一种基于无人机视觉系统的地面目标地理坐标定位方法与流程
本发明属于计算机视觉技术领域,具体涉及一种基于无人机视觉系统的地面目标地理坐标定位方法。
背景技术:
随着无人飞行器技术在近年的快速发展,多旋翼无人飞行器成为了一种相对成熟的无人飞行器,并被广泛应用于摄影、测绘、植保、巡线、安防、目标侦查等各种任务中。
无人机具有机动性高、操作灵活等优势,所以在目标侦察领域有巨大优势,比传统的固定摄像头监视范围更大且更灵活。使用无人飞行器进行目标搜索逐步成为一种应用热点,目前最普及的方法,还是操作人员手动操控飞行器飞行,或是手动设置任务区域或任务点后自动规划航线飞行。然后在飞行过程中通过传回的图像通过人工观察目标是否出现,并判断目标出现的位置。
让无人机自主进行目标搜索是一个趋势,可以大大提高工作的效率,在该方面,人们取得了一系列的成果。胡天江等发明了一种基于图像和导航信息的无人机地面目标定位方法(cn108845335a),通过无人机自身携带的导航信息(位置和姿态)结合摄像机的内外参数,根据目标在图像中的检测结果,可以获取地面目标的三维空间位置。谭冠政等发明了一种基于无人机的地面运动目标实时跟踪方法及系统(cn106981073a),通过地面站实时处理无人机传回的图像序列,检测图像中感兴趣的运动目标,并且利用算法融合策略对检测到的目标进行跟踪。管凤旭等发明了一种无人机飞行控制平台及目标跟踪方法(cn108803655a),视频采集单元采集目标图像传回地面控制单元,地面控制对目标进行跟踪,生成无人机控制信息将无人机控制信息传回无人机,无人机根据控制信息完成移动目标跟踪。
在现有方法中,存在目标的定位精度差,对多目标搜索时的处理策略差等问题。
技术实现要素:
针对现有技术中存在的缺陷,本发明的目的是提供一种让无人机自主对指定目标进行搜索并对其地理坐标进行高精度定位的方法,且能实现区域内多个目标的定位。为达到以上目的,本发明采用的技术方案是:
一种基于无人机视觉系统的地面目标地理坐标定位方法,在无人机视觉采集系统上实现的,包括以下步骤:
(1)搭建和训练目标检测模型,步骤如下:
第一步,构建带有标注信息的图像数据集:采集无人机空中视角下的图片,挑选出含有待搜索目标的图片对其进行标注,构建符合目标检测算法训练所需格式的标注数据集;
第二步,对目标检测深度学习模型进行训练:针对所得到的数据集,调整目标检测模型的超参数,对目标检测模型进行训练,得到无人机空中视角下可检测待搜索目标的目标检测模型;训练方法如下:
1)使用在imagenet数据集上进行预训练的darknet-53分类模型,去掉全连接层后作为特征提取部分,在特征提取部分的基础上增加特征金字塔作为多尺度特征融合的部分,最后在特征金字塔各预测层上添加1×1大小的卷积核,用来在特征金字塔各预测层每个位置进行目标分类以及目标位置的回归,在回归目标位置时,在预先设置先验框的基础上进行目标位置的回归,在计算损失函数时,使用交叉熵以及均方误差分别计算类别概率以及位置参数的损失,对损失函数中的每项采用求和操作,然后在批上取平均;
2)使用多先验框匹配的监督策略进行目标检测模型的训练,各张训练图像中的每个目标匹配特征金字塔多个预测层上的先验框来计算损失,令网络用多个预测层预测同一个目标,设置目标检测模型的基本图像输入大小,采用多尺度训练,训练过程中每隔一定批次,随机将训练图像缩放至不同大小,当训练过程中的验证指标无明显变化时,即得到无人机空中视角下的目标检测模型;
(2)将地面端电脑,移动基站与无人机部署到预定位置;
(3)在地面端电脑划定待搜索区域并设置待搜索目标,根据待搜索区域自动进行航线规划,生成航线覆盖搜索区域;
(4)由地面端电脑发布任务,无人机起飞,开始执行任务;
(5)无人机按既定航线飞行,云台相机以垂直于地面的俯仰角采集图像,将云台相机采集到的图像通过图像传输模块实时传回地面端,由地面端系统读取云台相机采集到的图像并同时利用已训练好的目标检测模型搜索目标,检测到目标后,对目标进行定位。
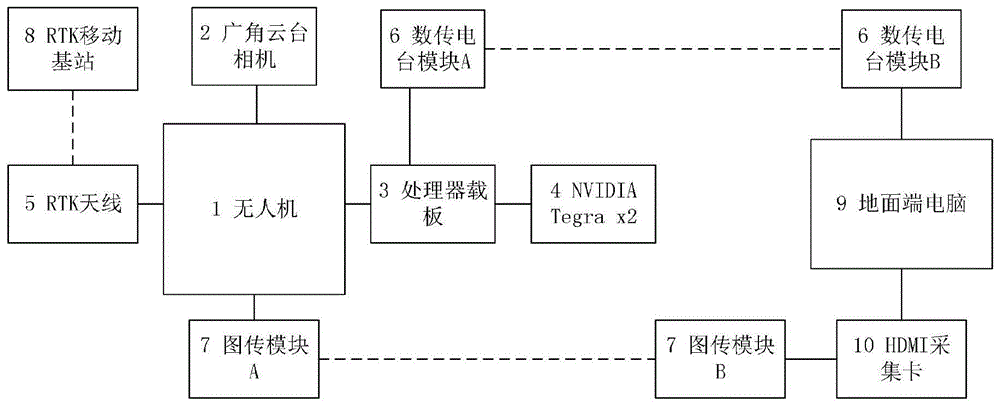
