一种基于云平台的机器视觉算法训练数据的管理系统及方法与流程
本发明涉及一种基于云平台的机器视觉算法训练数据的管理系统及方法,属于人工智能领域。
背景技术:
随着近年来人工智能的发展,基于深度学习的机器视觉算法在各个领域应用起来。伴随着这些算法,也出现了一些开源的数据集,但这些数据集只能涵盖实际应用领域的一小部分,在使用人工智能算法解决具体行业问题的时候,还是需要大量的样本数据来训练人工智能,但是采集数据的成本是很高的,这阻碍了人工智能在各个行业的推广使用。现有一些机器视觉算法训练数据处理工具,他们多数是离线的应用程序开发包,需要开发人员编写大量的与人工智能算法无关的代码,并且这些工具包并不能扩充数据的多样性。opencv是一个开源的跨平台计算机视觉库,它包含了很多基础的机器视觉算法,能满足ai算法训练数据预处理的基本需求,比如对训练图片数据进行放大,缩小,压缩,裁剪,旋转等一系列处理,但opencv是一个软件开发库。需要开发人员自己编写代码,并且是离线的。
现实中从各种设备,如手机、相机、摄像头、摄像机采集的图片与视频包含各种各样的格式,如图片格式:jpg图片,png图片,tiff图片等,视频编码格式:x265、x264、mp4等,但是在云端,现有浏览器支持的格式是有限的,例如大部分浏览器(比如使用最多的谷歌chrome或者微软的ie)都无法解析tiff格式的图片,或者x265编码的视频。
现有的阿里云的人工智能平台,与本专利相关的数据预处理部分,首先这个平台并不针对机器视觉,因此相关的功能很少。同时它并不包含图像与视频的预处理,多数是数据库里的字符数据,并且他们的数据格式转换仅仅是转换与合并数据库里的数据。
现有的华为云ai平台存在以下问题,首先仍然是不针对机器视觉,因此图片数据上传后缺少图像的预处理,然后不能上传视频,同时没有对现有不同数据集的合并功能。
现有技术存在如下问题:大多缺少对视频文件的支持,在机器视觉领域里常见的原始数据有两种:图像与视频,很多相关平台都只是支持上传图像或者图像序列。这对于一些需要连续图像序列的算法,如:目标跟踪,行为识别等,上传数据的时候不支持视频而使用图像序列代替的话,那么会将存储成本提高几倍甚至几十倍。
数据预处理方法不全:如最常用的opencv,虽然这个库在机器视觉领域十分常见,但是里面的部分算法比较陈旧,不支持一些最新的人工智能算法,如在训练数据预处理会用到的图像分类、图像超分辨率还原等。
开发成本高:开发者使用opencv进行训练数据预处理的需要自己编写代码,开发成本比较高,而且不能与在线的云服务紧密配合,从而又增加了部分云服务的额外开销。(举一个简单的例子:比如原始的图像分辨率是640x480,标注的时候需要的数据是1920x1080,如果自己开发这个放大图像的算法,就需要在后续上传中上传1920x1080的图像,这就增加了不小的网络上传流量以及开发工作量)
无法对样本进行扩展:在使用基于监督算法的人工智能来解决具体的问题的时候,我们常常无法收集到大量的样本,使用不充分样本进行人工智能算法训练的时候,会导致算法通用性不强,将样本扩展到足够的数量,可以提高算法的通用性与准确性。
对机器视觉的支持不够专业:如阿里云,华为云等提供的人工智能云平台,他们通常提供一个通用的平台。可以支持语音,文字,图像,文本等多种数据,但是他们对机器视觉算法的支持并不完善,对图像视频数据的预处理很少,并且缺少对不同格式标注的整合功能。
技术实现要素:
本发明设计开发了一种基于云平台的机器视觉算法训练数据的管理系统,能够提供基于云的图像视频管理系统,用以存储与管理图像视频数据。
本发明还设计开发了一种基于云平台的机器视觉算法训练数据的管理方法,能够基于云服务进行视频裁切与转码服务,并基于云的智能图像处理算法对训练样本进行扩展与增强。
本发明提供的技术方案为:
一种基于云平台的机器视觉算法训练数据的管理系统
文件服务器;
数据库;
云端服务器,其同时与所述文件服务器和所述数据库电连接,能够接收所述文件服务器和所述数据库传递的数据,用于提供基于云服务的图像视频转码服务;
客户端服务模块,其与所述云端服务器电连接,能够接收所述云端服务器提传递的数据,用于提供基于云服务的视频裁切,并通过基于云的智能图像处理算法,对训练样本进行扩展与增强。
优选的是,所述云端服务器包括:api接口、图像扩展模块、图像增强模块、任务队列模块、图像转码模块、视频转码模块。
优选的是,所述客户端服务模块包括:图像视频转码、视频剪切、文件上传下载、文件管理、样本增强与扩展。
一种基于云平台的机器视觉算法训练数据的管理方法,包括:
步骤一、创建数据集,用户根据兴趣在数据集文件中选择视频或图像文件进行裁切,并上传到云端;
步骤二、当用户选择视频文件时,并且从所述视频文件中裁切出感兴趣的时间段时,确定感兴趣时间段选择起点时间戳和终点时间戳,在所述感兴趣的时间段选择感兴趣区域;
步骤三、对所述感兴趣区域进行标准化配置,将所述数据集中的图像和视频的格式、分辨率进行统一;
步骤四、进行样本数据扩展配置,确定最终的任务工作流,生成任务,发送到消息队列,由云端服务器进行处理。
优选的是,所述步骤三还包括:
选择目标格式,对上传的图像和视频的文件格式进行统一;
选择目标分辨率,对上传的图像和视频的分辨率进行统一。
优选的是,所述样本数据扩展配置的扩展方式包括:基于深度学习的gan图像生成、图像基本变换中的一种。
优选的是,所述图像基本变换包括:通过图像旋转变换、镜像变换、仿射变换生成新的样本。
优选的是,所述图像和视频格式转换条用imagemagic库完成图像格式转换。
本发明所述的有益效果:
1、高效:数据预处理算法无需开发人员编写代码,同时提供云端的图像与视频转码服务。提升人工智能算法开发人员的效率。
2、提升算法准确率:通过图像增强算法与图像样本增广算法,提升后续样本标注的准确率以及最后得到的ai模型的准确率。
3、经济性:通过基于人工智能的算法扩充数据集,减少采集人工智能训练样本的成本。
附图说明
图1为本发明所述的基于云平台的机器视觉算法训练数据管理系统的整体设计图。
图2为本发明所述的视频裁切过程设计图。
图3为本发明所述的图像增强与样本增广任务过程设计图。
图4为现有技术中华为云ai平台的流程图
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
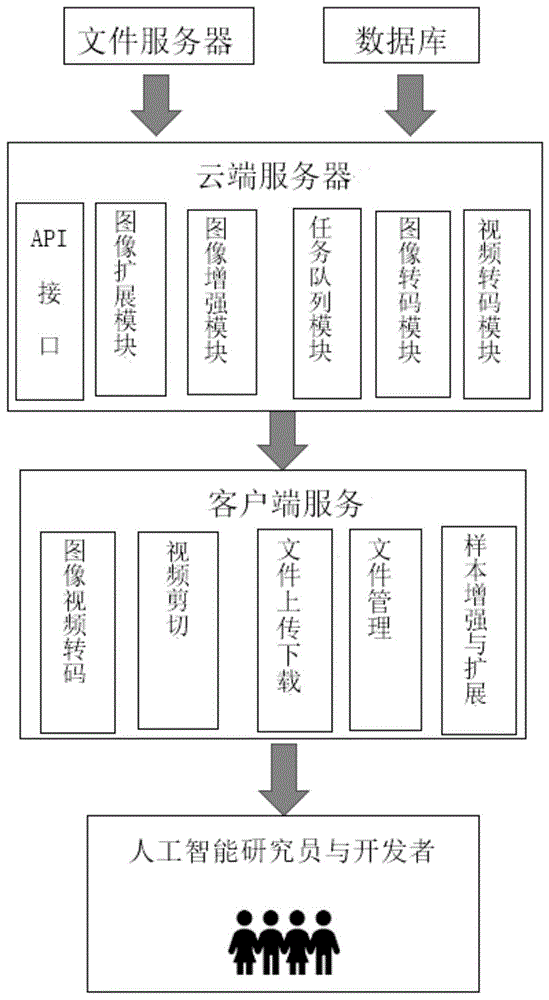
如图1-4所示,本发明提供一种基于云平台的机器视觉算法训练数据管理系统,包括:文件服务器、数据库、云端服务器、客户端服务以及人工智能研究员与开发者。
文件服务器设置在基于云平台的机器视觉算法训练数据管理系统的起始位置,用于储存较大文件,包括:样本图像以及对应的缩略图、视频文件、用户图像;数据库与文件服务器并行设置在基于云平台的机器视觉算法训练数据管理系统的起始位置,数据库用于存储除视频图想之外的其它数据,包括:用户信息、图像元数据(如图像分辨率、图像存储地址、图像占用空间等)、样本对应的标注数据、图像处理任务以及数据格式转换任务的任务信息。
文件服务器和数据库分别与云端服务器电连接,并将信息数据传递给云端服务器,云端服务器包括:api接口模块、图像扩展模块、图像增强模块、任务队列模块以及视频转码模块,用于提供基于云服务的图像视频转码服务。
api接口模块用于接收前端api接口以及与数据库通讯;图像扩展模块通过使用基于深度学习的图像风格迁移以及gan图像生成算法对已有的样本进行扩展;图像增强模块通过基于深度学习的超分辨率还原算法提高图像分辨率;任务队列模块用于对各个模块产生的异步任务进行排队;视频转码模块用于将用户上传的进行转码,在本发明中作为一种优选,将用户上传的视频转码为h264,yuv420g格式,并能够兼容常见的浏览器。
