人工智能大数据分析处理系统及方法与流程
本发明涉及一种大数据系统,特别是涉及一种用于大数据的分析处理系统。
背景技术:
弹幕(danmaku),中文流行词语,指的是在网络上观看视频时弹出的评论性字幕。其通常是将其与主播发送的音乐、点播视频、直播视频、直播音频、直播ppt画面、静态照片等合成后同时发送至观众,并且,观众可随意发送弹幕进行评论。
然而,弹幕的评论性往往带有感情色彩,人们对于一个事务的观点往往是多面性的,为了尽量让用户看到与观点立场相似的观点,以避免骂战、人身攻击等网络暴力,弹幕分布均匀不会影响观看体验,不会因局部弹幕较少而使用户丧失观看兴趣,以增加用户粘性。因此,目前亟需一种更加能够增加用户粘性的、增加用户好感的人工智能大数据分析处理系统。
技术实现要素:
本发明要解决的技术问题是提供一种更加能够增加用户粘性的、增加用户好感的人工智能大数据分析处理系统。
本发明人工智能大数据分析处理系统,包括
数据获取部,其用于输入观众用户的在时间轨道上的弹幕数据;
场景捕捉部,其根据主播用户的背景音乐、语音和/或画面而生成在时间轨道上的场景数据;
数据补偿部,其根据当前时间轨道上的最大同时显示个数和弹幕数据的个数而在弹幕数据上增加第一数据或删除第二数据而使弹幕数据的个数与所述最大显示个数一致;
数据处理部,其根据观众用户在所述主播用户的流媒体上发送的在时间轨道上第一预设时间内的弹幕数据的词性而生成第一数据或第二数据。
本发明人工智能大数据分析处理系统,其中所述数据处理部比较观众用户在时间轨道上的弹幕数据中正向词性和反向词性的数量,当所述正向词性大于或等于反向词性时,则将所述反向词性替换为正向词性或填充词性,当所述反向词性大于正向词性时,则将所述正向词性替换为反向词性或填充词性。
本发明人工智能大数据分析处理系统,其中所述数据处理部比较场景捕捉部捕获的时间轨道上的单位时间内的场景数据中的正向词性的数量和反向词性的数量,当正向词性的数量大于等于反向词性的数量,则判定该单位时间内场景数据是正向场景数据,当反向词性数量大于正向词性数量,则判定该单位时间内场景数据是反向场景数据;
当场景数据为正向场景数据时,则将观众用户的时间轨道上的该单位时间内的弹幕数据中的反向词性替换为正向词性或填充词性,当场景数据为反向场景数据时,则将观众用户的时间轨道上的该点位时间内的弹幕数据中的正向词性替换为反向词性。
本发明人工智能大数据分析处理系统,其中所述数据处理部比较场景捕捉部捕获的时间轨道上的单位时间内的场景数据中的正向词性的数量和反向词性的数量,当正向词性的数量大于等于反向词性的数量,则判定该单位时间内场景数据是正向场景数据,当反向词性数量大于正向词性数量,则判定该单位时间内场景数据是反向场景数据;
当在上述主播用户中的多个观众用户中显示在时间轨道上的弹幕数据的观众用户输入的弹幕数据的正向词性大于或等于反向词性时,则在该观众用户显示的正向场景数据的弹幕数据的反向词汇替换为正向词汇;
当在上述主播用户中的多个观众用户中显示在时间轨道上的弹幕数据的观众用户输入的弹幕数据的反向词性大于正向词性时,则在该观众用户显示的反向场景数据的弹幕数据的正向词汇替换为反向词汇。
本发明人工智能大数据分析处理系统,其中所述场景数据捕捉部通过音频识别软件识别背景音乐的歌名、歌词,并在所述背景音乐持续时间内,将其歌名做为所述背景音乐持续时间内的场景数据;并在单句歌词出现的持续时间内,将所述单句歌词的每个单词拆分为单句歌词出现的持续时间内的场景数据;
所述数据处理部根据所述背景音乐持续时间或单句歌词出现的持续时间切换所述时间轨道上的单位时间。
