一种用于肠道息肉检测识别的智能辅助系统的制作方法
本发明涉及医学和计算机结合技术领域,尤其涉及一种用于肠道息肉检测识别的智能辅助系统。
背景技术:
肠道息肉是一种常见的肠道疾病,内窥镜肠道检测是一种肠道疾病检测方式,使用肠道内窥镜深入肠道内对肠道图像进行采集,通过对内窥镜视觉范围内的图像进行判断,最大限度的发现病灶,从而确定患者病情。内窥镜肠道检查具有检测效率高和成本低的优点,能基本检测所有肠道区域,已经被世界各国各大医院所采用。现有的内窥镜肠道检测通常为医师肉眼观察探测结果来确定息肉位置,息肉的检出率也受医师的经验、疲劳度、探测速率等因素的影响,故存在着一定程度的息肉漏检情况。
因此,为了提高诊断准确率,降低漏诊率,同时也希望提高肠道检测的实时诊断的准确性,需要对肠道息肉检测识别提供智能辅助系统,以此可以实现对息肉的定位精度,为医师的诊断提供了参考。
技术实现要素:
本发明主要解决的技术问题是提供一种用于肠道息肉检测识别的智能辅助系统,解决现有技术中的肠道息肉检测存在的定位和识别的准确度不高、以及识别的时效性不强等问题。
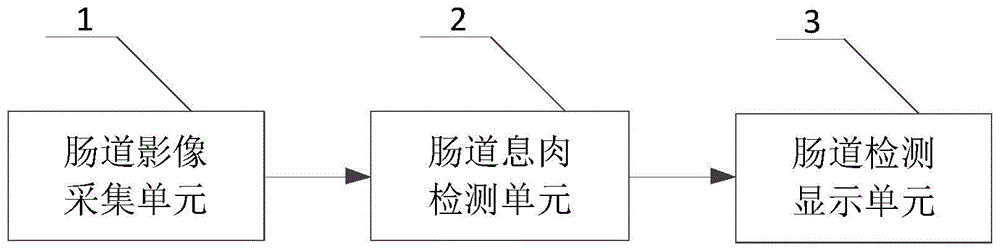
为解决上述技术问题,本发明采用的一个技术方案是提供一种用于肠道息肉检测识别的智能辅助系统,包括肠道影像采集单元、肠道息肉检测单元和肠道检测显示单元,其中,肠道影像采集单元用于对肠道影像的采集,然后将肠道影像输入到肠道息肉检测单元进行肠道息肉的定位和识别,肠道检测显示单元则对肠道影像进行呈现的同时还能在肠道影像上同步标注显示肠道息肉检测信息。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,肠道息肉检测单元还进一步包括转换模块、检测模块和显示模块。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,所述检测模块包括6级依次串联的卷积检测组和检测识别组,其中,第一卷积检测组和第二卷积检测组具有相同的结构,均是由两个卷积层和一个最大池化层串联而成,第三卷积检测组、第四卷积检测组和第五卷积检测组具有相同的结构,均是由三个卷积层和一个最大池化层串联而成,第六卷积检测组则包括9个卷积层串联而成;第四卷积检测组有一个卷积层输出特征图至检测识别组,而第六卷积检测组则有五个卷积层分别输出特征图至检测识别组。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,第一卷积检测组包括依次串联的第一输入卷积层、第一输出卷积层和第一最大池化层;第二卷积检测组包括依次串联的第二输入卷积层、第二输出卷积层和第二最大池化层。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,第三卷积检测组包括依次串联的第三输入卷积层、第三中间卷积层、第三输出卷积层和第三最大池化层,第四卷积检测组包括依次串联的第四输入卷积层、第四中间卷积层、第四输出卷积层3和第四最大池化层,第五卷积检测组中包括依次串联的第五输入卷积层、第五中间卷积层、第五输出卷积层和第五最大池化层。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,第六卷积检测组包括10个卷积子层,依次是串联的第1级卷积子层至第10级卷积子层,其中第2级卷积子层输出特征图至检测识别组,第4级卷积子层输出特征图至检测识别组,第6级卷积子层输出特征图至检测识别组,第8级卷积子层输出特征图至检测识别组,第10级卷积子层输出特征图至检测识别组q7。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,所述检测模块包括前后级联的五级检测组和检测输出组,其中,第一级检测组包括串联的卷积层和池化层,第二级检测组包括两级串联的inception结构,第三级检测组包括四级串联的inception结构,第四级检测组包括两级串联的inception结构,第五级检测组包括串联的卷积层和池化层,第三级检测组和第四级检测组分别有一路输出至检测输出组,第五级检测组则有三路输出至检测输出组,由检测输出组输出最终检测结果。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,其中,第一级检测组包括五层,从左至右依次是第一卷积层、第一最大池化层、第二卷积层、第三卷积层、第二最大池化层。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,所述inception结构包括四个分支,其中,第一分支中包括一个卷积层,在第二分支中包括两个串联的卷积层,在第三分支中包括三个串联的卷积层,在第四分支中包括串联的均值池化层和卷积层,这四个分支共同汇接到一个连接层。