基于图神经网络的全景分割方法、系统、设备及存储介质与流程
本发明涉及图像数据处理技术领域,尤其涉及一种基于图神经网络的全景分割方法、基于图神经网络的全景分割系统、计算机设备及计算机可读存储介质。
背景技术:
图像分割(imagesegmentation)技术是计算机视觉领域的研究热点,它在人们生活中的方方面面都有着非常广泛的应用,如自动驾驶领域的地图构建、医学影像领域的自动化诊断、日常生活中的虚拟试穿等。
图像分割技术分为语义分割(semanticsegmentation)、实例分割(instancesegmentation)及全景分割(panopticsegmentation)。其中:
语义分割要求对图像中的每一个像素都赋予一个类别标签,但是不对相同物体的不同实例进行区分。比如,如果一个像素被标记为红色,那就代表这个像素所在的位置是一个人,但是如果有两个都是红色的像素,则无法判断它们是属于同一个人还是不同的人,也就是说语义分割只能判断类别,无法区分个体。
实例分割则要求识别出图像中的每个物体以及区分物体实例,而忽略背景像素的分割。也就是说,实例分割不需要对每个像素进行标记,它只需要找到感兴趣物体的边缘轮廓就行。
全景分割是语义分割和实例分割的结合,要求对图像中的每个像素都赋予类别,并且对属于可数物体的像素,还要区分物体实例。但是,现有的全景分割技术没有考虑图片中前景和前景、背景和背景、前景和背景之间的关系,仅仅是两个独立的任务,没有像人类一样从物体关系的层面来进行推断。比如,一般来说,在湖上的物体更可能是一艘船而不是一辆车;如果背景是天空,那么前景物体更可能是小鸟而不是鱼;人牵着的更可能是一只狗而不是一匹狼。因此,现有的全景分割技术预测效果并不好,经常有误判的情况发生。
技术实现要素:
本发明所要解决的技术问题在于,提供一种基于图神经网络的全景分割方法、系统、计算机设备及计算机可读存储介质,可将全景分割网络应用于图片处理中,使预测更准确,网络解释性更强。
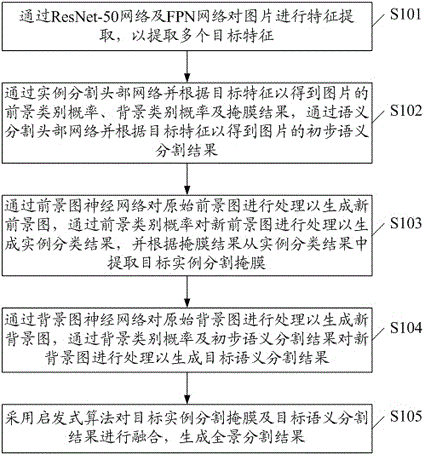
为了解决上述技术问题,本发明提供了一种基于图神经网络的全景分割方法,包括:通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征;通过实例分割头部网络并根据所述目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果,通过语义分割头部网络并根据所述目标特征以得到图片的初步语义分割结果;通过前景图神经网络对原始前景图进行处理以生成新前景图,通过所述前景类别概率对所述新前景图进行处理以生成实例分类结果,并根据所述掩膜结果从所述实例分类结果中提取目标实例分割掩膜;通过背景图神经网络对原始背景图进行处理以生成新背景图,通过所述背景类别概率及初步语义分割结果对所述新背景图进行处理以生成目标语义分割结果;采用启发式算法对所述目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果。
作为上述方案的改进,所述通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征的步骤包括:通过resnet-50网络对图片进行特征提取,以提取初步特征;通过fpn网络对所述初步特征进行特征提取,以提取多个目标特征。
作为上述方案的改进,所述通过实例分割头部网络并根据目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果的步骤包括:通过rpn网络对每一目标特征分别进行处理,以生成多个候选区域;对每一候选区域分别进行池化处理,以生成候选区域特征;通过全连接层对每一候选区域特征分别进行处理,以生成初步特征图;通过全连接层对每一初步特征图进行处理,以生成前景类别概率;通过全连接层对每一初步特征图进行处理,以生成背景类别概率;对每一候选区域特征分别进行卷积处理,以生成每一类别的掩模结果。
