一种基于子宫内膜癌的DKI序列MK图的影像组学特征处理方法与流程
本发明涉及影像医学与核医学、影像组学技术领域,具体而言,尤其涉及一种能谱ct增强碘水图影像组学术前预测肾透明细胞癌who/isup分级方法。
背景技术:
子宫内膜癌是常见的女性生殖道恶性肿瘤,不同病理学类型的内膜癌生物学行为不同,低风险型内膜癌(i型癌g1、g2级)因侵袭性弱而较少存在肿瘤淋巴管间隙浸润(lymphvascularspaceinvasion,lvsi),而高风险型内膜癌(ii型癌、i型癌g3级)常侵及深肌层且广泛存在lvsi。lvsi是导致子宫内膜癌复发、影响预后及治疗方案制定的重要因素。术前诊断性刮宫取材有限,往往影响病理类型判定的准确性,因此术前通过影像学方法评估子宫内膜癌病理风险分型尤为重要。弥散峰度成像(diffusionkurtosisimaging,dki)为mr功能成像,可更为精准的反映组织内水分子的非高斯分布弥散状态以及组织微观结构的变化,目前已应用于肝脏、肾脏、前列腺、直肠等腹部器官。本团队前期研究发现,dki作为mr非增强功能成像序列,可提供多个有效鉴别不同病理类型子宫内膜癌的定量参数,但该研究感兴趣区的放置仅仅在病灶实质区,忽略了病灶的空间异质性。影像组学分析是基于像素强度和空间分布特点,定量描述了组织异质性。
子宫内膜癌病理学风险分型与其疗效及预后密切相关。目前,术前评估子宫内膜癌病理风险分型主要依赖于诊断性刮宫,而肿瘤异质性限制了该样本的有效性,因为小组织样本不可能代表整个肿瘤。影像检查能够直观地涵盖整个肿块的信息,避免了因肿瘤异质性造成的差异。它还可以观察肿瘤外周区域,而这些区域通常不能通过外科手术切除,很难获取其病理信息。
技术实现要素:
根据上述提出的技术问题,而提供一种基于子宫内膜癌的dki序列mk图的影像组学特征处理方法。本发明将高通量的影像组学特征与子宫内膜癌病理分型信息相关联,为术前判定子宫内膜癌病理分型提供一种基于放射影像组学特征的非侵袭性的可视化方法。
本发明采用的技术手段如下:
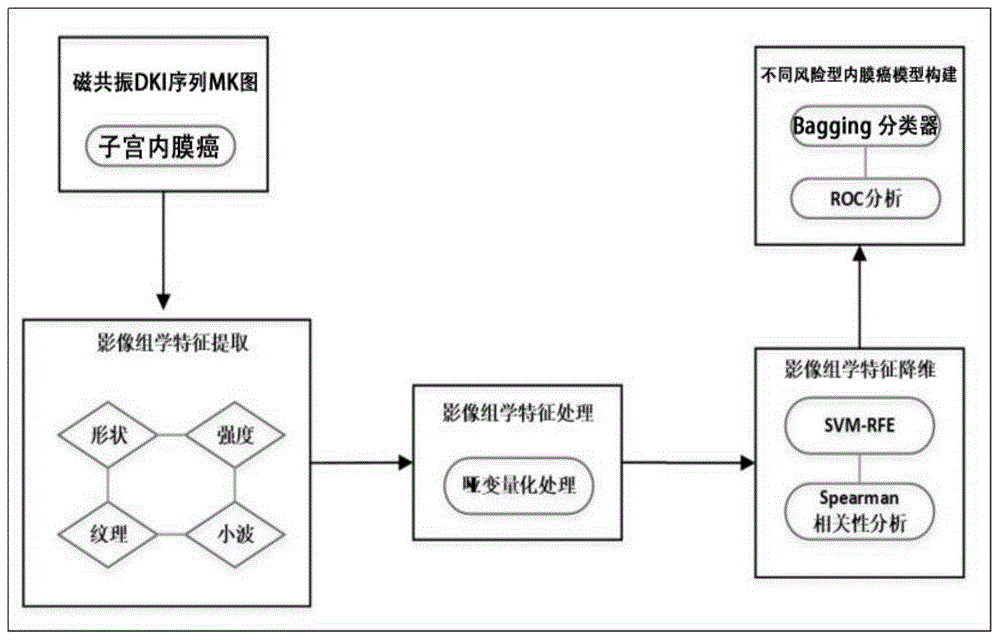
一种基于子宫内膜癌的dki序列mk图的影像组学特征处理方法,包括如下步骤:
s1、收集子宫内膜癌dki序列mk样本图像,包括高风险型子宫内膜癌dki序列mk图像和低风险型子宫内膜癌dki序列mk图像;
s2、对所述子宫内膜癌dki序列mk样本图像进行感兴趣区域勾画,提取区域内的图像特征;
s3、对所述步骤s2中提取的图像特征进行哑变量处理,生成一个取值为0或1的哑变量特征;
s4、计算spearman相关系数以0.95为阈值去除高相关性特征,再使用支持向量机递归特征消除方法进行特征选择;
s5、构建bagging分类器模型,采用roc方法对模型进行评价。
进一步地,所述步骤s3中的哑变量处理过程具体为:
s31、假设所述子宫内膜癌dki序列mk样本图像的数量为n,所述高风险型子宫内膜癌dki序列mk图像的数量为n1,低风险型子宫内膜癌dki序列mk图像的数量为n2,提取的图像特征为p;
s32、对p中的n个取值p1,...,pn进行由小至大排序,得到q1,...,qn;
s33、设置普通阈值cutoffi,且令cutoffi=qi;对qi进行离散化,令大于cutoffi的取值为1;反之,小于cutoffi的取值为0,得到新特征p’;
s34、将所述子宫内膜癌dki序列mk样本图像的类别与新特征相匹配,得到混淆矩阵ti;其中,高风险型子宫内膜癌dki序列mk图像的类别为1类,低风险型子宫内膜癌dki序列mk图像的类别为0类;
s35、根据混淆矩阵ti,计算出与其对应的敏感度sensitivityi、特异度specificityi以及和值senspei,且令:和值=敏感度+特异度;