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,所述检测模块包括fasterrcnn网络,所述fasterrcnn网络包括4个部分:第一,特征提取部分,使用连续的卷积加池化操作从原图提取特征,获取特征图,该部分可以进行替换,换成其他分类网络;第二,区域建议网络部分,通过网络训练的方式从特征图中获取前景目标的大致位置;第三,roipooling部分,利用前面获取到的区域建议框,从特征图中抠出要用于分类的特征图区域,并池化成固定长度的数据;第四,全连接部分,利用全连接网络对前面提取的特征图区域进行类别分类和边框回归,从而得到最终的类别概率和定位框。
在本发明用于肠道息肉检测识别的智能辅助系统另一实施例中,所述检测模块包括yolo检测网络,所述yolo检测网络采用网络模型darknet网络,共包含53个卷积层,采用leakyrelu为激活函数,并且整个网络没有池化层,使用卷积的步长为2完成降采样。
本发明的有益效果是:本发明公开了一种用于肠道息肉检测识别的智能辅助系统。该系统包括肠道影像采集单元、肠道息肉检测单元和肠道检测显示单元,其中,肠道影像采集单元用于对肠道影像的采集,然后将肠道影像输入到肠道息肉检测单元进行肠道息肉的定位和识别,肠道检测显示单元则对肠道影像进行视频呈现的同时,还能在肠道影像上同步标注显示肠道息肉的检测信息。该系统能够接入多种不同类型的肠道影像设备,通用性强,检测单元采用深度学习的方法大大提高了对肠道息肉的定位和识别的准确度,并且与肠道影像实时同步显示,提高了检测效率和便利性。
附图说明
图1是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例的组成框图;
图2是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的检测单元组成框图;
图3是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的网络训练示意图;
图4是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的第一检测模块实施例组成框图;
图5是图4所示第一检测模块实施例中的第一卷积检测组和第二卷积检测组的内部组成示意图;
图6是图4所示第一检测模块实施例中的第三卷积检测组至第五卷积检测组的内部组成示意图;
图7是图4所示第一检测模块实施例中的第六卷积检测组内部组成示意图;
图8是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的第二检测模块实施例组成框图;
图9是图8所示第二检测模块实施例中的第一级检测组的内部组成示意图;
图10是图8所示第二检测模块实施例中的inception结构组成示意图;
图11是图8所示第二检测模块实施例中的第五级检测组的内部组成示意图;
图12是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的第三检测模块实施例组成框图;
图13是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的第四检测模块实施例组成框图;
图14是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的损失函数收敛图;
图15是根据本发明用于肠道息肉检测识别的智能辅助系统一实施例中的检测效果图。
具体实施方式
为了便于理解本发明,下面结合附图和具体实施例,对本发明进行更详细的说明。附图中给出了本发明的较佳的实施例。但是,本发明可以以许多不同的形式来实现,并不限于本说明书所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
需要说明的是,除非另有定义,本说明书所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是用于限制本发明。本说明书所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
图1显示了本发明用于肠道息肉检测识别的智能辅助系统一实施例的组成框图。在图1中包括:肠道影像采集单元1、肠道息肉检测单元2和肠道检测显示单元3,其中,肠道影像采集单元1用于对肠道影像的采集,然后将肠道影像输入到肠道息肉检测单元2进行肠道息肉的定位和识别,肠道检测显示单元3则对肠道影像进行呈现的同时还能在肠道影像上同步标注显示肠道息肉检测信息。
