一种本地存储IO协议栈数据交互方法和装置与流程
本发明涉及计算机技术领域,尤其涉及一种本地存储io协议栈数据交互方法和装置。
背景技术:
linux操作系统因其稳定、开源、免费、安全、高效的特点,被广泛的应用于电信、金融、政府、教育、银行、石油等各个行业,同时互联网、服务器、存储等各大型企业都在使用linux系统作为其服务器端的程序运行平台,全球及国内排名前十的网站使用的几乎都是linux系统,linux已经逐步渗透到了各个领域。linux操作系统是基于posix和unix的多用户、多任务、支持多线程和多cpu的开源操作系统。线程是linux软件执行的最小单元。
当前的大型linux存储系统,主流的io协议栈包括:iscsi、fc、ib,对应驱动和协议的实现一般都是在linux内核态,而存储系统核心部分都是工作在linux用户态,这就涉及到大量的内核态和用户态的数据交互。存储系统对于整个io通路上都要求保证高性能和低时延,因此内核态和用户态的数据交互也需要满足这两个要求。
但是从linux操作系统的实现上看,内核软件独立于普通用户软件,运行在较高的特权级别上,它们驻留在被保护的内存空间上,拥有访问硬件设备的所有权限。用户软件,只能看到允许它们使用的部分系统资源,并且不能使用某些特定的系统功能,不能直接访问硬件,不能直接访问内核软件的资源。linux操作系统使用这种非对称访问机制,主要为了抵御恶意用户的窥探,防止质量低劣的用户程序的侵害,从而使系统运行得更稳定可靠。
基于以上背景,存储系统中需要一种高性能和低延时的方案,解决本地设备上内核软件和用户软件的数据交互问题。目前主流的技术方案有三种:
1)系统调用机制
linux操作系统提供了系统调用供用户软件进入内核,并操作内核的内存空间。linux系统调用是linux内核提供的一系列接口,用于用户程序调用,访问内核空间的资源。用户程序调用ioctl/read/write等系统调用进入内核,通过copy_to_user从内核态向用户态传输数据,通过copy_from_user从用户态向内核态传输数据。该机制只能由用户态主动发起。
2)内核netlink机制
netlink是linux操作系统特有的内核和用户空间通信机制,基于socket实现。netlink机制可以自定义一种新的协议并加入协议族,内核/用户软件通过socketapi使用netlink协议完成数据交互。该机制是双向通信机制,内核空间和用户空间程序均可发起,且该通信机制使用socket缓存队列,是一种异步通信机制。
3)共享内存机制
linux操作系统提供了mmap系统调用,用于linux内核态和用户态的内存共享。用户软件和内核软件可以通过创建一段共享内存,进行数据交互,该方案可以实现数据交互过程中的零拷贝。
表1:现有技术的优缺点
如表1所示,当前主流的三种方案均存在一些问题:
系统调用方案,只能由用户软件主动发起,内核软件无法向用户软件主动传输数据,该模型使用场景非常受限。系统调用是一个同步通信模型,无法满足高性能的需求,在数据交互频繁的场景,会影响操作系统的性能,因此该方案并不适用于存储系统的io通路。
内核netlink方案,是一种双向异步通信模型,相对于系统调用方案,数据交互的性能和时延都有一定的优势,但是该方案存在一次用户软件和内核软件的数据拷贝,会对数据交互的性能有影响。
共享内存方案,用户软件和内核软件可以共享一段相同的内存,因此可以实现数据交互过程中的内存零拷贝。但是访问同一段内存,需要通过操作系统的锁机制进行互斥,保证内存访问的安全性,这样如果需要通过增加线程的方式扩展数据交互的性能,会导致锁竞争加剧,无法保证性能随着线程的增加而线性扩展。多个软件同时访问共享资源时,需要通过锁来互斥访问,软件加锁过程中带来的开销为锁竞争。共享内存方案,需要实现用户软件和内核软件写入数据后的通知机制,且要求尽可能减少通知机制的时延。目前主流的通知实现机制,是通过epoll模型轮询的方式实现,虽然可以保证通知的实时性,但是会一直占用cpu,导致系统cpu资源的浪费。
技术实现要素:
针对相关技术中存在的问题,本发明的目的在于提供一种本地存储io协议栈数据交互方法和装置,本发明基于mmap机制,避免内存拷贝,同时通过优化线程和共享内存的映射关系,以及内核线程和用户线程之间的唤醒机制,最大限度的提升数据交互的性能。本发明的方案使得在存储io压力不大的场景,可以实时响应数据交互请求,保证性能和时延的前提下降低cpu开销;在存储io压力大的场景,可以通过增加处理线程的方式,线性扩展数据交互性能。
根据本发明的实施例,一种本地存储io协议栈数据交互方法,包括:第一内核线程将第一类型的存储io协议栈的数据写入第一环形缓冲区中;用户处理线程从第一环形缓冲区中读取数据,并获取数据对应的回执消息,将回执消息写入第二环形缓冲区;第一内核线程从第二环形缓冲区中读取回执消息并进行处理,将处理后的回执消息返回第一类型的存储io协议栈,其中,第一内核线程不与其他内核线程共用第一环形缓冲区和第二环形缓冲区。
根据本发明的实施例,本地存储io协议栈数据交互方法,还包括:在将数据写入第一环形缓冲区之后,唤醒阻塞在读模式(read)上的用户处理线程,其中,唤醒后的用户处理线程用于从第一环形缓冲区中读取数据;在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒用户处理线程,其中,唤醒后的用户处理线程用于获取数据对应的回执消息;在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒第一内核线程,唤醒后的第一内核线程用于从第二环形缓冲区中读取回执消息。
根据本发明的实施例,本地存储io协议栈数据交互方法,还包括:当没有数据交互的时候,用户处理线程调用字符设备读模式(read)接口进行休眠并让出cpu资源。
根据本发明的实施例,本地存储io协议栈数据交互方法,还包括:第二内核线程将第二类型的存储io协议栈的数据写入第三环形缓冲区中。
根据本发明的实施例,本地存储io协议栈数据交互方法,还包括:在用户处理线程从第一环形缓冲区中读取数据之后,将数据插入第一队列,并通过信号量唤醒工作(worker)线程;
唤醒后的工作(worker)线程从第一队列中获取数据,根据数据构建回执消息,将回执消息插入第二队列中,并调用字符设备写模式(write)接口唤醒用户处理线程;唤醒后的用户处理线程从第二队列中获取回执消息,并将回执消息写入第二环形缓冲区中。
根据本发明的实施例,一种本地存储io协议栈数据交互装置,包括:内核软件写入模块,用于第一内核线程将第一类型的存储io协议栈的数据写入第一环形缓冲区中;用户软件读取与写入模块,用户处理线程从第一环形缓冲区中读取数据,并获取数据对应的回执消息,将回执消息写入第二环形缓冲区;内核软件读取模块,第一内核线程从第二环形缓冲区中读取回执消息并进行处理,将处理后的回执消息返回第一类型的存储io协议栈;其中,第一内核线程不与其他内核线程共用第一环形缓冲区和第二环形缓冲区。
根据本发明的实施例,本地存储io协议栈数据交互装置,还包括:第一唤醒模块,用于在将数据写入第一环形缓冲区之后,唤醒阻塞在读模式(read)上的用户处理线程,其中,唤醒后的用户处理线程用于从第一环形缓冲区中读取数据;
第二唤醒模块,用于在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒用户处理线程,其中,唤醒后的用户处理线程用于获取数据对应的回执消息;第三唤醒模块,用于在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒第一内核线程,唤醒后的第一内核线程用于从第二环形缓冲区中读取回执消息。
根据本发明的实施例,本地存储io协议栈数据交互装置,还包括:休眠模块,用于当没有数据交互的时候,用户处理线程调用字符设备读模式(read)接口进行休眠并让出cpu资源。
根据本发明的实施例,本地存储io协议栈数据交互装置,内核软件写入模块还包括:第二内核线程将第二类型的存储io协议栈的数据写入第三环形缓冲区中。
根据本发明的实施例,本地存储io协议栈数据交互装置,还包括:在用户处理线程从第一环形缓冲区中读取数据之后,将数据插入第一队列,并通过信号量唤醒工作(worker)线程;
唤醒后的工作线程从第一队列中获取数据,根据数据构建回执消息,将回执消息插入第二队列中,并调用字符设备write接口唤醒用户处理线程;唤醒后的用户处理线程从第二队列中获取回执消息,并将回执消息写入第二环形缓冲区中。
