一种播放控制方法及装置与流程
本申请涉及计算机技术领域,尤其涉及一种播放控制方法及装置。
背景技术:
目前,很多应用程序(application,app)都提供文本转语音(texttospeech,tts)的朗读功能,例如,读书功能,便于用户使用,但是现有技术中,在朗读过程中只能使用一种音色的声音,在整个朗读过程中均使用一种音色,降低了用户的听觉感受,并且如果需要切换朗读音色,则需要用户手动切换,效率低,同时用户体验较差。
技术实现要素:
本申请实施例提供一种播放控制方法及装置,以实现播放过程中音色的自动切换,提高效率。
本申请实施例提供的具体技术方案如下:
一种播放控制方法,包括:
根据预设切割方式,将待播放文本切割为各待播放片段,所述待播放片段包括类型为对话的待播放片段以及类型为非对话的待播放片段;
确定所述类型为对话的待播放片段对应的角色名称;
确定所述角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定所述角色名称对应的播放音色;
以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段,具体包括:
按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段。
可选的,所述预设标识符为双引号,包括左双引号和右双引号,则按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段,具体包括:
确定所述待播放文本的文本长度;
依次扫描所述待播放文本的各字符,并记录当前扫描累积的字符长度;
判断当前扫描的字符是否为左双引号或右双引号,若确定所述当前扫描的字符为左双引号或右双引号,则进行切割,将上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,或将上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,直至确定当前扫描累积的字符长度不小于所述文本长度,获得切割后的各待播放片段,其中,所述上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为分句,所述上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为引用句;
确定所述各待播放片段的类型为对话或非对话。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段,具体包括:
根据预设的语法规则,对待播放文本进行解析,按照空行标识符,将所述待播放文件切割为各段落;
按照句号标识符,分别将所述各段落切割为各句子,并按照双引号标识符和分句标识符,分别将所述各句子切割为各引用句和各分句;
将所述各引用句和各分句确定为切割后的各待播放片段,并确定所述各待播放片段的类型为对话或非对话。
可选的,进一步包括:
采用自然语言处理方法,分别构建所述各待播放片段的语法树,其中,所述语法树中至少表征有待播放片段中每个分词的词性、语法关系;
基于预设角色词库和所述每个分词的词性,从所述各待播放片段中匹配获得角色名称集合,其中,所述角色名称集合中包括人物名称、关系名词和非人物名称。
可选的,确定所述各待播放片段的类型为对话或非对话,具体包括:
若确定切割为引用句的待播放片段符合预设非对话内容条件,则确定对应待播放片段的类型为非对话,若确定不符合,则确定对应待播放片段的类型为对话;
根据切割为分句的待播放片段的语法树和所述角色名称集合,分别判断所述切割为分句的待播放片段是否符合对话语法条件,若确定符合,则确定对应待播放片段的类型为对话,若确定不符合,则确定对应待播放片段的类型为非对话。
可选的,确定所述类型为对话的待播放片段对应的角色名称,具体包括:
根据所述类型为对话的待播放片段的语法树,若确定所述类型为对话的待播放片段的语法树中存在主谓语法关系,并所述主谓语法关系的主语在所述角色名称集合中,则确定所述类型为对话的待播放片段的角色名称为所述主语;或,
若确定所述类型为对话的待播放片段中存在第三人称指代关系词语,则确定所述类型为对话的待播放片段的角色名称为在所述类型为对话的待播放片段之前最近的角色名称。
可选的,确定所述角色名称对应的角色类别,具体包括:
将所述类型为对话的待播放片段的角色名称输入到已训练的第一分类模型中,确定所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别;或,
从所述待播放文本中获取与所述类型为对话的待播放片段的角色名称关联的多个形容词,并将所述角色名称的多个形容词输入到已训练的第二分类模型中,输出所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别。
可选的,所述角色类别表示角色性别,则以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段,具体包括:
按照所述各待播放片段在所述待播放文本中的顺序,依次播放所述各待播放片段时,若确定当前的待播放片段的类型为对话并角色类别为女性角色,则以第一女性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为对话并角色类别为男性角色,则以第一男性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为非对话,则以设定的第二女性播放音色或第二男性播放音色播放所述当前的待播放片段。
