海量文本去重筛选的方法、设备和存储介质与流程
本发明涉及互联网技术领域,特别是涉及一种海量文本去重筛选的方法、设备和存储介质。
背景技术:
在互联网时代,信息成爆炸式增长,一条新闻会被各种媒体转载、修改、编辑,文本去重就是将相似的、重复的信息识别出来。常用的文本去重算法有simhash(局部敏感哈希的一种)、余弦相似度等。
simhash的对比速度比较快,在海量文本去重任务中,可以极大的提升整体性能,但是准确率和召回率一般,能达到80%左右,也就是说还有20%的文本的相似度会被误判。
技术实现要素:
本发明的目的在于提供一种海量文本去重筛选的方法、设备和存储介质。
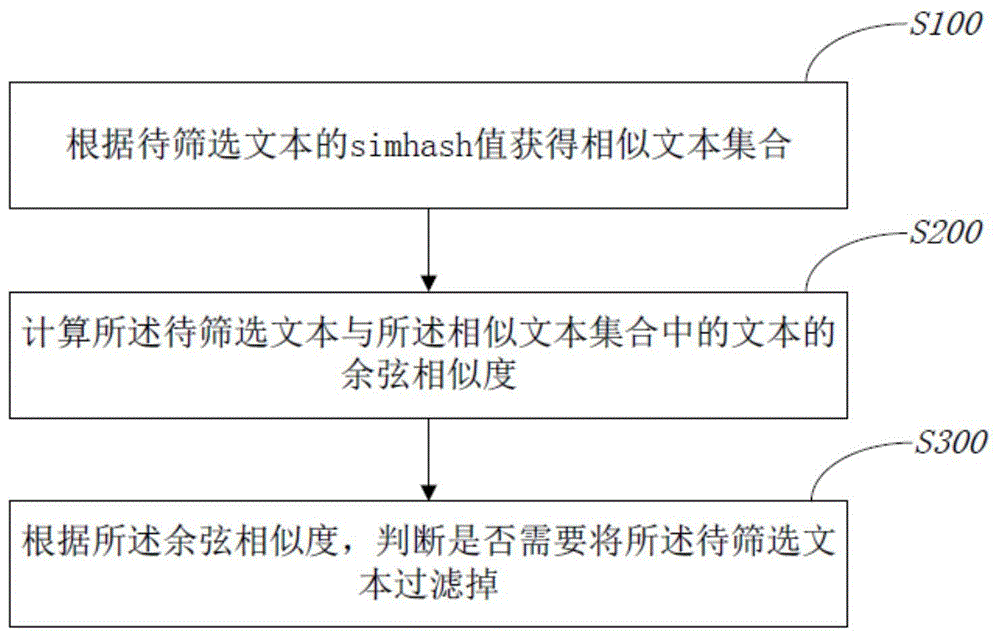
为实现上述发明目的之一,本发明一实施方式提供一种海量文本去重筛选的方法,所述方法包括:
根据待筛选文本的simhash值获得相似文本集合;
计算所述待筛选文本与所述相似文本集合中的文本的余弦相似度;
根据所述余弦相似度,判断是否需要将所述待筛选文本过滤掉。
作为本发明一实施方式的进一步改进,所述“根据待筛选文本的simhash值获得相似文本集合”具体包括:
根据待筛选文本的simhash值在simhash索引库中查找与所述待筛选文本海明距离小于等于k的相似simhash值链表,得到相似文本集合。
作为本发明一实施方式的进一步改进,所述k为大于3的正整数。
作为本发明一实施方式的进一步改进,所述待筛选文本的simhash值为64位,所述k=4,所述simhash值被分成5段,前4段为13位,最后1段为12位。
作为本发明一实施方式的进一步改进,所述“根据所述余弦相似度,判断是否需要将所述待筛选文本过滤掉”具体包括:
若所述相似文本集合中存在与所述待筛选文本的余弦相似度大于或等于相似度阈值的文本,过滤掉所述待筛选文本;
若所述相似文本集合中所有文本与所述待筛选文本的余弦相似度都小于相似度阈值,或者所述相似文本集合为空,将所述待筛选文本的simhash值存入所述simhash索引库中。
作为本发明一实施方式的进一步改进,所述“将所述待筛选文本的simhash值存入所述simhash索引库中”具体包括:
将所述simhash按照预定的规则分成k+1段,分别将每一段作为关键字在所述simhash索引库中查找对应的链表,总共找到k+1个链表,将所述simhash分别存入所述k+1个链表的末端。
作为本发明一实施方式的进一步改进,所述“根据待筛选文本的simhash值到simhash索引库中查找与所述待筛选文本海明距离小于等于k的相似simhash值链表,得到相似文本集合”具体包括:
将所述simhash按照预定的规则分成k+1段,分别将每一段作为关键字在所述simhash索引库中查找对应的链表,总共找到k+1个链表;
将所述k+1个链表中的simhash值对应的文本放入相似文本集合中。
作为本发明一实施方式的进一步改进,所述方法还包括:
计算所述待筛选文本的simhash值与所述相似simhash值链表中相似simhash值的海明距离;
若所述相似simhash值链表中存在与所述待筛选文本的simhash值的海明距离小于或等于距离阈值的相似simhash值,过滤掉所述待筛选文本。
为实现上述发明目的之一,本发明一实施方式提供一种电子设备,包括存储器和处理器,所述存储器存储有可在所述处理器上运行的计算机程序,所述处理器执行所述程序时上述任意一项所述海量文本去重筛选的方法中的步骤。
为实现上述发明目的之一,本发明一实施方式提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述海量文本去重筛选的方法中的步骤。
与现有技术相比,本发明将两种文本相似度算法进行整合,利用simhash的速度快、余弦相似度精度高的特点,在海量文本中进行相似度对比,来达到新闻去重的目的,能够对海量文本进行快速而又准确的去重筛选。
