一种关系型数据库数据对比方法及系统与流程
本发明属于数据库技术领域,尤其涉及一种关系型数据库数据对比方法及系统。
背景技术:
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
随着各类数据库类型的应用。为了提高数据交换效率,或者保证数据实时性等情况,需要在多个数据库之间进行数据同步或者迁移操作。然而,进行同步或迁移后,如何判断同步或者迁移后的数据与源数据库中一致,是目前亟待解决的技术问题。
据发明人了解,不同的数据库之间数据类型有差异,对数据的存储方式也不同,例如同样的数据,有的数据库存储二进制,有的存储是十六进制,导致尽管数据相同,但不能拿来直接对比,通常需要人工参与对比;并且,数据库通常数据量大,一条一条进行对比,耗时耗力,效率低。
技术实现要素:
为克服上述现有技术的不足,本发明提供了一种关系型数据库数据对比方法及系统,依次针对源库和目标库中的数据表名、全表和行进行对比,对比更为准确;且采用操作名称来标识对比结果为“不同”的表名或行,能够为用户提供对于目标库的下一步操作指示。
为实现上述目的,本发明的一个或多个实施例提供了如下技术方案:
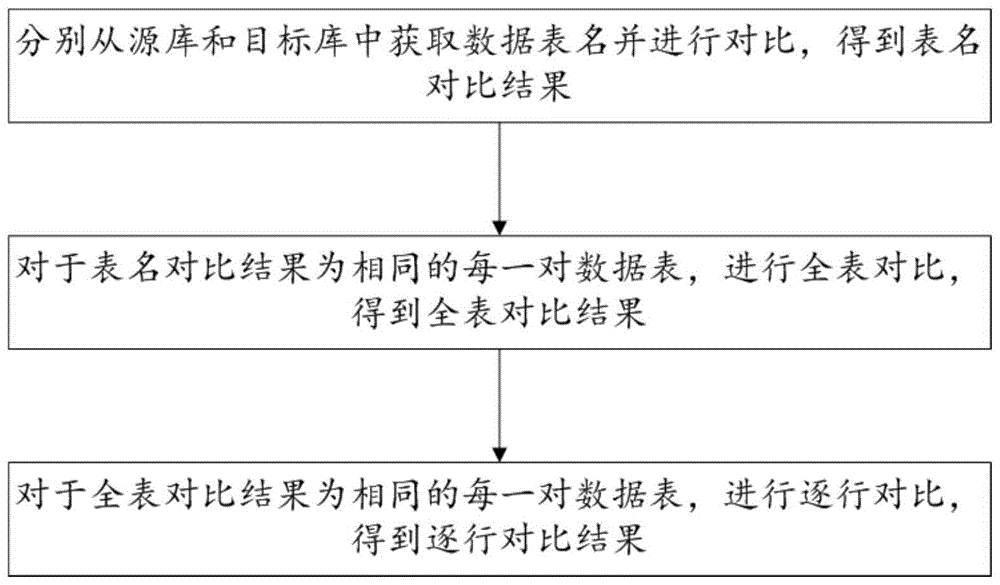
一种关系型数据库数据对比方法,包括以下步骤:
分别从源库和目标库中获取数据表名并进行对比,得到表名对比结果;
对于表名对比结果为相同的每一对数据表,进行全表对比,得到全表对比结果;
对于全表对比结果为相同的每一对数据表,进行逐行对比,得到逐行对比结果;
其中,所述表名对比结果和逐行对比结果中,对于对比结果为不同的记录,均采用操作名称来标识;所述操作名称为更新、操作或删除。
进一步地,数据表名对比方法包括:
创建map,将源库表名列表写入key字段,将value字段作为表名对比结果字段,value字段的值初始化为插入;
对于目标库中的每个表名,查找map中是否存在该表名,若存在,表名对比结果修改为相同;若不存在,不作处理;
遍历map,得到表名对比结果列表。
进一步地,全表对比方法包括:对于表名对比结果为相同的每一对数据表,依次根据表名、数据表行数和全表md5将两个数据表进行对比。
进一步地,全表对比方法包括:
对于表名对比结果为相同的每一对数据表,均执行以下操作:
从源库和目标库获取两个数据表的字段信息,所述字段信息包括字段名和字段的数据类型;
根据字段名的哈希值判断所述两个数据表中字段名是否完全相等,
若相等,判断字段的数据类型中是否存在md5值不支持的数据类型,
若不存在,从源库和目标库获取所述两个数据表的行数,判断行数是否相等,
若行数均不为0且相等,从源库和目标库获取所述两个数据表的全表md5,如果全表md5值相等,所述两个数据表的全表对比结果为相同,否则,为不同。
进一步地,逐行对比方法包括:
对于全表对比结果为相同的每一对数据表,判断两个数据表是否存在主键,若存在,依次按照主键值md5和整行数据值md5对两个数据表进行对比;若不存在,按照整行数据值md5对两个数据表进行对比。
进一步地,若两个数据表存在主键,分别获取两个数据表中每一行对应的唯一标识、主键值md5和整行数据值md5,并分别写入两个行数据列表;
遍历源库行数据列表,将主键值md5列写入map中的key字段,将value字段作为行对比结果字段;
遍历目标库行数据列表,对于目每个主键值md5,判断map中是否存在该主键值md5,如果不存在,行对比结果记为删除;
如果存在,对比整行数据md5值,若相同,从map中移除,否则,行对比结果记为更新;
遍历源库行数据列表,对于每个主键值md5,判断map中是否存在该主键值md5,如果不存在,将该主键值md5写入map,相应的行对比结果记为插入;
如果存在,对比整行数据md5值,若相同,从map中移除;否则行对比结果为更新。
进一步地,若两个数据表没有主键,分别获取两个数据表中每一行对应的唯一标识和整行数据值md5,并分别写入两个行数据列表;
创建map,key字段初始化为空,将value字段作为行对比结果字段;
