基于自动机器学习的疲劳驾驶预测方法、装置及存储介质与流程
本发明涉及汽车驾驶领域,特别是基于自动机器学习的疲劳驾驶预测方法、装置及存储介质。
背景技术:
疲劳驾驶容易导致驾驶安全隐患。为了加强汽车安全,各汽车生产商均致力于对疲劳驾驶预测进行研究。现阶段自动机器学习快速发展,为了提高疲劳驾驶预测的准确性,将自动机器学习应用到疲劳驾驶预测领域是一个值得研究的课题。
技术实现要素:
本发明的目的在于至少解决现有技术中存在的技术问题之一,提供基于自动机器学习的疲劳驾驶预测方法、装置及存储介质。
本发明解决其问题所采用的技术方案是:
本发明的第一方面,基于自动机器学习的疲劳驾驶预测方法,包括以下步骤:
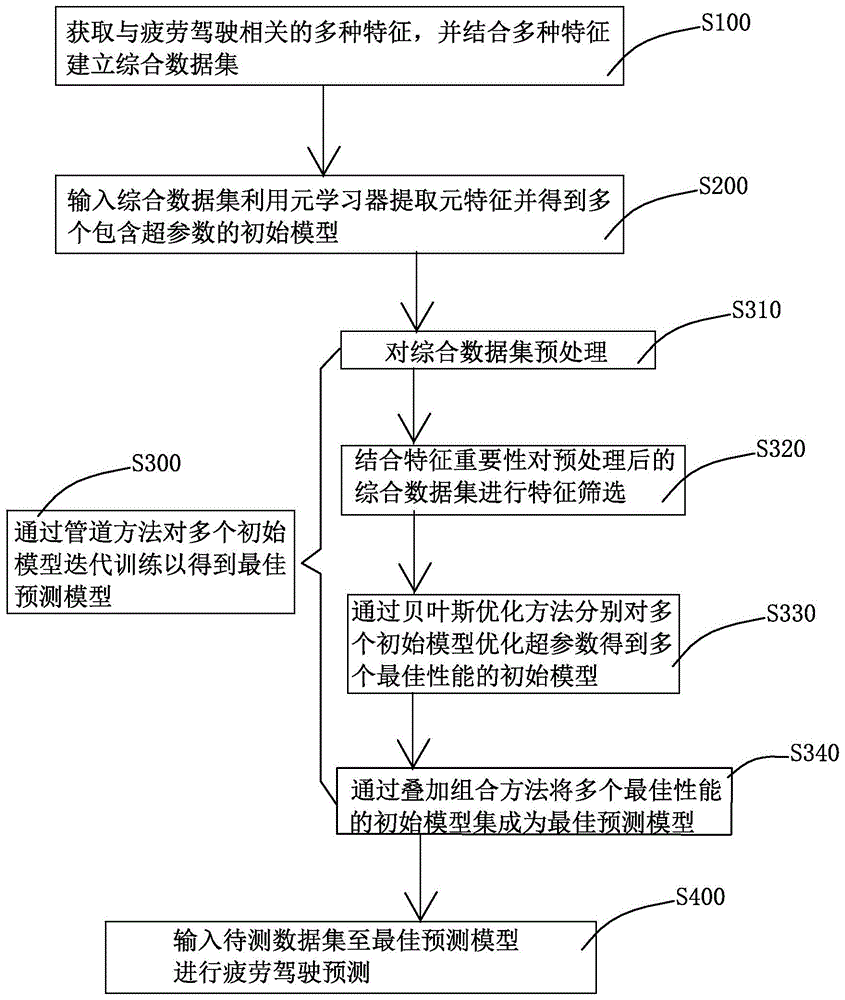
获取与疲劳驾驶相关的多种特征,并结合多种特征建立综合数据集;
输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型;
通过管道方法对多个初始模型迭代训练以得到最佳预测模型,具体,具体包括以下步骤:
对综合数据集预处理;
结合特征重要性对预处理后的综合数据集进行特征筛选;
通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型;
通过叠加组合方法将多个最佳性能的初始模型集成为最佳预测模型;
输入待测数据集至最佳预测模型进行疲劳驾驶预测。
根据本发明的第一方面,所述输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型包括以下步骤:
提取多个综合数据集的元特征;
计算综合数据集与其他参照数据集在元特征组成的空间上的空间距离;
根据空间距离得到多个包含超参数的初始模型。
根据本发明的第一方面,所述对综合数据集预处理包括数据采样、数据清洗、数据转换、数据标度和数据转换中的一种或多种。
根据本发明的第一方面,所述结合特征重要性对预处理后的综合数据集进行特征筛选具体为:
计算综合数据集的每种特征在随机森林的平均贡献度作为特征重要性;
筛选特征重要性大于1%的特征。
根据本发明的第一方面,所述平均贡献度计算方式如下:
根据本发明的第一方面,所述通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型包括以下步骤:
判断机器学习框架是否初始化,若是则采用上一轮选出的最大采样函数值的对应点的集合作为下一步的输入,若否则随机产生初始化点集作为下一步的输入;
进行gp高斯过程回归;
通过采样函数计算最大采集函数值的对应点;
判断最大采样函数值的对应点是否满足设定目标值,若是则输出作为机器学习框架的参数,若否则返回进行gp高斯过程回归循环。
根据本发明的第一方面,所述采样函数为:
本发明的第二方面,基于自动机器学习的疲劳驾驶预测装置,用于执行如本发明第一方面所述的基于自动机器学习的疲劳驾驶预测方法,所述疲劳驾驶预测装置包括:
数据集建立模块,用于获取与疲劳驾驶相关的多种特征,并结合多种特征建立综合数据集;
元学习模块,用于输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型;