可选的,所述第二女性播放音色或第二男性播放音色为默认的不同于所述第一女性播放音色和所述第一男性播放音色的播放音色,或,所述第二女性播放音色或第二男性播放音色为根据用户从预设的候选播放音色中选择的播放音色。
一种播放控制装置,包括:
切割模块,用于根据预设切割方式,将待播放文本切割为各待播放片段,所述待播放片段包括类型为对话的待播放片段以及类型为非对话的待播放片段;
第一确定模块,用于确定所述类型为对话的待播放片段对应的角色名称;
第二确定模块,用于确定所述角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定所述角色名称对应的播放音色;
播放模块,用于以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段时,切割模块具体用于:
按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段。
可选的,所述预设标识符为双引号,包括左双引号和右双引号,则按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段时,切割模块具体用于:
确定所述待播放文本的文本长度;
依次扫描所述待播放文本的各字符,并记录当前扫描累积的字符长度;判断当前扫描的字符是否为左双引号或右双引号,若确定所述当前扫描的字符为左双引号或右双引号,则进行切割,将上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,或将上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,直至确定当前扫描累积的字符长度不小于所述文本长度,获得切割后的各待播放片段,其中,所述上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为分句,所述上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为引用句;
确定所述各待播放片段的类型为对话或非对话。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段时,切割模块具体用于:
根据预设的语法规则,对待播放文本进行解析,按照空行标识符,将所述待播放文件切割为各段落;
按照句号标识符,分别将所述各段落切割为各句子,并按照双引号标识符和分句标识符,分别将所述各句子切割为各引用句和各分句;
将所述各引用句和各分句确定为切割后的各待播放片段,并确定所述各待播放片段的类型为对话或非对话。
可选的,进一步包括,解析模块,用于:
采用自然语言处理方法,分别构建所述各待播放片段的语法树,其中,所述语法树中至少表征有待播放片段中每个分词的词性、语法关系;
基于预设角色词库和所述每个分词的词性,从所述各待播放片段中匹配获得角色名称集合,其中,所述角色名称集合中包括人物名称、关系名词和非人物名称。
可选的,确定所述各待播放片段的类型为对话或非对话时,切割模块具体用于:
若确定切割为引用句的待播放片段符合预设非对话内容条件,则确定对应待播放片段的类型为非对话,若确定不符合,则确定对应待播放片段的类型为对话;
根据切割为分句的待播放片段的语法树和所述角色名称集合,分别判断所述切割为分句的待播放片段是否符合对话语法条件,若确定符合,则确定对应待播放片段的类型为对话,若确定不符合,则确定对应待播放片段的类型为非对话。
可选的,确定所述类型为对话的待播放片段对应的角色名称时,第一确定模块具体用于:
根据所述类型为对话的待播放片段的语法树,若确定所述类型为对话的待播放片段的语法树中存在主谓语法关系,并所述主谓语法关系的主语在所述角色名称集合中,则确定所述类型为对话的待播放片段的角色名称为所述主语;或,
若确定所述类型为对话的待播放片段中存在第三人称指代关系词语,则确定所述类型为对话的待播放片段的角色名称为在所述类型为对话的待播放片段之前最近的角色名称。
可选的,确定所述角色名称对应的角色类别时,第二确定模块具体用于:
将所述类型为对话的待播放片段的角色名称输入到已训练的第一分类模型中,确定所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别;或,
从所述待播放文本中获取与所述类型为对话的待播放片段的角色名称关联的多个形容词,并将所述角色名称的多个形容词输入到已训练的第二分类模型中,输出所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别。
可选的,所述角色类别表示角色性别,则以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段时,播放模块具体用于:
按照所述各待播放片段在所述待播放文本中的顺序,依次播放所述各待播放片段时,若确定当前的待播放片段的类型为对话并角色类别为女性角色,则以第一女性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为对话并角色类别为男性角色,则以第一男性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为非对话,则以设定的第二女性播放音色或第二男性播放音色播放所述当前的待播放片段。