优选地,所述的无人机视觉采集系统包括有安装在无人机上的云台相机,处理器载板,天线,长距离图像传输模块a,安装在处理器载板上的处理器,安装在无人机上与处理器载板连接的长距离数据传输电台模块a,以及设置于地面的移动基站,安装在地面端电脑上的长距离数据传输模块b、hdmi视频采集卡,与hdmi视频采集卡相连的图像传输模块b。
步骤(5)的定位方法如下:通过目标边界框中心与图像中心的偏差控制无人机向目标方向定高飞行,当目标中心与图像中心的偏差小于预设阈值时,则认为无人机悬停在目标正上方,此时将无人机自身的地理坐标作为目标的地理坐标,记录此目标的唯一编号与地理坐标。
本发明的目标搜索与定位方法可应用于指定区域中多个目标的搜索,以及对目标的地理坐标进行定位,定位的相对误差小于0.1m。
附图说明
图1是本发明方法所用的无人机视觉系统架构示意图;
图2是指定搜索范围内规划出的航线示意图;
图3是视野中出现多个待定位目标时的定位策略示意图;
图4是无人机检测到视野中车辆的示意图;
表1是本实施例目标检测模型在visdrone数据集上的性能指标
具体实施方式
下面结合实施例和附图对本发明的一种基于无人机视觉系统的地面目标地理坐标定位方做出详细说明。
本发明的一种基于无人机视觉系统的地面目标地理坐标定位方法,是在无人机视觉采集系统上实现的。首先进行软硬件平台的搭建,具体包括如下两部分:
1.搭建搜索和定位平台:
实施例中所述的无人机视觉采集系统如图1所示,包括有安装在djim210rtk(real-timekinematic,实时动态)四旋翼无人机1上的禅思x5s广角云台相机2,安装在m210rtk四旋翼无人机1上的处理器载板3,安装在rtso-9003u处理器载板3上的nvidiategrax2处理器4,安装在m210rtk四旋翼无人机1上的rtk天线5,安装在m210rtk四旋翼无人机1上与处理器载板3连接的长距离数据传输电台模块a6,安装在m210rtk四旋翼无人机1上的长距离图像传输模块a7,设置于地面的rtk移动基站8,安装在地面端电脑9上的长距离数据传输模块b6、美乐威usbcapturegenhdmi视频采集卡10,与hdmi视频采集卡相连的图像传输模块b7。
平台主要分为无人机端与地面端两部分。云台相机可以通过机械防抖使无人机在飞行过程中采集的图像更加清晰稳定,云台相机上的广角镜头是为了使采集的图像具有更大的视野范围。rtk天线让无人机可以进行高精度的实时差分定位,便于无人机在目标搜索任务中对目标进行更精确的定位。
无人机通过数据传输接收地面端发送的搜索任务和各种指令,云台相机实时采集图像通过m210rtk与cendence遥控器之间的图像传输链路将图像传回地面端,然后通过美乐威capturegenhdmi图像采集卡将传回的信号采集到运行在地面端工作站,由地面端系统读取云台相机采集到的图像并使用目标检测模型进行目标检测。
二、搭建目标检测系统:
(1)模型选择
为了实现目标搜索功能,我们采用目标检测算法。针对无人机视角下的目标检测问题,考虑到无人机视角下的目标较小,在本实施例中选择了具有特征金字塔结构的yolov3模型作为目标检测算法。
yolo系列单阶段目标检测模型由rpn网络发展而来,速度要比两阶段检测目标检测模型快很多,在目前常见的设备上可以满足实时性的要求。yolov3在yolo的基础上增加了特征融合金字塔,将不同层的特征融合并在多个尺度的特征上进行预测,这使得yolov3对小目标的检测很有效。
(2)训练数据设置
无人机视角进行目标检测普遍存在一个问题,就是在俯视视角下采集的图片较正常采集的图片视野更大,目标小,目标位置随机,存在各种角度变换等。在普通视角数据集(比如coco数据集等)上训练的模型,无法很好适应俯视视角下的目标检测。我们需要在无人机视角下的目标检测数据集上训练本实例模型,以实现俯视视角下的目标检测。
visdrone数据集是由天津大学机器学习和数据挖掘实验室aiskyeye团队制作的一个无人机视角下的数据集,以满足无人机上一些重要的视觉任务的研究。数据集由视频和静态图像组成,由各个型号的无人机搭载多种摄像设备进行收集得到,数据集包括了各个中国各个地理位置下的各种场景,具有行人、机动车辆和非机动车辆等目标。数据集中一共对260余万个目标进行了包围框与类别的标注,除去这些基本的标注信息,还对每个目标的被遮挡及被截断的情况进行了标注,方便更好的进行无人机视角下的视觉算法的开发。