训练模块,用于通过管道方法对多个初始模型迭代训练以得到最佳预测模型,所述训练模块包括:
第一筛选模块,用于对综合数据集进行预处理;
第二筛选模块,用于结合特征重要性对预处理后的综合数据集进行特征筛选;
调参模块,用于通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型;
集成模块,用于通过叠加组合方法将多个最佳性能的初始模型集成为最佳预测模型;
测试模块,用于输入待测数据集至最佳预测模型进行疲劳驾驶预测。
本发明的第三方面,存储介质,存储有可执行指令,可执行指令能被计算机执行,使计算机运行如本发明的第一方面所述的基于自动机器学习的疲劳驾驶预测方法。
上述技术方案至少具有以下的有益效果:通过元学习器从模型库中筛选得到多个包含超参数的初始模型,再经过不断的重复训练调整得到针对疲劳驾驶数据的多个初始模型的最佳状态,最后将多个最佳性能的初始模型集成为最佳预测模型,使该最佳预测模型能实现对疲劳驾驶数据分类预测出最优结果。使用管道方法端到端进行数据预处理、特征工程、模型选择和模型评估等机器学习流程来解决特定任务,使得预测模型无需人工干预即可被应用。在疲劳驾驶预测中整合了自动机器学习,在保证了高精度的同时可以最小化时间及人力成本。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
下面结合附图和实例对本发明作进一步说明。
图1是本发明实施例基于自动机器学习的疲劳驾驶预测方法的流程图;
图2是步骤s330的具体流程图;
图3是本发明实施例基于自动机器学习的疲劳驾驶预测装置的结构图。
具体实施方式
本部分将详细描述本发明的具体实施例,本发明之较佳实施例在附图中示出,附图的作用在于用图形补充说明书文字部分的描述,使人能够直观地、形象地理解本发明的每个技术特征和整体技术方案,但其不能理解为对本发明保护范围的限制。
在本发明的描述中,若干的含义是一个或者多个,多个的含义是两个以上,大于、小于、超过等理解为不包括本数,以上、以下、以内等理解为包括本数。如果有描述到第一、第二只是用于区分技术特征为目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量或者隐含指明所指示的技术特征的先后关系。
本发明的描述中,除非另有明确的限定,设置、安装、连接等词语应做广义理解,所属技术领域技术人员可以结合技术方案的具体内容合理确定上述词语在本发明中的具体含义。
参照图1,本发明的一个实施例,提供了基于自动机器学习的疲劳驾驶预测方法,包括以下步骤:
步骤s100、获取与疲劳驾驶相关的多种特征,并结合多种特征建立综合数据集;
步骤s200、输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型;
步骤s300、通过管道方法对多个拟合的机器学习框架迭代训练以得到最佳预测模型,具体包括以下步骤:
步骤s310、对综合数据集预处理;
步骤s320、结合特征重要性对预处理后的综合数据集进行特征筛选;
步骤s330、通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型;
步骤s340、通过叠加组合方法将多个最佳性能的初始模型集成为最佳预测模型;