可选的,所述第二女性播放音色或第二男性播放音色为默认的不同于所述第一女性播放音色和所述第一男性播放音色的播放音色,或,所述第二女性播放音色或第二男性播放音色为根据用户从预设的候选播放音色中选择的播放音色。
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一种播放控制方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一种播放控制方法的步骤。
本申请实施例中,根据预设切割方式,将待播放文本切割为各待播放片段,并确定待播放片段的类型为对话和非对话,确定类型为对话的待播放片段对应的角色名称,确定角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定角色名称对应的播放音色,进而以类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照各播放片段在待播放文本中的顺序依次播放各待播放片段,这样,将待播放文本切割为更小的待播放片段,并区分对话和非对话,针对类型为对话的待播放片段,以不同角色类别确定不同的播放音色,从而可以实现在播放过程中自动切换不同的播放音色,不需要人工手动切换,提高了效率,并且由于播放音色与角色类别相关,提升了播放效果,可以使得用户很容易辨别对话所属人物主体,更具有代入感。
附图说明
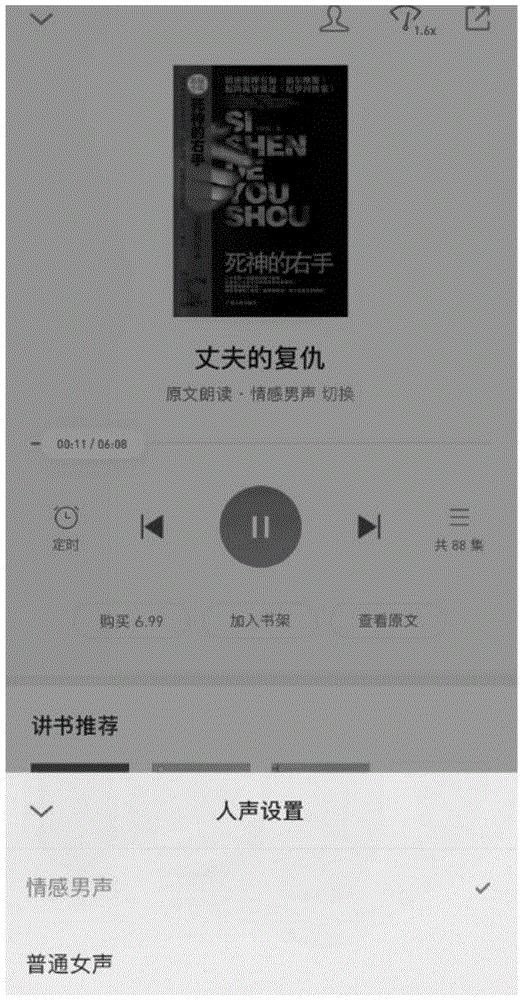
图1为现有技术中音色选择界面示意图;
图2为本申请实施例中播放控制方法流程图;
图3为本申请实施例中待播放文本切割原理示意图;
图4为申请实施例中语法树构建原理示意图;
图5为申请实施例中切割为分句的待播放片段的类型为对话的示意图;
图6为本申请实施例中一种待播放文本切割方法流程图;
图7为本申请实施例中播放控制装置结构示意图;
图8为本申请实施例中电子设备的结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,并不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为便于对本申请实施例的理解,下面先对几个概念进行简单介绍:
文本:本申请实施例中文本包括但不限于小说、剧本、童话故事等文学文本,也可以为新闻等其它任何内容的文本。
待播放片段的类型:本申请实施例中待播放片段的类型主要包括对话和非对话类型,对话类型表示待播放片段的是由某角色所说的文本,可以理解为人物对话内容,非对话类型表示待播放片段不是由角色说的文本,例如为旁白等内容。
角色名称:本申请实施例中表示角色的姓名。
角色类别:本申请实施例中角色类别表示角色性别,包括女性角色和男性角色,当然对于角色类别的划分并不进行限制,目的是为了针对不同角色类别,可以使用不同播放音色进行播放。
ll(1)文法:若文法g的预测分析表m中不含有多重定义项,则称g为ll(1)文法,其中,第一个l代表从左向右扫描输入符号串,第二个l代表产生最左推导,1代表在分析过程中执行每一步推导都要向前查看一个输入符号,只需向右看一个符号便可决定如何推倒即选择哪个产生式(规则)进行推导。ll(1)文法既不是二义性的,也不含左递归,对ll(1)文法的所有文本均可进行确定的自顶向下的语法分析。
目前,很多应用程序(application,app)都提供文本转语音(texttospeech,tts)的朗读功能,但是现有技术在朗读过程中只能使用一种音色的声音,例如,参阅图1所示,为现有技术中音色选择界面示意图,从人声设置中选择一种音色后,全文朗读只能用一种音色的声音,并且如果用户需要更换音色,则只能手动切换,降低了效率。
本申请实施例中,在研究过程中发现,对于某待播放文本,例如小说,通常是包含不同人物对话,现有技术中在朗读过程中不能自动根据角色性别自动切换相匹配的音色,因此,本申请实施例中为解决上述问题,提供了一种播放控制方法,可以实现播放过程中音色的自动切换,而不是全文朗读时仅能使用一种音色,具体地,将待播放文本切割为各待播放片段,确定各待播放片段的类别为对话或非对话,并确定类型为对话的待播放片段对应的角色名称,确定角色名称对应的角色类别,从而确定出角色名称对应的播放音色,进而以不同的播放音色播放各待播放片段,这样,在播放过程中,可以区分对话和非对话,并针对对话确定出相应的角色类别,可以根据对话的角色类别自动切换对应的播放音色,不需要人工手动切换音色,提高了效率,并且可以让用户能更加清楚地辨别对话和非对话的待播放片段,以及对话所属的角色类别,可以实现具有更强代入感的播放效果。
基于上述实施例,对本申请实施例中的播放控制方法进行说明,参阅图2所示,为本申请实施例中播放控制方法流程图,该方法包括:
步骤200:根据预设切割方式,将待播放文本切割为各待播放片段,待播放片段包括类型为对话的待播放片段以及类型为非对话的待播放片段。
本申请实施例中,待播放文本例如为小说,并不进行限制,为了对待播放文本在播放时切换不同的播放音色,需要切割为更小的待播放片段进行分析。
执行步骤200时,可以有以下几种实施方式:
第一种实施方式:根据预设切割方式,将待播放文本切割为各待播放片段,具体包括:按照预设标识符,以标识符为分割点,分别将待播放文本切割为各待播放片段。