优选的,对于肠道影像采集单元包括肠道内镜探测设备,该设备通过传感器及图像处理装置能够检测肠道内部清晰、高质量的图像,通过dvi视频接将采样得到的数据输出。例如,奥林巴斯(olympus)公司的cv-290电子内镜探测设备。cv-290电子内镜探测设备是通过传感器及图像处理装置提供了清晰、高质量的图像,并融合双焦距、nbi窄带成像、afi自体荧光成像等技术,通过dvi视频接将采样得到的数据输出。
进一步的,如图2所示,肠道息肉检测单元还进一步包括转换模块21、检测模块22和显示模块23。
优选的,转换模块21用于将从肠道影像采集单元传送过来的视频数据进行格式转换,以及对每一帧图像进行裁剪等处理。
优选的,在格式转换中包括把dvi数字视频接口传递过来的视频信号转换为usb接口的数字视频信号。进一步的,还可以对数字视频信号进一步优化处理,包括对画面色彩、亮度、对比度等参数进行设置和调整。
优选的,视频格式包括yuy2和rgg24,输出分辨率包含1280*720、1920*1080等10种,帧率从25fps-60fps可调,传输速率最高可达2.97gb/s。
优选的,通过裁剪可以将输入的单帧图像由像素1920*1080裁剪为像素是300*300,然后输入到检测模块中。
优选的,转换模块21的数据源来源于cv-290电子内镜探测设备的数据采集模块,数据经转换模块21处理完毕后输出给下游的检测模块22。格式转换的目的是为了将olympuscv-290主机采集到的dvi格式转换成数据处理模块所需要的usb格式,方便数据的后续处理。
优选的,转换模块21采用tyhd采集卡实现视频格式转换功能,该采集卡的驱动采用微软标准的avstream架构,可以直接调用directshow接口进行数据格式的处理。另一方面,用户既可调用libxistream接口,通过c语言完成对视频信号的进一步优化处理,采用设置回叫函数的方式访问视频帧信息,又可以调用libxiproperty接口访问画面色彩、亮度、对比度等参数。通过调用api完成参数设置,通过c语言编程完成信号的格式转换功能,并可兼容windowsmediaencoder、adobeflashmedialiveencoder、realproducerplus等软件,方便与其他软件协同联合处理。该采集卡的输出接口包含usb多种接口标准,以适配不同的传输速率,输出色彩空间为yuy2和rgg24两种模式,输出分辨率包含1280*720、1920*1080等10种,帧率从25-60fps可调,传输速率最高可达2.97gb/s,其内部存储结构采用64mb的ddr2,工作频率为300mhz,满足实时分析、响应、处理的设计需求。
进一步的,转换模块21还进一步将格式转换过来的数据进行预处理,完成从摄像头获取数据到送入检测模块之间的所有工作。包含视频获取、读取原始分辨率、获取每一帧图像、图像裁剪等几个部分。具体包括的步骤是:视频获取,使用cv2中的函数videocapture()实现对输入视频流信号的捕捉,videocapture的内置参数为视频路径,并将捕获的数据存入变量video_cap中;读取原始分辨率,在获取到视频信号之后,通过set(cv2.cap_prop_frame_width,2000)和set(cv2.cap_prop_frame_width,2000)来获取变量video_cap的真实分辨率;获取每一帧图像,使用cv2中read()函数获取输入视频信号的每一帧数据,并将每一帧数据保存在frame中;图像裁剪,对得到的frame中的每一帧图像进行裁剪,并送入检测模块进行检测。
进一步的,对于检测模块而言,优选采用基于卷积神经网络的目标检测网络对肠道内窥镜图像进行检测,因此需要预先对检测模块进行训练,考虑到实际结肠镜检查中光照,角度等因素对息肉的影响,于是在训练之前,对输入的训练图片进行扩增,主要使用的扩增方式包括:随机旋转变换,随机将图像旋转一定角度;随机缩小并填充变换,缩小图片之后,填充形状为原始尺寸;对比度变换,通过改变图像像元的亮度值来改变图像像元的对比度。由此,得到的图像数据集中包含了多种尺度的息肉,以及高亮度条件下的图片数据,有利于增强网络的鲁棒性。
检测模块是本发明系统的核心模块。主要工作是对采集到的肠道视频信号进行实时检测,并将检测到的结果进行画框标注显示出来。优选的,该模块主要由mxnet,caffe,tensorflow,torch,theano等多种深度学习框架实现核心检测处理得到检测结果,使用自定义函数label_map_util读取息肉标签信息,最后使用自定义函数vis_utils接收图像,对图像执行一些可视化操作。