步骤s400、输入待测数据集至最佳预测模型进行疲劳驾驶预测。
在该实施例中,通过元学习器从框架库中筛选得到多个包含超参数的初始模型,再经过不断的重复训练调整得到针对疲劳驾驶数据的多个初始模型的最佳状态,即为多个最佳性能的初始模型,最后将多个最佳性能的初始模型集成为最佳预测模型,使该最佳预测模型能实现对疲劳驾驶数据分类预测出最优结果。使用管道方法端到端进行数据预处理、特征工程、模型选择和模型评估等机器学习流程来解决特定任务,使得预测模型无需人工干预即可被应用。在疲劳驾驶预测中整合了自动机器学习,在保证了高精度的同时可以最小化时间及人力成本。
进一步,在步骤s100中,可以从样本数据库中获取与疲劳驾驶相关的多种数据样本,也可以通过摄像头和传感器实时从模拟驾驶中获取与疲劳驾驶相关的多种数据样本,多种数据样本包括驾驶员的生理数据、环境参数以及车辆行为信息。然后提取每种数据样本的特征信息,并分别对每种数据样本中各自的特征信息进行综合,以此建立起多种综合数据集。当通过摄像头和传感器实时从模拟驾驶中获取与疲劳驾驶相关的多种数据样本时,实验对象为不同性别不同年龄和种族背景的共100名驾驶员,数据来自公路行驶或模拟驾驶情况下的实验结果,驾驶员在以两分钟为周期的行驶过程中,每隔100ms记录一次数据,每名驾驶员记录1200次测量样本。
进一步,在步骤s200中,所述输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型包括以下步骤:
提取综合数据集的元特征;实际上共提取38个元特征,包括信息理论特征、简单特征和统计学特征,例如关于偏差和方差特征以及数据点的数量、特征和类的统计特征等;
计算综合数据集与其他参照数据集在元特征组成的空间上的空间距离;参照数据集是采用openml中的140个开放数据集;
根据空间距离得到多个包含超参数的初始模型;具体地,取其中空间距离最接近的25个参照数据集所对应的初始模型为拟合的初始模型。
需要说明的是,元学习器是一种解决学习“如何学习”问题的算法模型。
进一步,在步骤s310中、所述对综合数据集预处理包括数据采样、数据清洗、数据转换、数据标度和数据转换中的一种或多种。例如,数据清洗包括:去除零值特征、删除要忽略的列以及数据类型、删除重复的数据以及缺少特征或特征类型未知的数据。数据转换包括:采用独热编码将数据进行编码,使之转化成数值型;将数据集中缺省的值用平均值、中值或众数代替;对数据重新标度使之标准化,或者将它们归一化到0到1的范围内。当然,可以根据具体的数据选择最佳的策略对多种数据集筛选。
进一步,在步骤s320中、所述结合特征重要性对预处理后的综合数据集进行特征筛选具体为:
计算综合数据集的每种特征在随机森林的平均贡献度作为特征重要性;具体地,所述平均贡献度计算方式如下:
筛选特征重要性大于1%的特征。
进一步,参照图2,在步骤s330中、所述通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型包括以下步骤:
步骤s331、判断机器学习框架是否初始化,若是则采用上一轮选出的最大采样函数值的对应点的集合作为下一步的输入,若否则随机产生初始化点集作为下一步的输入;