客户端服务模块与云端服务器电连接,能够接收云端服务器提传递的数据,用于提供基于云服务的视频裁切,并通过基于云的智能图像处理算法,对训练样本进行扩展与增强,包括:图像视频转码、视频剪切、文件上传下载、文件管理、样本增强与扩展。
图像视频转码是通过云服务将浏览器不支持的图片与视频格式转码为支持的格式;视频剪切以浏览器插件的形式提供,用于从用户的视频中裁剪出感兴趣的片段,并进行上传;文件上传与下载主要用于图像、视频、标注数据的上传,以及这些文件的下载功能;文件管理模块是用于用户视频、图像、标注数据的查询,编辑删除等操作,也可以创建文件夹;样本增强与扩展通过人工智能算法对已上传的样本进行扩展与增强。
本发明还提供了一种基于云平台的机器视觉算法训练数据的管理方法,包括:
创建数据集,用户根据兴趣在数据集文件中选择视频或图像文件进行裁切,并上传到云端;
当用户选择视频文件时,并且从所述视频文件中裁切出感兴趣的时间段时,确定感兴趣时间段选择起点时间戳和终点时间戳,在所述感兴趣的时间段选择感兴趣区域;
对所述感兴趣区域进行标准化配置,将所述数据集中的图像和视频的格式、分辨率进行统一;
进行样本数据扩展配置,确定最终的任务工作流,生成任务,发送到消息队列,由云端服务器进行处理。
如图2所示,视频裁切包括:
1)用户安装视频处理插件:
用户完成注册和登录后安装视频处理插件;
2)加载视频文件:
用户将视频拖拽到视频浏览器上的裁切插件内,完成视频加载;
3)选择感兴趣视频片段:
点击播放按钮,查找感兴趣的视频片段。并拖拽视频播放器进度条上的起点指针和终点指针分别到感兴趣片段的起点与终点,然后选择下一步进行配置工作;
4)选择感兴趣视频矩形区域:
在选取感兴趣视频时间段的基础上,选择视频的感兴趣矩形区域,首先点击感兴趣矩形区域左上角,拖动鼠标移动到感兴趣区域的右下角。若省略该步骤,则默认感兴趣矩形区域
5)预览视频片段
对视频片段进行浏览,如果不满意可以退回到步骤3)重新选择;
6)执行裁切:点击裁切按钮,开始进行视频裁切。进度条到100%时候裁切完成。
如图3所示,图像增强与样本增广任务:
1)上传数据:
上传所要处理的数据集;
2)配置智能图像增强任务:
选择要使用的图像增强算法,可选项包括:
1、基于深度学习的图像超分辨率还原算法。该算法可以提高图像的分辨率;并且增强图像的细节。该算法需要配置目标图像的宽和高,单位为像素;
2、基于深度学习的图像去模糊算法。该算法可以增加图像的清晰度。提高后续标注工作的准确率;
3、图像锐化算法。增强图像的边缘梯度信息。使图像中的目标物体更显著;
3)配置智能图像扩展任务:
选择一个或者多个图像变换算法。来生成新的图像,从而增加了样本的数量。可选的变换算法包括:
1、gan图像生成;
2、图像放大,缩小,旋转,镜像,仿射变换等;
4)配置目标数据集:
配置合并后的数据集的名称,描述,以及存储位置;
5)开始任务:
点击开始按钮开始以上的任务,当进度条到100%的时候,会生成新的数据集。
基于云的视频图像训练样本增强系统具体实现过程包括:
1、用户注册账号登陆云端系统,创建数据集,然后进入数据集文件上传页面,选择本地图片视频文件并上传到云端;
2、视频配置,如果步骤一上传的是视频文件,用户需做如下选择:
1)是否从视频中裁切出感兴趣的时间段,如果是的话,首先选择感兴趣时间段的起点时间戳,然后选择感兴趣时间段的终点的时间戳。最后点击确定;
2)是否对感兴趣的视频时间段进行矩形框裁剪,在感兴趣时间段的基础上选择感兴趣区域。首先使用鼠标点击感兴趣矩形区域的左上角,然后拖拽鼠标到感兴趣区域的右下角,松开鼠标,并点击确定按钮;
