一种基于Wi-Fi指纹库文本分类的室内房间级定位方法与流程
本发明涉及一种基于wi-fi指纹库文本分类的室内房间级定位方法,主要是使用文本分类的方法对wi-fi指纹库进行室内房间级定位。
背景技术:
随着移动通信和普适计算技术的飞速发展,各种应用都在广泛尝试各种技术进行室内定位。
目前技术如基于gps的室外定位、基于地磁、rfid、zigbee网络、蓝牙等的室内定位技术。基于wi-fi的定位主要分为两类:基于位置指纹的方法和基于信号传播模型的方法。其中基于指纹的室内定位系统采用由多个接入点(aps)及其信号强度(rssi)组成wi-fi指纹。但是wi-fi信号容易受到环境因素的影响如墙壁、门、家具甚至人。此外,它可能来自个人访问点或临时热点。因此,智能手机接收到的wi-fi信号强度,即rssi,并不是恒定和稳定的。
技术实现要素:
本发明的目的是克服现有技术中的不足,提供一种基于wi-fi指纹库文本分类的室内房间级定位方法。
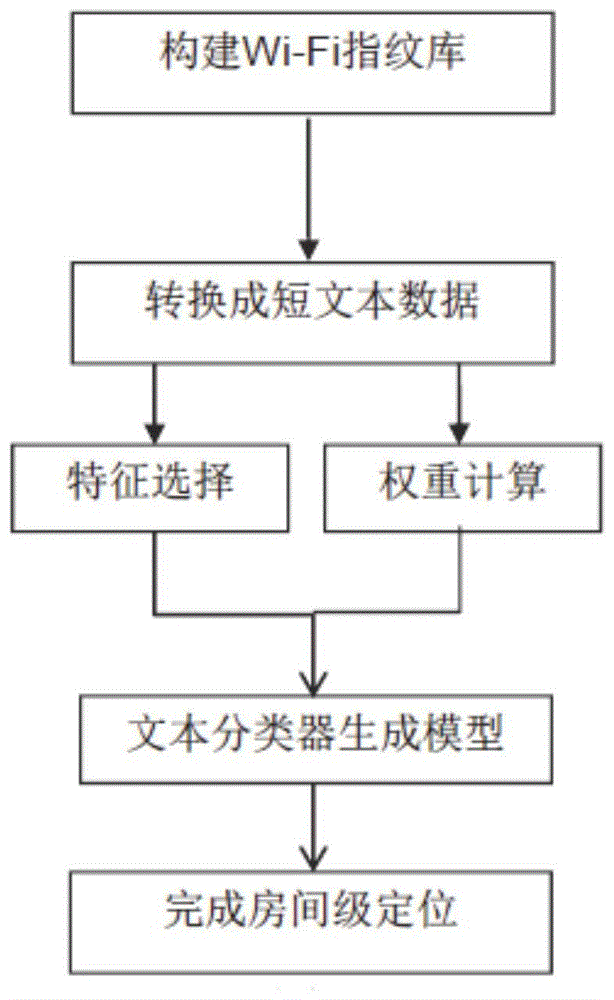
这种基于wi-fi指纹库文本分类的室内房间级定位方法,包括以下步骤:
步骤1、首先采集商场室内环境中的wi-fi信号强度以及基本服务集标识符;统计基本服务集标识符出现的次数,将基本服务集标识符出现次数小于5次的数据剔除;构建wi-fi指纹库;所述wi-fi指纹库中有标签s={s1,…,sr},si为商场中第i编号的商铺标签;
将剔除后的基本服务集标识符替换成接入点aps={ap1,…,apn},wi-fi指纹库的wi-fi信号强度为f={f1,…,fn},其中n为特征个数;fi为接入点api的信号强度值,i的范围为[1,n],fi的范围为(-100,0);
步骤2、将wi-fi指纹库转换成短文本数据:将wi-fi信号强度大小和接入点aps的标签结合生成短文本单词,多个短文本单词构成一句短句作为特征;将参数α设定为α=10,按照rssi的大小范围进行转换:
如果rssi(apn)>-50,转换成单词为ap_n_1;
如果-60<rssi(apn)<=-50,转成单词为ap_n_2;
如果-70<rssi(apn)<=-60,转换成单词为ap_n_3;
如果-80<rssi(apn)<=-70,转换成单词为ap_n_4;
如果-90<rssi(apn)<=-80,转换成单词为ap_n_5;
如果-100<rssi(apn)<=-90,转换成单词为ap_n_6;
如果rssi(apn)<-100,转换成单词为ap_n_7;
所述rssi为信号强度;n对应apn的下标值;得到短文本数据{sr|ap_k_x},其中x=1,2,3,4,5,6;x的值由上述转换方式得到,k∈n;
从短文本数据中剔除单词ap_n_7,将短文本数据划分成训练集和测试集;
步骤3、进行特征选择和单词权重计算:
步骤3.1、将文档频率df低于阈值的样本特征作为低频特征,将低频特征直接去除;所述文档频率df为样本特征在训练集中出现的次数;
步骤3.2、使用tf-idf函数计算权重:
weight=tf×idf(1)
上式(1)中,weigt为权重,tf为词频,所述词频为单个短文本单词在每行中出现的概率;idf为倒排文档频率,所述倒排文档频率为单个短文本单词在整个列表数据集中出现频数的倒数;上式(2)中,n为包含该特征项的短句个数,n表示整个训练集中短句的个数,用来修正该特征项的偏差;
步骤4、使用crammer-singer支持向量分类器:将一个测试集数据内的测试样本x划分到第r类,使得矩阵m的第r行与测试样本x的内积最大:
hm(x)=argmaxr=1,..,k{mr·x}(3)
上式(3)中,x为测试样本;mr为矩阵的第r行;
