基于深度优先搜索的频繁模式挖掘方法与流程
本发明属于复杂网络和数据挖掘领域,涉及面向带标签的异质网络中基于深度优先搜索的频繁模式挖掘方法,具体涉及一种复杂网络中基于深度优先搜索的频繁模式挖掘方法。
背景技术:
现如今,随着大数据时代的到来和网络信息技术的迅速发展,人类社会已经迈入复杂网络时代。复杂网络不仅是一种数据的表现形式,它同样也是一种科学研究的手段。基于复杂网络所建立起来的科学问题越来越多样化,为学科交叉提供了良好的可能性。复杂网络通常作为复杂系统的有力表示,例如社交网络、生物网络、文献网络等。带标签的异质网络通常用来研究和分析这些数据。
由于网络和图自身的拓扑结构等优势,使其具有广泛的应用性,针对图挖掘的相关研究也引起越来越多研究者的关注。而且,图挖掘在许多实际应用中具有巨大的潜在价值,这些应用包括语义网络、行为建模、生物网络分析、化学化合物分类等。目前,人们已经提出了很多高效的算法来挖掘图数据中的子图或模式,由于应用的对象及问题背景的不同,这些算法的效果也具有很大的差异。频繁模式挖掘的目的是找到在图集中频繁出现的模式集合,为接下来的研究和分析工作提供重要的帮助。目前的频繁子图挖掘算法大致可以分为两大类:一类是广度优先算法,这类算法包括agm和fsg等;另一类是深度优先算法,这类算法包括gspan和ffsm等。大多数的传统算法在时间复杂性上有一个影响最大的问题是子图同构问题。
因此,考虑到真实的复杂网络具有多样化的结构和如何节省时间和空间成本这一事实,以及异质网络中带标签的节点不仅能够帮助提高模式挖掘的结果而且可以协助分析挖掘出的模式的潜在规律。对复杂网络中的频繁模式的挖掘和分析是一个很值得研究的问题。基于深度优先搜索的方法对图进行遍历,将研究的图数据对象构建成一个由标准化图编码组成的线性序列,定义支持度和图的线性顺序,根据最右扩展和最佳匹配原则挖掘出所有的频繁模式,使挖掘的结果更具有广泛的适用性和意义。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种面向带标签的异质网络中基于深度优先搜索的频繁模式挖掘方法。
本发明针对探索复杂网络中的频繁模式结构和如何在匹配模式过程中节约时间和空间成本的困难,以及将节点的属性和网络的拓扑结构同时联系起来进行建模的问题,提出一个基于深度优先搜索的频繁模式挖掘方法,挖掘出真实网络中的频繁模式,找出其潜在的规律。此方法在事件的检测和预测、事件聚类中有广泛的应用价值,也可以帮助解决真实场景下的实际问题。
本发明为解决背景技术中的技术问题,采用的技术方案是:基于深度优先搜索的频繁模式挖掘方法,该方法包括如下步骤:
s1:方法中涉及的相关概念和定义:
(1)带标签网络:将一个带标签的网络看作是一个五元组,g={v,e,σv,σe,l}。其中,v表示网络中节点的集合;
(2)子图同构:图的同构是一个双射f:
①
②
③
子图同构是np完全问题。如何减少或降低子图同构的计算开销,是图挖掘工作的主要研究内容之一。
(3)频繁模式:给定一个网络集合gd,从gd中挖掘出的模式集合是pd,pd={pi|i=0,1,…,n},且给定最小支持度阈值为min_sup,我们称模式集合pd是频繁的,当且仅当集合中的每一个元素pi的支持度不小于最小支持度阈值,即suppi≥min_sup。