mxnet,caffe,tensorflow,torch,theano等多种深度学习框架部分主要包括的步骤有:加载训练好的模型,读取标签信息,检测算法,显示模块。其中,加载预训练好的模型:使用函数tf.gfile.gfile()获取文本操作句柄,类似于python提供的文本操作open()函数,filename是要打开的文件名,mode是以何种方式去读写,将会返回一个文本操作句柄。然后使用read()函数读取数据,之后进行函数解析。最终获得预训练好的模型里的参数和图表等信息;读取标签信息:使用自定义函数读取事先定义好的数据标签信息,以便于在输出结果中显示出标签信息;检测算法:该算法首先读取到视频数据采集模块采集的每一帧信号,然后使用cv2中的read()函数判断每一帧信号是否为真,如果是,则进行定位检测处理,否则就跳出。然后使用numpy函数对数组进行处理,转化为计算机语言,送入到mxnet,caffe,tensorflow,torch,theano等多种深度学习框架的模块中进行定位检测,最总得到检测结果:定位框、标签信息和阈值得分。三类信息一一对应,并以元组,列表,集合嵌套的格式存储。定位检测算法实现主要还是依赖于mxnet,caffe,tensorflow,torch,theano等多种深度学习框架中的特有的函数结构。利用检测模块对图像进行目标检测,得出病灶的定位框和类别概率值,最后经过非极大值抑制,进而得到最终的定位框和类别概率。
对于显示模块,进一步优选的,检测模块得到了所有目标的检测结果,得到的每组结果将在显示模块中画出。显示模块在函数中实现时,使用python中导入的pil图像处理库中的imagefont、imagedraw、imagecolor等函数,设置了输出框的粗细、颜色、字体大小等属性。
优选的,检测模块和显示模块还可以通过单独的视频图像处理硬件电路来实现,例如采用jetson板卡作为硬件实现平台,完成视频图像的采集、数据格式转换、定位检测处理和视频显示控制。这样,由前述的cv-290电子内镜探测设备采集的肠道图像信息并不是直接显示到显示屏上,而是接入到jetson卡的视频输入口,这样在jetson板卡完成转换和检测功能后,再在原有的肠道图像信息上叠加检测定位结果,然后通过jetson板卡的视频输出口连接显示器,这样由显示器显示的肠道图像就可以叠加显示有定位指示框,实现对肠道内息肉的辅助定位识别检测。
进一步的,通过上述肠道影像采集单元,如cv-290电子内镜探测设备输出的dvi数字视频信号接入到tyhd采集卡进行格式转换,转换为usb格式,这样转换模块21实现dvi到usb格式的转换,然后再接入到jetson板卡的usb接口,其中的检测模块完成对息肉的实时精确定位,软件设计结合算法模块和输入视频流,最后同步显示检测结果,而显示模块23实现视频数据以hdmi、usb、dvi、vga等多种视频接口方式进行传输与显示。
优选的,对于检测模块,使用mxnet,caffe,tensorflow,torch,theano等多种深度学习框架来构建目标检测网络,使用python开发语言进行代码编写,在ubuntu系统环境下进行模型的训练。硬件环境为nvidiagtx1080ti显卡。
优选的,对于检测模块的训练,如图3所示,对于检测模块中的神经网络,通过训练使得神经网络中的参数值不断的调整,使输出的坐标和类别结果无限接近真实值,最终使损失函数(图3中的交叉熵,用于求目标值与预测值之间的差距)达到最小值。神经网络的初始值一开始是人工赋予的,随着训练的进行,网络的参数逐渐调整,直到该神经网络收敛。该图3中的标注信息是指使用标注软件,对样本图片中的病灶部位进行标注,包含位置信息和类别信息,表示图像中病灶的真实信息。
优选的,为了在规模较小的数据集上训练出准确度高的神经网络检测模型,使用coco数据集下的预训练模型参数作为基础网络的初始参数,然后在此基础上进行训练。
进一步的,在检测模块完成训练之后,则需要对转换模块输入的视频信号进行实时检测,并将检测到的结果通过显示模块进行画框标注显示出来。
优选的,检测模块一优选实施例,如图4所示,包括6级依次串联的卷积检测组,其中,第一卷积检测组q1和第二卷积检测组q2具有相同的结构,均是由两个卷积层和一个最大池化层串联而成,第三卷积检测组q3、第四卷积检测组q4和第五卷积检测组q5具有相同的结构,均是由三个卷积层和一个最大池化层串联而成,第六卷积检测组q6则包括9个卷积层串联而成。进一步,第四卷积检测组q4有一个卷积层输出特征图至检测识别组q7,而第六卷积检测组q6则有五个卷积层分别输出特征图至检测识别组q7。