将训练集数据输入到文本分类器中,进行训练生成模型;
步骤5、计算分类精度:使用步骤4中产生的模型来对测试集数据进行预测分类,将与实际商铺标签相同的测试集数据作为正例,将与实际商铺标签不同的测试集数据作为负例;计算分类精度:
上式(4)中,tp为正确划分为正例的个数,fp为错误划分为正例的个数,tn为正确划分负例的个数,fn为错误划分为负例的个数。
作为优选,步骤1所述接入点api的信号强度值fi呈正态分布。
作为优选,步骤2所述rssi的值不等于-100,-100对应空信号强度
作为优选,步骤2所述单词ap_n_7对应的信号强度为-100,表示没有检测到wi-fi信号。
作为优选,步骤3.1所述阈值经由实验确定为三次。
作为优选,步骤3.2所述tf-idf函数用于衡量每个特征项权重:若单词在每句短句中出现频率很高,但其他类别短句中出现频率很低,则该特征项区分度高。
本发明的有益效果是:本发明将wi-fi的信号强度转换成短文本单词直接忽略其信号强度大小的影响,不再考虑其信号强度的大小的特征,缩减了wi-fi指纹库;本发明将wi-fi指纹库转换成短文本数据集,缩减了数据维度,同时文本分类器时基于线性核svm分类器,其训练和测试的效率极高,并能大幅度地降低定位时间和提高定位精度。
附图说明
图1为wi-fi室内房间级定位的流程图;
图2为本发明分类精度与参数α的柱状图;
图3为本发明房间级定位的分类精度图。
具体实施方式
下面结合实施例对本发明做进一步描述。下述实施例的说明只是用于帮助理解本发明。应当指出,对于本技术领域的普通人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
本发明提出了一种基于wi-fi指纹库文本分类的房间级定位方法,对于wi-fi的信号强度的大小构建短文本数据,通过分析信号强度的特征对每个特征与接入点进行结合构成单词,最终,每个标签的特征就是多个单词构成的短文本。将wi-fi的信号强度以及接入点(aps)进行结合生成短文本单词,将基于wi-fi指纹库转换成短文本数据集,使用文本分类的方法进行室内房间级室内定位的方法,降低定位时间并能提高定位精度。
这种基于wi-fi指纹库文本分类的室内房间级定位方法,包括以下步骤:
步骤1、首先采集商场室内环境中的wi-fi信号强度以及基本服务集标识符;由于商场环境中存在大量的个人热点,因此需要将其剔除,减少指纹库的维度;统计基本服务集标识符出现的次数,将基本服务集标识符出现次数小于5次的数据剔除;构建wi-fi指纹库;所述wi-fi指纹库中有标签s={s1,…,sr},si为商场中第i编号的商铺标签;原始wi-fi数据集如下表1所示:
表1原始wi-fi数据集
将剔除后的基本服务集标识符替换成接入点aps={ap1,…,apn},wi-fi指纹库的wi-fi信号强度为f={f1,…,fn},其中n为特征个数;fi为接入点api的信号强度值,i的范围为[1,n],fi的范围为(-100,0);构建的wi-fi指纹库如下表2所示:
表2剔除移动热点的wi-fi指纹库
步骤2、将wi-fi指纹库转换成短文本数据:将wi-fi信号强度大小和接入点aps的标签结合生成短文本单词,多个短文本单词构成一句短句作为特征;如何选取合适的信号强度范围,使得分类精度最大,如图2所示,经多次调整α值进行实验,当范围α=10时,分类精度最高为97%;将参数α设定为α=10,按照rssi的大小范围进行转换:
如果rssi(apn)>-50,转换成单词为ap_n_1;
如果-60<rssi(apn)<=-50,转成单词为ap_n_2;
如果-70<rssi(apn)<=-60,转换成单词为ap_n_3;