(4)模式的支持度:给定一个网络集合gd,从gd中挖掘出的模式集合是pd,pd={pi|i=0,1,…,n},模式pi(0≤i≤n)的支持度记为suppi,计算方法是根据第一步得到的pi中指定的pivot(也就是挖掘的起始点),随着pi的一步步匹配和更新,得到的所有匹配中pivot的映射,也就是模式pi中节点pivot的出现次数,记作该模式的支持度suppi。
s2:标准化图编码:
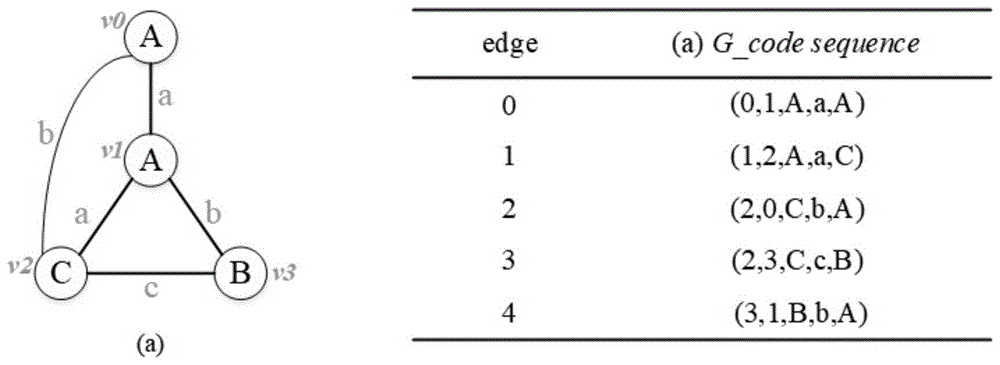
(1)由s1中(1)可知,带标签网络中的每一条边都存在5个基本元素,那么我们直接采用这样形式的五元组对边进行编码,将边e=(vi,vj)表示为(vi,vj,li,le,lj),其中,vi,vj为节点的唯一标识,li,lj为节点标号,le为边标号。例如附图1的示例图,边e=(v1,v2)可以表示为(1,2,a,a,b)。网络中每一条边都可以用编码形式来表示,那么整个网络就可以等价成是由一系列这样的图编码所组成的线性序列,即网络的标准化图编码序列g_codesequence={ek|k=1,2,…,n}。
(2)编码顺序的规则:节点标识的先后顺序的确定是存在一定的规则的。如果在图的dfs遍历过程中,先遍历的节点是vi,后遍历的节点是vj,那么vi和vj的编码顺序为vi<vj。同样,根据节点的标识确定出边标号也存在一定规则,进而定义边之间的线性关系。例如可以通过v0<v1来确定(v0,v1)<(v1,v2),边标号也符合这样的规则,例如可以通过e1=(v0,v1)<e2=(v1,v2)来确定le1=a<le2=b。
(3)编码的线性顺序:给定带标签网络中的任意两条边的编码为e1=(a1,a2,a3,a4,a5),e2=(b1,b2,b3,b4,b5),其线性顺序由下列条件决定:
①e1=e2,当且仅当ai=bi,i=1,2,…,5;
②e1<e2,当且仅当
③e1<e2,其他情况。
s3:频繁模式挖掘算法的过程:
在s1,s2的相关概念和定义的基础上,进行频繁模式挖掘。算法gfpm的起始,是采用深度优先搜索对整个网络集合gd进行遍历,随机选择一个起始顶点,并对访问过的顶点做标记,被访问过的顶点对应一个编码g_code,编码序列由少至多逐渐扩展,直到遍历结束,对整个网络建立起了一个完整的由标准化图编码组成的线性序列g_codesequence={ek|k=1,2,…,n}。
将遍历得到的图编码线性序列g_codesequence作为输入,进行频繁模式的挖掘。从编码序列的第一条边开始,逐步向下扩展来进行模式的匹配计算,每次进行扩展时遵循最右路径扩展原则,并且每扩展一次边ek和新节点vi+1,都要重新计算并更新模式的支持度suppi。最右路径扩展原则如下:一个模式中最后发现的节点叫做最右节点,从第一个节点到最右节点的直线路径叫做最右路径。给定图g,一条新边e可以添加到最右节点和最右路径上另一个节点之间,这种扩展方式称作后向扩展;也可以引入一个新节点并且连接到最右路径上的节点,这种扩展方式称作前向扩展。由于这两种扩展都发生在最右路径上,因此称为最右扩展。附图2展示了最右路径扩展可能的几种情况。
每次更新模式的支持度suppi,和给定的频繁模式的支持度阈值min_sup作比较,若suppi≥min_sup,则新的模式为频繁模式,放入频繁模式集合fpd={pi|i=0,1,…,m},若suppi≤min_sup,则判定新模式不是频繁模式,并对更新的该节点和边进行剪枝。
