一种用于加密边坡监测数据的改进时空Kriging插值算法的制作方法
本发明属于边坡变形监测数据处理技术领域,特别涉及一种用于加密边坡监测数据的改进时空kriging插值算法。
背景技术:
边坡位移监测是建筑、矿业等相关领域的重要研究内容,其工程安全直接影响到人民的生命财产安全。但是对于矿山边坡变形监测及其稳定性分析而言,由于其受到经费、设备、技术水平以及观测环境等因素的制约,大部分小型矿山企业采用的都是传统测量手段,即使部分矿山企业采用测量机器人或gnss等较为先进的设备,但依然很难获得大量、连续、均匀分布的时空变形监测数据,造成边坡变形趋势及稳定性分析产生偏差,导致对边坡施工及防治决策出现失误甚至错误。为弥补和克服边坡监测数据稀少(丢失)、不连续、不均匀等问题,准确分析露天矿边坡的整体变形趋势及其稳定性,这是矿山企业安全施工和管理中一个迫切需要解决的问题,并已成为国内外学者的研究热点。
为弥补和克服边坡监测数据稀少(丢失)、不连续、不均匀等问题,很多学者采用线性插值法、拉格朗日(lagrange)插值法、牛顿(newton)插值法、hermite插值法、反距离加权法和空间kriging插值法等方法对监测数据进行插值,提高其完整性、连续性和均匀性。但随着研究的不断深入,大量的实践结果表明,上述研究方法仅考虑监测数据的时间属性存在一定的不足。研究实践表明,变形监测数据不仅与时间属性有关,而且还与空间属性也有关系,具有较强的时空相关性。为此,部分学者充分考虑监测点的时空相关性,采用时空插值模型对变形监测数据进行处理,如采用不均匀时空kriging插值算法对滑坡位移进行分析;王建民采用高斯过程回归时空插值法以及kriging时空插值法对监测数据进行了插值分析。
但是现有技术方法在计算过程中存在所选变异函数模型受主观因素和理论半变异函数的局限性,以及参数估计较多的问题,导致其插值精度低、计算复杂效率低等缺点。
技术实现要素:
本发明的目的是为了解决传统时空插值方法在选择变异函数模型受主观因素和理论半变异函数的局限,以及参数估计较多的问题,并在充分考虑变形监测点时空相关性的基础上,提出一种用于加密边坡监测数据的改进时空kriging插值算法,其为一种改进自适应遗传算法(iaga)与时空kriging相结合的时空混合插值方法,以提高计算效率及插值数据的精度,增强其普适性和可靠性。
本发明的目的是通过以下技术方案来实现,一种用于加密边坡监测数据的改进时空kriging插值算法,包括如下步骤:
s1:确定编码方式,根据矿山边坡的实际情况,将获得的各个时期的边坡监测数据进行时空kriging变异函数时间序列编码,并按时期分组,每一组中都包含了某一个时段的空间变异函数类型和时间变异函数类型,并将历史数据分为t个时段,t≥1,t为自然数。
s2:种群初始化,在初始变异函数的确定中,先确定起始变异函数时间序列,然后采用hamilton改良圈算法对初始种群进行优化,获得父代;
s3:染色体的遗传交叉与变异,根据样本的适应度大小确定种群优劣排序,适应度小的父本与适应度小的父本交配,适应度大的父本与适应度大的父本交配,然后根据logistic混沌序列的方法确定交叉点的位置,最后对需要交叉配对的父代按照位置进行交叉操作;
s4:交叉概率和变异概率的自适应优化,对遗传变异概率进行自适应改正;
s5:目标函数的确定,边坡曲面的时空kriging插值变异函数的时间序列染色体由t个时段组成,当修改某一时段的变异函数类型时,kriging插值的性能将会发生相应变化,从而再寻求另外一组变异函数组序列对插值效果进行优化,然后通过交叉验证的方式,使得边坡曲面区域内插值后的rmse最小量作为目标,并以此确定其目标函数;
s6:插值精度分析,采用交叉验证的方法评价其精度,并检验所确定的变异函数模型的好坏。