s36、计算所有和值中的最大值,即senspek=maxsenspei,得出对应的k值、混合矩阵tk、cutoffk、sensitivityk、specificityk以及取值为0或1的哑变量特征qk。
进一步地,所述步骤s4的具体过程如下:
s41、采用相关性分析方法降低特征之间的冗余性,引用spearman相关性分析,计算相关性系数corxy,当|corxy|≥0.95时,剔除卡方检验p值较大特征;所述计算相关性系数corxy的公式如下:
其中,numberofconcordantpairs表示在混淆矩阵tk中主对角线的和;numberofdisconcordantpairs表示在混淆矩阵tk中副对角线的和;
s42、采用支持向量机递归特征消除法对影像组学特征进行筛选;具体如下:
s421、假设前列腺疾病的磁共振扩散加权样本图像数据集为:
t={(x1,y1),(x1,y1),...,(xi,yi),...,(xn,yn)}
其中,xi∈rd,yi∈{-1,+1},n为样本量,xi为第i个样本,d为影像组学特征数,s={1,2,...,d}为原始特征集合,svm模型的切分面为:
ω·x+b=0
其中,ω为法向量,b为截距;
s422、优化svm模型:
s.t.yi(ω·xi+b)≥1-ξi,i=1,2,...,n
ξi≥0,i=1,2,...,n
其中,c为惩罚参数,b为截距,ξi为松弛变量;
s423、将原始问题转化为对偶问题:
0≤αi≤c,i=1,2,...,n
其中,αi为拉格朗日乘子,解出:
第i个影像组学特征的排序准则得分的定义为:
s424、循环执行ci过程直到s为空集,再找出排序最小的组学特征p=argminkck后,更新特征集r={p,r},在原始特征集合中删去该特征p,剩下的s`=s/p即为新的特征集合。
进一步地,所述步骤s5的具体过程如下:
s51、bagging分类器默认以决策树作为底层模型,对子宫内膜癌dki序列mk总体样本进行有放回抽样bootstrap,执行k次后生成k个子样本集;
s52、对上述每一个子样本集进行模型训练,将各个子模型同等权重组合形成最终分类器;
s53、采用roc方法进行模型评价,得出auc值。
较现有技术相比,本发明具有以下优点:
1、本发明提供的基于子宫内膜癌的dki序列mk图的影像组学特征处理方法,将高通量的影像组学特征与子宫内膜癌病理分型信息相关联,为术前判定子宫内膜癌病理分型提供一种基于放射影像组学特征的非侵袭性的可视化方法。
2、本发明提供的基于子宫内膜癌的dki序列mk图的影像组学特征处理方法,对影像组学特征进行哑变量处理后模型的效果较优,具有较高的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明方法流程图。
图2为本发明实施例提供的bagging分类器流程图。
图3为本发明实施例提供的roc曲线图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
实施例
如图1所示,本发明提供了一种基于子宫内膜癌的dki序列mk图的影像组学特征处理方法,包括如下步骤:
s1、收集子宫内膜癌dki序列mk样本图像,包括高风险型子宫内膜癌dki序列mk图像和低风险型子宫内膜癌dki序列mk图像;
s2、对所述子宫内膜癌dki序列mk样本图像进行感兴趣区域勾画,提取区域内的图像特征;
s3、对所述步骤s2中提取的图像特征进行哑变量处理,生成一个取值为0或1的哑变量特征;
进一步地,作为本发明优选的实施方式
所述步骤s3中的哑变量处理过程具体为:
s31、假设所述子宫内膜癌dki序列mk样本图像的数量为n,所述高风险型子宫内膜癌dki序列mk图像的数量为n1,低风险型子宫内膜癌dki序列mk图像的数量为n2,提取的图像特征为p;
