一种基于目标检测与动作识别的多目标视觉监管方法与流程
本发明涉及人工智能技术领域,尤其涉及一种基于目标检测与动作识别的多目标视觉监管方法。
背景技术:
近年来,随着计算机图像处理技术以及传感器技术的发展,目标检测与人体行为识别成为了机器视觉领域一个热门的研究方向,在人机交互、智能监控和虚拟现实等领域中应用得越来越广泛,其中视频监控的智能化已成为社会发展的必然趋势,智能监控能够对视频中的异常行为和图像中的关键目标进行实时识别和检测,并及时发出预警,彻底改变了传统监控只能“监”不能“控”的被动状态,这将是视频监控行业以及安防行业的一次新的革命。现阶段,我国越来越多的技术型企业正在大力发展数字信号处理、视频分析算法等核心技术。
随着社会基础设施建设的大力发展,工程建设项目逐渐遍布于城市和乡村,尤其是大型工地的数目明显增多。大型工地属环境恶劣、事故多发的区域,其中出入的人员和车辆情况复杂,在疏于管理的情况下容易产生安全隐患,因此,需对大型工地出入的人员进行有效监管,实时监控工人工作情况并及时发现安全隐患,能防止和减少人员在作业过程中遭坠落物砸伤或自坠落时头部受到的伤患行为。大型工地中施工人员受到伤害的概率较大,安全帽是一种十分有效的防护设备,因此大型工地施工人员必须佩戴安全帽。然而,在很多情况下由于各种原因总会有一些人员未佩戴安全帽进入工地,产生较大安全隐患,因此对施工现场人员佩戴安全帽情况进行监管有重要意义,而且工人在工地内随时都有可能出现各种危险情况比如摔倒等。目前,传统的研究工人安全帽和制服的检测和工人异常动作的识别绝大多数是相互独立的。
技术实现要素:
根据现有技术存在的问题,本发明公开了一种基于目标检测与动作识别的多目标视觉监管方法,包括以下步骤:
s1:采集工人穿戴制服和安全帽的图像,数据增强后构成第一数据集;
s2:采用第一数据集对yolov3-mobilenetv3网络进行训练,得到yolov3-mobilenetv3目标检测模型;
s3:搭建tfpose人体骨架信息提取模型采集工人打电话和摔倒动作的骨架数据,构成第二数据集;
s4:采用第二数据集对indrnn网络进行训练,得到indrnn动作识别模型;
s5:利用deepsort多目标追踪算法对工人正在进行工作的图像进行追踪检测,检测识别每个工人,分割出每个工人图像,并为其分配固定id;
s6:摄像头根据图像中工人的位置与该图像中心位置的偏差,自动调节云台的角度位置,再根据工人在图像中所占整张图像的比例大小,自动调节焦距;
s7:yolov3-mobilenetv3目标检测模型检测分割出的工人图像,得到每个工人的安全帽和制服的穿戴情况;
tfpose人体骨架信息提取模型提取分割出的工人图像的人体关键点,并转换成人体向量数据输入到indrnn动作识别模型,识别每个工人的动作异常情况。