本发明解决了传统时空插值方法在选择变异函数模型受主观因素和理论半变异函数的局限,以及参数估计较多的问题,在一定程度上弥补和克服了边坡监测数据稀少(丢失)、不连续、不均匀等问题,提高了计算效率及插值数据的精度,为实现矿山边坡整体区域变形时空演化过程的分析提供保障,也为相关问题及领域的三维建模研究提供了一种新思路。
本发明提供了用于加密边坡监测数据的改进时空kriging插值算法,对比分析其精度,并构建基于iaga的时空kriging插值的边坡三维整体曲面,以实现对越堡露天矿边坡整体变形区域的时空演化过程的分析。
进一步地,所述步骤s1中的具体编码方式为:
进一步地,所述步骤s3中,先设定一个介于0-1的交叉概率值pj,该值一般较大,如pj>0.9,当pj=1时,说明所有个体都发生交叉操作,而当pj=0时,则表示不发生交叉操作;并且每次操作时,通过生成一个服从0-1均匀分布的随机数,若该值大于pj,则需要对相应个体染色体组点位进行对应操作;与交叉操作类似,在变异操作上先从交叉后的个体中选择变异个体,预先设定一个介于0-1的交叉概率值nb,该值一般较小,nb<0.1,假定样本的容量为n,则发生变异体的个数nb=nb*n。
进一步地,所述步骤s4中,采用下式进行修正,
上式(1)和(2)中,
进一步地,所述步骤s5中,目标函数的表达式如下:
上式(3)中,t为变异函数序列时间段数,ni为第i时段的边坡已知点个数,(xij,yij,zij)为采用kriging插值后得到的点坐标,
进一步地,所述步骤s6中可具体为s60:采用交叉验证的方法评价其精度,以检验所确定的变异函数模型的好坏。
所述步骤s60中,具体操作如下s61:先将观测值z(xi)(i=1,2,…,n)从监测数据列中去除,再用剩下的其它观测值通过建立变异函数模型的方法,预测出该去除监测点的估计值z*(xi),并将预测值放回到原数据列中,再选择其它点重复以上操作,直到计算出所有监测点的估计值z*(xi)为止。
在步骤61后进行步骤s62:计算原数据与估计值之间的误差dzi,以分析数据的一致性,并依据公式(4)得到均方根误差rmse以检验插值的准确性,
在步骤62后进行步骤s63:用判定系数r2评价其相关性程度,并计算判定系数r2,计算表达式如公式(5)所示,该值有残差平方和总体平方和构成,其定义式如公式(6)和(7)所示,若其值近似1则表示两者线性相关程度越强。
式(7)中,sres为残差平方和,stotal为总体平方和,
附图说明
本发明实施例的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
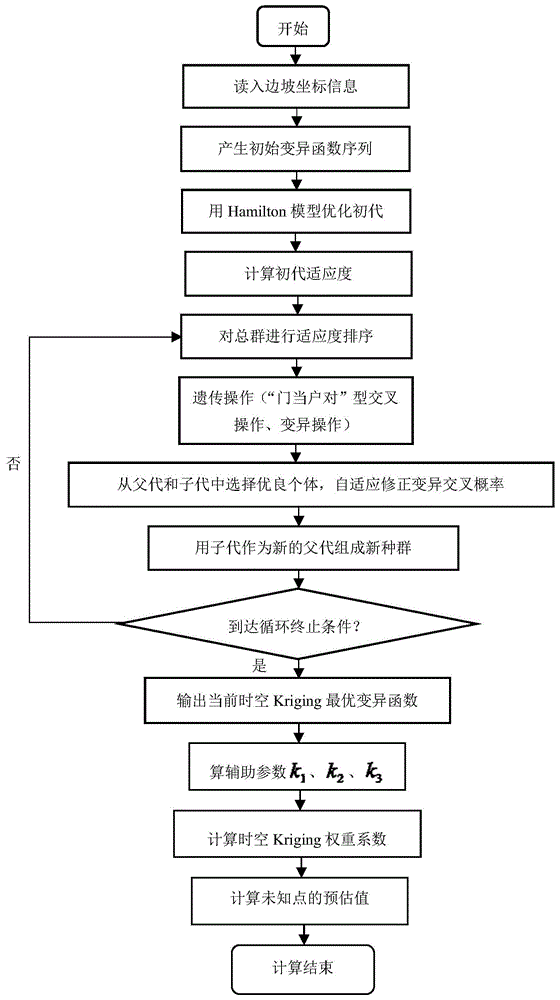
图1是基于iaga时空kriging插值算法计算流程图;
图2是越堡露天矿边坡监测点分布情况示意图;
图3是交叉验证法计算步骤流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
时空kriging插值方法是在空间kriging插值方法的基础上,将数据从空间域向时空域的延伸和扩展,以此充分考虑监测点间在空间和时间上的相关性。其时空位置函数为:z(ha,ta)=z(x,y,z,t)(ha=f(x,y,z)),则可以将时空kriging插值模型表示如式(8):
式中:z*(hp,tp)为未知点p的估计值,z(hi,ti)为未知点p邻域内已知样本点i的监测值,λi为kriging权重系数,n(u,t)为已知样本点对的个数。
与空间普通kriging插值方法相同,要获取未知点的预估值,应先将监测值依据下式(9)求算变异函数γ(hs,ht)的估计值γ*(hs,ht)。
式中:γ*(hs,ht)为未知点的估计值;z(hi,ti)为样本点i处的监测值;z(hi+hs,ti+ht)是与z(hi,ti)空间上相隔hs,时间上相隔ht的监测值;hs,ht分别表示空间分隔距离和时间分隔距离;n(hs,ht)表示时空分隔距离为hs,ht样本数据点对的数量。