进一步的,如图5所示,显示了第一卷积检测组q1和第二卷积检测组q2的内部组成,在第一卷积检测组q1中,包括第一输入卷积层q11、第一输出卷积层q12和第一最大池化层q13,第一输入卷积层q11的卷积核为3*3,通道数为64,每一通道输出的像素值300*300,第一输出卷积层q12的结构与第一输入卷积层q11的结构完全相同,即第一输出卷积层q12的卷积核为3*3,通道数为64,每一通道输出的像素值300*300,第一最大池化层q13为2*2,通道数为64,每一通道输出的像素值150*150;与第一卷积检测组q1类似,在第二卷积检测组q2中,包括第二输入卷积层q21、第二输出卷积层q22和第二最大池化层q23,第二输入卷积层q21的卷积核为3*3,通道数为128,每一通道输出的像素值150*150,第二输出卷积层q22的结构与第一输入卷积层q21的结构完全相同,即第二输出卷积层q22的卷积核为3*3,通道数为128,每一通道输出的像素值150*150,第二最大池化层q23为2*2,通道数为128,每一通道输出的像素值75*75。
进一步的,如图6所示,显示了第三卷积检测组q3至第五卷积检测组q5的内部组成。在第三卷积检测组q3中,包括第三输入卷积层q31、第三中间卷积层q32、第三输出卷积层q33和第三最大池化层q34,第三输入卷积层q31至第三输出卷积层q33的卷积核为3*3,通道数均为256,每一通道输出的像素值均为75*75,第三最大池化层q34为2*2,通道数为256,每一通道输出的像素值38*38;在第四卷积检测组q4中,包括第四输入卷积层q41、第四中间卷积层q42、第四输出卷积层q43和第四最大池化层q44,第四输入卷积层q41至第四输出卷积层q43的卷积核为3*3,通道数均为512,每一通道输出的像素值均为38*38,第四输出卷积层q43还输出到输出特征图至检测识别组q7,第四最大池化层q44为2*2,通道数为512,每一通道输出的像素值19*19;在第五卷积检测组q5中,包括第五输入卷积层q51、第五中间卷积层q52、第五输出卷积层q53和第五最大池化层q54,第五输入卷积层q51至第五输出卷积层q53的卷积核为3*3,通道数均为512,每一通道输出的像素值均为19*19,第五最大池化层q54为2*2,通道数为512,每一通道输出的像素值19*19。
进一步的,如图7所示,显示了第六卷积检测组q6的内部组成,包括10个卷积子层,依次是串联的第1级卷积子层q61至第10级卷积子层q610,其中第1级卷积子层q61的卷积核为3*3,通道数为1024,每一通道输出的像素值19*19;第2级卷积子层q62的卷积核为1*1,通道数为1024,每一通道输出的像素值19*19,第2级卷积子层q62还输出特征图至检测识别组q7;第3级卷积子层q63的卷积核为1*1,通道数为256,每一通道输出的像素值19*19;第4级卷积子层q64的卷积核为3*3,通道数为512,每一通道输出的像素值10*10,第4级卷积子层q64还输出特征图至检测识别组q7;第5级卷积子层q65的卷积核为1*1,通道数为128,每一通道输出的像素值10*10;第6级卷积子层q66的卷积核为3*3,通道数为256,每一通道输出的像素值5*5,第6级卷积子层q66还输出特征图至检测识别组q7;第7级卷积子层q67的卷积核为1*1,通道数为128,每一通道输出的像素值5*5;第8级卷积子层q68的卷积核为3*3,通道数为256,每一通道输出的像素值3*3,第8级卷积子层q68还输出特征图至检测识别组q7;第9级卷积子层q69的卷积核为1*1,通道数为128,每一通道输出的像素值3*3;第10级卷积子层q610的卷积核为3*3,通道数为256,每一通道输出的像素值1*1,第10级卷积子层q610输出特征图至检测识别组q7。
进一步,图8显示了检测模块另一优选实施例的组成框图,包括前后级联的五级检测组和检测输出组。其中,第一级检测组j1包括串联的卷积层和池化层,第二级检测组j2包括两级串联的inception结构,第三级检测组j3包括四级串联的inception结构,第四级检测组j4包括两级串联的inception结构,第五级检测组j5包括串联的卷积层和池化层,第三级检测组j3和第四级检测组j4分别有一路输出至检测输出组s1,第五级检测组j5则有三路输出至检测输出组s1,由检测输出组s1输出最终检测结果。
其中,第一级检测组j1包括五层,如图9所示,从左至右依次是第一卷积层j11、第一最大池化层j12、第二卷积层j13、第三卷积层j14、第二最大池化层j15,其中,第一卷积层j11的卷积核为7*7,通道数为64,每一通道输出的像素值均为150*150;第一最大池化层j12为3*3,通道数为64,每一通道输出的像素值75*75;第二卷积层j13的卷积核为1*1,通道数为64,每一通道输出的像素值均为75*75;第三卷积层j14的卷积核为3*3,通道数为192,每一通道输出的像素值均为75*75;第二最大池化层j15为3*3,通道数为192,每一通道输出的像素值38*38。
