一种裁判文书实体关系抽取方法及系统与流程
本发明涉及自然语言处理信息抽取领域,具体地,涉及一种裁判文书实体关系抽取方法及系统。
背景技术:
目前,通用的关系抽取方法包括基于规则的关系抽取、基于深度学习cnn等方法的关系抽取等。由于法律关系的多样性(仅民事案件达800多个案由)和文本表述的多样性,基于规则的关系抽取无法在裁判文书领域应用。基于深度学习cnn等方法的关系抽取依赖大量标注数据,需要借助大量不同细分案件领域的专业人员,效率较低且对标注人员要求更高。目前尚无裁判文书领域实体关系抽取的典型案例。
技术实现要素:
本发明的目的在于实现裁判文书中两个实体间关系的抽取。裁判文书在特定区域描述案情事实,将非结构化的案情描述转化为程序可识别的描述方式,是实现案情匹配的重要步骤。本发明实现裁判文书案情事实中实体关系抽取,用于支撑通过三元组形式描述案情。
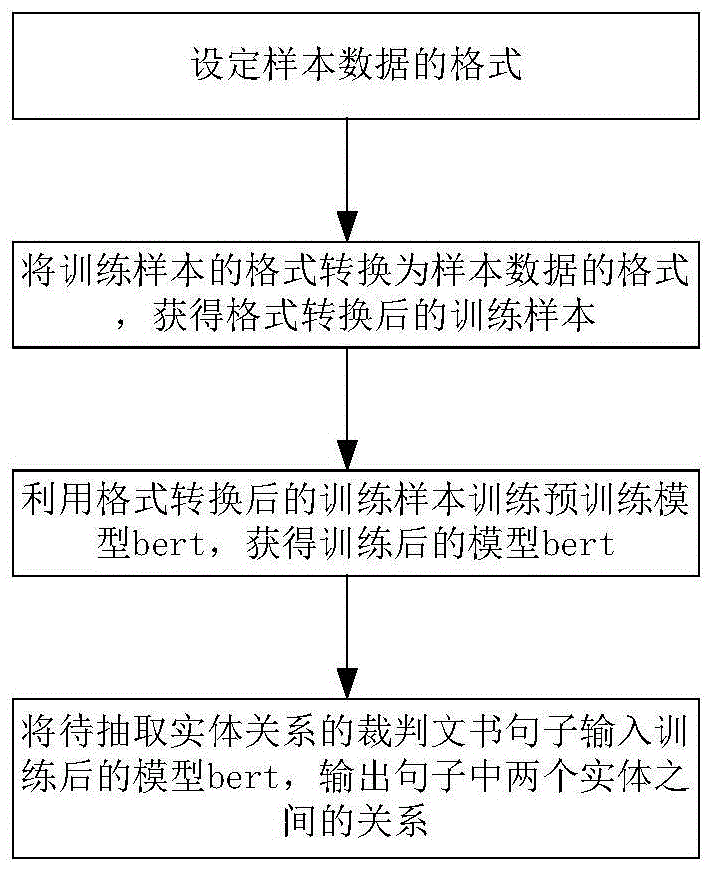
为实现上述发明目的,本发明一方面提供了一种裁判文书实体关系抽取方法,所述方法包括:
设定样本数据的格式;
将训练样本的格式转换为样本数据的格式,得到格式转换后的训练样本;
利用格式转换后的训练样本训练预训练模型bert,得到训练后的模型bert;
将待抽取实体关系的裁判文书句子输入训练后的模型bert,输出裁判文书句子中两个实体之间的关系。
优选的,预训练模型bert的结构为:
模型的输入为一个明确表示单个裁判文书句子或一对裁判文书句子的token序列。对于给定token,其输入表示通过对相应的token、segment和positionembeddings求和进行构造,通过12层双向self-attention处理得到对应token长度表示的768维向量。
优选的,样本数据的格式为:(句子,(实体1,开始位置1,结束位置1,实体类型1),(实体2,开始位置2,结束位置2,实体类型2),实体1与实体2之间的关系),表示一个句子中已知的实体对的关系,添加实体位置信息是为了消除句子中存在多个相同实体时产生的歧义。例如样本数据:(张三在天府大道上开着张三买的奔驰车呼啸而过,(张三,1,2,自然人),(奔驰车,15,18,机动车),驾驶),表示句子“张三在天府大道上开着张三买的奔驰车呼啸而过”对应的实体“张三”和“奔驰车”的关系为“驾驶”,句子中有两个“张三”,位置信息用来区分这两个“张三”,第一个“张三”和“奔驰车”是“驾驶”关系,第二个“张三”和“奔驰车”是“购买”关系。
优选的,模型的训练过程为:
将格式转换后的训练样本输入预训练模型bert;
提取预训练模型bert的cls位置的输出向量作为裁判文书句子的向量表示,记为sentenceembedding;
提取预训练模型bert的输出序列中实体1的开始位置到结束位置对应的向量序列,取向量序列的平均值作为实体1的向量表示,记为ent1embedding;
提取预训练模型bert的输出序列中实体2的开始位置到结束位置对应的向量序列,取向量序列的平均值作为实体2的向量表示,记为ent2embedding;
顺序拼接sentenceembedding、ent1embedding和ent2embedding向量,得到第一次拼接后的向量;
将第一次拼接后的向量进行变换得到变换后的向量表示,记为vector1;
将实体1对应的实体类型转换成向量表示,记为ent1typeembedding;
将实体2对应的实体类型转换成向量表示,记为ent2typeembedding;
顺序拼接vector1、ent1typeembedding和ent2typeembedding向量,得到第二次拼接后的向量;