作为上述方案的改进,所述通过语义分割头部网络并根据目标特征以得到图片的初步语义分割结果的步骤包括:对每一目标特征分别进行上采样处理;将所有上采样结果相加,以生成特征;将所述特征进行上采样处理,以生成语义分割特征;将所述特征进行卷积处理;将卷积结果进行上采样处理,以生成初步语义分割结果。
作为上述方案的改进,所述通过前景图神经网络对原始前景图进行处理以生成新前景图,通过前景类别概率对新前景图进行处理以生成实例分类结果,并根据掩膜结果从实例分类结果中提取目标实例分割掩膜的步骤包括:通过前景图神经网络对原始前景图进行节点特征的传播及节点表示的更新,以生成新前景图;对所述前景类别概率中的每一行向量分别进行归一化处理,将每一归一化结果分别作为实例注意力系数,将每一实例注意力系数与新前景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成实例一维向量;将所述实例一维向量与初步特征图中对应的行向量进行拼接,以生成新实例特征图;通过全连接层对所述新实例特征图进行处理,以生成实例分类结果;提取实例分类结果中每一行的概率最大值,根据所述概率最大值提取候选区域对应的类别,并根据所述类别提取对应的掩模结果以得到目标实例分割掩膜。
作为上述方案的改进,所述通过背景图神经网络对原始背景图进行处理以生成新背景图,通过背景类别概率及初步语义分割结果对新背景图进行处理以生成目标语义分割结果的步骤包括:通过背景图神经网络对原始背景图进行节点特征的传播及节点表示的更新,以生成新背景图;对所述背景类别概率中的每一行向量分别进行归一化处理,将所有归一化结果相加以作为第一注意力系数;对所述初步语义分割结果中每一像素所对应的向量分别进行归一化处理,将每一归一化结果分别作为第二注意力系数;将每一第二注意力系数与第一注意力系数分别相加并求均值以作为语义注意力系数,将每一语义注意力系数与新背景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成语义一维向量;将每一语义一维向量与所述语义分割特征中对应像素的向量分别进行拼接,以生成新语义特征图;将所述新语义特征图输入卷积层,以生成目标语义分割结果。
作为上述方案的改进,,所述采用启发式算法对目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果的步骤包括:判断图片中的像素在所述目标实例分割掩膜中是否存在对应的标签;判断为是时,则将所述目标实例分割掩膜中对应的标签赋值给所述像素;判断为否是,则将所述目标语义分割结果中对应的标签赋值给所述像素。
相应地,本发明还提供了一种基于图神经网络的全景分割系统,包括:特征提取单元,用于通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征;初步分割单元,用于通过实例分割头部网络并根据所述目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果,通过语义分割头部网络并根据所述目标特征以得到图片的初步语义分割结果;实例分割单元,用于通过前景图神经网络对原始前景图进行处理以生成新前景图,通过所述前景类别概率对所述新前景图进行处理以生成实例分类结果,并根据所述掩膜结果从所述实例分类结果中提取目标实例分割掩膜;语义分割单元,用于通过背景图神经网络对原始背景图进行处理以生成新背景图,通过所述背景类别概率及初步语义分割结果对所述新背景图进行处理以生成目标语义分割结果;全景分割单元,用于采用启发式算法对所述目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果。
相应地,本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行上述全景分割方法的步骤。
相应地,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述全景分割方法的步骤。
实施本发明,具有如下有益效果:
本发明基于图神经网络的全景分割方法能够考虑前景之间、背景之间以及前景和背景之间的关系,利用了注意力机制来分配权重,从而能够更好地纠正错误的预测结果,让全景分割网络对图片数据预测得更加准确,且网络的解释性更强。