本发明人工智能大数据分析处理系统,其中所述场景数据捕捉部通过音频识别软件识别主播用户的语音,并在相邻的两句或多句语音间隔低于第二预设阈值时,将上述两句或多句合并为一个句段,再将上述句段的拆分为所述句段持续时间内的场景数据;
所述数据处理部将所述所述句段持续时间配置为时间轨道上的单位时间;
其中,当所述音频识别软件能够同时识别主播用户的语音和背景音乐时,场景数据捕捉部对比主播用户的语音和背景音乐的响度而通过响度较大的为判定单位时间。
本发明人工智能大数据分析处理系统,其中当所述流媒体为视频时,所述场景捕捉部通过视频识别软件识别主播用户的视频的文字数据,并在当在时间轨道上所述文字数据出现的时间超过第三阈值时,则将所述文字数据转化为拆分为所述文字数据持续时间内的场景数据;
当所述视频被视频识别软件在相同时间识别出至少两个文字数据时,场景捕捉部将所述至少两个文字数据的最早开始时间和最晚结束时间判定为单位时间,其中所述单位时间应小于第四阈值。
本发明人工智能大数据分析处理系统,其中当观众用户输入的弹幕数据的个数大于所述最大显示个数时,数据补偿部删除弹幕数据的第二数据,所述第二数据的个数等于所述弹幕数据的个数与所述最大显示个数的差,所述第二数据为在所述弹幕数据中的随机的填充词性或随机的任意数据;
当观众用户输入的弹幕数据的个数小于所述最大显示个数时,数据补偿部补偿弹幕数据的第一数据,所述第一数据的个数等于所述最大显示个数与所述弹幕数据的个数的差,所述第一数据为所述弹幕数据中的任意数据的同义词或任意数据的相同的词或随机的填充词性。
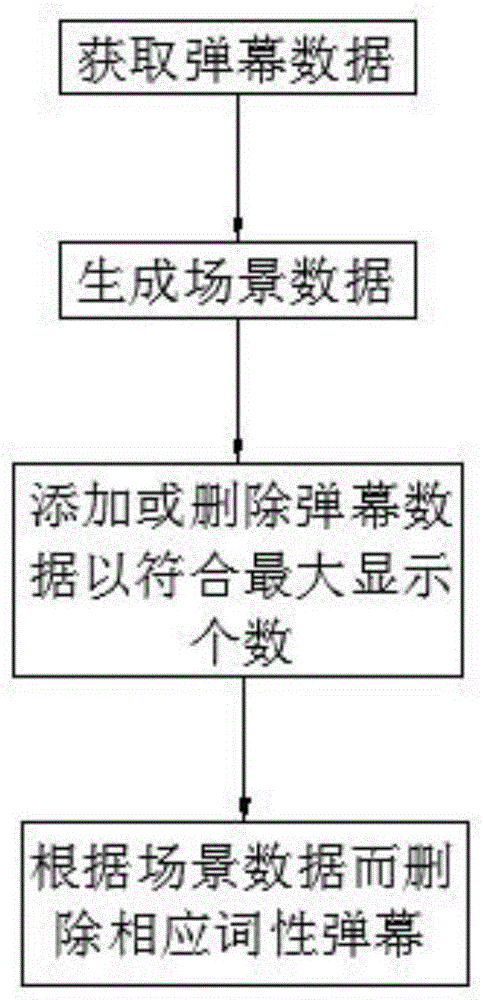
本发明人工智能大数据分析处理系统的处理方法,包括如下步骤:
获取观众用户的在时间轨道上的弹幕数据;
根据主播用户的背景音乐、语音和/或画面而生成在时间轨道上的场景数据;
根据当前时间轨道上的最大同时显示个数和弹幕数据的个数而在弹幕数据上增加第一数据或删除第二数据而使弹幕数据的个数与所述最大显示个数一致;
根据观众用户在所述主播用户的流媒体上发送的在时间轨道上第一预设时间内的弹幕数据的词性而生成第一数据或第二数据。
本发明人工智能大数据分析处理系统与现有技术不同之处在于本发明人工智能大数据分析处理系统本发明通过方式而将每个观众用户发送弹幕的不同喜好结合主播用户的不同背景音乐、语音和/或画面的场景而有针对性地生成用户补偿屏幕上显示的第一数据的弹幕或删除第二数据的弹幕,以使与主播用户的流媒体合成的弹幕不会过多或多少,并符合观众用户观看的喜好,增加用户粘性。
下面结合附图对本发明的人工智能大数据分析处理系统作进一步说明。
附图说明
图1是人工智能大数据分析处理系统的流程图。
具体实施方式
如图1所示,本发明人工智能大数据分析处理系统包括
数据获取部,其用于输入观众用户的在时间轨道上的弹幕数据;
场景捕捉部,其根据主播用户的背景音乐、语音和/或画面而生成在时间轨道上的场景数据;
数据补偿部,其根据当前时间轨道上的最大同时显示个数和弹幕数据的个数而在弹幕数据上增加第一数据或删除第二数据而使弹幕数据的个数与所述最大显示个数一致;
数据处理部,其根据观众用户在所述主播用户的流媒体上发送的在时间轨道上第一预设时间内的弹幕数据的词性而生成第一数据或第二数据。
本发明通过方式而将每个观众用户发送弹幕的不同喜好结合主播用户的不同背景音乐、语音和/或画面的场景而有针对性地生成用户补偿屏幕上显示的第一数据的弹幕或删除第二数据的弹幕,以使与主播用户的流媒体合成的弹幕不会过多或多少,并符合观众用户观看的喜好,增加用户粘性。