其中,预设标识符为双引号,包括左双引号和右双引号,这是因为,通常若是人物所说的话,即类型为对话的待播放片段,是以双引号引用起来的,因此可以根据双引号来对待播放文本进行切割,确定出对话和非对话类型的待播放片段。
具体地,按照预设标识符,以标识符为分割点,分别将待播放文本切割为各待播放片段,包括:
s1、确定待播放文本的文本长度。
s2、依次扫描待播放文本的各字符,并记录当前扫描累积的字符长度。
s3、判断当前扫描的字符是否为左双引号或右双引号,若确定当前扫描的字符为左双引号或右双引号,则进行切割,将上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,或将上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,直至确定当前扫描累积的字符长度不小于文本长度,获得切割后的各待播放片段,其中,上一个右双引号字符的下一个字符到当前扫描的字符的上一个字符之间的文本的待播放片段为分句,上一个左双引号字符的下一个字符到当前扫描的字符的上一个字符之间的文本的待播放片段为引用句。
s4、确定各待播放片段的类型为对话或非对话。
这样,根据双引号将待播放文本划分为了双引号包含的待播放片段,称为引用句,非双引号包含的待播放片段,称为分句,采用双引号切割方式实现简单快捷。
第二种实施方式:根据预设切割方式,将待播放文本切割为各待播放片段,具体包括:
s1、根据预设的语法规则,对待播放文本进行解析,按照空行标识符,将待播放文件切割为各段落。
s2、按照句号标识符,分别将各段落切割为各句子,并按照双引号标识符和分句标识符,分别将各句子切割为各引用句和各分句。
通常句号表示一个句子的终止,可以采用句号分割为句子,双引号通常可以为角色说话时使用,采用双引号划分为引用句,并且分句标识符为除句号、双引号的其它符号,例如,逗号、问号、分号等。
s3、将各引用句和各分句确定为切割后的各待播放片段,并确定各待播放片段的类型为对话或非对话。
本申请实施例中,可以将待播放文本类比编程语言,使用语法规则例如ll(1)文法进行解析,解析后可以将一个待播放文本划分为多个分句和引用句的组合,参阅图3所示,为本申请实施例中待播放文本切割原理示意图,如图3所示,可以将待播放文本先切割为段落,再将段落切割为句子,最后将句子切割为分句和引用句。
进一步地,基于上述两种实施方式,切割为引用句和分句后,并不能直接将为引用句的待播放片段的类型确定为对话,这是因为在小说或其它文本中,语法的使用并不是特别严谨,不同的作者可能有不同的文法或写作习惯,有些引用句可能并不是对话而仅是一些特定名词,而分句也不一定不是对话,可能是作者习惯不使用双引号括起来,因此针对切割的各引用句和各分句,还需要进一步筛选确定其类型为对话或非对话。
为说明本申请实施例中确定各待播放片段的类型为对话或非对话的具体实施方式,下面先对待播放片段的语法树解析进行说明。具体地,本申请实施例中,为了进行待播放片段的类型确定和对应的角色名称确定,还提供了一种实施方式,包括:
1)采用自然语言处理方法,分别构建各待播放片段的语法树,其中,语法树中至少表征有待播放片段中每个分词的词性、语法关系。
本申请实施例中,可以采用nlp中依存语法(dependencyparsing,dp)分析方法对各待播放片段进行解析,获得各待播放片段分别对应的语法树,具体语法树构建方法,本申请实施例中并不进行限制。
例如,参阅图4所示,为申请实施例中语法树构建原理示意图,待播放片段为“梁格珍不去追究张恪在昏迷不醒时到底梦见了什么”,采用nlp中dp分析方法,每个待播放片段可以分为多个分词,例如图4中每个小方块为一个分词,分为“梁格珍”、“不”、“去”等分词,并且还可以确定出每个分词的词性,例如人名(nr)、副词(d)、动词(v)、介词(p)、其它专有名词(nz)、名语素(ng)、助词(u)、代词(r),具体可以根据预设词性编码表确定每个分词的词性,以及还可以确定待播放片段中存在的语法关系,例如主谓语法结构、动宾语法结构等,一个待播放片段中可能存在多个语法关系,从而通过词性和语法关系的解析,可以构建语法树,其中,对于一个待播放片段的语法树,有且仅有一个根节点,语法树中所有节点也仅有一条路径指向根节点。
2)基于预设角色词库和每个分词的词性,从各待播放片段中匹配获得角色名称集合,其中,角色名称集合中包括人物名称、关系名词和非人物名称。
具体地,可以根据分词的词性,筛选出其中的人名即人物名称,但通常对话的角色除了人物名称以外,还可能是其它名词,例如关系名词,如哥哥、姐姐等,动物名称,如一些动画小说,可能是牛、羊等,因此对于这部分名词,采用预设角色词库进行匹配,在角色词库内名词可以认为是角色名称。
进一步地,在待播放文本中同一角色可能会被提取为不同角色名称,例如,李彦、李彦能,因为“能”不但可以作为人名,它本身还拥有自己的词性,这两个角色名称可能是表示同一个角色,则可以解析完所有待播放片段后,再综合矫正所有角色名称,具体地,可以依次处理每个角色名称,判断角色名称是否是其它角色名称的前缀,若是则保留最小前缀的角色名称,若否则直接保留该角色名称,最终获得矫正后的角色名称集合。
这样,可以解析获得各待播放片段的语法树,并获得角色名称集合,从而可以基于语法树和角色名称集合,来确定待播放片段的类型,以及类型为对话的待播放片段对应的角色名称。
基于上述实施例,则确定各待播放片段的类型为对话或非对话时,本申请实施例中提供了一种可能的实施方式:
1)若确定切割为引用句的待播放片段符合预设非对话内容条件,则确定对应待播放片段的类型为非对话,若确定不符合,则确定对应待播放片段的类型为对话。
本申请实施例中,针对为引用句的待播放片段,即用双引号括起来的内容,按照汉语常规语法双引号括起来内容可以表示对话、特殊指代、强调等,即不仅仅是对话,因此需要对引用句再进行筛选,可以根据实际经验设置非对话内容条件,过滤掉符合非对话内容条件的引用句,不符合非对话内容条件的引用句的待播放片段的类型即为对话。
其中,预设非对话内容条件,例如是为引用句的待播放片段的内容中只存在一个词,并词性不是语气助词,例如“苹果”,用双引号括起来仅表示强调,又例如,预设非对话内容条件是为引用句的待播放片段的内容中没有标点,例如人名或地名等,引用时不会有标点。
当然也可以设置其它非对话内容条件,本申请实施例中并不进行限制。
2)根据切割为分句的待播放片段的语法树和角色名称集合,分别判断切割为分句的待播放片段是否符合对话语法条件,若确定符合,则确定对应待播放片段的类型为对话,若确定不符合,则确定对应待播放片段的类型为非对话。
本申请实施例中,针对为分句的待播放片段从中确定出类型为对话和非对话的,主要是考虑到作者没有采用标准的语法规则来撰写,对于对话可能会省略双引号,本申请实施例中可以采用对话动词来判断对话。
例如,参阅图5所示,为申请实施例中切割为分句的待播放片段的类型为对话的示意图,可知,梁格珍说张恪在昏迷不醒时到底梦见了什么,以及张恪在昏迷不醒时到底梦见了什么梁格珍说,这两句虽然都没有采用双引号括起来,但是可知这两句都是对话,通过分析可知对话中通常是包含对话动词的,例如“说”,因此,对于切割为分句的待播放片段,可以根据经验和实际情况设置对话语法条件,从而从中确定为对话和非对话。
其中,设置的对话语法条件,可以有以下几种:
a、语法树的根节点是对话动词,即是对话动词则确定类型为对话,否则确定类型为非对话。
b、存在主语是角色名称的主谓语法结构,具体地,可以根据待播放片段的语法树,判断是否存在主谓语法结构,并根据确定的角色名称集合,确定主谓语法结构的主语是否是角色名称,若是则确定其类型为对话,否则确定其类型为非对话。
c、上一个待播放片段的语法树中除了主谓语法结构对应的子树外不存在其它子树,并子树结束符是冒号。即考虑待播放文本的上下文,判断待播放片段中除了主谓语法结构对应的子树外是否存在其它子树,若不存在,则判断子树结束符是否是冒号,若是冒号,则下一个待播放片段的类型是对话,否则判断下一个待播放片段的类型是非对话。
d、待播放片段中存在主谓语法结构对应的子树,并且该待播放片段对应的角色名称是该主谓语法结构中的主语。即在基于该对话语法条件判断待播放片段的类型时,也是需要确定待播放片段的角色名称的,在该过程中有些待播放片段的角色名称可以是中间结果,在后续确定所有待播放片段的角色名称时,对已确定出角色名称的待播放片段就无需再确定了。
当然本申请实施例中也并不仅限于上述几种对话语法条件,也可以设置其它对话语法条件,本申请实施例中并不进行限制。
这样,通过设置条件,确定各待播放片段为对话或非对话类型,从而可以针对类型为对话的待播放片段和类型为非对话的待播放片段分别进行分析,以确定不同的播放音色。
步骤210:确定类型为对话的待播放片段对应的角色名称。
本申请实施例中,将待播放文本切割为多个待播放片段,确定出对话类型的待播放片段,并获得角色名称集合,进而需要将角色名称和类型为对话的待播放片段进行关联,即确定出类型为对话的待播放片段是由哪个角色名称说的。
执行步骤210时,可以有以下几种方式:
第一种方式:根据类型为对话的待播放片段的语法树,若确定类型为对话的待播放片段的语法树中存在主谓语法关系,并主谓语法关系的主语在角色名称集合中,则确定类型为对话的待播放片段的角色名称为该主语。
也就是说,针对待播放片段中存在角色名称的情况,可以根据语法树,以角色名称为起点向树的根部方向遍历,确定如果存在主谓语法关系,则可以确定该角色名称为该待播放片段对应的角色名称。
第二种方式:若确定类型为对话的待播放片段中存在第三人称指代关系词语,则确定类型为对话的待播放片段的角色名称为在类型为对话的待播放片段之前最近的角色名称。
通常对于人物的指代关系是使用第三人称指代关系词语,例如他、她等,若待播放片段中存在第三人称指代关系词语,则该待播放片段对应的角色名称可以为在待播放文本中之前邻近的角色名称,例如,针对待播放文本的某小部分:…小红一脸不屑,她说今天到这里就结束吧…,其中,通过切割并确定类型后,“小红一脸不屑”为类型为非对话的待播放片段,“她说今天到这里就结束吧”为类型为对话的待播放片段,通过判断“她说今天到这里就结束吧”中存在第三人称指代关系词语“她”,则去找该待播放片段之前的最邻近的角色名称,可知为“小红”,则可知该播放片段的角色名称为小红。
另外,本申请实施例中并不仅限于上述两种方式,也可以采用其它方式确定类型为对话的待播放片段对应的角色名称。例如,根据一些对话的特定句式的特点,来设置确定方式。
例如,1)交替句式:主要是单个段落是对话,各对话类型的待播放片段的角色名称呈交替规律。
例如:宋彦哲瞪眼:“我看你再甩一下试试?”
艾米米囧红了脸小声嘀咕:“我们可是签了协议的。”
“是你先违约的。”
“我哪里违约了?”
2)前后句式:主要是单个段落是对话,角色名称存在于上一句或下一句中。
例如,尹夏沫径直转身走向庭院四周散放的花盆,边洒水,边淡淡地说:
“你还不值得。”
“嗯,谢谢姐!”