如果-80<rssi(apn)<=-70,转换成单词为ap_n_4;
如果-90<rssi(apn)<=-80,转换成单词为ap_n_5;
如果-100<rssi(apn)<=-90,转换成单词为ap_n_6;
如果rssi(apn)<-100,转换成单词为ap_n_7;
所述rssi为信号强度;n对应apn的下标值;得到短文本数据{sr|ap_k_x},其中x=1,2,3,4,5,6;x的值由上述转换方式得到,k∈n;wi-fi的信号强度转换成单词表的情况如下表3所示:
表3wi-fi的信号强度转换成单词表
从短文本数据中剔除单词ap_n_7,将短文本数据划分成训练集和测试集;剔除无效数据的短文本数据情况如下表4所示:
表4剔除无效数据的短文本数据表
步骤3、进行特征选择和单词权重计算:
步骤3.1、将文档频率df低于阈值的样本特征作为低频特征,将低频特征直接去除;所述文档频率df为样本特征在训练集中出现的次数;
步骤3.2、使用tf-idf函数计算权重:
weight=tf×idf(1)
上式(1)中,weight为权重,tf为词频,所述词频为单个短文本单词在每行中出现的概率;idf为倒排文档频率,所述倒排文档频率为单个短文本单词在整个列表数据集中出现频数的倒数;上式(2)中,n为包含该特征项的短句个数,n表示整个训练集中短句的个数,用来修正该特征项的偏差;使用tf-idf计算特征权重的情况如下表5:
表5使用tf-idf计算特征权重表
步骤4、使用crammer-singer支持向量分类器:该分类器目的是使得对一个测试集进行分类是的错误概率尽可能小。将一个测试集数据内的测试样本x划分到第r类,使得矩阵m的第r行与测试样本x的内积最大:
hm(x)=argmaxr=1,..,k{mr·x}(3)
上式(3)中,x为测试样本;mr为矩阵的第r行;
将训练集数据输入到文本分类器中,进行训练生成模型;
步骤5、计算分类精度:使用步骤4中产生的模型来对测试集数据进行预测分类,将与实际商铺标签相同的测试集数据作为正例,将与实际商铺标签不同的测试集数据作为负例;计算分类精度:
上式(4)中,tp为正确划分为正例的个数,fp为错误划分为正例的个数,tn为正确划分负例的个数,fn为错误划分为负例的个数。
步骤1所述接入点api的信号强度值fi呈正态分布。
步骤2所述rssi的值不等于-100,-100对应空信号强度
步骤2所述单词ap_n_7对应的信号强度为-100,表示没有检测到wi-fi信号;剔除这些数据减少了数据量,却不影响数据的特征。
步骤3.1所述阈值经由实验确定为三次;即对分类有较少的特征信息量,将这些较少的特征直接去除,能够提高分类速度,降低了特征空间维度。
步骤3.2所述tf-idf函数用于衡量每个特征项权重:若单词在每句短句中出现频率很高,但其他类别短句中出现频率很低,则该特征项区分度高。
实施例:
为了验证该方法定位的效果,本发明使用2017年天池竞赛商铺定位数据集,使用4个商铺(m_615,m_622,m_623,m_625)合并的wi-fi数据进行验证本发明。首先对4个商铺数据剔除移动热点和通信商的热点,构建wi-fi信号强度指纹库,并按照图2所示的方式,将信号强度和aps的编号进行结合构成短文本的单词。短文本数据由商铺名称作为标签,多个单词构成一句短句作为特征。
通过对这短文本数据进行划分,训练集和测试集按照(50%,60%,70%,80%,90%)比例进行实验,输入到文本分类器中计算分类精度。如图3所示,在这商铺数据集中,在不同训练集下与knn,朴素贝叶斯以及随机森林进行对比。从分类精度结果图中可以看出本发明可以基于wi-fi的室内房间级室内分类精度达到97%。
- 还没有人留言评论。精彩留言会获得点赞!