遍历源库行数据列表,对于每个整行数据值md5,判断map中是否存在该整行数据值md5,如果存在,该整行数据值md5的出现次数加1;如果不存在,将该整行数据值md5写入map,该整行数据值md5的出现次数加1,并将相应的行对比结果赋值为插入;
遍历目标库行数据列表,对于每个整行数据值md5,判断map中是否存在该整行数据值md5,如果存在,该整行数据值md5的出现次数减1;如果不存在,将该整行数据值md5写入map,该整行数据值md5的出现次数减1,并将相应的行对比结果赋值为删除。
进一步地,所述方法还包括:将表名对比结果、全表对比结果和逐行对比结果进行可视化输出。
一个或多个实施例提供了一种关系型数据库数据对比系统,包括:
待对比数据库选择模块,接收指定的待比较源库和目标库数据库;
表名对比模块,从源库和目标库中获取数据表名并进行对比,得到表名对比结果;
全表对比模块,接收表名对比结果,对于表名对比结果为相同的每一对数据表,进行全表对比,得到全表对比结果;
逐行对比模块,接收全表对比结果,对于全表对比结果为相同的每一对数据表,进行逐行对比,得到逐行对比结果;
其中,所述表名对比结果和逐行对比结果中,对于对比结果为不同的记录,均采用操作名称来标识;所述操作名称为更新、操作或删除。
进一步地,还包括对比结果展示模块,用于对表名、全表或逐行对比结果进行展示。
以上一个或多个技术方案存在以下有益效果:
本发明的数据库数据对比方法依次针对源库和目标库中的数据表名、全表和行进行对比,对比更为全面,得到的对比结果更为精确;
并且其中,全表依次根据字段名、行数和全表md5进行对比,行依次根据主键md5和整行数据md5进行对比,将md5引入全表和行之间的对比,相较于直接对比内容而言,准确率和对比效率都有很大提高,可以在短时间内对比大量数据;
本发明采用操作名称(更新、操作或删除)来标识对比结果为“不同”的表名或行,除了直观的体现出不同外,还为用户提供了对于目标库的下一步操作指示。
本发明还提供了一种数据库数据对比系统,通过该系统,用户可以自主选择源库和目标库,并且提供了表名对比、全表对比和逐行对比模块,用户可根据需求查看各对比结果。
附图说明
构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
图1为本发明实施例中关系型数据库数据对比方法整体流程图;
图2为本发明实施例中表名对比流程图;
图3为本发明实施例中全表对比流程图;
图4为本发明实施例中关系型数据库数据对比系统整体功能框架图。
具体实施方式
应该指出,以下详细说明都是示例性的,旨在对本发明提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本发明所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本发明的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
实施例一
本实施例公开了一种关系型数据库数据对比方法,包括以下步骤:
步骤1:分别从源库和目标库中获取数据表名并进行对比,得到表名对比结果列表;
所述步骤1具体包括:
步骤1.1:将从源库和目标库中获取数据表名的数据表名分别写入两个列表中;
步骤1.2:遍历源库表名列表,把表名作为key,放入map中,在map中插入表名对比结果列,并将表名对比结果的值初始化为insert;
步骤1.3:遍历目标库表名列表,对于每个表名,把该表名作为key的值,基于get(key)函数判断map中是否存在该表名,若存在,说明源库和目标库均包括数据表为这个表名,对比结果修改为same;若不存在,说明源库中没有数据表是这个表名,不作处理;遍历结束后,得到表名对比结果列表。所述表名对比结果列表的对比结果只有insert和same这两种。
其中,对比结果为insert的数据表为源库中有但目标库中没有的数据表。
步骤1.4:还将表名对比结果列表根据表名进行排序,最后把表名显示到视图表格中。
上述步骤1将目标库与源库的表名进行对比,对比结果用操作方式insert进行标识,不仅直观的体现了目标库和源库之间表名的差异,还标识了要对目标库执行的下一步操作。