3、样本标准化配置,该步骤将样本数据集中的图像与书品的格式,分辨率统一,用户需做如下选择:
1)是否统一所有上传的样本文件的格式,如果选择是,则需要选择一个目标格式;
2)是否统一所有上传的样本文件的分辨率,如果选择是,则需要选择一个目标分辨率;
2)选择完后点击确定;
4、样本数据扩展配置,用户选择是否对样本文件进行扩展。如果选择是,则在一下三种扩展方式中选择一种:
2)基于深度学习的gan图像生成;
3)图像基本变换;
5、确定最终的任务工作流,在页面中浏览以上几步配置的汇总,没问题的话点击确认,生成任务,发送到消息队列;
6、云端服务器处理任务,云端服务器从消息队列中读取任务,并根据任务的内容,分别做如下的处理:
1)视频时间段裁剪与感兴趣区域裁剪,与视频格式转换:
步骤1:根据任务配置解析以下参数:感兴趣时间段起始时间戳t1,结束时间戳t2,以及感兴趣区域的起始坐标x,y与宽和高:w,h;
步骤2:使用开源库ffmpeg来完成视频的裁剪与格式转换,假设输入视频为:input.avi,输出视频为output.mp4,使用如下命令:
ffmpeg-iinput.avi-sst1-ccopy-tot2output.mp4crop=w=100:h=100:x=12:y=34-c:vlibx264;
步骤3:将output.mp4存储到数据集中;
2)图像格式转换(该步骤相对来说比较简单)
步骤1:读取任务配置中的图像转换的格式;
步骤2:调用imagemagic库完成图像格式转换;
3)图像分辨率,视频分辨率转换:
步骤1:读取任务配置中的分辨率参数;
步骤2:判断目标分辨率res1与原始分辨率res0的关系:
1、若res0>res1,使用最邻近插值算法,将图片分辨率降低到res1,对于原图像的每一个像素(src_x,src_y),建立其与对应的目标像素(dst_x,dst_y)的关系:
src_x=dst_x*(ws/wd)
src_y=dst_y*(hs/hd)
其中ws,hs分别为源图的宽与高。wd,hd分别为目标图片的宽与高。
2、若res0<res1,使用基于神经网络的图像超分辨率还原算法提高图像的分辨率到res1,对于待生成的目标图像xd,与原图像xs与超分辨率还原算法f有:
xd=f(xs);
f=convd1·convd2…convdn·convu1·convu2…convun;
其中convd1…convdn为图像编码神经网络,convu1…convun为图像解码神经络,对于不同分辨率的图像,神经网络的层数会有不同的变化;
3、若res0=res1则不执行任何操作;
3)图像基本变换:通过图像旋转变换,镜像变换,仿射变换生成新的样本:
步骤一:读取任务配置中变换方式;
步骤二:根据变换参数执行实际变换操作,假设原图的每一个像素(xs,ys),目标图像的每一个像素(xd,yd):
1、图像旋转变换:
其中θ为旋转的角度;
2、图像镜像翻转:
其中w为图像的宽度;
3、图像仿射变换:
其中a1a2b1b2c1c2为仿射变换的6个参数;
4)基于深度学习的gan图像生成,包括:
步骤1:读取任务配置中的gan图像生成的参数。
步骤2:使用gan神经网络生成目标图像,令目标图像为xd,有:
xd=fgan(xrand),
其中,xrand为随机生成的1024维的初始向量,
fgan=fconve·factive
其中,fconve为卷积函数;
其中,factive为sigmoid激活函数;
其中,z为fup函数的输出结果;
步骤三:将生成的目标图上存储到数据集中;
5)云端服务器完成任务,更新数据库中任务状态,并发送消息通知前端用户。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!