(3)训练模型
选择了python环境下的pytorch深度学习框架进行yolov3的搭建与训练。为了提升yolov3对目标的召回率,有效利用各个尺度预测层的输出,对实施例中的目标检测算法yolov3训练时的监督策略进行了调整。在训练阶段读入标签后给每个目标编码时,在每个输出层上各找一个和该目标的包围框具有最大交并比的先验框,将损失函数中该先验框位置的指示函数置为1,然后设定一个拒绝阈值,若指示函数被置为1的先验框与目标的交并比小于该拒绝阈值,则将该指示函数置为0。最后将目标的信息赋给指数函数为1的先验框。这样当目标的尺寸与两个输出层上的先验框尺寸都很接近时,可以用两层输出同时预测该目标,有效利用不同尺度下的特征。
通过该监督方式在visdrone数据集上进行了模型的训练,模型完成训练后的精度如表1所示。
(4)模型部署
用tensorrt推理引擎将训练好的模型部署到我们的地面端软件系统。tensorrt具有以下两个特性:一个是通过它的解析器可以将各个框架下的深度学习模型部署在我们的软件系统,第二个是它可以为模型的预测过程进行加速。首先将pytorch编写的yolov3的模型转为onnx格式的模型。然后基于onnx的计算图用yolov3生成tensorrt的推理引擎并将引擎序列化保存到本地,检测程序直接将本地的yolov3推理引擎反序列化加载到程序中用于检测。
由tensorrt部署后的yolov3在检测速度上有较大提升,显存用量有大幅的下降,所以本实施例中采用这种部署方式。地面端将云台相机采集到的图像输入到该模型,经模型推理后可得到图片中每个预设目标的类别以及目标外接矩形框的位置。
软硬件系统搭建完成后,开始执行目标搜索与定位任务。
将地面端电脑,rtk移动基站与无人机部署到预定位置。令云台相机以向下转动90°的姿态进行图像采集,即相机朝向地面且与地面垂直,简化了相机坐标系与机体坐标系换算的过程,减少了云台角度换算时所造成的误差。
起飞前在地面站设置搜索区域进行无人机的航线规划,这个搜索区域信号是由搜索区域的一系列边界点组成。首先获取当前gps坐标,计算目标搜索区域各边界点坐标的距离,选择最短距离的目标点,计算飞行角度,直线飞行到搜索区域的边界点,开始进行目标搜索和定位。为了保证能够检测到目标,固定一个高度,在与地面水平的平面内规划路径进行搜索,由于高度固定,搜索视野半径已知,使用本系统就可以根据区域生成往复式航线。在地面端电脑划定待搜索区域并设置待搜索目标,根据待搜索区域自动进行航线规划,生成航线覆盖搜索区域,所生成的航线如图2所示,为等间隔且互相平行的。
航线规划完毕并设置好待搜索目标后,由地面站发送起飞指令。无人机起飞后沿生成的往复式航线飞行,过程中始终开启着图像传输和地面端的目标检测功能。一旦地面端检测到视野中存在目标,如图4所示,地面端立即将检测到目标的信号以及目标位置通过通信模块反馈给无人机。无人机接收到目标位置之后将在当前航线上与目标点之间作临时路径变更,无人机飞到目标据航线的最小距离位置点,开始向目标位置飞行。目标中心位置与图像中心位置的偏差通过数据传输电台发送给无人机,无人机系统中的控制算法通过该偏差控制无人机向目标方向定高飞行。当目标中心与图像中心的偏差小于预设阈值时,则认为无人机悬停在目标正上方,记录此目标的id,并将无人机自身的地理坐标作为目标的地理坐标记录下来,发送到地面端。待定位完成或超时后无人机返回原规划航线,继续进行搜索。如果视野中同时出现多个目标时,按如图3所示的策略依次进行定位。由于无人机使用了rtk定位系统获取地理坐标,所以该定位方法的相对误差可到0.1m以下。
当预定区域搜索完毕后或无人机电量不足时,无人机根据当前gps坐标和起飞位置的gps坐标,计算最短路径,返航回到起飞地点,完成本次搜素定位任务。
表1本实施例目标检测模型在visdrone数据集上的性能指标
上
上面结合附图对本发明的实施方式做了详细说明,但是本发明并不限于上述实施方式,任何熟悉本技术领域的研究人员在本发明专利所公开的范围内,在不脱离本发明宗旨的前提下做出的各种变化均属于本发明专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!