步骤2:对于表名对比结果为相同的每一对数据表,进行全表对比,得到全表对比结果;
所述步骤2具体包括:
步骤2.1:获取表名对比结果列表,将对比结果为same的表名放入相同表名列表,否则放入不同表名列表,分别为相同表名列表和不同表名列表创建全表对比结果字段、表行数对比结果字段和md5值对比结果字段;
步骤2.2:遍历不同表名列表,将表行数对比结果字段和md5值对比结果字段的值均赋值为-1,即将这些表名相应的数据表标记为无效,不再做其他操作;
步骤2.3:根据相同表名列表,分别从源库和目标库获取相同表名数据表中的字段信息,写入两个字段信息列表;所述字段信息包括字段名和字段的数据类型(例如整型、字符型、浮点型等);
步骤2.4:根据字段名的哈希值判断这些表名相同的数据表中字段名是否相等,若相等,继续执行步骤2.5;若不相等,表行数对比结果字段和md5值对比结果字段的值均赋值为-1,将全表对比结果字段赋值为diffcolumn,不再做其他操作;
步骤2.5:判断字段的数据类型中是否存在md5值不支持的数据类型,若不存在,继续执行步骤2.6;若存在,表行数对比结果字段和md5值对比结果字段的值均赋值为-1,将全表对比结果字段赋值unsupport,不再做其他操作;
步骤2.6:分别从源库和目标库获取这些表名相同的数据表的行数,若行数均不为0且相等,继续执行步骤2.7;若其中一个行数为0或行数不相等,表行数对比结果字段和md5值对比结果字段的值均赋值为-1,将全表对比结果字段赋值diff,不再做其他操作;
步骤2.7:获取源库和目标库的表的全表md5,如果md5值相等,全表对比结果改为same,如果md5值不相等,全表对比结果改为diff;
至此,全表对比结束,得到全表对比结果列表。
步骤2.8:还将全表对比结果列表根据对比结果进行排序,显示到视图表格和html页面中。
步骤3:对于全表对比结果为相同的每一对数据表,进行逐行对比,得到逐行对比结果。
所述步骤3具体包括:
步骤3.1:分页获取数据表对中的两个数据表的数据,每次获取十万行作为一组,对各分组依次进行逐行对比;
步骤3.2:判断两个数据表是否存在主键,若存在,执行步骤3.3,若不存在,执行步骤3.4;
步骤3.3:对于存在主键的数据表对,对于每一个分组,分别根据以下步骤进行逐行对比:
步骤3.3.1:分别为数据表对中的两个数据表创建行数据列表,所述列表包括唯一标识列字段、主键值md5字段和整行数据值md5字段;分别获取两个数据表中每一行对应的唯一标识、主键值md5和整行数据值md5,并写入相应行数据列表的相应字段;
步骤3.3.2:遍历源库行数据列表,将主键值md5列写入key字段,将value字段作为行对比结果字段;
步骤3.3.3:遍历目标库行数据列表,将主键值md5作为key的值,通过get(key)判断map中是否存在该主键值md5,如果不存在,行对比结果记为delete;如果存在,执行步骤3.3.4;
步骤3.3.4:对比整行数据md5值,若相同,从map中移除;否则,行对比结果记为update;
步骤3.3.5:遍历源库行数据列表,将主键值md5作为key的值,通过get(key)判断map中是否存在该主键值md5,如果不存在,将该主键值md5写入map,相应的行对比结果记为insert;如果存在,执行步骤3.3.6;
步骤3.3.6:对比整行数据md5值,若相同,从map中移除;否则行对比结果为update;
结合唯一标识列,即可得到包含唯一标识和行对比结果的map。
步骤3.4:对于没有主键的数据表对,对于每一个分组,分别根据以下步骤进行逐行对比:
步骤3.4.1:分别为数据表对中的两个数据表创建行数据列表,所述列表包括唯一标识列字段和整行数据值md5字段;分别获取两个数据表中每一行对应的唯一标识和整行数据值md5,并写入相应行数据列表的相应字段;
步骤3.4.2:创建map,key字段初始化为空,将value字段作为行对比结果字段;
步骤3.4.3:遍历源库行数据列表,将整行数据值md5作为key的值,对于每个整行数据值md5,通过get(key)判断map中是否存在该整行数据值md5,如果存在,对于该整行数据值md5的出现次数time加1;如果不存在,将该整行数据值md5写入map,该整行数据值md5的出现次数time加1,并将相应的行对比结果赋值为insert;
