一种基于元学习与强化学习的推荐系统的制作方法
本发明涉及元学习、强化学习和数据挖掘领域,尤其涉及一种基于元学习与强化学习的推荐系统。
背景技术:
目前推荐系统几乎无处不在,许多的app都运用了推荐系统,出行,购物,视频,新闻,社交等等,我们都能看到推荐系统的影子,它已经与我们的日常生活息息相关。究其原因,对于用户而言,面临海量的数据,总是希望能够快速的找到自己感兴趣或者是对自己有价值的信息;对于信息生产者而言,总是希望自己的内容能够吸引更多的顾客,但是不同的顾客有不同的偏好,所以对于不同的用户,应该有不同的推荐内容。虽然推荐系统无论对于企业还是用户都有很多好处,但是如果推荐系统的表现差强人意,会对企业造成很大的损失。目前很多的推荐系统都是基于用户或者是商品之间的相似度进行推荐的,这种基于监督式学习的推荐方式有一定的局限性:
1.这些推荐系统倾向于基于短期内行为进行推荐,没有考虑到用户长期的行为。比如:当一个人在淘宝上购买了一副耳机,那么最近一段时间推荐系统仍会给该用户推荐耳机,会严重影响用户的体验。
2.不能快速的根据用户的行为或者偏好进行个性化的推荐。由于是基于相似度的推荐,那么系统需要先收集到一定的用户信息和行为,才能进行个性化的推荐。这需要长时间的用户反馈,并可能导致用户的流失。
3.推荐系统的偏差。推荐系统及其依赖用户的反馈,当推荐系统给用户推荐了,a和b两个商品,那么我们会只关注到用户对a和b的反馈,而不知道用户对于其他视频的喜爱程度。
强化学习近年来获得了很多的关注,在围棋场上大放异彩,在游戏中无懈可击,甚至在自动驾驶中的表现也夺人眼球。强化学习是机器学习的一个领域,强调的是如何在与环境的交互中学习,来获得最大的收益。而元学习的核心的是让机器学习模型学习如何去学习,与强化学习这种动态的调整策略的方式相结合后可以达到随着使用者的改变而迅速的适应的效果,十分吻合类似推荐系统这样的需要根据新用户对推荐的反应而敏捷反应的运行机制,因此我们可以用元学习和强化学习的技术相结合起来做推荐系统。
技术实现要素:
为了解决目前推荐系统的一些弊端,我们提出使用元学习与强化学习的方法来做推荐系统。一方面这种动态的交互策略改进方法能够很好的规避由于通过相似性进行判断的一些缺陷。另一方面近年来元学习的快速发展,它要解决的是在面临很少样本的情况下学习,如何能达到很好的效果,它与强化学习的结合现在也在一些问题上达到了很好的效果,因此我们使用强化学习和元学习的方法来解决推荐学习快速学习用户偏好的问题。
为达到上述目的,本发明采用了下列技术方案:
一种基于元学习与强化学习的推荐系统,具体的包括如下步骤:
步骤一:输入用户基本信息以及游览记录或者购买记录,定义内部更新模块和元更新模块模型,由内部更新模块和元更新模块构成系统模型;
所述内部更新模块模型首先接受用户以往一段时间的各项特征数据包括用户对这些数据的反馈,然后用梯度下降的方法来对模型进行优化得到快速适应后的模型,然后再接受该用户目前的各项特征数据;
所述元更新模块通过马尔可夫过程计算用户的各项指标变化,通过定义的元损失函数使得在在整个阶段中提供的推荐的激励能达到最大;
步骤二:所述系统模型通过所述内部更新模块,首先系统结合对用户以往一次的推荐内容,和用户对其产生的反馈,通过梯度下降的方法来进行模型修正,进行个性化的适应。
步骤三:通过所述内部更新模块接受用户当前的的各项特征数据,然后用步骤二修正后的策略来为该用户推荐新的内容;
步骤四:通过输入用户对步骤三中推荐内容的反馈而计算得到推荐的激励,所述反馈为对推荐内容是否喜欢的标签记录。
步骤五:得到这次推荐得到的激励之后,再对初始的模型进行求导更新,调整我们的策略。
所述内部更新模块可以表示为:
并定义
其中,θ为输入数据的向量,
所述元更新模块误差计算表示为:
其中
所述元损失函数定义为:
与传统的推荐系统的方法相比,基于元学习与强化学习的方法具有以下优势:
1.通过对用户的基本数据以及他们的浏览记录或者购买记录来综合学习该用户的行为或者偏好,自动化抽取用户的个人行为与可能喜欢的物品之间的隐藏关系,实现首次精准推荐。
2.通过结合用户对于推荐的内容的反应(喜欢或者不喜欢),动态的调整我们的推荐策略。
3.使用强化学习的方法进行推荐的决策,通过智能体(推荐系统的决策器)与环境(用户)的交互动态地调整给该用户的推荐内容来学习对于某用户的最优的推荐方案;
