以Python为接口C++实现的字符布隆过滤器的制作方法
本发明涉及一种布隆过滤器,具体涉及一种以python为接口c++实现的字符布隆过滤器。
背景技术:
布隆过滤器(bloomfilter)是一个很长的二进制向量和一系列随机映射函数,可以用于检索一个元素是否在一个集合中。由于c++是静态编译型语言,可以直接编译成机器码,有较高的执行效率。另外,python是一种面向对象、解释型的计算机程序设计语言,它具有语法简单、跨平台、公用库多等特点,因此python也得到了广泛的使用。因此将这2种语言的优势结合来实现字符布隆过滤器,有较高的实用性和易用性。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法。一般将过滤器使用在极大规模数据集的场景下,对程序的执行效率有较高的要求。
因此,需要对现有技术进行改进。
技术实现要素:
本发明要解决的技术问题是提供一种高效的以python为接口c++实现的字符布隆过滤器。
为解决上述技术问题,本发明提供一种以python为接口c++实现的字符布隆过滤器,包括以下步骤:
1)、输入数据;
2)、c++实现布隆过滤器并编译成动态链接库;
3)、将数据通过调用动态链接库传输给c++程序模块;
4)、计算出字符的哈希值分布到布隆过滤器的二进制向量中,判断数据是否已经存在,如果已存在,则返回已存在,否则返回不存在。
作为对本发明以python为接口c++实现的字符布隆过滤器的改进:还包括以下步骤:
5)、python输出步骤4得到的返回结果。
作为对本发明以python为接口c++实现的字符布隆过滤器的进一步改进:
在步骤1中:
字符通过python代码接口进入系统,用python实现http接口或者python主动拉取数据的方式输入数据。
作为对本发明以python为接口c++实现的字符布隆过滤器的进一步改进:
在步骤3中:
python将拿到的数据通过调用动态链接库传输给c++程序模块。
作为对本发明以python为接口c++实现的字符布隆过滤器的进一步改进:
在步骤4中:
c++利用8种不同的哈希函数算法,分别计算出字符的不同哈希值,分布到布隆过滤器的二进制向量中,判断数据是否已经存在,如果8个位置的向量状态都表示被占用,则返回已存在,否则返回不存在;返回结果给python。
作为对本发明以python为接口c++实现的字符布隆过滤器的进一步改进:
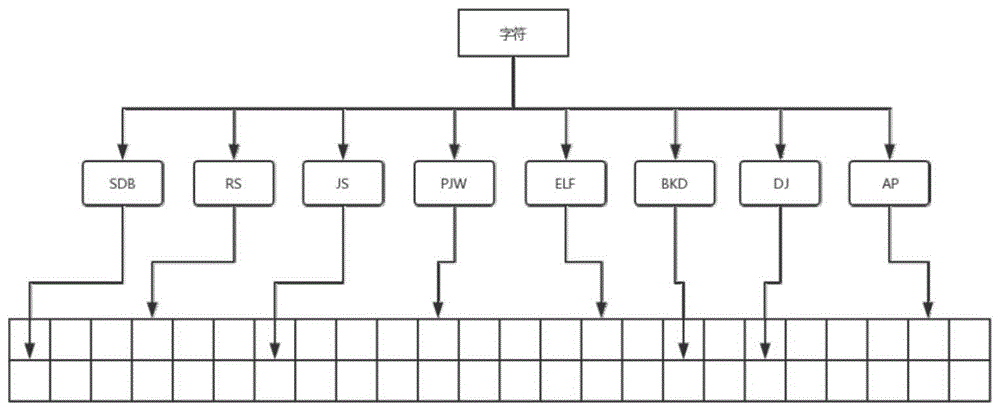
哈希函数算法包括sdbmhash,rshash,jshash,pjwhash,elfhash,bkdrhash,djbhash,aphash。
作为对本发明以python为接口c++实现的字符布隆过滤器的进一步改进:
如果哈希值对应的向量位置为空,则设置该位置的向量值,二进制状态从0变成1。
本发明以python为接口c++实现的字符布隆过滤器的技术优势为:
本发明对于程序开发人员而言,可以减少使用布隆过滤器的学习成本和时间,通过使用简单的python接口,不损失程序的执行效率,达到执行速度和开发效率的双赢。
本发明将c++的高效执行效率和python的高效开发效率结合起来,大大地提高程序的开发效率和执行速度。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细说明。
图1为布隆过滤器原理图;
图2为本发明以python为接口c++实现的字符布隆过滤器的结构示意图。
具体实施方式
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此。
实施例1、以python为接口c++实现的字符布隆过滤器,如图1-2所示,包括以下步骤:
1)、字符通过python代码接口进入系统,用python实现http接口或者python主动拉取数据的方式输入数据,充分利用python开发的便利和快速来适应不同数据源;
2)、c++实现布隆过滤器并编译成动态链接库,字符数据的处理交给c++来实现,充分利用机器的底层性能来加速代码执行效率;
在内存空间申请一块较大的二进制向量存储空间,空间越大布隆过滤器的检测误判率越低;
3)、python将拿到的数据通过调用动态链接库传输给c++程序模块;
4)、c++利用8种不同的哈希函数(sdbmhash,rshash,jshash,pjwhash,elfhash,bkdrhash,djbhash,aphash)算法,分别计算出字符的不同哈希值,分布到布隆过滤器的二进制向量中,判断数据是否已经存在,如果8个位置的向量状态都表示被占用,则返回已存在,否则返回不存在;返回结果给python;
如果哈希值对应的向量位置为空,则设置该位置的向量值(二进制状态从0变成1)。如果哈希值对应的向量位置都已被设置值则返回信息说明该字符哈希值重复;
5)、python拿到结果(步骤4得到的返回结果)可以输出返回不同的方向,如http接口,文件,数据库等。
1、以下功能由c++语言实现:
1.1、在内存空间申请一块较大的二进制向量存储空间,空间越大布隆过滤器的检测误判率越低;
1.2、被检测字符进入系统,通过8个不同的哈希函数算法计算出8个不同的哈希值;
1.3、将哈希值映射到布隆过滤器的二进制向量中,如果哈希值对应的向量位置为空,则设置该位置的向量值。如果哈希值对应的向量位置已被设置值则返回信息说明该字符哈希值重复
1.4、计算8个映射结果,如果8个结果都为重复则返回最终结果为该字符已在布隆过滤器中重复出现。
映射结果可以通过哈希值和存储空间大小计算得出,举例其中一个简单算法:哈希值为155,空间大小为10个向量位,通过计算155除以10取余为5,映射结果为向量位第5位置。
2、将以上用c++实现的功能代码通过g++编译器编译成一个libbloomfilter模块(与python将拿到的数据通过调用动态链接库传输给c++类似),成为一个动态链接库;
3、以下功能由python语言实现;
3.1、通过数据库协议链接待处理的数据库和保存处理结果的数据库,从源数据库提取需要检测的数据;
3.2、导入libbloomfilter模块;
3.3、将检测字符输入libbloomfilter模块,并从libbloomfilter模块拿到返回结果;
3.4、判断结果是否重复字符,如果是未重复的字符输出到结果数据库;
从libbloomfilter模块返回的一个结果是布尔值,python程序根据布尔值来判断是输出的字符串是否为重复。
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!