一种基于时间t的指数消失函数的网络流量动态分类方法与流程
本发明属于网络流量分类领域,具体涉及一种基于时间t的指数消失函数的网络流量动态分类方法。
背景技术:
网络流量分类的实现是运行和优化各种网络资源的重要基础,在网络资源管理、入侵检测等方面发挥重要作用。在网络流量识别研究中分类技术主要经历了三个阶段:基于固定端口号的流量分类阶段、基于深度包流量检测(deeppacketinspection,dpi)分类阶段和基于机器学习的流量分类阶段。随着动态端口技术和伪装端口技术的出现,给基于固定端口的流量分类系统带来了严峻挑战。为解决基于端口的流量分类技术存在的不足,yang等人使用dpi流量分类技术,即以透视的形式深度检查数据包是否携带目标流量类型的特征码,从而实现对网络流量的分类识别。然而基于dpi的流量分类是以分组数据信息可见性及荷载目标特征已知为前提的,因此不适用于加密流量和未知特征码的网络流量。基于固定端口、dpi的流量分类技术本质上可以理解专家系统,即通过人为的制定规则来实现对网络流量的匹配和识别,不具备智能识别、分类能力。近年来,随着人工智能的兴起,机器学习作为人工智能的主要实现方式,越来越多的机器学习技术被应用到网络流量分类当中。
基于机器学习的网络流量分类技术是对各网络流量统计信息进行计算,利用相关算法对数据包进行识别,进而对相应的网络流量进行分类。机器学习方法主要分为有监督学习和无监督学习。无监督学习是指根据样本间的相似特性对训练集中的样本进行聚类来设计分类器,例如k均值聚类,最大期望算法等。然而在无监督网络流量分类中,利用聚类结果构造未知类别的流量是困难的。同时,实际网络流量是随时间而动态变化的,即含有时间偏移现象,进一步加大实时动态分类的难度。
技术实现要素:
本发明的目的在于一种基于时间t的指数消失函数的网络流量动态分类方法,以克服现有技术的缺陷,本发明通过基于时间t的消失函数对动态流量数据进行权重衰减,再通过对核心类簇、潜在类簇以及边缘类簇之间的进化、退化,实现流量的动态分类。
为达到上述目的,本发明采用如下技术方案:
一种基于时间t的指数消失函数的网络流量动态分类方法,包括以下步骤:
1)收集网络流量数据,形成流量数据集ft1,并记录实际流量数据各维度特征的到达时间;
2)对流量数据集ft1按特征维度进行归一化、离散化预处理,得到特征集合ft2;
3)定义基于时间t的指数消失函数,作用于特征集合ft2各维度特征,模拟各维度特征随时间变化而权重衰减;
4)定义三种聚类类簇,分别是核心类簇、潜在类簇和边缘类簇;
5)通过对实时网络流量的权重系数、密度区域半径与实验获取的相应阈值进行判断,实现核心类簇、潜在类簇和边缘类簇间的动态变化,进而对动态网络流量的实时分类。
进一步地,步骤1)中,流量数据集ft1表示为x={x1,x2,...,xn},包含n条流量数据,其中对于每条流量数据xi规范定义为{xi1,xi2,...,xik},其中k为样本的维度,当xik特征到达,记录相应时间,最终得到每条流量数据的维度特征到达时间向量{ti1,ti2,...,tik}。
进一步地,步骤2)中,对流量数据集ft1按特征维度进行归一化,是对流量数据集ft1中每一维特征分别进行线性映射,使每一维特征值在保持原有数据意义下映射到[0,1]之间,消除各维度特征值量纲差别带来的影响,从而得到归一化后的特征集;再对归一化后的特征集中的非连续型数据进行one-hot离散化,得到特征集合ft2。
进一步地,步骤3)中,定义基于时间t的指数消失函数为:f(t)=2-λt,其中t为当前时间,λ为指数系数,当λ越大,权重衰减的程度越大,即已经权重衰减的数据特征对当前分类的影响越小。