其中,数据获取部可先根据输入观众用户的在时间轨道上的弹幕数据与不良词汇数据库进行对比,并剔除与输入观众用户的在时间轨道上的弹幕数据中与不良词汇数据库重合的数据,并将筛选后的弹幕数据上传,从而避免不良词汇对其他用户造成影响。
其中,最大同时显示个数可由能够显示视频流和弹幕的窗口的大小、分辨率或第一预设阈值而决定。优选的,所述最大显示个数可为同一屏幕下滚动的第一预设阈值可为:4~100个弹幕或10字符~100字符的弹幕。进一步优选为,所述最大显示个数可为同一屏幕下滚动20个弹幕或40字符的弹幕。
作为对本实施例的进一步解释,所述数据处理部比较观众用户在时间轨道上的弹幕数据中正向词性和反向词性的数量,当所述正向词性大于或等于反向词性时,则将所述反向词性替换为正向词性或填充词性,当所述反向词性大于正向词性时,则将所述正向词性替换为反向词性或填充词性。
本发明通过上述单纯的考虑到观众用户们发送弹幕的词性的数量而将正向词性或反向词性势力较弱的一方替换为势力较强的一方的词性,从而减少不必要的网络战争,并且,增加流媒体的可观赏性,增加用户粘性,避免网络攻击、网络暴力给观众用户带来的心里创伤。
其中,填充词性可为中性词或搞笑词性,例如,中性词:还行、差不多、没问题、好的、哦、恩等,搞笑词:大威天龙、雨女无瓜、人艰不拆等网络搞笑词。
其中,正向词性例如:真棒、666、好强、无敌、漂亮等。反向词性例如:无聊、难看、没意思、就这等。
其中,正向词性、反向词性、填充词性均有相应的数据库。
作为对本实施例的进一步解释,所述数据处理部比较场景捕捉部捕获的时间轨道上的单位时间内的场景数据中的正向词性的数量和反向词性的数量,当正向词性的数量大于等于反向词性的数量,则判定该单位时间内场景数据是正向场景数据,当反向词性数量大于正向词性数量,则判定该单位时间内场景数据是反向场景数据;
当场景数据为正向场景数据时,则将观众用户的时间轨道上的该单位时间内的弹幕数据中的反向词性替换为正向词性或填充词性,当场景数据为反向场景数据时,则将观众用户的时间轨道上的该点位时间内的弹幕数据中的正向词性替换为反向词性。
本发明通过上述基于随时切换的场景而仅向用户输出符合所述场景数据的弹幕数据,从而可过滤掉与场景不符合或故意与场景唱反调的弹幕而避免引发弹幕的骂战。
具体的说,将与场景不符合的正向词性和反向词性适应于不同的正向场景数据或反向场景数据,可使弹幕能够更好的应对于场景的特征而将与场景不符合的词性替换为与场景符合的词性,并保留原有弹幕中与场景符合的词性,从而避免与场景不符合的词性所带来的突兀感和网络骂战,净化网络环境。
其中,在默认情况下,而在反向词性数量大于正向词性数量的1.1~5倍时,才将其识别为反向场景数据;其他情况可将大多场景识别为正向场景数据。
其中,优选为,反向词性数量大于正向词性数量的3倍时,才将其识别为反向场景数据;其他情况可将大多场景识别为正向场景数据。
本发明通过上述方式可尽可能避免识别错误而在相邻的场景中发生错乱或诱发不和谐问题。
作为对本实施例的进一步解释,所述数据处理部比较场景捕捉部捕获的时间轨道上的单位时间内的场景数据中的正向词性的数量和反向词性的数量,当正向词性的数量大于等于反向词性的数量,则判定该单位时间内场景数据是正向场景数据,当反向词性数量大于正向词性数量,则判定该单位时间内场景数据是反向场景数据;
当在上述主播用户中的多个观众用户中显示在时间轨道上的弹幕数据的观众用户输入的弹幕数据的正向词性大于或等于反向词性时,则在该观众用户显示的正向场景数据的弹幕数据的反向词汇替换为正向词汇;