本发明的有益技术效果在于:本发明的方案可以避免内存拷贝,同时通过优化线程和共享内存的映射关系,以及内核线程和用户线程之间的唤醒机制,最大限度的提升数据交互的性能。在存储io压力不大的场景,可以实时响应数据交互请求,保证性能和时延的前提下降低cpu开销;存储io压力大的场景,可以通过增加处理线程的方式,线性扩展数据交互性能。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
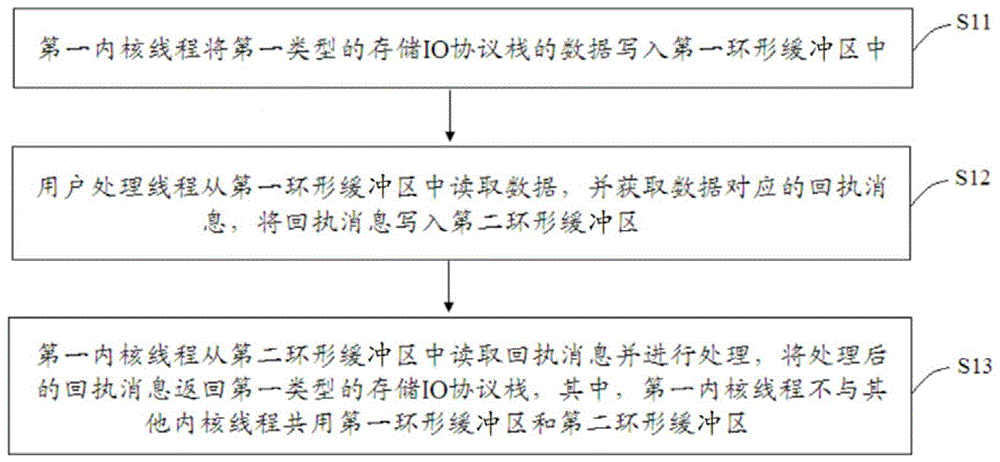
图1是根据本发明一个实施例的一种本地存储io协议栈数据交互方法的流程图;
图2是根据本发明一个实施例的本地存储io协议栈数据交互架构的示意图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明提供了一种本地存储io协议栈数据交互方法,包括:
s11,第一内核线程将第一类型的存储io协议栈的数据写入第一环形缓冲区中;
s12,用户处理线程从第一环形缓冲区中读取数据,并获取数据对应的回执消息,将回执消息写入第二环形缓冲区;
s13,第一内核线程从第二环形缓冲区中读取回执消息并进行处理,将处理后的回执消息返回第一类型的存储io协议栈,其中,第一内核线程不与其他内核线程共用第一环形缓冲区和第二环形缓冲区。
通过本发明的上述技术方案,实现了通信过程中的免锁机制,通过将软件和共享内存绑定的方式,每个线程独占不同的环形缓冲区进行处理。
首先,第一内核线程不与其他内核线程共用第一环形缓冲区和第二环形缓冲区。也就是,每个内核线程独占一对环形缓冲区(ringbuffer),多个线程不共享环形缓冲区,这样可以避免多个线程操作同一段内存时的锁竞争,达到多线程可以线程扩展数据交互性能的效果。
其次,根据不同的数据流向使用不同的环形缓冲区,其中一个环形缓冲区,即第一环形缓冲区,用于记录内核软件(kernel)向用户软件(user)发送的消息,另外一个环形缓冲区,即第二环形缓冲区,用于记录用户软件(user)向内核软件(kernel)发送的消息。同时,第一内核线程将数据写入第一环形缓冲区中并从第二环形缓冲区中读取回执消息,使得同一个内核线程进行写入和读取操作也不需要通过加锁进行互斥。这样可以最大限度的减少内核软件的锁竞争。
另外,本发明的技术方案中,用户空间采用一个多级线程流水线处理的策略,其中环形缓冲区的接收和发送由一个轻量级的线程,即用户处理线程进行处理,这样可以完全避免用户态对环形缓冲区的并发操作,减少锁竞争。
图2为本发明一个实施例的本地存储io协议栈数据交互架构的示意图,如图2所示,101-108代表一次io的数据流向,数据交互包括以下步骤:
步骤101,内核线程1从iscsi存储协议栈接收数据写入环形缓冲区。即,第一内核线程将第一类型的存储io协议栈的数据写入第一环形缓冲区中。步骤101还包括:第二内核线程将第二类型的存储io协议栈的数据写入第三环形缓冲区中。每个缓冲区具有缓冲区头(head)和缓冲区尾(tail)。在步骤101中,不同的存储io协议栈(iscsi、fc)由不同的内核线程进行处理,每个内核线程处理对应的存储io协议栈,并将协议发送的数据直接写入环形缓冲区中,优化了线程和共享内存的关系,并且能够实现内存零拷贝的效果。
在步骤101将数据写入第一环形缓冲区之后,唤醒阻塞在读模式(read)上的用户处理线程,其中,唤醒后的用户处理线程用于从第一环形缓冲区中读取数据;
步骤102,用户处理线程唤醒后,通过接收工作(recvworker)进行环形缓冲区的读取。
步骤103,将在步骤102中读取的数据插入队列(queue)中,通过信号量唤醒工作(worker)线程。
步骤104,工作线程(workerthread)唤醒后,从队列(queue)中获取数据并进行处理。
步骤105,根据步骤104中的数据构建回执消息,插入到队列(queue)中。
在步骤105之后之后,调用字符设备写模式(write)接口唤醒用户处理线程,其中,唤醒后的用户处理线程用于获取数据对应的回执消息。
步骤106,用户处理线程唤醒后,从队列(queue)中获取回执消息。