使用softmax层对第二次拼接后的向量进行分类,得到训练后的模型bert。
优选的,本方法中的句子为裁判文书句子。
另一方面,本发明还提供了一种裁判文书实体关系抽取系统,所述系统包括:
样本数据格式设定单元,用于设定样本数据的格式;
训练样本格式转换单元,用于将训练样本的格式转换为样本数据的格式,得到格式处理后的训练样本;
模型训练单元,用于利用格式转换后的训练样本训练预训练模型bert,得到训练后的模型bert;
实体关系抽取单元,用于将待抽取实体关系的裁判文书句子输入训练后的模型bert,输出裁判文书句子中两个实体之间的关系。
进一步的,预训练模型bert的结构为:
模型的输入为一个明确表示单个裁判文书句子或一对裁判文书句子的token序列。对于给定token,其输入表示通过对相应的token、segment和positionembeddings求和进行构造,通过12层双向self-attention处理得到对应token长度表示的768维向量。进一步的,样本数据的格式为:(句子,(实体1,开始位置1,结束位置1,实体类型1),(实体2,开始位置2,结束位置2,实体类型2),实体1与实体2之间的关系),表示一个句子中已知的实体对的关系,添加实体位置信息是为了消除句子中存在多个相同实体时产生的歧义。例如样本数据:(张三在天府大道上开着张三买的奔驰车呼啸而过,(张三,1,2,自然人),(奔驰车,15,18,机动车),驾驶),表示句子“张三在天府大道上开着张三买的奔驰车呼啸而过”对应的第一个实体“张三”和“奔驰车”的关系为“驾驶”,句子中有两个“张三”,位置信息用来区分这两个“张三”,第一个“张三”和“奔驰车”是“驾驶”关系,第二个“张三”和“奔驰车”是“购买”关系。
进一步的,模型训练单元训练模型的过程为:
将格式转换后的训练样本输入预训练模型bert;
提取预训练模型bert的cls位置的输出向量作为裁判文书句子的向量表示,记为sentenceembedding;
提取预训练模型bert的输出序列中实体1的开始位置到结束位置对应的向量序列,取向量序列的平均值作为实体1的向量表示,记为ent1embedding;
提取预训练模型bert的输出序列中实体2的开始位置到结束位置对应的向量序列,取向量序列的平均值作为实体2的向量表示,记为ent2embedding;
顺序拼接sentenceembedding、ent1embedding和ent2embedding向量,得到第一次拼接后的向量;
将第一次拼接后的向量进行变换得到变换后的向量表示,记为vector1;
将实体1对应的实体类型转换成向量表示,记为ent1typeembedding;
将实体2对应的实体类型转换成向量表示,记为ent2typeembedding;
顺序拼接vector1、ent1typeembedding和ent2typeembedding向量,得到第二次拼接后的向量;
使用softmax层对第二次拼接后的向量进行分类,获得训练后的模型bert。
进一步的,本系统中的句子为裁判文书中的句子。
本发明提供的一个或多个技术方案,至少具有如下技术效果或优点:
本方法及系统在小样本情况下能达到更好的效果。本方法及系统采用了迁移学习方法,使用预训练模型bert,在小样本情况下实验效果远远好于其他关系抽取模型(cnn,pcnn,lstm)。
本方法及系统在同等数据量情况(包含小样本,中样本,大量样本)下效果优于其他关系抽取模型(bert+cnn,cnn,pcnn,lstm)。本方法及系统使用句子信息、实体信息、实体位置信息以及实体类型信息,在模型中间拼接,符合关系抽取三元组的天然结构。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本发明的一部分,并不构成对本发明实施例的限定;