进一步的,第二级检测组j2包括两级串联的inception结构,如图10所示,这两级inception结构均具有相同结构组成的四个分支,区别在于分支中的通道数有所不同。
优选的,对于第一级inception结构,结构图如图10所示,在第一分支b1中包括一个卷积层b11,卷积核为1*1,通道数为64;在第二分支b2中包括两个串联的卷积层,第一卷积层b21的卷积核为1*1,通道数为64,第二卷积层b22的卷积核为3*3,通道数为64;在第三分支b3中包括三个串联的卷积层,第一卷积层b31的卷积核为1*1,通道数为64,第二卷积层b32的卷积核为3*3,通道数为96,第三卷积层b33的卷积核为3*3,通道数为96;在第四分支b4中包括一个均值池化层b41和一个卷积层b42,均值池化层b41为3*3,卷积层b42的卷积核为1*1,通道数为32。因此,对于第一级inception结构共有256个通道,每个通道输出的像素值均为38*38。这四个分支通过共同汇接到一个连接层l1。
对于第二级inception结构,结构图如图10所示,与第一级inception具有相同的结构,区别在于:第二分支b2中的第二卷积层b22的通道数为96,第四分支b4中的卷积层b42的通道数为64。
在第二级检测组j2和第三级检测组j3之间串联的是第一组间均值池化层,为3*3,经过该第一组间均值池化层输出的像素为19*19,通道数为320。
第三级检测组j3包括四级串联的inception结构,如图10所示,这四级inception结构均具有相同结构组成的四个分支,区别在于分支中的通道数有所不同。其中,主要区别在于:第一级inception结构中第一分支的卷积层的卷积核为1*1,通道数为224,第二分支中的第一卷积层的卷积核为1*1,通道数为64,第二卷积层的卷积核为3*3,通道数为96;第三分支中的第一卷积层的卷积核为1*1,通道数为96,第二卷积层的卷积核为3*3,通道数为128,第三卷积层的卷积核为3*3,通道数为128;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为128。第二级inception结构中第一分支的卷积层的卷积核为1*1,通道数为192,第二分支中的第一卷积层的卷积核为1*1,通道数为96,第二卷积层的卷积核为3*3,通道数为128;第三分支中的第一卷积层的卷积核为1*1,通道数为96,第二卷积层的卷积核为3*3,通道数为128,第三卷积层的卷积核为3*3,通道数为128;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为128。第三级inception结构中第一分支的卷积层的卷积核为1*1,通道数为160,第二分支中的第一卷积层的卷积核为1*1,通道数为128,第二卷积层的卷积核为3*3,通道数为160;第三分支中的第一卷积层的卷积核为1*1,通道数为128,第二卷积层的卷积核为3*3,通道数为160,第三卷积层的卷积核为3*3,通道数为160;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为96。第四级inception结构中第一分支的卷积层的卷积核为1*1,通道数为96,第二分支中的第一卷积层的卷积核为1*1,通道数为128,第二卷积层的卷积核为3*3,通道数为192;第三分支中的第一卷积层的卷积核为1*1,通道数为160,第二卷积层的卷积核为3*3,通道数为192,第三卷积层的卷积核为3*3,通道数为192;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为96。
在第三级检测组j3和第四级检测组j4之间串联的是第二组间最大池化层,为3*3,经过该第二组间最大池化层输出的像素为10*10,通道数为576。
第四级检测组j4包括两级串联的inception结构,如图10所示,这两级inception结构均具有相同结构组成的四个分支,第一级inception结构中第一分支的卷积层的卷积核为1*1,通道数为352,第二分支中的第一卷积层的卷积核为1*1,通道数为192,第二卷积层的卷积核为3*3,通道数为320;第三分支中的第一卷积层的卷积核为1*1,通道数为160,第二卷积层的卷积核为3*3,通道数为224,第三卷积层的卷积核为3*3,通道数为224;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为128。第二级inception结构中第一分支的卷积层的卷积核为1*1,通道数为352,第二分支中的第一卷积层的卷积核为1*1,通道数为192,第二卷积层的卷积核为3*3,通道数为320;第三分支中的第一卷积层的卷积核为1*1,通道数为160,第二卷积层的卷积核为3*3,通道数为224,第三卷积层的卷积核为3*3,通道数为224;第四分支b4中的均值池化层为3*3,卷积层的卷积核为1*1,通道数为128。