在对非频繁模式进行剪枝时,若更新的节点vi+1后续没有邻居节点簇,即该节点为最右节点,则对该节点vi+1和边ek进行剪枝即可,若更新的该节点vi+1后续有邻居节点簇,则需要对邻居节点簇进行整体剪枝。对邻居节点簇的整体剪枝,根据该节点vi+1的位置信息确定在图编码序列中该节点的邻居节点簇的映射信息,然后再对邻居节点簇的所有信息全部剪枝。
剪枝结束后,返回当前节点继续进行最右扩展,每次进行扩展时遵循最右路径扩展原则,即回到第五步,循环这一扩展-计算匹配-剪枝的过程,直到整个网络扩展结束,会得到频繁模式集合fpd={pi|i=0,1,…,m};输出最终得到的频繁模式集合fpd={pi|i=0,1,…,m},挖掘过程结束。
有益效果
本发明所提出的方法,以复杂网络理论框架为基础,基于深度优先搜索对图遍历后得到由标准化图编码组成的线性序列,对所构建的带标签的关系网络进行频繁模式挖掘,挖掘出网络中的频繁模式集合的同时,在方法上有效地减少了子图同构问题,避免了冗余候选模式的产生;对线性序列的映射操作,大大节省了内存的使用。还可以应用到多种场景和挖掘领域,有利于对实际问题的分析和进一步的研究。
附图说明
图1是标准化图编码的示例说明;
图2是最右路径扩展的几种情况说明。
具体实施方式
下面结合附图和具体实施例对本发明技术方案作进一步详细描述,所描述的具体实施例仅对本发明进行解释说明,并不用以限制本发明。
本发明针对研究复杂网络中的频繁模式结构,提出一个基于深度优先搜索的频繁模式挖掘方法,挖掘出带标签的关系网络中的频繁模式,找出其潜在的规律。该方法主要可应用于对某些领域频繁模式的挖掘结果的研究,实施频繁模式挖掘算法时,可以按照下面的步骤进行:
第一步:首先对要分析的带标签的关系网络进行数据处理,确认每个节点和每条边有对应的节点标识、节点标号和边标号;
第二步:采用深度优先搜索对整个网络进行遍历,随机选择一个起始顶点,并对访问过的顶点做标记,被访问过的顶点对应一个编码g_code,编码序列由少至多逐渐扩展,直到遍历结束;
第三步:遍历结束,对整个网络建立起了一个完整的由标准化图编码组成的线性序列g_codesequence={ek|k=1,2,…,n};
第四步:将遍历得到的图编码线性序列g_codesequence作为输入,进行频繁模式的挖掘;
第五步:从编码序列的第一条边开始,逐步向下扩展来进行模式的匹配计算,每次进行扩展时遵循最右路径扩展原则,并且每扩展一次,都要重新计算并更新模式的支持度suppi;
第六步:每次更新模式的支持度suppi,和给定的频繁模式的支持度阈值min_sup作比较,若suppi≥min_sup,则新的模式为频繁模式,放入频繁模式集合fpd={pi|i=0,1,…,m},若suppi≤min_sup,则判定新模式不是频繁模式,并对更新的该节点和边进行剪枝;
第七步:对非频繁模式进行剪枝,若更新的节点后续没有邻居节点簇,即该节点为最右节点,则对该节点和边进行剪枝即可,若更新的该节点后续有邻居节点簇,则需要对邻居节点簇进行整体剪枝;
第八步:对更新的节点的邻居节点簇进行整体剪枝,根据该节点的位置信息确定在图编码序列中该节点的邻居节点簇的映射信息,对邻居节点簇的所有信息全部剪枝;
第九步:剪枝结束后,返回当前节点继续进行最右扩展,每次进行扩展时遵循最右路径扩展原则,即回到第五步,循环这一扩展-计算匹配-剪枝的过程,直到整个网络扩展结束,会得到频繁模式集合fpd={pi|i=0,1,…,m};
第十步:输出最终得到的频繁模式集合fpd={pi|i=0,1,…,m},算法结束。
- 还没有人留言评论。精彩留言会获得点赞!