在此基础上,采用一种不可分离型模型常用的方法(一类积和式)来构建时空kriging变异函数模型,其模型如式(3)。
式中:γst(hs,ht)表示时空变异函数,γs(hs)表示空间变异函数,γt(ht)表示时间变异函数,cst(0,0)、cs(0)、ct(0)分别为相应变异函数的基台值,k1、k2、k3为辅助参数。
尽管空间插值和时空插值方法能够实现对边坡整体变形趋势的分析,但是在插值的过程中,由于所选择的变异函数模型通常会受到主观因素和理论半变异函数的局限,以及参数估计较多的问题,导致插值方法的普适性及其精度会受到一定程度的影响。时空变异函数序列确定问题实际上是一个组合优化问题,也就是优化理论中的np-hard问题。但由于其解向量空间不连续,并且解邻域在表达方面困难,所以难用通常的经典算法求解。作为现代优化算法之一的遗传算法其主要特点是对非线性极值问题能以概率1跳出局部最优解,找到全局最优解,是一种启发式的算法。而遗传算法的跳出局部最优和寻找全局最优特性都主要取决于交叉和变异行为。由此,基于iaga时空kriging插值算法计算流程如图1所示。
s1:确定编码方式
通常情况下,染色体编码方式有浮点数编码、二进制编码、格雷码编码、符号编码法。鉴于浮点数编码可表示的数值范围广、精度高且便于较大空间的遗传搜索,且能够较好地表示克里金kriging插值变异函数的时间序列关系,更容易体现出边坡曲面长时间序列情况。因此本文选择浮点数编码方式进行表示。
首先根据矿山边坡的实际情况,将获得的各个时期的边坡监测数据进行时空kriging变异函数时间序列编码,并按时期分组,每一组中都包含了某一个时段的空间变异函数类型和时间变异函数类型,并将历史数据分为t个时段,具体编码方式如下示:
其中:第m染色体组lm1lm2表示在第m段时期时采用的空间变异函数编码lm1(表示范围为1-i,编码数字分别指代所采用的变异函数模型,例如球形模型、指数模型等)和时间变异函数编码(同空间变异函数一样,表示范围为1-j,编码数字指代该时段的时间变异函数类型),当i和j超过个位数时,lm1lm2可根据实际情况增加染色体长度表示其编码范围。
s2:种群初始化
通常来说,初始种群应有足够大的规模,这样能够提高取得的最优解概率,但由于规模过大造成搜索范围越广,使得造成后代遗传过程时间变长。同时,初始总群的优劣也直接影响到结果的准确性和算法效率。因此,在初始变异函数的确定中,可以先根据经验模型,例如:空间克里金插值和时空克里金插值的方式选择起始变异函数时间序列。另一方面也可以结合一些经典优化算法,例如hamilton改良圈算法对初始种群进行优化,获得较好的父代。
s3:染色体的遗传交叉与变异
基于kriging插值编译函数时间序列的改进自适应遗传算法的染色体交叉配对方式,将采用“门当户对”的方式进行,也就是根据样本的适应度大小确定种群优劣排序,适应度小的父本与适应度小的父本交配,适应度大的父本与适应度大的父本交配。然后根据logistic混沌序列的方法确定交叉点的位置,最后对需要交叉配对的父代按照位置进行交叉操作。
在实际操作上,可以先设定一个介于0-1的交叉概率值pj,该值一般较大。而且一般情况下,当pj=1时,说明所有个体都发生交叉操作,而当pj=0时,则表示不发生交叉操作。并且每次操作时,通过生成一个服从0-1均匀分布的随机数,若该值大于pj,则需要对相应个体染色体组点位进行对应操作。
此外,与交叉操作类似,在变异操作上可先从交叉后的个体中选择变异个体,预先设定一个介于0-1的交叉概率值nb,该值一般较小,假定样本的容量为n,则发生变异体的个数nb=nb*n。
s4:交叉概率和变异概率的自适应优化
为了提升子代最优解的质量,减小局部最优解的概率,可对遗传变异概率进行自适应改正,避免在变异函数时间序列大空间范围内进行搜索时陷入局部极值,由此,本文采用式(1)和式(2)对其进行修正。