步骤3.4.4:遍历目标库行数据列表,将整行数据值md5作为key的值,对于每个整行数据值md5,通过get(key)判断map中是否存在该整行数据值md5,如果存在,该整行数据值md5的出现次数time减1;如果不存在,将该整行数据值md5写入map,该整行数据值md5的出现次数time减1,并将相应的行对比结果赋值为delete;
结合行对比结果为insert和delete的行相应的唯一标识,即可确定两个数据表中不同的行数据,得到了包含唯一标识和行对比结果的map。
步骤3.5:遍历map,如果time等于0,进行移除,如果time大于0,对比结果为insert,time小于0对比结果为delete,对比结束。
步骤3.6:采用唯一标识列关联数据表的行对比结果,以及相应数据表中的行,显示到sql文件中,最多显示100条,同时,计算出insert,update和delete的数量,返回行对比结果列表;
步骤3.7:根据行对比结果进行排序,显示到视图表格和html页面中。
上述唯一标识为数据库为每个数据表中的行分配的物理地址,能够与数据表中的行一一对应。
对于数据表对所有数据分组通过两种方式中的其中一种均进行逐行对比后,即完成了数据表对的逐行比对,得到的行对比结果列表中仅体现出两个数据表中不同的行数据,并且行比较结果记录了对目标库中数据表的操作方式:如果一条行记录在目标库中有而在源库中没有,则从目标库数据表中删除该行记录;如果同一条行记录在源库和目标库中数据存在差异,则根据源库中数据表对目标库中数据表进行更新;如果一条行记录在源库中有而在目标库中没有,则将该行记录插入目标库数据表。
本实施例中,采用操作名称(更新、操作或删除)来标识对比结果为“不同”的表名或行,除了直观的体现出不同外,还为用户提供了对于目标库的下一步操作指示。为了更便于用于操作,本实施例还基于表名对比结果、全表对比结果和逐行对比结果,生成针对目标库操作的sql语句,并写入文件。
实施例二
本实施例的目的是提供一种关系型数据库数据对比系统。
为了实现上述目的,本实施例提供了一种关系型数据库数据对比系统,包括:
待对比数据库选择模块,接收选择的待比较源库和目标库数据库类型,以及要连接的数据库服务器;
待对比数据库用户选择模块,接收选择的待比较源库和目标库数据库的用户;
表名对比模块,从源库和目标库中获取数据表名并进行对比;
全表对比模块,接收表名对比结果,对于表名对比结果为相同的每一对数据表,进行全表对比;
逐行对比模块,接收全表对比结果,对于全表对比结果为相同的每一对数据表,进行逐行对比;
对比结果展示模块,用于对表名、全表或逐行对比结果进行展示;
sql文件生成模块,用于根据表名、全表或逐行对比结果,生成针对目标库的操作命令文件。
上实施例二中涉及的各步骤与方法实施例一相对应,具体实施方式可参见实施例一的相关说明部分。
以上一个或多个实施例具有以下技术效果:
本发明的数据库数据对比方法依次针对源库和目标库中的数据表名、全表和行进行对比,对比更为全面,得到的对比结果更为精确;
并且其中,全表依次根据字段名、行数和全表md5进行对比,行依次根据主键md5和整行数据md5进行对比,将md5引入全表和行之间的对比,相较于直接对比内容而言,准确率和效率都有很大提高,可以在短时间内对比大量数据;
本发明采用操作名称(更新、操作或删除)来标识对比结果为“不同”的表名或行,除了直观的体现出不同外,还为用户提供了对于目标库的下一步操作指示。
本发明还提供了一种数据库数据对比系统,通过该系统,用户可以自主选择源库和目标库,并且提供了表名对比、全表对比和逐行对比模块,用户可根据需求查看各对比结果。
本领域技术人员应该明白,上述本发明的各模块或各步骤可以用通用的计算机装置来实现,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。本发明不限制于任何特定的硬件和软件的结合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!