当在上述主播用户中的多个观众用户中显示在时间轨道上的弹幕数据的观众用户输入的弹幕数据的反向词性大于正向词性时,则在该观众用户显示的反向场景数据的弹幕数据的正向词汇替换为反向词汇。
本发明通过上述方式将场景数据是正向场景数据和反向场景数据来判断该场景下主播用户的所呈现的状态是正向或反向的,例如胜利或失败,并继续根据用户通常发的正向的数据或反向的数据判定该观众用户时喜欢夸人的还是挖苦人的,而根据场景数据的切换而过滤掉可能与其内心想法发生冲突的数据,以符合用户的内心需求,增加用户的舒适度,避免网络骂战,增加用户粘性。
作为对本实施例的进一步解释,所述场景数据捕捉部通过音频识别软件识别背景音乐的歌名、歌词,并在所述背景音乐持续时间内,将其歌名做为所述背景音乐持续时间内的场景数据;并在单句歌词出现的持续时间内,将所述单句歌词的每个单词拆分为单句歌词出现的持续时间内的场景数据;
所述数据处理部根据所述背景音乐持续时间或单句歌词出现的持续时间切换所述时间轨道上的单位时间。
本发明通过上述音频识别软件来识别背景音乐的歌名和每一句歌词及其持续时间,可便于确定上述单位时间的切换,也就是说,在通过所述时间轨道上的单为时间的确定场景数据的正向或反向时,为了使单位时间能够更加切合该场景想要表达的场景时,可根据歌名或单句歌词的持续时间来判定,并且,上述歌名和/或单句歌词的单词中,也可将其转变为场景数据而进行识别,从而增加了对于场景数据的正向或反向识别的准确性。
例如,歌名《倍儿爽》,当单句歌词为“这个feel倍儿爽”,如果以单句歌词持续时间为所述时间轨道上的单位时间,那么在所述时间轨道上的单位时间的场景数据为:“倍儿爽”正向、“这个”中性、“feel”中性、“倍儿爽”正向。因此判定该单位时间内场景数据是正向场景数据,并替换反向场景数据为正向场景数据。
优选的,所述被替换的反向场景数据为正向场景数据时,所述正向场景数据可为原有场景数据中的正向场景数据或中性场景数据的近义词或同义词或完全相同的词汇。
同理,所述被替换的正向场景数据为反向场景数据时,所述正向场景数据可为原有场景数据中的反向场景数据或中性场景数据的近义词或同义词或完全相同的词汇。
作为对本实施例的进一步解释,所述场景数据捕捉部通过音频识别软件识别主播用户的语音,并在相邻的两句或多句语音间隔低于第二预设阈值时,将上述两句或多句合并为一个句段,再将上述句段的拆分为所述句段持续时间内的场景数据;
所述数据处理部将所述所述句段持续时间配置为时间轨道上的单位时间;
其中,当所述音频识别软件能够同时识别主播用户的语音和背景音乐时,场景数据捕捉部对比主播用户的语音和背景音乐的响度而通过响度较大的为判定单位时间。
本发明通过上述方式可更好的融合语音和背景音乐同时存在时,对于单位时间的判定,以准确评估场景数据,和切换场景,以更符合场景的内容并降低过多场景出现带来的算力要求,也避免过少场景切换带来的内容过于一致而没有转折。
其中,当流媒体为语音直播或视频直播时,应配置发送延迟大于历史最长句段的持续时间,以保证每个句段都能够充分计算后再发送,以保证能够在该时间轨道上能够筛选弹幕。
其中,所述历史最长句段的持续时间不应大于1分钟。
也就是说,当主播用户在说话时,既有语音又有背景音乐,那么音频识别软件同时识别语音和背景音乐,并对比此时语音和背景音乐的响度谁更大,若语音更大,则以语音的句段的持续时间判定单位时间,若背景音乐更大,则以预先设置的背景音乐持续时间或单句歌词出现的持续时间判定为单位时间。
其中,所述第二预设阈值可为0.1~5秒,优选为2秒。