进一步地,所述采集工人穿戴制服和安全帽的图像,数据增强后构成第一数据集;包括以下步骤:
s1-1:采集不同工人穿戴制服和安全帽的图像,将图像中有工人的前景图像与没有工人的背景图像分离;
s1-2:单独采集某一定数量的不同工作情形的背景图像;
s1-3:将分离出的工人的前景图像与采集到的不同工作背景进行图像融合,并让工人的前景图像在背景图像范围内有规律的进行移动,生成合成图像;
s1-4:将合成图像与采集的不同工人穿戴制服和安全帽的图像构成第一数据集,所述第一数据集经过标记工作生成类别位置标签,并划分训练集和测试集。
进一步地,所述indrnn动作识别模型包括数据增强模块、特征提取模块和行为检测模块;
所述数据增强模块对tfpose人体骨架信息提取模型的关节点坐标进行处理,取18个人体关键点坐标按两两组合生成17个人体向量数据,将人体关键点的数据转换成人体向量数据,将数据增强后的数据传给所述特征提取模块;
所述特征提取模块接收数据增强模块输入的人体向量数据,通过深度网络自动学习出打电话和摔倒的行为相关的时序特征并传送给所述行为检测模块;
所述行为检测模块将特征提取模块输出的特征进行加权融合,识别每个工人的动作异常情况。
进一步地,所述特征提取模块包括六个网络块;所述网络块依次顺序连接;
所述网络块包括fc全连接层、indrnn层、bn层和dp遗忘层;
所述fc全连接层、所述indrnn层、所述bn层和所述dp遗忘层依次顺序连接。
进一步地,所述利用deepsort多目标追踪算法对工人正在进行工作的图像进行追踪检测,检测识别每个工人,分割出每个工人图像的具体方式如下:
所述deepsort多目标追踪算法采用tfpose作为检测器,利用tfpose人体骨架信息提取模型得到图像中每个工人的骨骼坐标,对工人的骨骼信息进行处理得到每个工人骨骼在x和y坐标下的最大值和最小值,即得到图像中工人的具体位置。
进一步地,所述yolov3-mobilenetv3目标检测模型检测分割出的工人图像,得到每个工人的安全帽和制服的穿戴情况,其中制服的穿戴情况判断方法如下:
s7-1:当目标检测模型检测并框出工人的制服区域;
s7-2:在该区域内随机选取n个点,通过hsv颜色检测方法,检测该n个点的hsv值与实际制服的颜色比较,当n个点的颜色值正确率达到一定阈值则断定该工人穿有制服。
进一步地,所述hsv颜色检测方法的判断模型如下:
式(4)中xhmin、xhmax分别为真实制服的hsv颜色中色调h的最小与最大值,xsmin、xsmax分别为真实制服的hsv颜色中饱和度s的最小与最大值,xvmin、xvmax分别为真实制服的hsv颜色中明度v的最小与最大值,bhi、bsi、bvi分别为n点中的某一点的hsv颜色值。