小澄抬头对她笑。
步骤220:确定角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定角色名称对应的播放音色;以类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照各播放片段在待播放文本中的顺序依次播放各待播放片段。
执行步骤220时,具体包括:
s1、确定角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定角色名称对应的播放音色。
具体可以有以下几种实施方式:
第一种实施方式:将类型为对话的待播放片段的角色名称输入到已训练的第一分类模型中,确定角色名称属于各预设角色类别的分值,并根据角色名称属于各预设角色类别的分值,确定角色名称的角色类别。
本申请实施例中,以角色类别为角色性别为例,可以预先采用男性和女性的姓名进行训练,将姓名拆分为不同的字以及组合,通过机器学习训练第一分类模型,用于确定不同字组合属于预设角色类别的分值。
从而将各类型为对话的待播放片段的角色名称输入到第一分类模型中,可以获得属于各预设角色类别的分值,将分值最大对应的角色类别作为该角色名称的角色类别。
第二种实施方式:从待播放文本中获取与类型为对话的待播放片段的角色名称关联的多个形容词,并将角色名称的多个形容词输入到已训练的第二分类模型中,输出角色名称属于各预设角色类别的分值,并根据角色名称属于各预设角色类别的分值,确定角色名称的角色类别。
以角色类别表示角色性别为例,即本申请实施例中考虑到对于男性或女性的形容词通常是不同的,因此,还可以通过不同的形容词和形容词的性别标注,训练获得第二分类模型,从而从待播放文本中获取角色名称关联的多个形容词,例如,很漂亮、温柔等,输入到第二分类模型中,可以获得属于各预设角色类别的分值,将分值最大对应的角色类别作为该角色名称的角色类别。
本申请实施例中除了上述两种方式外,还可以采用其它方式,并不进行限制,例如通过第三人称指代词语来确定,如“她”表示女性,“他”表示男性。
s2、以类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照各播放片段在待播放文本中的顺序依次播放各待播放片段。
其中,角色类别表示角色性别。
进一步地,本申请实施例中,确定出角色名称对应的播放音色后,并根据预设的角色类别和播放音色映射关系,建立角色名称、角色性别、播放音色的对应关系表,参阅表1所示,为本申请实施例中角色名称与播放音色、角色类别对应关系表。
表1.
基于表1,还可以建立各待播放片段与角色名称对应关系表,本申请实施例中将待播放文本切割为多个待播放片段,类型为对话的待播放片段有对应的角色名称,类型为非对话的待播放片段是没有对应角色名称的,可以不进行确定,在后续直接以设定的第二女性播放音色或第二男性播放音色播放即可,这里建立对应关系表时,还可以将类型为非对话的待播放片段的角色名称称为无名氏,则参阅表2所示,为本申请实施例中待播放片段与角色名称对应关系表。
表2.
本申请实施例中,整个待播放文本根据顺序可以分割为一个数组结构,数组中每个元素的结构可以如表2所示,这样,通过表2和表1的映射,就可以确定出每个待播放片段的播放音色,从而按照各待播放片段在待播放文本中的顺序,以相应的播放音色依次播放即可。
具体地,以类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照各播放片段在所述待播放文本中的顺序依次播放各待播放片段,包括:
按照各待播放片段在待播放文本中的顺序,依次播放各待播放片段时,若确定当前的待播放片段的类型为对话并角色类别为女性角色,则以第一女性播放音色播放当前的待播放片段,若确定当前的待播放片段的类型为对话并角色类别为男性角色,则以第一男性播放音色播放当前的待播放片段,若确定当前的待播放片段的类型为非对话,则以设定的第二女性播放音色或第二男性播放音色播放当前的待播放片段。
其中,第二女性播放音色或第二男性播放音色为默认的不同于第一女性播放音色和第一男性播放音色的播放音色,或,第二女性播放音色或第二男性播放音色为用户从预设的候选播放音色中选择的播放音色。
这样,对于女性角色说的内容,以第一女性播放音色播放,对于男性角色说的内容,以第一男性播放音色播放,对于非对话的待播放片段,以默认的或用户选择的第二女性播放音色或第二男性播放音色播放,实现了在播放待播放文本过程中,自动切换播放音色,并能够根据对话的角色性别,自动切换男性播放音色或女性播放音色。
本申请实施例中,将待播放文本切割为各待播放片段,并确定其类型为对话或非对话,确定类型为对话的待播放片段对应的角色名称,确定角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定角色名称对应的播放音色,从而以类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照各播放片段在待播放文本中的顺序依次播放各待播放片段,这样,在播放一段文本时,可以根据待播放文本切割的各待播放片段的角色类别,以不同播放音色进行播放,实现在播放过程中自动切换播放音色的效果,不需要人工进行切换,提高了效率,并且播放音色与角色类别相关,提升了播放效果,使得用户在收听过程中更有代入感,能直观的感受对话推动情节的过程。
为更好地理解上述实施例中步骤200的第一种实施方式按照预设标识符,以标识符为分割点,分别将待播放文本切割为各待播放片段的执行过程,下面以具体实施场景进行说明,其中,标识符为双引号,包括左双引号和右双引号,通过依次扫描待播放文本的各个字符,从而将待播放文本切割为一个个小的待播放片段,参阅图6所示,为本申请实施例中一种待播放文本切割方法流程图,具体包括:
步骤600:初始化参数:index=0,length=文本长度,array初始化为一个空的数组。