同时,本发明的图节点使用语义的词嵌入表示,和视觉特征一起进行特征提取,相当于将语义信息和视觉信息相结合,给网络提供了更丰富的信息,也更符合人类的推理过程。
附图说明
图1是本发明基于图神经网络的全景分割方法的实施例流程;
图2是本发明中前景类别概率、背景类别概率及掩膜结果的生成流程图;
图3是本发明中初步语义分割结果的生成流程图;
图4是本发明中目标实例分割掩膜的生成流程图;
图5是本发明中目标语义分割结果的生成流程图;
图6是本发明中基于图神经网络的全景分割方法的示意图;
图7是本发明基于图神经网络的全景分割系统的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
参见图1,图1显示了本发明基于图神经网络的全景分割方法的实施例流程图,包括:
s101,通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征。
具体地,所述通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征的步骤包括:
(1)通过resnet-50网络对图片进行特征提取,以提取初步特征。
resnet又名残差神经网络,指的是在传统卷积神经网络中加入残差学习(residuallearning)的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度。本发明中采用50层的resnet网络。
(2)通过fpn网络对所述初步特征进行特征提取,以提取多个目标特征。
需要说明的是,所述fpn网络为四层的fpn网络。其中,fpn(featurepyramidnetwork)网络即特征金字塔网络,特征金字塔网络通过自底向上的特征提取、自顶向下的特征上采样以及横向连接来把底层特征和顶层特征结合起来,在每一层能够获得不同尺寸大小的特征信息。
因此,本发明将图片输入resnet-50网络进行处理后,输出初步特征;再将初步特征输入一个四层的fpn网络进行处理后,输出目标特征p1、p2、p3及p4。
s102,通过实例分割头部网络并根据目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果,通过语义分割头部网络并根据目标特征以得到图片的初步语义分割结果。
经步骤s101提取出来的目标特征分别通过两个分割头部网络,一个是实例分割头部网络,另一个是语义分割头部网络。具体地:
从fpn网络出来的目标特征需要经过实例分割头部网络的三个分支:
(1)实例分类分支。目标特征经过实例分类分支得到前景类别概率cins;
(2)掩模分支。目标特征经过掩膜分支得到对应每个类别的掩膜结果mins;
(3)背景类别分支。目标特征经过背景类别分支则输出在该前景类别情况下的背景类别概率pb。
从fpn网络出来的目标特征需要经过语义分割头部网络,得到图片的初步语义分割结果msem。
s103,通过前景图神经网络对原始前景图进行处理以生成新前景图,通过所述前景类别概率对所述新前景图进行处理以生成实例分类结果,并根据掩膜结果从实例分类结果中提取目标实例分割掩膜。
s104,通过背景图神经网络对原始背景图进行处理以生成新背景图,通过背景类别概率及初步语义分割结果对新背景图进行处理以生成目标语义分割结果。
需要说明的是,本发明中设有两个图神经网络,一个是前景图网络gf,一个是背景图网络gb。其中,原始前景图nins经过前景图神经网络gf得到传播更新后的新前景图nins_g,原始背景图nsem经过图神经网络gb得到传播更新后的新背景图nsem_g。
一般情况下,前景指图片中可数的物体,如人、车、飞机、猫、狗等;背景指图片中不可数的物体,如天空、草地、湖等。本发明中,原始前景图即原始前景图谱,原始背景图即原始背景图谱。原始前景图及原始背景图均由多个节点构成,节点采用类别语义的词嵌入表示。其中,词嵌入是一个一维向量,本发明采用glove(globalvectorsforwordrepresentation,全局词向量)方法来获得类别语义的词嵌入表示,因此每个节点是一个300维的向量,而节点与节点之间的邻接矩阵是使用余弦距离计算而得的。