步骤s332、进行gp高斯过程回归;
步骤s333、通过采样函数计算最大采集函数值的对应点;
步骤s334、判断最大采样函数值的对应点是否满足设定目标值,若是则输出作为机器学习框架的参数,若否则返回进行gp高斯过程回归循环。
贝叶斯优化方法通过比较最大采样函数值的对应点与设定目标值大小关系,以对超参数进行两种分布。下一个采样点的选择要在高均值和高方差这两者之间权衡以最大化期望效用。贝叶斯优化可以减少函数的评估次数,提高超参数优化效率;此外还可以找到初始模型的全局最优值点,使之在测试集上获得更好的表现。
具体地,所述采样函数为:
进一步,在步骤s340中、通过叠加组合方法将多个最佳性能的初始模型集成为最佳预测模型。通过叠加组合方法进行集成可以避免丢弃掉表现优秀的最佳性能的初始模型,将所有最佳性能的初始模型存储并构建成集成体。叠加组合方法是一个从空集开始的累积过程,叠加组合向集成体中添加最佳性能的初始模型,进而使得集成体的性能表现更优且组合更灵活。这能避免超参数的单一化以及数据的过拟合化,且鲁棒性更强。
需要说明的是,管道方法是一个复合评估器,用于多个流程和环节的反复性操作,实现了对重复的操作步骤的封装和管理。目的是将多个具有上下逻辑环节的过程连接起来形成一个复合对象,然后针对该对象训练不同参数下对应交叉检验的结果,简化了模型构建的流程。
在步骤s400中,输入待测数据集至由管道方法构建对的最佳预测模型中进行疲劳驾驶预测,对待测数据集分类,输出疲劳驾驶预测结果。
参照图3,本发明的另一个实施例,提供了基于自动机器学习的疲劳驾驶预测装置,用于执行如上所述的基于自动机器学习的疲劳驾驶预测方法,所述疲劳驾驶预测装置包括:
数据集建立模块10,用于获取与疲劳驾驶相关的多种特征,并结合多种特征建立综合数据集;
元学习模块20,用于输入综合数据集利用元学习器提取元特征并得到多个包含超参数的初始模型;
训练模块30,用于通过管道方法对多个拟合的机器学习框架迭代训练以得到最佳预测模型,
所述训练模块30包括:
第一筛选模块31,用于对综合数据集进行预处理;
第二筛选模块32,用于结合特征重要性对预处理后的综合数据集进行特征筛选;
调参模块33,用于通过贝叶斯优化方法分别对多个初始模型优化超参数得到多个最佳性能的初始模型;
集成模块34,用于通过叠加组合方法将多个最佳性能的初始模型集成为最佳预测模型;
测试模块40,用于输入待测数据集至最佳预测模型进行疲劳驾驶预测。
在该基于自动机器学习的疲劳驾驶预测装置中,各个模块与上述的基于自动机器学习的疲劳驾驶预测装置方法的步骤对应,并使该基于自动机器学习的疲劳驾驶预测装置具有与疲劳驾驶预测方法相同的有益效果,在此不再具体展开阐述。
本发明的另一个实施例,提供了存储介质,存储有可执行指令,可执行指令能被计算机执行,使计算机运行如上所述的基于自动机器学习的疲劳驾驶预测方法。
存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。
以上所述,只是本发明的较佳实施例而已,本发明并不局限于上述实施方式,只要其以相同的手段达到本发明的技术效果,都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!