其中,length为待播放文本的文本长度,index表示扫描的字符的位置,取值范围为[0,length)。
步骤601:判断是否index<length,若是,则执行步骤602,否则,则执行步骤619。
步骤602:设置参数:i=index。
步骤603:判断是否i<length,若是,则执行步骤605,否则,则执行步骤604。
步骤604:将[index,i)之间的文本作为一个元素加入到array数组中。
即一个元素为一个待播放片段,[index,i)之间的文本为一个待播放片段。
步骤605:扫描待播放文本的第i个字符。
步骤606:判断第i个字符是否为左双引号,若是,则执行步骤608,否则,则执行步骤607。
步骤607:i增加1:i=i+1。
步骤608:将[index,i)之间的文本作为一个元素加入到array数组中。
步骤609:index设置为length-1和i+1中的较小值:index=min(length-1,i+1)。
步骤610:判断是否index<length,若是,则执行步骤611,否则,则执行步骤619。
步骤611:设置参数:i=index。
步骤612:判断是否i<length,若是,则执行步骤614,否则,则执行步骤613。
步骤613:将[index,i)之间的文本作为一个元素加入到array数组中。
步骤614:扫描待播放文本的第i个字符。
步骤615:判断第i个字符是否为右双引号,若是,则执行步骤617,否则,则执行步骤616。
步骤616:i增加1:i=i+1。
步骤617:将[index,i)之间的文本作为一个元素加入到array数组中。
步骤618:index设置为length-1和i+1中的较小值:index=min(length-1,i+1),并继续执行步骤601。
步骤619:结束。
这样,通过左双引号和右双引号判断,将左双引号和右双引号之间的文本切割为一个待播放片段,即为引用句,上一个右双引号的下一个字符到当前左双引号的上一个字符之间的文本切割为一个待播放片段,以及上一个左双引号字符的下一个字符到当前右双引号字符的上一个字符之间切割为一个待播放片段,这两类待播放片段为分句,通过切割将待播放文本切割为更小的待播放片段,从而后续可以对切割出的各待播放片段确定对应的角色名称,并确定角色名称对应的角色类别、播放音色等,处理为一个具有对应角色名称的数据结构,加入到数组中,这样即可以将一个待播放文本处理为一个具有特定数据结构的数组。
基于上述实施例,下面采用具体应用场景对本申请实施例中的播放控制方法进行说明,以待播放文本为《1q84》中的部分内容为例,该部分内容为:
“我刚才洗了个澡。”她对着呆立在那的天吾,像想起了一件大事般严肃地说,“用了你的香波和护发素。”
天吾点点头,喘了一口气,终于从门把手上松开手,上了锁。香波和护发素?他抬脚向前迈去,离开了门边。
“后来电话铃响过吗?”他问。
“一次也没响过。”深绘里答道,微微摇了摇头。
天吾走到窗边,把窗帘拉开一条缝,向外望去。从三楼窗口看到的风景没有特别的变化。看不见可疑的人影,也没有停放可疑的汽车。
本申请实施例中,针对该待播放文本,可以切割为多个待播放片段,并确定其类型为对话或非对话,确定类型为对话的待播放片段对应的角色名称,确定角色名称对应的角色类别,以及确定角色名称对应的播放音色,从而可以以对应的播放音色,播放各待播放片段,实现播放音色的自动切换,其中,本申请实施例中可以将一个待播放文本处理为一个具有特定数据结构的数组,例如,转换为js对象简谱(javascriptobjectnotation,json)格式的数据结构:
[
{
"text":"我刚才洗了个澡。",
"sex":"女性角色"
},
{
"text":"她对着呆立在那的天吾,像想起了一件大事般严肃地说,",
"sex":"无"
},
{
"text":“用了你的香波和护发素。”,
"sex":"女性角色"
},
{
"text":"天吾点点头,喘了一口气,终于从门把手上松开手,上了锁。香波和护发素?他抬脚向前迈去,离开了门边。",
"sex":"无"
},
{
"text":"后来电话铃响过吗?",
"sex":"男性角色"
},
{
"text":"他问。",
"sex":"无"
},
{
"text":“一次也没响过。”,
"sex":"女性角色"
}
{
"text":"深绘里答道,微微摇了摇头。",
"sex":"无"
},
{
"text":"天吾走到窗边,把窗帘拉开一条缝,向外望去。从三楼窗口看到的风景没有特别的变化。看不见可疑的人影,也没有停放可疑的汽车。",
"sex":"无"
}
]
需要说明的是,上述数据结构仅是一种可能的示例,不应对本申请实施例进行限制。
基于同一发明构思,本申请实施例中还提供了一种播放控制装置,基于上述实施例,参阅图7所示,本申请实施例中播放控制装置,具体包括:
切割模块70,用于根据预设切割方式,将待播放文本切割为各待播放片段,所述待播放片段包括类型为对话的待播放片段以及类型为非对话的待播放片段;
第一确定模块71,用于确定所述类型为对话的待播放片段对应的角色名称;
第二确定模块72,用于确定所述角色名称对应的角色类别,以及预设的角色类别和播放音色映射关系,确定所述角色名称对应的播放音色;
播放模块73,用于以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段时,切割模块70具体用于:
按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段。
可选的,所述预设标识符为双引号,包括左双引号和右双引号,则按照预设标识符,以所述标识符为分割点,分别将待播放文本切割为各待播放片段时,切割模块70具体用于:
确定所述待播放文本的文本长度;