因此,本发明中的图节点使用语义的词嵌入表示,和视觉特征一起进行特征提取,相当于将语义信息和视觉信息相结合,给网络提供了更丰富的信息,也更符合人类的推理过程。
s105,采用启发式算法对所述目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果。
具体地,所述采用启发式算法对目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果的步骤包括:
(1)判断图片中的像素在目标实例分割掩膜中是否存在对应的标签;
(2)判断为是时,则将目标实例分割掩膜中对应的标签赋值给所述像素;
(3)判断为否是,则将目标语义分割结果中对应的标签赋值给所述像素。
本发明采用使用启发式算法对目标实例分割掩膜mins_g及目标语义分割结果msem_g进行融合。需要说明的是,对于图片中的每一个像素,优先采用目标实例分割掩膜mins_g中的标签,如果一个像素在目标实例分割掩膜mins_g中没有标签,则给该像素赋值目标语义分割结果msem_g中的标签。
因此,本发明在网络中加入了图谱,通过图谱能够更好地编码前景与前景、背景与背景以及前景与背景之间的关系,能够有效纠正预测结果的偏差,使得预测结果更加准确。
如图2所示,所述通过实例分割头部网络并根据目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果的步骤包括:
s201,通过rpn网络对每一目标特征分别进行处理,以生成多个候选区域。
目标特征p1、p2、p3及p4分别通过rpn网络(regionproposalnetwork,区域候选网络),得到可以检测不同尺寸实例的候选区域。
需要说明的是,区域候选网络用于在特征图上选取若干候选区域,让后续网络对候选区域内的内容进行检测操作。
s202,对每一候选区域分别进行池化处理,以生成候选区域特征。
使用roipooling(regionofinterestpooling,感兴趣区域池化)对候选区域进行操作,可以得到候选区域特征,此时,多个不同大小的候选区域特征已经被池化到统一大小。
需要说明的是,由于经过rpn网络得到的候选区域大小可能不相同,为了方便后面的操作,需要将不同大小的候选区域变成统一大小的特征。感兴趣区域池化就是通过对不同大小的特征进行池化操作,从而达到统一特征大小的目的。
s203,通过全连接层对每一候选区域特征分别进行处理,以生成初步特征图。
用于预测候选区域类别以及bbox(boundingbox,包围框)参数的特征被统一成7×7的大小,然后通过两个全连接层,得到初步特征图
相应地,可通过一个全连接层对每一初步特征图进行处理,以生成回归的bbox参数
s204,通过全连接层对每一初步特征图进行处理,以生成前景类别概率。
用一个分类的全连接层得到前景类别概率
s205,通过全连接层对每一初步特征图进行处理,以生成背景类别概率。
初步特征图经过一个用于预测背景类别概率的全连接层,得到背景类别概率pb。
s206,对每一候选区域特征分别进行卷积处理,以生成每一类别的掩模结果。
对每个类别预测一个掩模的特征向量被统一成14×14的大小,本发明采用全卷积网络,最终得到对应于每一个类别的掩模结果
因此,通过步骤s201~s206即可利用实例分割头部网络的三个分支,高效、精确地得到前景类别概率cins、掩膜结果mins及背景类别概率pb。
如图3所示,所述通过语义分割头部网络并根据所述目标特征以得到图片的初步语义分割结果的步骤包括:
s301,对每一目标特征分别进行上采样处理;
s302,将所有上采样结果相加,以生成特征;
s303,将所述特征进行上采样处理,以生成语义分割特征;
s304,将所述特征进行卷积处理;
s305,将卷积结果进行上采样处理,以生成初步语义分割结果。
为了进行全图的语义分割,将目标特征p1、p2、p3、p4分别进行上采样到相同的大小,并且进行相加,得到相加后的特征