图1是本发明中一种裁判文书实体关系抽取方法的流程示意图;
图2是本发明中预训练模型bert的结构示意图;
图3是本发明中一种裁判文书实体关系抽取系统的组成示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
请参考图1,本发明实施例提供了一种裁判文书实体关系抽取方法,所述方法包括:
设定样本数据的格式;
将训练样本的格式转换为样本数据的格式,得到格式转换后的训练样本;
利用格式转换后的训练样本训练预训练模型bert,得到训练后的模型bert;
将待抽取实体关系的裁判文书句子输入训练后的模型bert,输出句子中两个实体之间的关系。
本方法的目的在于抽取裁判文书句子中两个实体之间的关系。本方法包括三个步骤:
步骤1:数据准备。定义样本数据的格式为(sentence,(ent1,start1,end1,type1),(ent2,start2,end2,type2),relation)。其中,sentence表示句子,ent1表示实体1,ent2表示实体2,start1和start2表示实体在句子中的开始位置,end1和end2表示实体在句子中的结束位置,type1和type2表示实体类型,relation表示实体1与实体2之间的关系。
步骤2:数据处理。将输入数据转换成预训练模型bert需要的输入格式。
步骤3:模型训练和实体关系抽取。模型的具体结构参照附图2,训练过程包括以下步骤:
1.将格式转换后的输入数据输入预训练模型bert。
2.提取模型bert的cls位置的输出向量作为sentence的向量表示,记为sentenceembedding,表示句子的含义。
3.提取模型bert的输出序列中ent1的start1到end1对应的向量,然后对提取的向量取平均值作为ent1的向量表示,记为ent1embedding。
4.提取模型bert的输出序列中ent2的start2到end2对应的向量,然后对提取的向量取平均值作为ent2的向量表示,记为ent2embedding。
5.顺序拼接sentenceembedding、ent1embedding和ent2embedding,得到第一次拼接后的向量。
6.对第一次拼接后的向量进行多个全连接层的变换得到新的向量表示vector1。
7.将ent1对应的实体类型type1转换成向量表示ent1typeembedding。
8.将ent2对应的实体类型type2转换成向量表示ent2typeembedding。
9.顺序拼接vector1、ent1typeembedding和ent2typeembedding,得到第二次拼接后的向量。
10.在第二次拼后的向量后加一个softmax层,用于对第二次拼接后的向量进行分类,得到对应的关系relation。
请参考图3,本发明实施例提供了一种裁判文书实体关系抽取系统,所述系统包括:
样本数据格式设定单元,用于设定样本数据的格式;
训练样本格式转换单元,用于将训练样本的格式转换为样本数据的格式,得到格式转换后的训练样本;
模型训练单元,用于利用格式转换后的训练样本训练预训练模型bert,得到训练后的模型bert;
实体关系抽取单元,用于将待抽取实体关系的裁判文书句子输入训练后的模型bert,输出裁判文书句子中两个实体之间的关系。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!