以上网络结构中采用了inception结构,主要是可以增加网络的宽度和深度,实现了对特征的多维度的提取,从而提取了更多的特征,再就是其中采用了尺寸为1*1的卷积核对数据进行降维,减小了网络的计算量。
第五级检测组j5包括八级依次串联的卷积层,如图11所示,第一级卷积层j51的卷积核为1*1,通道数为256,第二级卷积层j52的卷积核为3*3,通道数为512,第三级卷积层j53的卷积核为1*1,通道数为128,第四级卷积层j54的卷积核为3*3,通道数为256,第五级卷积层j55的卷积核为1*1,通道数为256,第六级卷积层j56的卷积核为3*3,通道数为128,第七级卷积层j57的卷积核为1*1,通道数为128,第八级卷积层j58的卷积核为3*3,通道数为64。
优选的,图8中的检测输出组s1对6个特征图以选择框的方式输出,例如这六个特征图中分别包括的选择框的个数为[4,6,6,6,4,4],而这些选择框的尺寸比例还可以进一步限定,第一特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0],第二特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0,0.5,0.33],第三特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0,0.5,0.33],第四特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0,0.5,0.33],第五特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0],第六特征图中各个选择框的归一化比例为[1.0,1.25,2.0,3.0]。这些选择框汇总后作为候选目标,然后再经过非极大值抑制得到有效目标的选择框。
以上图4至图11中的网络结构参数设置是通过大量的训练实验不断优化调整得到的,由此获得了对息肉检测的高准确率和高时效性。
进一步,如图12显示检测模块另一优选实施例,采用ssd(singleshotmultiboxdetector)网络结构。ssd是一个前向传播的cnn网络,基于事先设定好的不同宽高比的定位框,预测每一个定位框的偏移量以及每一个定位框包含物体的类别概率,之后对符合要求的定位框进行非极大值抑制,最终得出预测的定位框和类别概率。
从图12可以看出ssd网络包括两个部分:基础特征提取网络和金字塔网络。基础网络是vgg-16网络改造而来,使用前面的前5层,然后利用astrous算法将fc6和fc7层转化成两个卷积层,再额外增加了3个卷积层和1个均值池化层。金字塔网络是对逐渐变小的特征图进行卷积处理,不同层次的特征图分别用于选择框的偏移以及不同类别得分的预测。
这些增加的卷积层的特征图变化比较大,允许能够检测出不同尺度下的物体:在低层的特征图感受野比较小,高层的感受野比较大,在不同的特征图进行卷积,可以达到多尺度的目的。
ssd去掉了全连接层,每一个输出只会感受到目标周围的信息,包括上下文。这样来做就增加了合理性。并且不同的特征图预测不同宽高比的图像,这样增加了预测更多的比例的选择框。ssd网络通过对不同的特征层进行卷积操作,直接预测坐标和类别,这样就可以对原图中不同尺度的物体进行检测。
进一步,如图13显示检测模块另一优选实施例,采用fasterrcnn网络,该目标检测网络的优点是使用网络训练来获取区域建议框,而且需要的时间非常短,使得整个网络的检测、分类速度大幅提升。
该fasterrcnn个网络由4个部分构成:第一,特征提取部分:使用连续的卷积加池化操作从原图提取特征,获取特征图,该部分可以进行替换,换成其他分类网络;第二,区域建议网络部分:这部分是fasterrcnn全新提出的结构,也是整个网络最大的改进地方,作用是通过网络训练的方式从特征图中获取前景目标的大致位置;第三,roipooling部分:利用前面获取到的区域建议框,从特征图中抠出要用于分类的特征图区域,并池化成固定长度的数据,方便后面的卷积操作;第四,最后的全连接部分:利用全连接网络对前面提取的特征图区域进行类别分类和边框回归,从而得到最终的类别概率和定位框。
