一种分布式校园内网搜索系统的制作方法
本发明属于计算机技术领域,涉及一种分布式校园内网搜索系统。
背景技术:
随着目前高校校园网的不断发展,各所高校越来越重视数字化建设,并迅速步入了信息化高速发展的阶段。随着校园网的不断完善,这就要求给广大师生提供一个良好的信息化教学、科研和管理平台。目前,各所高校对数字化校园建设非常重视,如何更全面、更准确地获取最新、最有效的信息已经成为我们把握机遇、迎接挑战和获取成功的重要条件。建设一个优秀的、实用的、符合自身内网信息整合的搜索引擎平台成为一种必然趋势。
目前,通用的搜索引擎,如比较著名的百度、谷歌、搜狐等在web信息检索一块已经做的很完善,但是并不能真正适用校园内部所有的情况和特定需要。通用的搜索引擎平台和校园内网搜索引擎平台在具体校园内部信息检索应用上差别分别在以下几方面:第一方面,通用的搜索引擎检索信息的对象为整个互联网,所以无法保证对校园内网信息全面的进行搜集和提取,并且通用搜索引擎一般采取“定期搜集”,从而导致更新周期过长,而结合学校自身特点,存在各部门信息更新频繁,故通用搜索引擎在针对校内信息搜集实时性和准确性很难得以保证。第二方面,结合学校特点,部分web信息虽然在学校主页上有链接,但必须是校园网内部用户才能访问,如:只允许内网用户访问的内部网络办公系统,只允许内网用户下载的内部文件,内部网站等,由于针对外网用户保密等各方面的原因,受到校园网设置导致通用搜索引擎在进行爬取时无能为力。第三方面,通用搜索引擎大多以商业赢利为主要目的,针对用户的检索,所返回的结果难以到达绝对的公平性。开发本平台,对于用户检索的结果排序我们可以完全自由控制,可以满足实际需要。第四方面,校园网各部门网站大部分和学校主页进行了链接,但有部分内部信息系统、网站往往由于某些原因没有和学校主页进行链接,导致通用搜索引擎在进行原始网页、文件采集时对这部分网站上的信息没收集到,如果实现内部的搜索引擎可对这部分信息进行专门的采集。第五方面,教学科研方面的需要,搜索引擎现在已经成为人们的一项生活内容,市场上对这方面的人才是非常需要的,各大高校先后都开设了这方面的课程。本发明适合校园内部的搜索引擎平台,不仅可以满足功能需要,还可以为教学科研方面服务。
技术实现要素:
本发明的目的是针对现有的技术存在的上述问题,提供一种分布式校园内网搜索系统,本发明所要解决的技术问题是构建一种搜索系统,用于实现网络爬虫子系统、信息预处理子系统、索引器子系统、查询器子系统,可以使得校园网用户检索信息方便、快捷。
本发明的目的可通过下列技术方案来实现:一种分布式校园内网搜索系统,其特征在于,采用java的相关技术,套接字类,url类,中文字符处理,多线程机制,hibernate框架包,hadoop框架,dubbo框架包,struts2框架包,spring框架包,lucene工具包,heritrix框架包,nutch框架包、采用垂直应用架构以及soa服务化架构实现的内网搜索引擎应用;具体而言,本分布式校园内网搜索系统包括四个子系统,分别是:
网络爬虫子系统:对于校内校园网信息的原始收集,能够对所有的静态、动态格式文件能够进行随时、及时、效率更高的爬取,能够对不同格式的文件尽可能的全部下载;
信息预处理子系统:从扩展名为html的网页文件中提取出有用的文本信息,过滤掉广告信息以及导航栏或者网页底部的企业、公司、单位介绍等噪声信息;
索引子系统:能够理解网络爬虫子系统所搜集的各种文档信息,提取相关网页以及文档信息,包括网页和文档所在的url地址、编码格式类型、网页和文档的主要内容、生成时间、文件大小等等,并采用相关度算法进行计算,得到网页和文档针对其内容和超级链接的相关度或重要性等级,然后根据这些信息建立索引并持久化到硬盘;
查询器子系统:获取用户通过浏览器传送过来的输入关键字,对索引库进行检索,匹配查询索引项,并对查询的结果按照重要度进行排序,返回给用户浏览器端。
