一种图像语义分割方法与流程
本发明涉及图像处理领域,具体涉及一种图像语义分割方法。
背景技术:
像素级语义分割图是把图片上属于不同类别的像素用不同的标签标记出来,在自动驾驶中具有眼睛的作用。车辆拍到前方图片,通过分割模型得到分割图,就获得了道路包含的类别和位置信息,这些信息反馈给自动驾驶系统判断该前进还是停车还是转弯,或是其他操作。
合成数据集图像分割技术面临的最主要困难是在完全不使用来自目标域的人工标签时,由合成数据集训练出的分割模型在应用中会出现域移位的现象。因此,现有的合成数据集图像分割技术的主要突破点也在进行域对齐上。
现有的应用于图像语义分割的域对齐方法主要有两大类,第一类是通过尽可能地减小源域与目标域的分布差异来学习域不变表示的方法。该类方法的代表技术是最大平均差(mmd)损失、均值、协方差等。其核心思想是用这些统计信息作为两个域之间的公共距离度量。然而,当域的分布不是高斯分布时,想靠均值、协方差等统计信息来对齐两个差异较大的域是非常困难的。
第二类方法是基于对抗学习的域对齐方法。它通过强制将不同领域的特征统一化来欺骗鉴别器,从而减少了两个域的差异性,这一过程也通常被称为翻译过程。该类方法最主要的缺点是分割模型的性能非常依赖于图像到图像翻译模型的性能。一旦图像到图像的转换失败或出现一定量的误差,在图像分割模型上就无法对其进行修正。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种图像语义分割方法解决了现有技术中图像翻译模型性能对分割结果影响过大且无法被修正的问题,并给出了一个具有更强域不变特征区分力的图像语义分割方法。
为了达到上述发明目的,本发明采用的技术方案为:
提供一种图像语义分割方法,其包括以下步骤:
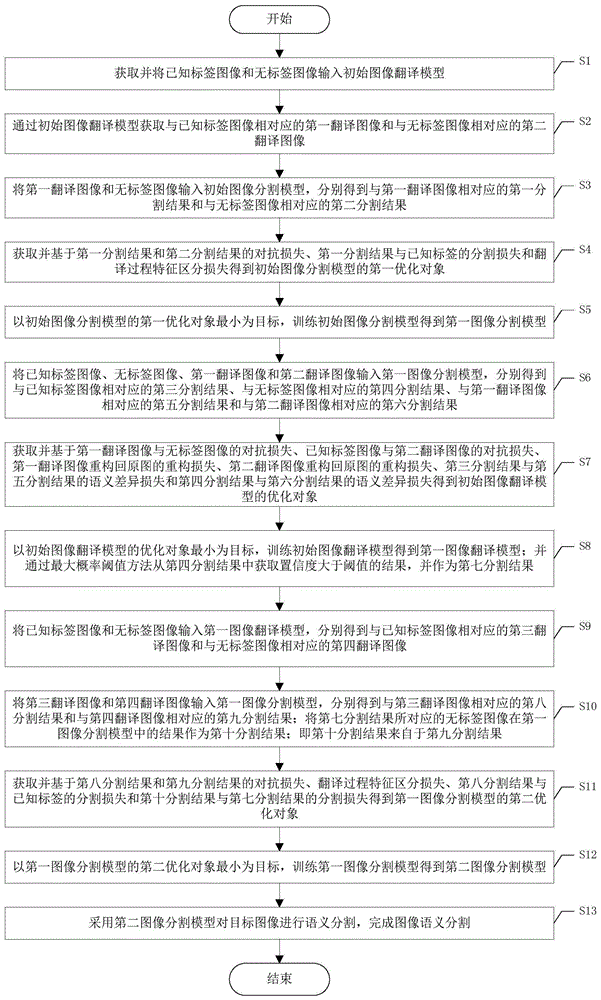
s1、获取并将已知标签图像和无标签图像输入初始图像翻译模型;
s2、通过初始图像翻译模型获取与已知标签图像相对应的第一翻译图像和与无标签图像相对应的第二翻译图像;
s3、将第一翻译图像和无标签图像输入初始图像分割模型,分别得到与第一翻译图像相对应的第一分割结果和与无标签图像相对应的第二分割结果;
s4、获取并基于第一分割结果和第二分割结果的对抗损失、第一分割结果与已知标签的分割损失和翻译过程特征区分损失得到初始图像分割模型的第一优化对象;
s5、以初始图像分割模型的第一优化对象最小为目标,训练初始图像分割模型得到第一图像分割模型;
s6、将已知标签图像、无标签图像、第一翻译图像和第二翻译图像输入第一图像分割模型,分别得到与已知标签图像相对应的第三分割结果、与无标签图像相对应的第四分割结果、与第一翻译图像相对应的第五分割结果和与第二翻译图像相对应的第六分割结果;
s7、获取并基于第一翻译图像与无标签图像的对抗损失、已知标签图像与第二翻译图像的对抗损失、第一翻译图像重构回原图的重构损失、第二翻译图像重构回原图的重构损失、第三分割结果与第五分割结果的语义差异损失和第四分割结果与第六分割结果的语义差异损失得到初始图像翻译模型的优化对象;
s8、以初始图像翻译模型的优化对象最小为目标,训练初始图像翻译模型得到第一图像翻译模型;并通过最大概率阈值方法从第四分割结果中获取置信度大于阈值的结果,并作为第七分割结果;
s9、将已知标签图像和无标签图像输入第一图像翻译模型,分别得到与已知标签图像相对应的第三翻译图像和与无标签图像相对应的第四翻译图像;
s10、将第三翻译图像和第四翻译图像输入第一图像分割模型,分别得到与第三翻译图像相对应的第八分割结果和与第四翻译图像相对应的第九分割结果;将第七分割结果所对应的无标签图像在第一图像分割模型中的结果作为第十分割结果;即第十分割结果来自于第九分割结果;
s11、获取并基于第八分割结果和第九分割结果的对抗损失、翻译过程特征区分损失、第八分割结果与已知标签的分割损失和第十分割结果与第七分割结果的分割损失得到第一图像分割模型的第二优化对象;
s12、以第一图像分割模型的第二优化对象最小为目标,训练第一图像分割模型得到第二图像分割模型;