其中,所述音频识别软件能够按照中文的习惯语句,将用户的语音标定“逗号”、“句号”、“感叹号”、“问号”。而当出现“句号”、“感叹号”、“问号”时,则判定此为用户的语音的一句,而在相邻的两句话的间隔低于第二预设阈值时,则将其判定为一个句段,若超过第二阈值或等于第二阈值,则将其分割为两个句段。
例如:一个句段可为“今天天气真好!我要出门了。”或者两个句段:“床前明月光,疑是地上霜。”、“举头望明月,低头思故乡。”
其中“再将上述句段的拆分为所述句段持续时间内的场景数据”可为,例如,所述句段为:“今天天气真好!我要出门了”,那么场景数据可为“今天”、“天气”、“真好!”、“我”、“要”、“出门了”。
作为对本实施例的进一步解释,当所述流媒体为视频时,所述场景捕捉部通过视频识别软件识别主播用户的视频的文字数据,并在当在时间轨道上所述文字数据出现的时间超过第三阈值时,则将所述文字数据转化为拆分为所述文字数据持续时间内的场景数据;
当所述视频被视频识别软件在相同时间识别出至少两个文字数据时,场景捕捉部将所述至少两个文字数据的最早开始时间和最晚结束时间判定为单位时间,其中所述单位时间应小于第四阈值。
本发明通过上述视频识别软件可将主播用户播放的视频上的字幕、弹幕、文字牌等文字数据及其持续时间识别出,并将其作为场景数据。并且,为了便于切换场景,而合成同一时间出现的多个文字数据的持续时间作为单位时间,从而便于识别同一场景的场景数据。
其中,所述第三阈值可为0.5s~+∞,优选为2s。
其中,所述第四阈值可为3s~20s,优选为10s,其中,当视频识别软件识别出视频带有弹幕时,则可能会使单位时间永远不会停下来,而引发单位时间无限长,场景无法切换,因此,将单位时间配置第四阈值做为上限,而经常切换场景,而使观众用户欣赏到的弹幕适应于不同场景。
其中,所述视频识别软件可以获取视频出现的字幕、弹幕、文字牌等文字信息,并删除乱码文字。其原理可与百度翻译上的识图翻译的原理类似。
作为对本实施例的进一步解释,当观众用户输入的弹幕数据的个数大于所述最大显示个数时,数据补偿部删除弹幕数据的第二数据,所述第二数据的个数等于所述弹幕数据的个数与所述最大显示个数的差,所述第二数据为在所述弹幕数据中的随机的填充词性或随机的任意数据;
当观众用户输入的弹幕数据的个数小于所述最大显示个数时,数据补偿部补偿弹幕数据的第一数据,所述第一数据的个数等于所述最大显示个数与所述弹幕数据的个数的差,所述第一数据为所述弹幕数据中的任意数据的同义词或任意数据的相同的词或随机的填充词性。
本发明通过上述方式可固定屏幕显示的最大的弹幕个数,并保持屏幕上始终保持恒定的最大显示个数,从而让观众用户体会到观看人数的火热,增加用户的兴趣和用户粘性。并且,通过不同的补偿第一数据或删除第二数据的方式可尽可能的添加与场景相符合的词汇或删除无关紧要的词汇,以增加弹幕与场景的符合程度,避免网络不同观点的用户的骂战影响用户体验。
本发明人工智能大数据分析处理系统的处理方法,包括如下步骤:
获取观众用户的在时间轨道上的弹幕数据;
根据主播用户的背景音乐、语音和/或画面而生成在时间轨道上的场景数据;
根据当前时间轨道上的最大同时显示个数和弹幕数据的个数而在弹幕数据上增加第一数据或删除第二数据而使弹幕数据的个数与所述最大显示个数一致;
根据观众用户在所述主播用户的流媒体上发送的在时间轨道上第一预设时间内的弹幕数据的词性而生成第一数据或第二数据。
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案作出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!