进一步的,网络爬虫子系统:采用开源项目heritrix对校园网内相关信息资源进行抓取,并可进行灵活的二次开发,不同的功能采用不同的组件进行实现,灵活的修改代码之后可扩展网络爬虫的功能。
抓取任务crawlorder组件crawlorder是整个抓取工作的起点,在一次抓取过程中包含多种属性。
按照规则决定具体的url进入处理队列的范围部件、处理已被搜集或者准备进行搜集的url的边界部件、对于若干处理程序获取的url进行分析,并通知给边界部件的处理器链部件。
所采用的算法特性:在多个站点之间采用递归算法反复进行信息的抓取;对于种子站点主要采用广度优先算法获取二级站点和主机的精确信息;采用多线程的工作方式,线程数量灵活可调,可灵活设置下载的最大字节,文档数量以及下载时间。
信息预处理子系统:提取文档中的文本内容一般分为两类:一种是从html文件中提取纯文本,另一种是从非html文件中提取纯文本。从html文件中提取纯文本需要相关的html内容解析器,从非html中提取纯文本方法比较复杂,其中word、excel、rtf、powerpoint格式都来自于微软公司,可以借助相关的开源项目提取这些文件中的纯文本内容。pdf是adobe公司的电子文件格式,这种文件格式是跨平台的。pdfbox(一个bsd许可下的源码开放项目)是一个为开发人员读取和创建pdf文档而准备的纯java类库。
从html文件中提取纯文本信息采用是目前全球最大开源软件平台(http://sourceforge.net)上非常活跃的一个开源项目htmlparser,本身用java语言编写,用于对html代码进行解析,以及html网页的转换(transformation)和网页内容的抽取(extraction)。htmlparser可以将网页中的各种标签转换成一个个串联的结点,并能从中获取结点的各项属性和信息。目前htmlparser组件相比其它的网页解析组件设计上更加简洁,经过严格的测试表明该组件在程序运行的效率和处理网页的能力等方面也明显由于其它网页解析组件。
对于网页信息在网页中文本内容一般会在<div>、<td>、<title>、<ahref=></a>、<p>等标签中,从html文件中提取纯文本信息就是提取出这些有用的文本信息,保存起来,为本发明建立索引所用。因此,在进行网页预处理器设计时对网页源代码里面的标签首先要进行判别,然后再有选择的进行文本抽取。htmlparser将网页中的各种标签转换成一个个串联的node,node大致有三类:注释节点、标签节点、文本节点。
在本发明中,对相关的数据和操作进行封装;用来封装原始网页处理之后的网页模型类,用来分析处理原始网页,提取有用文本信息的解析器类,保存模型对象于文件中的存储类,为避免处理后的文件重名而进行文件重新命名的md5摘要计算类,以及读取原始网页信息。
由于html的语法没有xml严格,简单使用java基础类中的pattern和match类进行分析实现上难度比较大,htmlparser包一般通过lexer解析、filter解析、visitor解析三种方法对网页源代码进行分析。
索引子系统:索引器是用来完成信息索引的建立、维护和管理功能的软件。它的主要功能:能够理解网络爬虫程序所搜集的各种文档信息,提取相关网页以及文档信息,包括网页和文档所在的url地址、编码格式类型、网页和文档的主要内容、生成时间、文件大小等等,并采用相关度算法进行计算,得到网页和文档针对其内容和超级链接的相关度或重要性等级,然后根据这些信息建立索引并持久化到硬盘。