附图说明
图1是本发明海量文本去重筛选的方法的流程示意图。
图2是本发明海量文本去重筛选的方法的步骤s300的流程示意图。
具体实施方式
以下将结合附图所示的具体实施方式对本发明进行详细描述。但这些实施方式并不限制本发明,本领域的普通技术人员根据这些实施方式所做出的结构、方法、或功能上的变换均包含在本发明的保护范围内。
如图1所示,本发明提供一种海量文本去重筛选的方法,所述方法具体包括:
步骤s100:根据待筛选文本的simhash值获得相似文本集合。
在获取相似文本集合之前,需要先计算待筛选文本的simhash值。
simhash算法是一种局部敏感哈希算法,它能够将高维数据进行概率降维并映射为位数较少且固定的指纹(指纹也称为simhash值),之后再对指纹进行相似度比较来反映数据之间的相似程度。其中相似度比较通常使用海明距离。计算文本simhash值的具体过程为:
将所述待筛选文本进行分词和去停用词,得到文本关键词集合;计算集合中每个文本关键词的权重和hash值,将文本关键词的权重与hash值相乘,得到每个文本关键词的权重向量;将所述待筛选文本的文本关键词集合中的元素的权重向量进行合并(相加),得到所述待筛选文本的权重向量;对所述待筛选文本的权重向量进行降维处理,得到待筛选文本的simhash值,优选simhash值的长度为64位(64bit)。
在计算完成待筛选文本的simhash值后,根据simhash值获得相似文本集合。具体的,根据待筛选文本的simhash值在simhash索引库中查找与所述待筛选文本海明距离小于等于k的相似simhash值链表,得到相似文本集合。再进一步的,将所述simhash按照预定的规则分成k+1段,分别将每一段作为关键字在所述simhash索引库中查找对应的链表,总共找到k+1个链表;将所述k+1个链表中的simhash值对应的文本放入相似文本集合中。
由于当k小于或等于3时,simhash的准确率和召回率最大能达到80%,想要获取更高的准确率和召回率,优选k是大于3的正整数。
在一个优选的实施方式中,所述待筛选文本的simhash值为64位,所述k=4,所述simhash值被分成5段,前4段为13位,最后1段为12位。具体的分段计算过程为:
在相似度阈值为海明距离k时,则根据抽屉原理,把simhash分成k+1段,使用这k+1段在simhash的倒排索引中进行查找待对比的数据。切分逻辑如下(f为simhash长度):
前k个按以下公式计算切分块长度:
len1(i)=ceil(f/(k+1)),i∈[1,k]
第k+1个按以下公式计算切分块长度:
len2(i)=f-ceil(f/(k+1))×(i-1),i=k+1
当f=64、k=4时,64bit被切分为13bit,13bit,13bit,13bit,12bit。
此时simhash索引库包括4*2^13+2^12=36864张链表,每张链表下存放海明距离小于或等于4的simhash值。待筛选文本的simhash值也被切分成5段,然后分别将每一段作为关键字在所述simhash索引库中查找对应的链表,总共找到5张链表。由于每张链表下存放的都是与待筛选文本的simhash值的还没距离小于或等于4的simhash值,因此将所述5个链表中的simhash值对应的文本放入相似文本集合中,就得到相似文本集合。
步骤s200:计算所述待筛选文本与所述相似文本集合中的文本的余弦相似度。
所述步骤具体包括:使用已经训练好的模型,将所述待筛选文本和所述相似文本集合中的文本都转化成向量;计算述待筛选文本的向量与所述相似文本集合中的文本的向量的余弦相似度。
具体的,使用已训练好的word2vec模型(当然也可以是其它的模型),将待筛选文本转化成向量表示成v,向量维度为j维,然后转化成[1,j]的矩阵,同时对于相似文本集合t,共n条记录,将t中所有的文本向量取出,组成[n,j]的矩阵。根据以下矩阵运算公式可计算出待筛选文本与相似文本集合中的各文本的余弦相似度:
步骤s300:根据所述余弦相似度,判断是否需要将所述待筛选文本过滤掉。如图2所示,所述步骤具体包括:
步骤s310:若所述相似文本集合中存在与所述待筛选文本的余弦相似度大于或等于相似度阈值的文本,过滤掉所述待筛选文本。
相似度阈值为预先设定的一个值,当两个文本的余弦相似度大于或等于相似度阈值时,判定这两个文本为相似文本,当两个文本的余弦相似度小于相似度阈值时,判定这两个文本为不相似文本。
需要说明的是,在本发明中,当两个文本的海明距离小于等于k时,判定这两个文本可能相似,需要将两个文本的余弦相似度与相似度阈值进行比较才能判断这两个文本是相似文本还是不相似文本。但是当两个文本的海明距离大于k时,可以判定这两个文本是不相似文本。
因此,当相似文本集合中存在与所述待筛选文本的余弦相似度大于或等于相似度阈值的文本时,认为相似文本集合中存在与待筛选文本相似的文本,所述待筛选文本为重复的文本,因此过滤掉所述待筛选文本(当然是记录所述待筛选文本或者给所述待筛选文本做记号等)。
步骤s320:若所述相似文本集合中所有文本与所述待筛选文本的余弦相似度都小于相似度阈值,或者所述相似文本集合为空,将所述待筛选文本的simhash值存入所述simhash索引库中。
当相似度合集为空时,判定simhash索引库中不存在与待筛选文本的海明距离小于或等于4的文本,可以直接判定待筛选文本与simhash索引库存放的simhash值对应的文本都不相似,待筛选文本为不相似文本,需要存入simhash索引库中。
或者当相似文本集合中所有文本与所述待筛选文本的余弦相似度都小于相似度阈值,也可以判定待筛选文本为不相似文本,需要存入simhash索引库中。
优选的,所述“将所述待筛选文本的simhash值存入所述simhash索引库中”具体包括:
将所述simhash按照预定的规则分成k+1段,分别将每一段作为关键字在所述simhash索引库中查找对应的链表,总共找到k+1个链表,将所述simhash分别存入所述k+1个链表的末端。
就这样将海量文本中的每个文本到simhash索引库中进行比对,然后将重复的文本过滤掉,不重复的文本存入simhash索引库中,最后得到不相似文本合集,达到了去重筛选的目的。
本发明将两种文本相似度算法(simhash算法和余弦相似度)进行整合,利用simhash的速度快、余弦相似度精度高的特点,在海量文本中进行相似度对比,来达到新闻去重的目的,能够对海量文本进行快速而又准确的去重筛选。
为了进一步加快去重筛选的速度,在一个优选的实施方式中,当找到simhash索引库中的相似simhash值链表后,计算所述待筛选文本的simhash值与所述相似simhash值链表中相似simhash值的海明距离。若所述相似simhash值链表中存在与所述待筛选文本的simhash值的海明距离小于或等于距离阈值的相似simhash值,过滤掉所述待筛选文本。
距离阈值为预先设定的海明距离,优选此距离阈值为1,即当两个文本的海明距离小于或等于1时,判定这两个文本为相似文本。因此,在本实施方式中,当相似simhash值链表中存在与待筛选文本相似的文本时,判断待筛选文本为重复文本,需要过滤掉(或者记录此待筛选文本、或给此待筛选文本打上记号)。
在一个具体的实施例中,当海量文本需要去重时,按照文本的时间顺序逐一对每个文本进行处理,将相似的文本过滤掉,将不相似的文本的simhash值存入simhash索引库中,最后将所有相似的文本都过滤掉,就得到不相似文本的集合。simhash索引库包括4*2^13+2^12=36864张链表,用于存储不相似文本的simhash值。其中单个文本(待筛选文本)的处理过程具体为:
首先计算待筛选文本的64位simhash值,将所述simhash值分成5段(前4段13位,后1段12位),分别将这5段作为关键字在simhash索引库中查找对应的链表,最后总共能找出5张链表。判断这5张链表是不是都为空,若是,判定待筛选文本为不相似文本,存入simhash索引库中。若不是,5张链表中的simhash值对应的文本放入一个集合中,就得到相似文本集合。这个相似文本集合中可能存在重复存放的文本,此时可以先将重复存放的文本清理一遍,再进行余弦相似度判断。
将待筛选文本与上述相似文本集合中的文本进行文本向量化,然后计算待筛选文本与相似文本集合中的文本的余弦相似度,若存在余弦相似度小于相似度阈值的文本,则判定待筛选文本为相似文本,否则,判定待筛选文本为不相似文本,存入simhash索引库中。
在另一个将simhash算法与余弦相似度结合进行文本去重筛选的实施方式中,存在4个文本,其中文本1为待筛选文本,文本1需要判断与文本2-4是否为相似文本,4个文本的simhash值依次如下:
1101111110110111001111001000110110110001100000001110111010011010
1101111110110111001111001000100110110001100000001110011010011010
1001111110100110001111011001100110110001100000001110111011011010
1101111110110111001111001000100110110001100010001110111001011010
通过simhash值,判断文本1与文本2和文本4的海明距离分别为2和4,需要继续进入下一步余弦相似度对比,文本1与文本3的海明距离为7,直接判定文本1和文本3为不相似文本。
再经模型推理,文本1、2、4的向量依次为:
[0.207306050.02028328-0.32165986-0.21978268-0.058638460.16604638-0.676250640.418463560.23052499-0.093540750.33701654-0.69099678-0.30069899-0.429458530.19196298-0.656540450.372762620.11128408…]
[1.54137742e-016.58711775e-02-3.29600481e-01-1.50874229e-01-4.48612731e-029.21696734e-02-6.49440484e-013.18887830e-011.82012444e-01-1.02761533e-013.18788333e-01-7.16967488e-01…]
[0.28797083-0.09659498-0.24238907-0.22820453-0.188848970.06698163-0.723589510.378369130.259974670.051538460.3284452-0.54951132-0.26240415-0.393325790.27352081-0.617880260.33407160.29438264…]
经余弦相似度计算cos(d1_d2)=0.99487017,cos(d1_d4)=0.96130207,假设预先设定0.97为相似度阈值,则文本1与文本2相似,而文本1与文本4不相似。
本发明还提供一种电子设备,包括存储器和处理器,所述存储器存储有可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述所述海量文本去重筛选的方法中的步骤。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述所述海量文本去重筛选的方法中的步骤。
应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施方式中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!