一种居家办公环境下的用电负荷状态识别方法与流程
本发明属于非侵入式负荷识别技术领域,具体涉及一种居家办公环境下的用电负荷状态识别方法。
背景技术:
随着社会经济的发展,电力成为当今社会中应用最为广泛的能源之一。为了给用户提供更加可靠、绿色的电能以及减缓全球变暖及气候改变所带来的影响,智能用电,变得愈发重要。为了更好的利用电能,首先需要对用电负荷进行负荷监测,负荷监测是为了获取用户用电数据,掌握详细的用户负荷运行状态和使用频率,其采样及用电行为的挖掘是建设灵活互动智能用电的关键环节。
电力负荷监测方法大致可以分为侵入式和非侵入式两类,侵入式负荷监测,往往需要在每个电器负荷上安装相应的数据采集和传感装置,带来大量的人力物力资源消耗。非侵入式负荷监测只需要在电力供给的入口处安装非侵入式的监测设备,通过监测该处的电压、电流等信号就可以分析得到负荷集群中单个负荷的种类和运行情况,以此实现对整个系统范围内的所有用电负荷的在线监测。相较于传统的侵入式负荷监测方法,非侵入式负荷监测(non-instrusiveloadmonitoring,nlim)不中断设备供电,易于被用户所接受,不需要安装大量的检测设备,节省了购买、安装和维护这些硬件设备所需要的投资和时间,是未来电力负荷监测的重要发展方向。
非侵入式负荷监测技术一般可以分为数据测量、事件检测、负荷识别。对于电网来说,负荷监测能够帮助电网企业细致地掌握负荷组成和用户用电行为,为电网的规划、发电调度提供指导,为双向互动与智能用电提供服务。对于用户而言负荷监测能给出各用电设备的具体用电信息,从而引导用户改变用电习惯、优化用电行为,节约用电成本。负荷监测和智能用电的结合在智能电网中得到了完美体现,非侵入式负荷监测技术具有广泛的应用前景,能为用户、电力公司等多方面带来效益。
传统的负荷监测技术多利用负荷的稳态特征来进行识别,比如负荷工作时的稳态电流、稳态电压等信息,然后基于最优化问题解决方法来找出当前总负荷下各个用电负荷的最佳组合,这类负荷状态识别方法往往需要建立复杂模型,且对负荷的历史数据依赖很大,且随着负荷种类的增多,用电负荷整体的识别准确率不高。还有一部分负荷识别算法是基于负荷暂态特征进行的,但是由于负荷特征提取的单一性,未能够细分深挖用电负荷的最典型特征,故这部分算法对相似用电设备和小功率电器的识别效果较差。
技术实现要素:
本发明针对目前方法存在稳态特征建模复杂,负荷识别度不高;暂态特征对相似设备和小功率负荷识别精度低等问题,提出基于psosc-mdtw(particleswarmoptimization-systemclustering-multidimensionaldtw)的负荷状态识别算法,用于对居家办公环境下的用电负荷进行状态识别。
本发明具体是:
步骤1.构建负荷特征模板库
1-1、获取居家或办公环境中用电负荷投切时的有功功率时间序列和无功功率时间序列,将上述的两种功率时间序列记为用电负荷的瞬态功率波形tpw。
获取和投切事件相对应的事件标签,将所有电负荷的瞬态功率波形tpw组成一个完整的数据集dataset。将每一种用电负荷的瞬态功率波形tpw随机取出50%的数据作为训练集,记为tr,用于负荷特征模板库选择。将数据集dataset中另外50%的数据作为测试集,记为te,用于用电负荷状态识别方法的性能测试。
1-2、计算训练集中元素ωi的最大聚类类数mimax,其中ωi表示第i种用电负荷的瞬态功率波形tpw的集合。
1-3、初始情况下,集合ωi中每个样本都为一个单独的类,此时的类间距离和样本间距离相同。计算集合ωi中各个类之间的dtw距离,并得到类间距离矩阵d(ωi)。
1-4、对集合ωi中距离最近的两类样本进行合并,其余类样本保持不变。用c(j,k)表示集合ωi中第j类样本c(j)和第k类样本c(k)合并之后的集合。
其中d(j,k)表示集合ωi中的第j和第k类样本之间的dtw距离。