从20世纪50年代起,对于中文信息处理的相关技术,计算机以及语言学界开始进行了大量的应用研究,相应的产生了一些研究成果以及专利产品。比如:国内的第一个实用的自动分词系统,它由北京航空大学1983年设计的cdws分词系统;中国科学院计算所ictclas,这个分词系统带有词性标注,便于相关科研工作者进行科学以及工程研究;清华大学研制的segtag系统;复旦大学的分词系统;哈工大的统计分词系统;杭州大学改进的mm分词系统;中搜使用的分析系统,由天津市海量科技发展有限公司设计的中文分词系统是首先在商业领域得到广泛应用的系统;由猎兔搜索设计的猎兔中文分词系统。以上中文分词系统大多为专用的中文信息分词处理系统,结合实际需要,本发明采用了比较流行的极易分词组件。如果想实现更加适合自己需求的分词,则需要设计相关的分词程序,并将他们包装成lucene的tokenstream即可,然后根据分词算法中比较常用的正向最大匹配法,设计好相应的词库,应用于lucene开发包中。
查询器子系统:查询器的主要功能,是获取用户通过浏览器端(或者手机客户端、pc客户端)传送过来的输入关键字,对索引库进行检索,匹配查询索引项,并对查询的结果按照重要度进行排序,返回给用户浏览器端。本部分采用struts2框架、spring框架、分布式服务框架dubbo结合lucene工具包采用了分层设计,采用面向接口编程、组件化开发,低耦合设计,可以非常方便扩展视图组件。分层设计目的是为了便于分布式部署,将不同的模块部署于不同的服务器上,通过远程调用协同工作,能够处理一定的并发访问和数据量。
视图层为搜索引擎系统查询器部分的外观表现,是查询器部分与最终用户交互的界面。主要采用手机客户端、浏览器端实现。业务逻辑层完成业务处理逻辑,完成用户在浏览器端发送的查询关键字的接收、获取符合用户查询条件的数据信息。另外还有辅助类,用于处理全角字符和半角字符的转换。数据操作层完成对搜索引擎系统索引器部分所建立索引进行查询操作。数据以document对象返回。
数据层用于存放数据,由lucene工具包创建的索引库构成。
在浏览器端,可以通过浏览器缓存、使用页面压缩、减少cookie传输等手段改善性能,在应用服务器端可以使用服务器本地缓存和分布式缓存,通过缓存在内存中的热点数据处理用户请求,加快请求处理过程。
本系统具有如下优点:
1、采用分布式结构,相比集中式结构所用功能集中部署在一台服务器上,导致系统对服务器硬件性能要求比较高,稳定性,扩展性不高;
2、基于hadoop进行分布式设计,对于爬行、索引、搜索均采用分布式设计。
3、应用map/reduce编程模型思想,把数据计算任务封装到map函数中,数据合并任务封装到reduce函数中。经过以上的改进,搜索引擎系统可以部署在廉价的pc构成的hadoop分布式环境中。
4、查询器子系统采用面向接口编程、组件化开发,低耦合设计,采用strus2框架、spring框架、可以非常方便扩展视图组件。面向接口、分层设计便于分布式部署,将不同的模块部署于不同的服务器上,通过远程调用协同工作。
5、中文分词采用一款采用java技术实现的极易分词程序,提供的功能很多,比如设定分词粒度,正向最大匹配字数、词典可动态规划、词库进行了优化,对lucene开发包全面支持。
6、网页链接签名和去重、网页内容签名和去重都使用md5算法。采用htmlparser开源项目对html网页中的格式、数据进行处理。
本发明解决了以下几个技术问题:
1、网络爬虫子系统:对于校内校园网信息的原始收集,能够对所有的静态、动态格式文件能够进行随时、及时、效率更高的爬取,能够对不同格式的文件(微软word文件、微软excel文件、微软powerpoint文件、rtf、pdf、转换成jpg的文件资料、zip、rar等)尽可能的全部下载。
2、信息预处理子系统:对原始网页预处理和从不同格式的文件(微软word文件、微软excel文件、微软powerpoint文件、rtf、pdf、转换成jpg的文件资料、zip、rar等)中提取有用的纯文本信息进行整合,并且对于网页噪声(过滤掉广告信息以及导航栏或者网页底部的企业、公司介绍)信息的去除。