fasterrcnn的主要贡献在于提出了rpn来进行高效而准确的区域提议。这种网络与检测网络共享卷积层,而且区域建议的过程基本上不消耗时间,该方法使统一的,端到端的目标检测系统能够以接近实时的帧率运行,通过训练学习的rpn也提高了区域提议的质量,从而提高了整体的目标检测精度。
进一步,在检测模块另一优选实施例中,采用yolo目标检测网络,该网络是josephredmon等人在yolov1版本基础上不断升级改进而来,该网络可以实现端到端的目标检测。
yolo目标检测网络的核心思想是将图片分成s×s的网格,每个网格有b个boxbounding,相应的每个boxbounding有一个confindence,四个box位置,c个类别概率。如果物体的中心坐标落在某个格子中,那么这个格子就负责检测这个物体(包括boundingbox的坐标和类别概率)。yolo目标检测网络借鉴fasterrcnn的anchorbox思想,去掉了早期版本的全连接层,使用anchorboxes来预测boundingboxes,同时采用加快收敛速度和多尺度训练技术。
优选的,yolo目标检测网络采用多尺度对不同大小的目标进行检测,在保证速度的前提下提高了精度。进一步的,yolo目标检测网络采用一种新的网络模型darknet网络,共包含53个卷积层,采用leakyrelu为激活函数,并且整个网络没有池化层,使用卷积的步长为2完成降采样。为增加对小目标的检测,没有像ssd那样直接采用backbone中间层的处理结果作为featuremap的输出,而是和后面网络层的上采样结果进行一个拼接之后的处理结果作为特征图。最终输出了3个不同尺度的特征图,分别是13*13*1255,26*126*1255,52*152*1255。
优选的,为了验证本发明的检测特性,本发明的训练过程是在ubuntu系统环境下使用python进行的。所有实验均采用mxnet,caffe,tensorflow,torch,theano等多种深度学习框架来实现软件库。整个训练过程使用梯度下降及反向传播算法来学习网络参数。训练的批次处理大小batch为32,动量(momentum)为0.9,权重衰减(decay)为0.0005,最大迭代次数为60000次。初始化网络训练的初始学习率为0.004,decay_steps为15000,decay_factor为0.9。训练过程中模型的损失函数收敛曲线如图14所示,由图可知,损失函数随着迭代次数的增加越来越接近于0,网络是稳定收敛的。
优选的,还选取了检测性能指标,包括iou(交并比):即intersection-over-union,表示检测结果dr(detectionresult)与真实标注框groundtruth的交集比上它们的并集,即为iou。
其中,j+1表示检测图片的总数,i表示被检测图片的标号,dri表示第i张检测结果,gti表示第i张的真实值。
第二个指标是敏感性:是测试集中所有正样本比例中,被正确识别为正样本的比例。公式如下:
其中,tp(truepositives,tp)为正样本被正确识别为正样本的数量,fn(falsenegatives,fn)为正样本被错误识别为负样本的数量。
第三个指标是特异性:是测试集中所有负样本比例中,被正确识别为负样本的比例。公式如下:
其中,tn(truenegatives,tn)为负样本中被正确识别为负样本的数量,fp(falsepositives,fp)为负样本被错误识别为正样本的数量。
第四个指标是准确率(accuracy):为所有样本中检查正确的比例。公式如下:
为了进一步评估本发明实施例的检测性能,我们在同一数据集上评估了第一实施例(图4对应的实施例),第二实施例(图8对应的实施例)在iou、敏感性、特异性方面的性能,如表一所示。
表一:两种实施例检测性能对比
从图15可以看出,结肠镜下息肉检测定位算法取得了较好的结果。并且能够在检测视频中实时呈现检测目标对应的选择框及检测概率。
由此可见,本发明公开了一种用于肠道息肉检测识别的智能辅助系统。该系统包括肠道影像采集单元、肠道息肉检测单元和肠道检测显示单元,其中,肠道影像采集单元用于对肠道影像的采集,然后将肠道影像输入到肠道息肉检测单元进行肠道息肉的定位和识别,肠道检测显示单元则对肠道影像进行视频呈现的同时,还能在肠道影像上同步标注显示肠道息肉的检测信息。该系统能够接入多种不同类型的肠道影像设备,通用性强,检测单元采用深度学习的方法大大提高了对肠道息肉的定位和识别的准确度,并且与肠道影像实时同步显示,提高了检测效率和便利性。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!