1-5、比较tc-1和预置聚类类数mi之间的关系,若tc-1=mi,则跳到1-6,输出样本当前的分类情况;若tc-1>mi,则返回到1-3,重新计算类间距离矩阵。
1-6、系统聚类后将数据细分为mi个样本类,集合表示为c1,c2,…,cr,…,
其中nr表示第r个集合中样本的个数。
1-7、将集合ωi中选取出来的样本集合表示为kui
其中
1-8、对训练集tr={ω1,ω1,…,ωn}中所有的集合都经过聚类筛选可得到完整的负荷特征模板库ku
ku={ku1,ku2,…,kui}
步骤2.识别用电负荷状态
2-1、从测试集te中选取待测tpw,记为te,负荷特征模板库ku中的典型模板波形记为tz。
2-2、采用如下电负荷状态识别规则:将te与tz做dtw计算,找出与待测tpw间dtw距离最小的典型模板波形,并将其状态标签给与待测tpw,从而得到用电负荷的负荷状态。
de,z(te,tz)表示计算te和tz间的dtw距离,argmin()表示求取使de,z(te,tz)最小时的变量值,
步骤3.对负荷状态识别方法进行参数优化
3-1:设定负荷状态识别方法的评价指标
用电负荷状态识别的评价指标包括精度、灵敏度以及f度量。精度是指c类样本的概率;灵敏度是指c类样本被正确识别的概率。f度量是精度与灵敏度结合的综合指标。
3-2:参数优化
1)获取综合评价指标f度量
根据完整的负荷特征模板库ku和测试数据集te,进行最近邻模板匹配,可得到f度量
f=lab(dtw(g(m1,m2,…,mn,tr),te))
其中n表示用电负荷种类数,m1,m2,…,mn分别表示每一种用电负荷的聚类类数,g(,)表示步骤1构建的负荷特征模板库,dtw(,)表示步骤2-2中的用电负荷状态识别规则,lab(,)表示f度量的映射关系。
2)优化过程
将m1,m2,…,mn作为可变参数,综合评价指标f度量作为优化目标,对负荷识别方法进行pso优化。优化目标函数下所示:
maxf(h)=lab(dtw(g(h,tr),te))
其中z+表示正整数。
本发明的有益效果:
本发明选用居家、办公环境下负荷投切时的瞬态功率波形为特征,用做负荷辨识;针对小功率和相似负荷识别存在的难点,本发明提出对同类负荷tpw进行系统聚类,选取典型tpw模板,创建负荷模板特征库,提高负荷的识别率。由于负模板更加精细,本发明筛选得到的模板库,更具典型性,在负荷状态匹配识别时精确度更高。
针对负荷种类增多存在的困难,本发明提出利用pso进行参数优化,确定负荷典型tpw簇数的最优组合,使得负荷状态识别算法的综合性能最佳。本发明在负荷种类较多时仍然能够保证负荷状态识别的整体性能最佳。
附图说明
图1为本发明方法流程图。
具体实施方式
以下结合附图对本发明作进一步说明。
本发明为了更加准确快速的识别出用电负荷的工作状态,首先要获取居家、办公环境下用电负荷(例如冰箱、空调、饮水机等)投切时的瞬态功率波形tpw(transientpowerwaveform),及负荷投切时的准确标签,以便用于负荷辨识,及算法性能评估。然后,针对小功率和相似负荷识别存在的难点,本发明提出对同类负荷tpw进行系统聚类,选取典型tpw模板,提高负荷的识别率。最后为了解决负荷种类增多存在的困难,本发明提出利用pso算法进行参数优化,确定负荷典型tpw簇数的最优组合,使得负荷状态识别算法的综合性能最佳。本发明所提方法为居家办公环境下的负荷状态识别及智能用电做了重要贡献。
本发明方法的步骤包括:
1.基于mdtw-sc方法构建负荷特征模板库
本发明针对一般负荷识别算法存在基于稳态特征建模复杂,负荷识别度不高;基于暂态特征对相似设备和小功率负荷识别精度低等问题,首先设计了一种基于mdtw-sc(multidimensionaldtw-systemclustering)的负荷特征模板库筛选方法。