3、查询器采用面向接口编程、组件化开发,低耦合设计,struts2框架、spring框架、分布式服务框架dubbo可以非常方便扩展视图组件。面向接口、分层设计便于分布式部署,将不同的模块部署于不同的服务器上,通过远程调用协同工作。
4、构建基于hadoop云计算的mapreduce、构建小型分布式存储系统,通过对网络资源的爬行、索引、检索,对系统进行可靠性和扩展性测试、获取实验数据。
5、利于扩展视图组件,可以同时实现手机客户端、pc客户端以及浏览器端。
附图说明
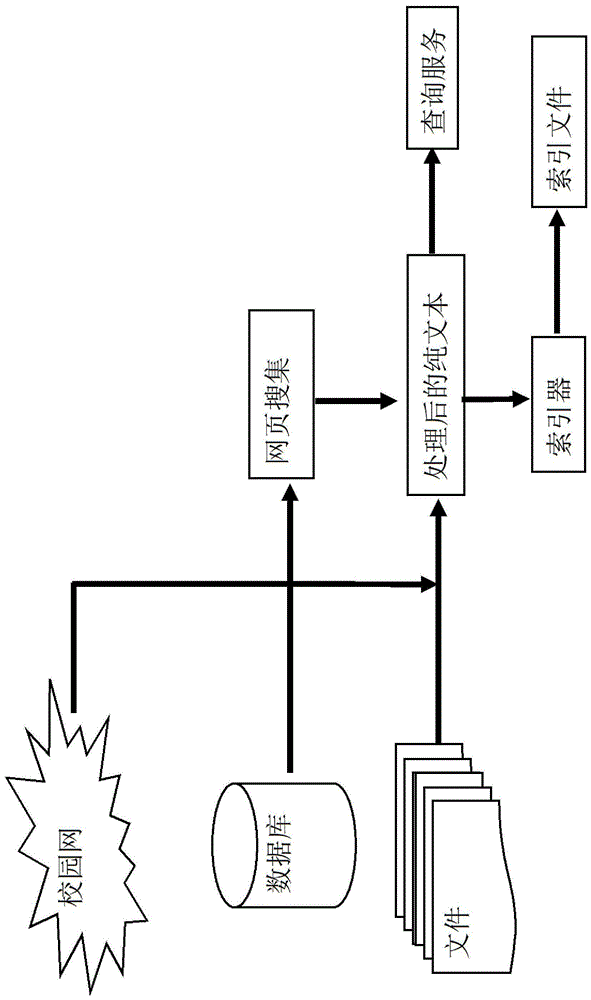
图1是本搜索系统的系统构架图。
图2是网页预处理器功能结构图。
图3是查询器架构图。
具体实施方式
以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
如图1所示,网络爬虫子系统:对于校内校园网信息的原始收集,能够对所有的静态、动态格式文件能够进行随时、及时、效率更高的爬取,能够对不同格式的文件尽可能的全部下载;
信息预处理子系统:从扩展名为html的网页文件中提取出有用的文本信息,过滤掉广告信息以及导航栏或者网页底部的企业、公司、单位介绍等噪声信息;
索引子系统:能够理解网络爬虫子系统所搜集的各种文档信息,提取相关网页以及文档信息,包括网页和文档所在的url地址、编码格式类型、网页和文档的主要内容、生成时间、文件大小等等,并采用相关度算法进行计算,得到网页和文档针对其内容和超级链接的相关度或重要性等级,然后根据这些信息建立索引并持久化到硬盘;
查询器子系统:获取用户通过浏览器传送过来的输入关键字,对索引库进行检索,匹配查询索引项,并对查询的结果按照重要度进行排序,返回给用户浏览器端。
进一步的,网络爬虫子系统:采用开源项目heritrix对校园网内相关信息资源进行抓取,并可进行灵活的二次开发,不同的功能采用不同的组件进行实现,灵活的修改代码之后可扩展网络爬虫的功能。
抓取任务crawlorder组件crawlorder是整个抓取工作的起点,在一次抓取过程中包含多种属性。
按照规则决定具体的url进入处理队列的范围部件、处理已被搜集或者准备进行搜集的url的边界部件、对于若干处理程序获取的url进行分析,并通知给边界部件的处理器链部件。
所采用的算法特性:在多个站点之间采用递归算法反复进行信息的抓取;对于种子站点主要采用广度优先算法获取二级站点和主机的精确信息;采用多线程的工作方式,线程数量灵活可调,可灵活设置下载的最大字节,文档数量以及下载时间。
信息预处理子系统:提取文档中的文本内容一般分为两类:一种是从html文件中提取纯文本,另一种是从非html文件中提取纯文本。从html文件中提取纯文本需要相关的html内容解析器,从非html中提取纯文本方法比较复杂,其中word、excel、rtf、powerpoint格式都来自于微软公司,可以借助相关的开源项目提取这些文件中的纯文本内容。pdf是adobe公司的电子文件格式,这种文件格式是跨平台的。pdfbox(一个bsd许可下的源码开放项目)是一个为开发人员读取和创建pdf文档而准备的纯java类库。
从html文件中提取纯文本信息采用是目前全球最大开源软件平台(http://sourceforge.net)上非常活跃的一个开源项目htmlparser,本身用java语言编写,用于对html代码进行解析,以及html网页的转换(transformation)和网页内容的抽取(extraction)。htmlparser可以将网页中的各种标签转换成一个个串联的结点,并能从中获取结点的各项属性和信息。目前htmlparser组件相比其它的网页解析组件设计上更加简洁,经过严格的测试表明该组件在程序运行的效率和处理网页的能力等方面也明显由于其它网页解析组件。