s13、采用第二图像分割模型对目标图像进行语义分割,完成图像语义分割。
进一步地,步骤s1中的已知标签图像包括gta5合成数据集中的24966张图片;无标签图像包括cityscapes数据集中的2975张训练图像和500张验证图像。
进一步地,图像翻译模型的翻译方法为风格迁移方法。
进一步地,步骤s4中初始图像分割模型的第一优化对象的表达式为:
其中
进一步地,初始翻译模型的翻译过程特征区分损失
将已知标签图像s和第二翻译图像t1分别输入初始图像分割模型,分别得到与已知标签图像s相对应的第十一分割结果m(s)和与第二翻译图像t1相对应的第十二分割结果m(t1);
根据公式:
获取初始翻译模型的翻译过程特征区分损失
进一步地,步骤s7中初始图像翻译模型的优化对象的表达式为:
其中lf为初始图像翻译模型的优化对象;λgan和λrecon均为常数;s为已知标签图像;t为无标签图像;s1为第一翻译图像;t1为第二翻译图像;f-1(·)表示初始图像翻译模型的逆操作;lgan(s1,t)为第一翻译图像与无标签图像的对抗损失;lgan(s,t1)为已知标签图像与第二翻译图像的对抗损失;lrecon(s,f-1(s1))为第一翻译图像重构回原图的重构损失;lrecon(t,f(t1))为第二翻译图像重构回原图的重构损失;lper(m1(s),m1(s1))为第三分割结果与第五分割结果的语义差异损失,m1(·)表示第一图像分割模型;lper(m1(t),m1(t1))为第四分割结果与第六分割结果的语义差异损失。
进一步地,步骤s11中第一图像分割模型的第二优化对象的表达式为:
其中
进一步地,第一图像翻译模型的翻译过程特征区分损失
将已知标签图像s和无标签图像分别输入初始图像分割模型,分别得到与已知标签图像s相对应的第十三分割结果m1(s)和与无标签图像相对应的第十四分割结果m1(t);
根据公式:
获取第一图像翻译模型的翻译过程特征区分损失
本发明的有益效果为:本发明通过第一图像分割模型逆向改进图像翻译模型的方式解决合成数据集图像语义分割对图像翻译模型性能的过度依赖的问题,通过优化后的图像翻译模型(第一图像翻译模型)的输出数据和第一图像分割模型的输出数据,使得第一图像分割模型可以通过监督学习再次进行优化,进行得到一个具有更强域不变特征区分力的图像语义分割模型(第二图像分割模型),采用图像语义分割模型(第二图像分割模型)对目标图像进行语义分割,即可完成图像语义分割。本方法解决了现有技术中图像翻译模型性能对分割结果影响过大且无法被修正的问题。
附图说明
图1为本发明的流程示意图;
图2为图像分割模型网络结构示意图;
图3为图像分割模型的监督学习流程示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,该图像语义分割方法包括以下步骤:
s1、获取并将已知标签图像和无标签图像输入初始图像翻译模型;
s2、通过初始图像翻译模型获取与已知标签图像相对应的第一翻译图像和与无标签图像相对应的第二翻译图像;
s3、将第一翻译图像和无标签图像输入初始图像分割模型,分别得到与第一翻译图像相对应的第一分割结果和与无标签图像相对应的第二分割结果;
s4、获取并基于第一分割结果和第二分割结果的对抗损失、第一分割结果与已知标签的分割损失和翻译过程特征区分损失得到初始图像分割模型的第一优化对象;
s5、以初始图像分割模型的第一优化对象最小为目标,训练初始图像分割模型得到第一图像分割模型;
s6、将已知标签图像、无标签图像、第一翻译图像和第二翻译图像输入第一图像分割模型,分别得到与已知标签图像相对应的第三分割结果、与无标签图像相对应的第四分割结果、与第一翻译图像相对应的第五分割结果和与第二翻译图像相对应的第六分割结果;
s7、获取并基于第一翻译图像与无标签图像的对抗损失、已知标签图像与第二翻译图像的对抗损失、第一翻译图像重构回原图的重构损失、第二翻译图像重构回原图的重构损失、第三分割结果与第五分割结果的语义差异损失和第四分割结果与第六分割结果的语义差异损失得到初始图像翻译模型的优化对象;