4.算法多参数可调,扩展性强,系统通过与用户的交互不断的获取奖励(用户的喜欢或者不喜欢)、环境状态(当前用户的游览记录或者购买记录)并采取行动(推荐内容),可以根据问题需求设置,算法的可移植性好。
附图说明
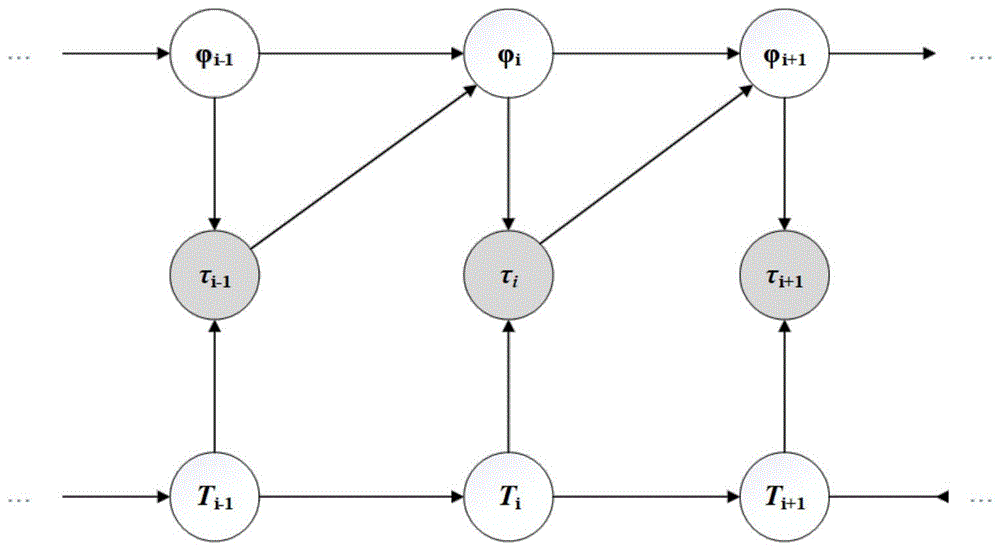
图1模型训练中与用户数据的交互图;
图2模型整体更新策略;
具体实施方式
以下是本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于此实施例。
本发明基于元学习和强化学习的方法,通过对用户基本信息以及游览记录或者购买记录进行学习,抽取其中隐藏的规则,为用户进行推荐,并将用户对于推荐内容的反应(喜欢或者不喜欢)作为模型反馈,从而调整模型学习到的策略,给出新的针对该用户的推荐内容。
其模型整体流程如图2所示,首先模型对一次用户的特征数据输入产生推荐的策略,进而根据这个策略求出误差,然后通过内部更新过程中提到的优化方法来优化模型的参数得到下一步策略,根据设定的内部更新的步数得到最终的策略,最后通过输入用户对推荐内容的反馈而产生误差,然后对初始的模型进行求导,并进行更新得到新的模型,至此一次训练至此结束。
因为我们系统的该方法在训练与工作时采取不同的策略,训练时:对于某一个用户对于每次推荐内容后的浏览行为(喜欢或者不喜欢)的变化(ti,ti+1)以及相对应的推荐内容yi,通过元学习以及梯度下降的方法来共同更新模型的参数θ和学习率α。而因为在执行时无法立即获得用户对于推荐内容的反馈,所以学习的策略就要做一下改变。执行时:获得某一个用户的基本数据和浏览数据ti,然后作出针对该用户的推荐内容yi,并根据每种不同的推荐的权重进行更新。
首先,对方案中涉及数据进行定义:
记用户的基本数据为x={x1,...,xn},其中每个数据点xi代表第i条数据,每条数据代表用户在某一时刻的行为记录(喜欢或不喜欢的物品或者是购买历史等等),xi={xi1,...,xim},其中每一个xij表示第i条数据的第j个特征,每条数据共有m个特征。记待推荐的集合为y={y1,...,yk},其中每个数据点yi代表第i种物品或内容,下面定义本发明提出的推荐系统模型的数据定义:
1.状态空间:一个长度为m的向量x,向量的各分量值表示当前状态下用户基本信息和历史记录中的各项指标相对应的指标值;
2.动作空间:一个长度为k的向量a,ai∈{0,1},1≤i≤k,对应表示在当前状态下推荐的内容是否包含物品yi,若为0则代表不含有此物品,若为1则代表含有此物品;
3.奖励:一个标量r,表示用户在接收到推荐系统决策器决策出的动作a之后的反馈。
4.策略序列:用户各项特征xi和对应推荐内容yi以及激励ri的有序序列
损失函数:lt对于某一特定的用户推荐内容效果的损失函数:
内部更新模块:
整个系统主要的部分之一,模型θ首先接受用户的各个xi项特征数据x,预测其对应的处方数据y,然后用梯度下降的方法来对模型进行优化得到快速适用(fastadaptation)后的模型φ:
上述的m是内部更新(innerupdate)的步数,
元更新模块:
元更新(metaupdate)模块的作用是检验模型的一个泛化能力,用户的行为在不停的动态变化,为了更好了使模型适应这个动态的环境,在面临用户指标多样的变化时,仍能提供实现为用户提供最好的推荐建议。
在元更新阶段,我们要实现的是在推荐过后下一次为用户的预测能达到最大的激励r。我们把用户的各项指标变化看作是一个马尔可夫过程,那我们在整体上看模型与数据的交互可以用图1表示。
元更新阶段的目标就是让使得在在整个阶段中提供的推荐的误差能达到最小,表示为:
其中
可以理解为我们我们用现在的输入ti,来对模型进行改变以能对该用户的各项特征数据ti+1产生最有效的推荐建议。
那么其整体流程即:首先模型
基于元学习与强化学习的推荐系统的输出模块:
在模型训练完成之后,系统首先接受到用户的特征数据,然后运行模型为该用户推荐推内容,模型的输出结果是一个动作向量a,ai∈{0,1},1≤i≤k,k是待推荐集合的长度,ai如果为1表示当前为用户推荐内容yi,否则不为用户推荐内容yi,然后根据模型的结果向用户推送相应内容,并收集这之后用户对于这些内容的反馈(喜欢或者不喜欢),根据这些反馈来计算这次推荐的奖励r,如果推荐的内容用户喜欢,增大r,若用户不喜欢减小r,若无反馈r为默认值,然后根据这一次推荐的结果,进行模型参数的调整(策略调整)。然后进行下一次的推荐。
- 还没有人留言评论。精彩留言会获得点赞!