s32、对p中的n个取值p1,...,pn进行由小至大排序,得到q1,...,qn;
s33、设置普通阈值cutoffi,且令cutoffi=qi;对qi进行离散化,令大于cutoffi的取值为1;反之,小于cutoffi的取值为0,得到新特征p’;
s34、将所述子宫内膜癌dki序列mk样本图像的类别与新特征相匹配,得到混淆矩阵ti;其中,高风险型子宫内膜癌dki序列mk图像的类别为1类,低风险型子宫内膜癌dki序列mk图像的类别为0类;
s35、根据混淆矩阵ti,计算出与其对应的敏感度sensitivityi、特异度specificityi以及和值senspei,且令:和值=敏感度+特异度;
s36、计算所有和值中的最大值,即senspek=maxsenspei,得出对应的k值、混合矩阵tk、cutoffk、sensitivityk、specificityk以及取值为0或1的哑变量特征qk。
s4、计算spearman相关系数以0.95为阈值去除高相关性特征,再使用支持向量机递归特征消除方法进行特征选择;
进一步地,作为本发明优选的实施方式
步骤s4的具体过程如下:
s41、采用相关性分析方法降低特征之间的冗余性,引用spearman相关性分析,计算相关性系数corxy,当|corxy|≥0.95时,剔除卡方检验p值较大特征;所述计算相关性系数corxy的公式如下:
其中,numberofconcordantpairs表示在混淆矩阵tk中主对角线的和;numberofdisconcordantpairs表示在混淆矩阵tk中副对角线的和;
s42、采用支持向量机递归特征消除法对影像组学特征进行筛选;具体如下:
s421、假设前列腺疾病的磁共振扩散加权样本图像数据集为:
t={(x1,y1),(x1,y1),...,(xi,yi),...,(xn,yn)}
其中,xi∈rd,yi∈{-1,+1},n为样本量,xi为第i个样本,d为影像组学特征数,s={1,2,...,d}为原始特征集合,svm模型的切分面为:
ω·x+b=0
其中,ω为法向量,b为截距;
s422、优化svm模型:
s.t.yi(ω·xi+b)≥1-ξi,i=1,2,...,n
ξi≥0,i=1,2,...,n
其中,c为惩罚参数,b为截距,ξi为松弛变量;
s423、将原始问题转化为对偶问题:
0≤αi≤c,i=1,2,...,n
其中,αi为拉格朗日乘子,解出:
第i个影像组学特征的排序准则得分的定义为:
s424、循环执行ci过程直到s为空集,再找出排序最小的组学特征p=argminkck后,更新特征集r={p,r},在原始特征集合中删去该特征p,剩下的s`=s/p即为新的特征集合。
s5、构建bagging分类器模型,采用roc方法对模型进行评价。
进一步地,作为本发明优选的实施方式
如图2所示,步骤s5的具体过程如下:
s51、bagging分类器默认以决策树作为底层模型,对子宫内膜癌dki序列mk总体样本进行有放回抽样bootstrap,执行k次后生成k个子样本集;
s52、对上述每一个子样本集进行模型训练,将各个子模型同等权重组合形成最终分类器;
s53、采用roc方法进行模型评价,得出auc值。随后采用delong’stest对roc进行显著性检验以评价auc统计学意义。如图3所示,为本实施例提供的roc曲线图,进而得出roc曲线下面积auc值;与表1roc曲线下auc值及其诊断效果做对比。
表1roc曲线下auc值及其诊断效果
研究的结论为对影像组学特征进行哑变量化后模型的效果较优,具有较高的准确性。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!