其基本思想为:在居家及办公环境中,存在多种用电负荷(比如冰箱,空调、饮水机等),对于特定用电负荷,其典型负荷状态存在多个,以空调为例存在启动、关闭、制冷、制热等多个典型负荷状态。因此,选择用电负荷的模板库时需要准确的将负荷的典型工作波形都选入模板库,这样在匹配状态识别时才能更加快速、准确。
其具体步骤如下:
step1、获取居家或办公环境中用电负荷投切时的有功功率时间序列p=[p1,p2,…,pe]t和无功功率时间序列q=[q1,q2,…,qe]t,e表示上述两个功率时间序列的长度,上述的两种功率时间序列记为用电负荷的瞬态功率波形tpw。
获取和投切事件相对应的事件标签,将所有电负荷的瞬态功率波形tpw组成一个完整的数据集dataset。将每一种用电负荷的tpw随机取出50%作为训练集,记为tr,用于负荷特征模板库选择。
设训练集tr={ω1,ω1,…,ωn},其中n表示训练集tr中用电负荷的种类,ωi,i={1,2,…,n}表示第i种用电负荷tpw的集合。集合ωi的具体表示形式为:
将数据集dataset中另外50%的数据作为测试集,称之为te,用于用电负荷工作状态识别算法的性能测试。
step2、对集合ωi的最大聚类类数mimax进行计算。mimax表示第i种用电负荷经过聚类后最多能聚成的类,即第i种用电负荷聚类类数的最大值。本发明欲将集合ωi聚为mi个类,mi称为预置聚类类数,易知mi≤mimax。
step3、初始情况下,集合ωi中每个样本都为一个单独的类,此时的类间距离和样本间距离相同。计算集合ωi中各个类之间的dtw距离(类间距离用最短距离法),并得到类间距离矩阵d(ωi),其具体表现形式如公式(2)所示。
其中d(j,k),j,k={1,2,…,tc}表示的是集合ωi中的第j和第k类样本之间的dtw距离。mi≤tc≤ni,tc∈z+表示集合ωi中当前聚类类数。
step4、对集合ωi中距离最近的两类样本进行合并,其余类样本保持不变。其中c(j,k)表示集合ωi中第j类样本c(j)和第k类样本c(k)合并之后的集合。
step5、比较tc-1和预置聚类类数mi之间的关系,若tc-1=mi,则跳到step6,输出样本当前的分类情况;若tc-1>mi,则返回到step3,重新计算类间距离矩阵。
step6、系统聚类后将数据细分为mi个样本类,集合表示为c1,c2,…,cr,…,
step7、集合ωi中选取出来的样本集合表示为kui,其表示形式如公式(5)所示。其中
step8、对训练集tr={ω1,ω1,…,ωn}中所有的集合都经过聚类筛选可得到完整的负荷特征模板库ku,其形式如公式(6)所示。
ku={ku1,ku2,…,kui}(6)
2.识别用电负荷状态
其基本思想为:首先获得和训练集结构一样的测试集样本,其来源于测试集te,然后再基于最近邻匹配原则,将算法识别出的标签给与待测负荷。
step1、测试集te和训练集tr共同构成了数据集dataset,故首先从te中选取待测试瞬态功率波形,称之为te,其具体的表现形式为te=[p,q]^,模板库ku中的模板波形称之为tz。
step2、按照公式(7)所示用电负荷状态识别规则,将te与负荷特征模板库ku中的典型模板波形分别做dtw计算,找出与待测tpw间dtw距离最小的典型模板波形,并将其状态标签给与待测tpw,从而得到用电负荷的负荷状态。
公式(7)中de,z(te,tz)表示计算te和tz间的dtw距离,argmin()表示求取使de,z(te,tz)最小时的变量值,
3.基于psosc-mdtw的负荷状态识别方法进行参数优化。
由于负荷种类多,故为了提高算法对所有负荷的总体识别效果,本发明提出了基于pso优化以及系统聚类的多维dtw(psosystemclustering-multidimensionaldtw,psosc-mdtw)负荷状态识别算法,设定负荷状态识别方法的综合评价指标,利用pso算法进行参数优化,确定负荷投切状态典型工作波形簇数之间的最优组合,使得负荷状态识别的综合评价指标最佳。
