项用来最小化来自同一类别的样本对之间的距离。对于来自不同类别的样本对,希望它们之间的距离大于一个预定义的边距m,因此式(3)中的第二项用来惩罚那些来自不同类别且距离小于m的样本对。
将式(2)和式(3)代入式(1),最终的目标函数定义如下:
2.样本对生成
在本发明的模型中,度量学习正则化项的输入是样本对。考虑到当训练集中包含大量训练样本时,会产生一个巨大的样本对空间。具体来说,给定一个包含n个样本的训练集,共存在
(1)初始化样本对集合pairs为空:pairs←{};
(2)从训练集中得到训练样本的标签集合:label_set←set(y);
(3)对于label_set中的每个类别标签l,分别计算其类别中心:
(4)对于训练集中的每个样本xi,随机从{0,1}中选择一个值赋值给样本对指示器
(5)若样本对指示器
(6)若样本对指示器
(7)随机从label_set中选择一个不等于yi的标签y′;
(8)随机选择一个标签为y′的样本x′;
(9)将(x′,center[yi],
最终,给定训练数据集、权衡系数λ和边距m,使用标准的随机梯度下降算法对式(5)中的目标函数进行优化。
以上虽然描述了本发明的具体实施方法,但是本领域的技术人员应当理解,这些仅是举例说明,在不背离本发明原理和实现的前提下,可以对这些实施方案做出多种变更或修改,因此,本发明的保护范围由所附权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!