在上述步骤中,用户处理线程从所有环形缓冲区中读取消息并投递到多个队列(queue)中,由多个工作(worker)线程从队列中获取消息并处理,工作(worker)线程处理消息结束后的回执消息也加入队列(queue)中,通过用户处理线程将回执消息写入环形缓冲区。因此,在用户软件的处理流程中,唯一的锁开销只在多个队列的插入和获取,对性能影响并不大。
步骤107,将在步骤106中获取的回执消息通过发送工作(sendworker)写入环形缓冲区中,调用字符设备write接口唤醒内核线程1。
在步骤107将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒内核线程1,唤醒后的第一内核线程用于从第二环形缓冲区中读取回执消息。
步骤108,内核线程1唤醒后,从环形缓冲区中读取回执消息。
内核线程1将读取的回执消息进行处理后,返回存储协议栈。
当系统没有数据交互的时候,用户处理线程调用字符设备read接口进行休眠,此时会让出cpu资源。
通过以上步骤,可以实时的唤醒内核软件和用户软件的线程,减少线程通知上的时间开销,同时io压力小的时候,线程可以休眠让出cpu,降低系统开销。
在上述实施例中,本发明通过唤醒阻塞在读模式(read)上的用户处理线程、调用字符设备写模式(write)接口唤醒用户处理线程、以及调用字符设备写模式(write)接口唤醒第一内核线程,通过内核程序提供字符驱动,用read系统调用来实现用户态进程的阻塞,用write系统调用实现用户态线程唤醒、内核态线程唤醒和阻塞在read上的用户态线程唤醒。优化了内核线程和用户线程之间的唤醒机制,实现了实时的唤醒内核软件和用户软件的线程,减少线程通知上的时间开销的效果。同时,内核程序和用户程序的实时通信机制,可以极大的降低程序处理切换阶段的时延。
通过本发明的上述技术方案,在存储io压力不大的场景,可以实时响应数据交互请求,保证性能和时延的前提下降低cpu开销,同时io压力小的时候,线程可以休眠让出cpu,降低系统开销;存储io压力大的场景,可以通过增加处理线程的方式,线性扩展数据交互性能。
本发明还提供了一种本地存储io协议栈数据交互装置,包括:
内核软件写入模块,用于第一内核线程将第一类型的存储io协议栈的数据写入第一环形缓冲区中;
用户软件读取与写入模块,用户处理线程从第一环形缓冲区中读取数据,并获取数据对应的回执消息,将回执消息写入第二环形缓冲区;
内核软件读取模块,第一内核线程从第二环形缓冲区中读取回执消息并进行处理,将处理后的回执消息返回第一类型的存储io协议栈,其中,第一内核线程不与其他内核线程共用第一环形缓冲区和第二环形缓冲区。
在一个实施例中,本地存储io协议栈数据交互装置,还包括:第一唤醒模块,用于在将数据写入第一环形缓冲区之后,唤醒阻塞在读模式(read)上的用户处理线程,其中,唤醒后的用户处理线程用于从第一环形缓冲区中读取数据;第二唤醒模块,用于在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒用户处理线程,其中,唤醒后的用户处理线程用于获取数据对应的回执消息;第三唤醒模块,用于在将回执消息写入第二环形缓冲区之后,调用字符设备写模式(write)接口唤醒第一内核线程,唤醒后的第一内核线程用于从第二环形缓冲区中读取回执消息。
在一个实施例中,本地存储io协议栈数据交互装置,还包括:休眠模块,用于当没有数据交互的时候,用户处理线程调用字符设备读模式(read)接口进行休眠并让出cpu资源。
在一个实施例中,本地存储io协议栈数据交互装置,内核软件写入模块还包括:第二内核线程将第二类型的存储io协议栈的数据写入第三环形缓冲区中。
在一个实施例中,本地存储io协议栈数据交互装置,还包括:在用户处理线程从第一环形缓冲区中读取数据之后,将数据插入第一队列,并通过信号量唤醒工作(worker)线程;唤醒后的工作线程从第一队列中获取数据,根据数据构建回执消息,将回执消息插入第二队列中,并调用字符设备write接口唤醒用户处理线程;唤醒后的用户处理线程从第二队列中获取回执消息,并将回执消息写入第二环形缓冲区中。
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!