步骤1:设定负荷状态识别方法的评价指标
用电负荷状态识别的评价指标通常有精度和灵敏度以及f度量。精度是指c类样本的概率,记为pc;灵敏度是指c类样本被正确识别的概率,记为sc。f度量是精度与灵敏度结合的综合指标,c类的f度量记为fc。定义综合评价指标f度量,记为f。具体指标的定义如下所示。
1)精度
其中,c表示测试集te中用电负荷的总类,tpc表示正确识别为c类样本的数量,fpc表示错误识别为c类样本的数量。
2)灵敏度
其中,fnc表示被错误的识别为其他类样本的c类样本。
3)f度量
其中,n为用电负荷的种类数,ni第i类用电负荷的事件总数。指标f是所有用电负荷识别精度以及灵敏度的综合反映。
步骤2:基于psosc-mdtw对负荷状态识别方法进行参数优化。
1)获取综合评价指标f度量
根据完整的负荷特征模板库ku和测试数据集te,进行最近邻模板匹配,可得到综合f度量指标如公式(12)所示。
f=lab(dtw(g(m1,m2,…,mn,tr),te))(12)
式中,n表示用电负荷种类数,m1,m2,…,mn分别表示每一种用电负荷的聚类数,tr,te分别表示训练集和测试集,g(,)表示基于mdtw-sc方法构建负荷特征模板库,dtw(,)表示式(7)中所示的用电负荷状态识别规则,lab(,)表示基于公式(11)计算用电负荷f度量。
2)负荷状态识别算法的优化。
将每种负荷投切时的典型工作波形簇数m1,m2,…,mn作为可变参数,综合评价指标f度量作为优化目标,对负荷识别算法进行pso优化。优化目标函数如公式(13)所示。
maxf(h)=lab(dtw(g(h,tr),te))
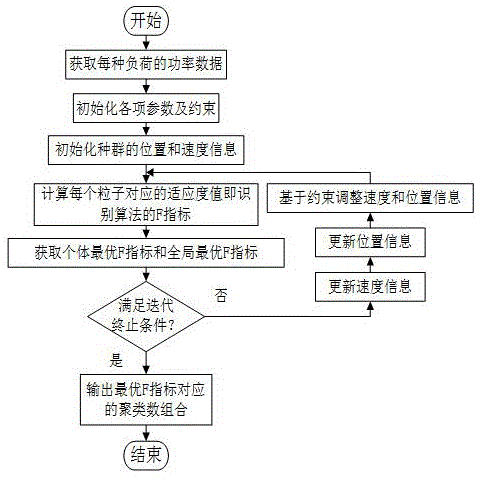
其优化过程如下图1所示,负荷识别算法的具体步骤如下。
step1、获取原始功率数据,构建训练集tr和测试集te,以及训练集中事件标签清晰的各种用电设备的瞬态功率数据的集合{ω1,ω1,…,ωn}。
step2、初始化各项参数,包括粒子群的种群规模m,设置约束条件vmax,vmin,xmax,xmin;最大迭代次数mgen,搜索空间的维度n,边界budy和相应的迭代结束条件。
step3、初始化每个粒子的速度信息和位置信息vi0=[vi1vi2…vin]t,
step4、初始化的位置,其中每个位置信息实际上是负荷聚类类数组合,后根据公式(13)计算f度量,即适应度值。
step5、根据设定好的目标函数,计算粒子群种所有粒子的适应度值,然后评估粒子的历史最优解pbest和全局最优解gbest。
step6、判断全局最优解对应的适应度值是否达到算法设定的要求;或迭代次数是否已经达到最大。满足上述任何一个要求,算法结束迭代,输出最优解;否则,跳到step7。
step7、根据公式(14)对粒子速度信息进行跟新。公式中第一部分称为记忆项,表示上次速度大小和方向的影响;第二部分称为自身认知项,表示粒子的动作来源于自己经验的部分;第三部分称为群体认知项,反映了粒子间的协同合作和知识共享,粒子通过自己的经验和同伴中最好的经验来决定下一步的运动。
其中,vik表示第k次迭代后粒子i的速度;
step8、根据公式(15)跟新粒子位置信息
其中
step9、根据公式(16)所示约束对粒子的速度和位置进行调整。
粒子的速度和位置经过调整后跳至step5,然后重复执行step6至step9直至算法迭代结束,输出全局最优解及其最优解对应的适应度值。
基于psosc-mdtw对负荷状态识别方法进行参数优化,优化后的最优参数是用电负荷聚类类数的最佳组合,此时筛选出的负荷特征模板库ku,能使得负荷识别的综合指标f达到很高,优于现有的大部分方法。
- 还没有人留言评论。精彩留言会获得点赞!