依次扫描所述待播放文本的各字符,并记录当前扫描累积的字符长度;
判断当前扫描的字符是否为左双引号或右双引号,若确定所述当前扫描的字符为左双引号或右双引号,则进行切割,将上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,或将上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本作为一个待播放片段,直至确定当前扫描累积的字符长度不小于所述文本长度,获得切割后的各待播放片段,其中,所述上一个右双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为分句,
所述上一个左双引号字符的下一个字符到所述当前扫描的字符的上一个字符之间的文本的待播放片段为引用句;
确定所述各待播放片段的类型为对话或非对话。
可选的,根据预设切割方式,将待播放文本切割为各待播放片段时,切割模块70具体用于:
根据预设的语法规则,对待播放文本进行解析,按照空行标识符,将所述待播放文件切割为各段落;
按照句号标识符,分别将所述各段落切割为各句子,并按照双引号标识符和分句标识符,分别将所述各句子切割为各引用句和各分句;
将所述各引用句和各分句确定为切割后的各待播放片段,并确定所述各待播放片段的类型为对话或非对话。
可选的,进一步包括,解析模块74,用于:
采用自然语言处理方法,分别构建所述各待播放片段的语法树,其中,所述语法树中至少表征有待播放片段中每个分词的词性、语法关系;
基于预设角色词库和所述每个分词的词性,从所述各待播放片段中匹配获得角色名称集合,其中,所述角色名称集合中包括人物名称、关系名词和非人物名称。
可选的,确定所述各待播放片段的类型为对话或非对话时,切割模块70具体用于:
若确定切割为引用句的待播放片段符合预设非对话内容条件,则确定对应待播放片段的类型为非对话,若确定不符合,则确定对应待播放片段的类型为对话;
根据切割为分句的待播放片段的语法树和所述角色名称集合,分别判断所述切割为分句的待播放片段是否符合对话语法条件,若确定符合,则确定对应待播放片段的类型为对话,若确定不符合,则确定对应待播放片段的类型为非对话。
可选的,确定所述类型为对话的待播放片段对应的角色名称时,第一确定模块71具体用于:
根据所述类型为对话的待播放片段的语法树,若确定所述类型为对话的待播放片段的语法树中存在主谓语法关系,并所述主谓语法关系的主语在所述角色名称集合中,则确定所述类型为对话的待播放片段的角色名称为所述主语;或,
若确定所述类型为对话的待播放片段中存在第三人称指代关系词语,则确定所述类型为对话的待播放片段的角色名称为在所述类型为对话的待播放片段之前最近的角色名称。
可选的,确定所述角色名称对应的角色类别时,第二确定模块72具体用于:
将所述类型为对话的待播放片段的角色名称输入到已训练的第一分类模型中,确定所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别;或,
从所述待播放文本中获取与所述类型为对话的待播放片段的角色名称关联的多个形容词,并将所述角色名称的多个形容词输入到已训练的第二分类模型中,输出所述角色名称属于各预设角色类别的分值,并根据所述角色名称属于各预设角色类别的分值,确定所述角色名称的角色类别。
可选的,所述角色类别表示角色性别,则以所述类型为对话的待播放片段对应的播放音色和类型为非对话的待播放片段对应的设定播放音色,按照所述各播放片段在所述待播放文本中的顺序依次播放所述各待播放片段时,播放模块73具体用于:
按照所述各待播放片段在所述待播放文本中的顺序,依次播放所述各待播放片段时,若确定当前的待播放片段的类型为对话并角色类别为女性角色,则以第一女性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为对话并角色类别为男性角色,则以第一男性播放音色播放所述当前的待播放片段,若确定所述当前的待播放片段的类型为非对话,则以设定的第二女性播放音色或第二男性播放音色播放所述当前的待播放片段。
可选的,所述第二女性播放音色或第二男性播放音色为默认的不同于所述第一女性播放音色和所述第一男性播放音色的播放音色,或,所述第二女性播放音色或第二男性播放音色为根据用户从预设的候选播放音色中选择的播放音色。
基于上述实施例,参阅图8所示为本申请实施例中电子设备的结构示意图。
本申请实施例提供了一种电子设备,该电子设备可以包括处理器810(centerprocessingunit,cpu)、存储器820、输入设备830和输出设备840等,输入设备830可以包括键盘、鼠标、触摸屏等,输出设备840可以包括显示设备,如液晶显示器(liquidcrystaldisplay,lcd)、阴极射线管(cathoderaytube,crt)等。
存储器820可以包括只读存储器(rom)和随机存取存储器(ram),并向处理器810提供存储器820中存储的程序指令和数据。在本申请实施例中,存储器820可以用于存储本申请实施例中任一种播放控制方法的程序。
处理器810通过调用存储器820存储的程序指令,处理器810用于按照获得的程序指令执行本申请实施例中任一种播放控制方法。
基于上述实施例,本申请实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意方法实施例中的播放控制方法。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
显然,本领域的技术人员可以对本申请实施例进行各种改动和变型而不脱离本申请实施例的精神和范围。这样,倘若本申请实施例的这些修改和变型属于本申请权利要求及其等同技术的范围之内,则本申请也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!