进一步地,步骤4)中:
核心类簇:由核心对象构成的可分类簇,如果核心类簇聚类成未知标签类簇,则由专家确定分类标签;所述核心对象定义为对于任一训练样本,在其密度区域半径内至少存在3个类似样本;
潜在类簇:通过对网络流量权重系数、密度区域半径与实验获得的相应阈值的判断,能够进化为核心类簇或者退化为边缘类簇;
边缘类簇:通过对网络流量权重系数、密度区域半径与实验获得的相应阈值的判断,能够进化为潜在类簇或者消失。
进一步地,步骤5)中,定义核心对象的权重系数和的阈值为μ,核心对象的密度区域半径的阈值为ε;对属于流量数据集ft2中的实时流量数据进行基于时间t的指数消失函数权重衰减,即w'=f(t)w,其中w是实时流量数据特征的初始权重,初始化为1,w'为相应权重系数再经过基于时间t的指数消失函数后的更新值;当核心对象权重系数和w'≥μ且实时流量数据的密度区域半径r<ε,则为核心类簇;当w'>βμ且r≤ε,其中β是类簇变化阈值,且0.5<β<1,则属于潜在类簇;当w'<βμ,则属于边缘类簇。
与现有技术相比,本发明具有以下有益的技术效果:
面对实际网络流量数据是随时间的变化而动态变化的特性,采用基于时间t的指数消失函数实现对流量数据特征的权重衰减,拟合实时网络流量的时间特性,使得该分类算法具有较好的实时性,能够处理含有时间变化现象的实时流量。同时,定义核心类簇、潜在类簇、边缘类簇,通过相关阈值条件判断实现对网络流量实时动态分类,具有较好的实际应用价值。
附图说明
图1为实时网络流量分类总体框架图;
图2为网络流量包信息提取图;
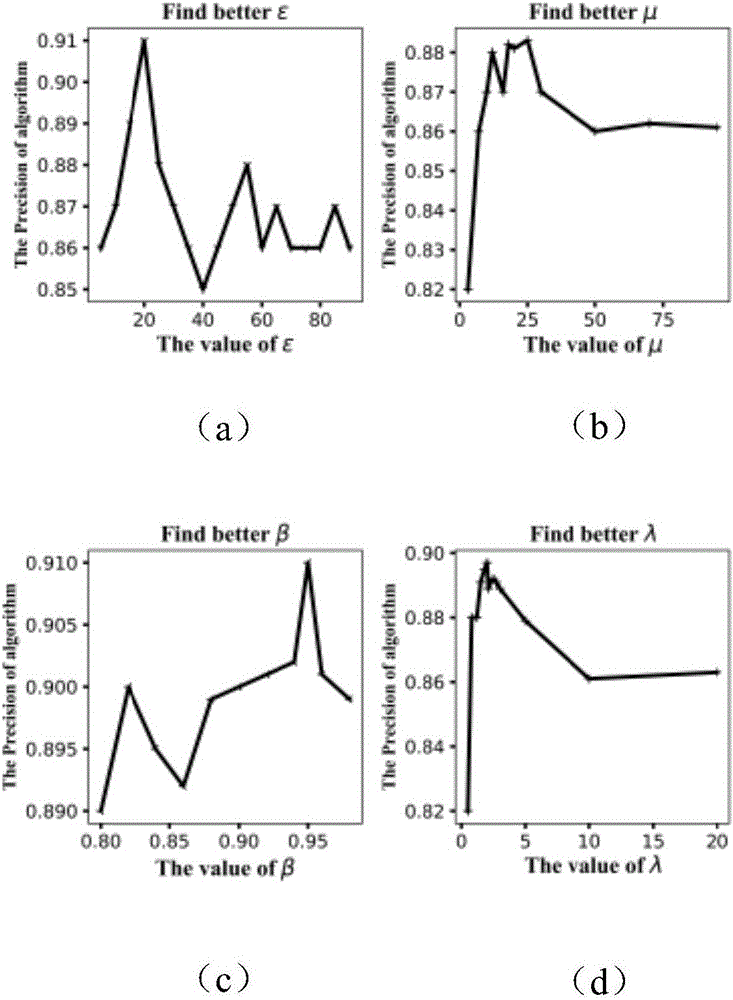
图3为模型训练参数确定图,其中(a)为通过交叉对比实验,其密度区域半径阈值ε的变化趋势图,(b)为通过交叉对比实验,核心对象的权重系数和的阈值变化趋势图,(c)为通过交叉对比实验,其类簇变化β的阈值变化趋势图,(d)为通过交叉对比实验,其基于时间t的指数消失函数的指数系数λ的阈值变化趋势图;
图4为模型损失函数图;
图5为模型训练准确度图;
图6为模型训练roc图。
具体实施方式
下面对本发明作进一步详细描述:
一种基于时间t的指数消失函数的网络流量动态分类方法,包含以下步骤:
1)使用wireshark工具收集网络流数据,形成数据集ft1,并记录实际流量数据各维度特征的到达时间;数据集表示为x={x1,x2,...,xn},包含n条流量数据,其中对于每条流量数据xi规范定义为{xi1,xi2,...,xik},其中k为样本的维度,当xik特征到达,记录相应时间,最终得到每条流量数据的特征到达时间向量{ti1,ti2,...,tik}。
2)对流量数据集ft1按特征维度进行归一化、离散化预处理,得到特征集合ft2;预处理实现步骤如下:
2.1)对网络流量数据集ft1按特征维度进行归一化,是对ft1中流量数据中每一维特征分别进行线性映射,使每一维特征值在保持原有数据意义下映射到[0,1]之间,消除各维度特征值量纲差别带来的影响,从而得到归一化后的特征集。
2.2)再对归一化后的特征集中的非连续型数据进行one-hot离散化,得到处理后的流量数据集ft2。
3)定义基于时间t的指数消失函数,用于对特征集合ft2中流量数据,模拟各维度特征随时间变化而权重衰减;定义基于时间t的指数消失函数为:f(t)=2-λt,其中t为当前时间,λ指数系数,当λ越大,权重衰减的程度越大,即已经权重衰减的数据特征对当前分类的影响越小。
4)定义三种聚类类簇,分别是核心类簇、潜在类簇、边缘类簇,三种类型类簇定义如下:
4.1)核心类簇,由核心对象构成的可分类簇,如果核心类簇聚类成未知标签类簇,则由专家确定分类,表示为coc=(w,c,r),根据当前流量数据特征到达时间戳
4.2)潜在类簇,通过相关阈值条件判断,可以进化为核心类簇或者退化为边缘类簇,表示为cadoc=(w,c,r,β),其中0.5<β<1,满足w>βμ且r≤ε,其中β是类簇变化阈值,由实验得出。
4.3)边缘类簇,通过相关阈值条件判断,可以进化为潜在类簇或者消失,表示为ooc=(w,c,r,t0,β),其中t0是当前边缘类簇创建时间,满足w<βμ。
5)通过对权重系数、区域半径等阈值条件的判断实现对动态网络流量的实时分类;当流量数据到达时:
5.1)当满足条件w≥μ且r<ε时,归为核心类簇。
5.2)当满足条件满足w>βμ且r≤ε时,归为潜在类簇。
5.3)当满足条件w<βμ时,归为边缘类簇。
5.4)当新的流量数据xi到达时,记录当前时刻ti,计算xi到核心类簇、潜在类簇、边缘类簇的欧式距离,再根据条件将xi融入相关类簇,更新数据阈值。
进一步地,所述步骤5)中,当流量数据到达时:
5.1)当满足条件w≥μ且r<ε时,归为核心类簇,μ为流量数据的周边权重和,ε为密度区域半径。
5.2)当满足条件满足w>βμ且r≤ε时,归为潜在类簇。
5.3)当满足条件w<βμ时,归为边缘类簇。
5.4)当新的流量数据xi到达时,记录当前时刻ti,计算xi到核心类簇、潜在类簇、边缘类簇的欧式距离,再根据条件将xi融入相关类簇,更新数据阈值。
步骤5.4)中,xi融入类簇可以分为三种情况:
5.4.1)如果xi融入核心类簇后,新的周边权重和w'>μ,并且新的密度区域半径rd<ε,则xi的分类标签和当前核心类簇标记相同。
5.4.2)如果xi融入潜在类簇后,新的周边权重和w'>βμ,并且新的密度区域半径rd<ε,则xi的分类标签不能确定直到该潜在满足条件化为核心类簇。
5.4.3)如果xi融入边缘类簇后,同时满足新的周边权重和w'<βμ和新的密度区域半径rd>ε,则删除该边缘类簇。
下面结合实施例对本发明作进一步说明:
实时网络流量分类的总体框架如图1所示,首先使用wireshark工具对实时网络流量数据进行抓包,得到最初网络流量数据集ft1,然后对获取的数据集ft1进行归一化、离散化操作,得到特征预处理后的数据集ft2,再ft2基础上执行本发明所述算法进行模型训练和调试,最终实现对实时网络流量进行动态的分类。
本次实验网络流量包由itnac组织收集,含有273061个数据包,所有的包可以提取为8个特征,分别是源ip、目标ip、协议、长度、源端口、目标端口、数据流间隔时间、标签,如图2所示。实验在此基础上进一步提取特征,如数据包初始达到时间,最小数据流间隔时间、平均到达时间、三分之一到达间隔时间等特征。同时,将网络流量划分为六个类别,并记录相关统计数据。
模型阈值ε,阈值μ,阈值β,阈值λ确定。通过交叉实验法确定相关模型阈值,对于ε,如果ε太大,会导致模型融合不同分类的类簇,如果ε太小,则会导致类簇数变大,进而降低分类准确度;再设定好ε后,可以启发式的设定类簇阈值μ;λ,β在设定ε,ε参数后通过交叉实验确定。交叉试验后,设定ε=20,μ=27,β=0.95,λ=2.1,如图3确定。
使用准确率曲线、roc曲线等衡量模型效果,而准确度曲线和roc曲线可以由混线矩阵获得,模型训练损失函数如图4所示,在模型阈值设定为ε=20,μ=27,β=0.95,λ=2.1时,随着模型训练的进行,算法的损失函数逐渐收敛至稳定值。实验结果如图5显示,模型的分类的准确率、图6所示为对比其他算法,本发明所提算法auc值约为0.85,优于其他两种算法,具有较好的实际分类效果。
- 还没有人留言评论。精彩留言会获得点赞!