s8、以初始图像翻译模型的优化对象最小为目标,训练初始图像翻译模型得到第一图像翻译模型;并通过最大概率阈值方法从第四分割结果中获取置信度大于阈值的结果,并作为第七分割结果;
s9、将已知标签图像和无标签图像输入第一图像翻译模型,分别得到与已知标签图像相对应的第三翻译图像和与无标签图像相对应的第四翻译图像;
s10、将第三翻译图像和第四翻译图像输入第一图像分割模型,分别得到与第三翻译图像相对应的第八分割结果和与第四翻译图像相对应的第九分割结果;将第七分割结果所对应的无标签图像在第一图像分割模型中的结果作为第十分割结果;即第十分割结果来自于第九分割结果;
s11、获取并基于第八分割结果和第九分割结果的对抗损失、翻译过程特征区分损失、第八分割结果与已知标签的分割损失和第十分割结果与第七分割结果的分割损失得到第一图像分割模型的第二优化对象;
s12、以第一图像分割模型的第二优化对象最小为目标,训练第一图像分割模型得到第二图像分割模型;
s13、采用第二图像分割模型对目标图像进行语义分割,完成图像语义分割。
步骤s1中的已知标签图像包括gta5合成数据集中的24966张图片;无标签图像包括cityscapes数据集中的2975张训练图像和500张验证图像。
图像翻译模型的翻译方法为风格迁移方法,即将输入的图像a和图像b分别进行a到a的翻译、a到b的翻译、b到a的翻译和b到b的翻译。
步骤s4中初始图像分割模型的第一优化对象的表达式为:
其中
初始翻译模型的翻译过程特征区分损失
获取初始翻译模型的翻译过程特征区分损失
步骤s7中初始图像翻译模型的优化对象的表达式为:
其中lf为初始图像翻译模型的优化对象;λgan和λrecon均为常数;s为已知标签图像;t为无标签图像;s1为第一翻译图像;t1为第二翻译图像;f-1(·)表示初始图像翻译模型的逆操作;lgan(s1,t)为第一翻译图像与无标签图像的对抗损失;lgan(s,t1)为已知标签图像与第二翻译图像的对抗损失;lrecon(s,f-1(s1))为第一翻译图像重构回原图的重构损失;lrecon(t,f(t1))为第二翻译图像重构回原图的重构损失;lper(m1(s),m1(s1))为第三分割结果与第五分割结果的语义差异损失,m1(·)表示第一图像分割模型;lper(m1(t),m1(t1))为第四分割结果与第六分割结果的语义差异损失。
步骤s11中第一图像分割模型的第二优化对象的表达式为:
其中
第一图像翻译模型的翻译过程特征区分损失
获取第一图像翻译模型的翻译过程特征区分损失
在本发明的具体实施过程中,对抗损失可以通过一个由多个卷积层构成的鉴别器dm来获取,例如ladv(m(s1),
在本发明的一个实施例中,图像分割模型网络结构如图2所示,其中,ec是源数据集(已知标签图像)与目标数据集(无标签图像)的公用编码器,es和et分别为源数据集和目标数据集的私有编码器,cs和ct分别为源数据集和目标数据集的域不变特征,ps和pt分别为源数据集和目标数据集的纹理特征。经过多个解码器,该网络对结构与纹理特征具有强力的区分力。
在图像分割模型的整个优化过程中,如图3所示,在刚开始对初始图像分割模型进行训练时,具有伪标签ty'的目标域数据集通常为空集,但随着初始图像分割模型不断更新,取得更好地效果,具有伪标签ty'的目标域数据集包含图像的大小会逐渐扩张,当初始图像分割模型完成优化时,得到较多具有伪标签ty'的目标域数据集。通过最大概率阈值方法从较多具有伪标签ty'的目标域数据集选出tssl,并用于第一图像分割模型的训练,最终通过监督学习得到训练好的第二图像分割模型。
综上所述,本发明通过第一图像分割模型逆向改进图像翻译模型的方式解决合成数据集图像语义分割对图像翻译模型性能的过度依赖的问题,通过优化后的图像翻译模型(第一图像翻译模型)的输出数据和第一图像分割模型的输出数据,使得第一图像分割模型可以通过监督学习再次进行优化,进行得到一个具有更强域不变特征区分力的图像语义分割模型(第二图像分割模型),采用图像语义分割模型(第二图像分割模型)对目标图像进行语义分割,即可完成图像语义分割。本方法解决了现有技术中图像翻译模型性能对分割结果影响过大且无法被修正的问题。
- 还没有人留言评论。精彩留言会获得点赞!