上式中,
s5:目标函数的确定
假设露天矿边坡曲面的时空kriging插值变异函数的时间序列染色体由t个时段组成,当修改某一时段的变异函数类型时,kriging插值的性能将会发生相应变化,从而再寻求另外一组变异函数组序列对插值效果进行优化,然后通过交叉验证的方式,使得边坡曲面区域内插值后的rms最小量作为目标,并以此确定其目标函数为式(3):
上式中,t为变异函数序列时间段数,ni为第i时段的边坡已知点个数,(xij,yij,zij)为采用kriging插值后得到的点坐标,
s6:插值精度分析
本申请以发生过失稳的广州市越堡露天矿西侧hp1边坡为研究对象,根据边坡实际情况,布设了40个变形监测点,其编号分别用jc01-jc40来表示,构建成了5个断面形式的观测线,其分布情况如图2所示,考虑到布点者的安全,部分平台布点较少,但为了满足边坡变形趋势分析需要,提高边坡插值精度,在靠近滑坡区域的周边观测线内加密了监测点,并采用具有高精度和高稳定度的徕卡tm30测量仪器,获取各监测点的三维坐标,并计算出其水平及沉降位移大小。
为了更清晰地对比、分析插值方法的精度,本文采用交叉验证的方法评价其精度,并检验所确定的变异函数模型的好坏。其基本思路是:先暂时将观测值z(xi)(i=1,2,…,n)从监测数据列中去除,再用剩下的其它观测值通过建立变异函数模型的方法,预测出该去除监测点的估计值z*(xi),并将预测值放回到原数据列中,再选择其它点重复以上操作,直到计算出所有监测点的估计值z*(xi)为止。然后再计算原数据与估计值之间的误差dzi,以分析数据的一致性,并依据公式(4)得到均方根误差rmse以检验插值的准确性:
用判定系数r2评价其相关性程度,计算步骤流程如图3所示。并计算判定系数r2,计算表达式如公式(5)所示。该值有残差平方和总体平方和构成,其定义式如公式(6)和(7)所示,若其值近似1则表示两者线性相关程度越强。
式(6)中,sres为残差平方和,stotal为总体平方和,
为验证本文基于iaga的时空kriging插值方法的可行性,本文将采集的变形监测数据分为三期,时间分别为2016年12月23日、2017年05月31日和2018年02月07日,得到传统空间插值和改进自适应时空插值经交叉验证所得结果如表2所示:
表2不同监测时期两种插值方法均方根误差和相关系数对比
由此,根据表2中交叉验证结果分析可以得出:
1)改进自适应遗传算法克服了变异函数模型选择受主观因素和理论半变异函数的局限,以及参数估计较多的问题,其插值精度相比较普通时空克里金插值方法更优,能够提高约1倍左右,更具一定的普适性、可靠性和可行性;
2)随着边坡监测数据量的不断增加,并在变形量变化相对较大的情况下,改进自适应遗传算法的时空kriging混合插值方法运算更简便,也更能突出其在优选变异函数以及参数估计等方面的优势;
3)不管是在哪个时间段,改进自适应遗传算法的时空kriging插值方法和时空kriging插值方法计算得到结果的相关性及其精度都明显高于空间kriging插值方法,增强其普适性和可靠性,表明其插值效果能更好地拟合边坡表面变形监测点数据,有利于后续的边坡整体变形趋势和三维特征的分析。
本申请提出的用于加密边坡监测数据的改进时空kringing插值算法,是一种改进自适应遗传算法的时空kriging插值混合算法,通过对插值精度进行对比分析,结果表明:改进自适应遗传算法的时空kriging插值混合方法在优选变异函数时更具普适性和可靠性,并且计算得到的rmse和r2都明显高于空间kriging插值方法,弥补和克服了边坡监测数据稀少或丢失等问题,增强其普适性和可靠性,表明其插值效果能更好地拟合边坡表面变形监测点数据,有利于后续的边坡整体变形趋势和三维特征的分析。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!