对于网页信息在网页中文本内容一般会在<div>、<td>、<title>、<ahref=></a>、<p>等标签中,从html文件中提取纯文本信息就是提取出这些有用的文本信息,保存起来,为本发明建立索引所用。因此,如图2所示,在进行网页预处理器设计时对网页源代码里面的标签首先要进行判别,然后再有选择的进行文本抽取。htmlparser将网页中的各种标签转换成一个个串联的node,node大致有三类:注释节点、标签节点、文本节点。
在本发明中,对相关的数据和操作进行封装;用来封装原始网页处理之后的网页模型类,用来分析处理原始网页,提取有用文本信息的解析器类,保存模型对象于文件中的存储类,为避免处理后的文件重名而进行文件重新命名的md5摘要计算类,以及读取原始网页信息。
由于html的语法没有xml严格,简单使用java基础类中的pattern和match类进行分析实现上难度比较大,htmlparser包一般通过lexer解析、filter解析、visitor解析三种方法对网页源代码进行分析。
索引子系统:索引器是用来完成信息索引的建立、维护和管理功能的软件。它的主要功能:能够理解网络爬虫程序所搜集的各种文档信息,提取相关网页以及文档信息,包括网页和文档所在的url地址、编码格式类型、网页和文档的主要内容、生成时间、文件大小等等,并采用相关度算法进行计算,得到网页和文档针对其内容和超级链接的相关度或重要性等级,然后根据这些信息建立索引并持久化到硬盘。
从20世纪50年代起,对于中文信息处理的相关技术,计算机以及语言学界开始进行了大量的应用研究,相应的产生了一些研究成果以及专利产品。比如:国内的第一个实用的自动分词系统,它由北京航空大学1983年设计的cdws分词系统;中国科学院计算所ictclas,这个分词系统带有词性标注,便于相关科研工作者进行科学以及工程研究;清华大学研制的segtag系统;复旦大学的分词系统;哈工大的统计分词系统;杭州大学改进的mm分词系统;中搜使用的分析系统,由天津市海量科技发展有限公司设计的中文分词系统是首先在商业领域得到广泛应用的系统;由猎兔搜索设计的猎兔中文分词系统。以上中文分词系统大多为专用的中文信息分词处理系统,结合实际需要,本发明采用了比较流行的极易分词组件。如果想实现更加适合自己需求的分词,则需要设计相关的分词程序,并将他们包装成lucene的tokenstream即可,然后根据分词算法中比较常用的正向最大匹配法,设计好相应的词库,应用于lucene开发包中。
查询器子系统:查询器的主要功能,是获取用户通过浏览器端(或者手机客户端、pc客户端)传送过来的输入关键字,对索引库进行检索,匹配查询索引项,并对查询的结果按照重要度进行排序,返回给用户浏览器端。本部分采用struts2框架、spring框架、分布式服务框架dubbo结合lucene工具包采用了分层设计,采用面向接口编程、组件化开发,低耦合设计,可以非常方便扩展视图组件。分层设计目的是为了便于分布式部署,将不同的模块部署于不同的服务器上,通过远程调用协同工作,能够处理一定的并发访问和数据量。
如图3所示,视图层为搜索引擎系统查询器部分的外观表现,是查询器部分与最终用户交互的界面。主要采用手机客户端、浏览器端实现。业务逻辑层完成业务处理逻辑,完成用户在浏览器端发送的查询关键字的接收、获取符合用户查询条件的数据信息。另外还有辅助类,用于处理全角字符和半角字符的转换。数据操作层完成对搜索引擎系统索引器部分所建立索引进行查询操作。数据以document对象返回。
数据层用于存放数据,由lucene工具包创建的索引库构成。
在浏览器端,可以通过浏览器缓存、使用页面压缩、减少cookie传输等手段改善性能,在应用服务器端可以使用服务器本地缓存和分布式缓存,通过缓存在内存中的热点数据处理用户请求,加快请求处理过程。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!