因此,通过步骤s301~s305即可利用语义分割头部网络,快速地得到图片的初步语义分割结果msem。
如图4所示,所述通过前景图神经网络对原始前景图进行处理以生成新前景图,通过前景类别概率对新前景图进行处理以生成实例分类结果,并根据掩膜结果从实例分类结果中提取目标实例分割掩膜的步骤包括:
s401,通过前景图神经网络对原始前景图进行节点特征的传播及节点表示的更新,以生成新前景图。
原始前景图
s402,对前景类别概率中的每一行向量分别进行归一化处理,将每一归一化结果分别作为实例注意力系数,将每一实例注意力系数与新前景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成实例一维向量。
需要说明的是,每个候选区域的前景类别概率cins中,每一行代表一个候选区域对应的前景类别概率,每一行的向量cins_i为一个1×(cf+1)的向量,因此,对行向量进行一个softmax(softmax是一个常用的映射函数,能够把输入映射为0-1之间的实数,并且归一化保证和为1)的操作,使得前景类别概率cins都归一到0到1之间;然后,以此作为实例注意力系数,和新前景图nins_g进行相乘;相乘后,对每一行对应的值进行相加并求均值,得到一个图的一维向量
s403,将实例一维向量与初步特征图中对应的行向量进行拼接,以生成新实例特征图
将对应的一维向量nins_rep与初步特征图x对应的行向量进行拼接,得到新特征图
s404,通过全连接层对所述新实例特征图进行处理,以生成实例分类结果
令新特征图xg再经过一个全连接层,输出维度为
s405,提取实例分类结果中每一行的概率最大值,根据所述概率最大值提取候选区域对应的类别,并根据所述类别提取对应的掩模结果以得到目标实例分割掩膜。
对实例分类结果cins_g每一行的概率取最大值,选出该候选区域对应的类别,并使用该类别选取对应的掩模,得到目标实例分割掩膜mins_g。
因此,本发明使用实例分割头部网络的前景类别概率cins作为实例注意力系数,并将实例注意力系数与新前景图nins_g进行结合,再将结合结果
如图5所示,所述通过背景图神经网络对原始背景图进行处理以生成新背景图,通过背景类别概率及初步语义分割结果对新背景图进行处理以生成目标语义分割结果的步骤包括:
s501,通过背景图神经网络对原始背景图进行节点特征的传播及节点表示的更新,以生成新背景图。
原始背景图
s502,对背景类别概率中的每一行向量分别进行归一化处理,将所有归一化结果相加以作为第一注意力系数。
提取背景类别概率
s503,对初步语义分割结果中每一像素所对应的向量分别进行归一化处理,将每一归一化结果分别作为第二注意力系数。
提取初步语义分割结果msem,由于初步语义分割结果msem中每个像素值都由一个
s504,将每一第二注意力系数与第一注意力系数分别相加并求均值以作为语义注意力系数,将每一语义注意力系数与新背景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成语义一维向量。
需要说明的是,由于初步语义分割结果有h×w个像素,因此有h×w个第二注意力系数
s505,将每一语义一维向量与语义分割特征中对应像素的向量分别进行拼接,以生成新语义特征图。
将对应的语义一维向量nsem_rep与步骤s302得到的特征y中对应像素的向量进行拼接,得到新的特征图
s506,将新语义特征图输入卷积层,以生成目标语义分割结果。
将新语义特征图yg输入一个卷积核为1×1的卷积层后,得到最终的目标语义分割结果msem_g。
因此,本发明将实例分割头部网络的背景类别概率pb和语义分割头部网络的初步语义分割结果msem进行加权求均值,作为语义注意力系数,并将语义注意力系数与新背景图nsem_g进行结合,再将结合结果
结合图6可知,本发明基于图神经网络的全景分割方法能够考虑前景之间、背景之间以及前景和背景之间的关系,利用了注意力机制来分配权重,从而能够更好地纠正错误的预测结果,让全景分割网络预测得更加准确,且网络的解释性更强。
参见图7,图7显示了本发明基于图神经网络的全景分割系统100的具体结构,其包括:
特征提取单元1,用于通过resnet-50网络及fpn网络对图片进行特征提取,以提取多个目标特征。具体地,先通过resnet-50网络对图片进行特征提取以提取初步特征,再通过fpn网络对所述初步特征进行特征提取以提取多个目标特征。
初步分割单元2,用于通过实例分割头部网络并根据所述目标特征以得到图片的前景类别概率、背景类别概率及掩膜结果,通过语义分割头部网络并根据所述目标特征以得到图片的初步语义分割结果。具体地,通过rpn网络对每一目标特征分别进行处理,以生成多个候选区域;对每一候选区域分别进行池化处理,以生成候选区域特征;通过全连接层对每一候选区域特征分别进行处理,以生成初步特征图;通过全连接层对每一初步特征图进行处理,以生成前景类别概率;通过全连接层对每一初步特征图进行处理,以生成背景类别概率;对每一候选区域特征分别进行卷积处理,以生成每一类别的掩模结果。另外,还对每一目标特征分别进行上采样处理;将所有上采样结果相加,以生成特征;将所述特征进行上采样处理,以生成语义分割特征;将所述特征进行卷积处理;将卷积结果进行上采样处理,以生成初步语义分割结果。
实例分割单元3,用于通过前景图神经网络对原始前景图进行处理以生成新前景图,通过所述前景类别概率对所述新前景图进行处理以生成实例分类结果,并根据所述掩膜结果从所述实例分类结果中提取目标实例分割掩膜。具体地,通过前景图神经网络对原始前景图进行节点特征的传播及节点表示的更新,以生成新前景图;对所述前景类别概率中的每一行向量分别进行归一化处理,将每一归一化结果分别作为实例注意力系数,将每一实例注意力系数与新前景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成实例一维向量;将所述实例一维向量与初步特征图中对应的行向量进行拼接,以生成新实例特征图;通过全连接层对所述新实例特征图进行处理,以生成实例分类结果;提取实例分类结果中每一行的概率最大值,根据所述概率最大值提取候选区域对应的类别,并根据所述类别提取对应的掩模结果以得到目标实例分割掩膜。
语义分割单元4,用于通过背景图神经网络对原始背景图进行处理以生成新背景图,通过所述背景类别概率及初步语义分割结果对所述新背景图进行处理以生成目标语义分割结果。具体地,通过背景图神经网络对原始背景图进行节点特征的传播及节点表示的更新,以生成新背景图;对所述背景类别概率中的每一行向量分别进行归一化处理,将所有归一化结果相加以作为第一注意力系数;对所述初步语义分割结果中每一像素所对应的向量分别进行归一化处理,将每一归一化结果分别作为第二注意力系数;将每一第二注意力系数与第一注意力系数分别相加并求均值以作为语义注意力系数,将每一语义注意力系数与新背景图分别相乘以生成加权结果,将每一行的加权结果相加并求均值以生成语义一维向量;将每一语义一维向量与所述语义分割特征中对应像素的向量分别进行拼接,以生成新语义特征图;将所述新语义特征图输入卷积层,以生成目标语义分割结果。
全景分割单元5,用于采用启发式算法对所述目标实例分割掩膜及目标语义分割结果进行融合,生成全景分割结果。需要说明的是,对于图片中的每一个像素,优先采用目标实例分割掩膜mins_g中的标签,如果一个像素在目标实例分割掩膜mins_g中没有标签,则给该像素赋值目标语义分割结果msem_g中的标签。
因此,本发明能够考虑前景之间、背景之间以及前景和背景之间的关系,利用了注意力机制来分配权重,从而能够更好地纠正错误的预测结果,让全景分割网络对图片数据预测得更加准确,且网络的解释性更强。同时,本发明的图节点使用语义的词嵌入表示,和视觉特征一起进行特征提取,相当于将语义信息和视觉信息相结合,给网络提供了更丰富的信息,也更符合人类的推理过程。
相应地,本发明还提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述全景分割方法的步骤。同时,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述全景分割方法的步骤。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!