进一步地,所述yolov3-mobilenetv3目标检测模型检测分割出的工人图像,得到每个工人的安全帽和制服的穿戴情况,其中安全帽的穿戴情况的判断方法如下:
当检测到安全帽位置在人体头部关键点坐标值区域,则判断工人戴了安全帽;
当检测到安全帽位置不在人体头部关键点坐标值区域,则判断工人没有戴安全帽。
进一步地,所述调节焦距的方法如下:
当工人图像占整张图像的比例小于阈值m时,则调大焦距;
当工人图像占整张图像的比例大于阈值m时,则调小焦距;
当工人图像占整张图像的比例等于阈值m时,则进行图像采集。
由于采用了上述技术方案,本发明提供的一种基于目标检测与动作识别的多目标视觉监管方法,具体内容包括对工人穿戴安全帽与制服情况的监管和工人实时动作的识别两个部分,而且方法中更是应用了网络大变焦摄像头能够根据工人的检测情况实时调节云台角度与摄像头焦距,使目标检测和动作识别算法更加准确,使用了deepsort算法能够对每个工人实时追踪检测,更方便对工人进行视觉管理。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
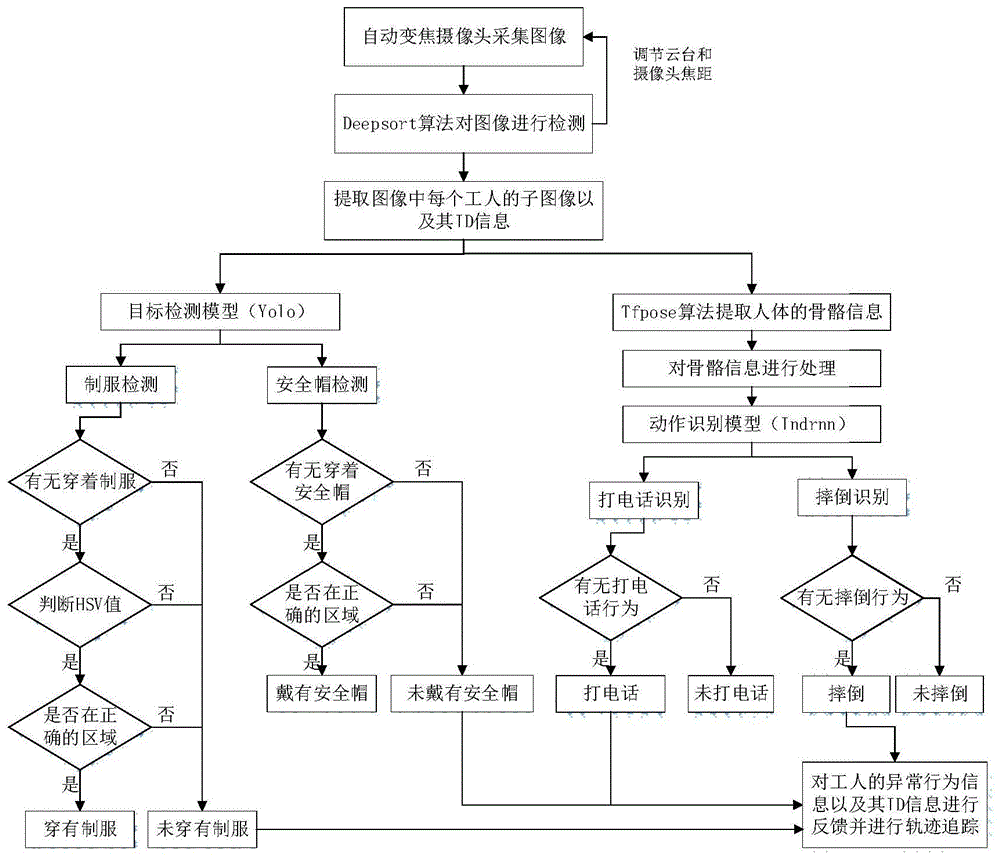
图1是本发明基于目标检测与动作识别的多目标视觉监管方法的总体流程图;
图2(a)是本发明采用的网络大变焦摄像头;
图2(b)是本发明采用的云台;
图3是本发明采用的deepsort算法的检测效果图;
图4是本发明采用的基于indrnn模型的深度网络结构图;
图5是本发明采用的tfpose网络模型提取人体关键点以及人体向量的示意图;
图6是本发明实现的安全帽的检测效果图;
图7是本发明实现的制服的检测效果图;
图8是本发明实现的打电话动作的识别效果图;
图9是本发明实现的摔倒动作的识别效果图。
具体实施方式
为使本发明的技术方案和优点更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述:
图1为本发明提供的基于目标检测与动作识别的多目标视觉监管方法的总体流程图,包括以下步骤:
s1:采集工人穿戴制服和安全帽的图像,数据增强后构成第一数据集;
s2:采用第一数据集对yolov3-mobilenetv3网络进行训练,得到yolov3-mobilenetv3目标检测模型;
s3:搭建tfpose人体骨架信息提取模型采集工人打电话和摔倒动作的骨架序列信息,构成第二数据集;
s4:对第二数据集对indrnn网络进行训练,数据增强后得到indrnn动作识别模型;
s5:使用网络大变焦摄像头对工人进行监管,利用deepsort多目标追踪算法对工人正在进行工作的图像进行追踪检测,检测识别每个工人,分割出个工人图像并为其分配固定id;
s6:摄像头根据图像中工人的位置与该图像中心位置的偏差,自动调节云台的角度位置,再根据工人在图像中所占整张图像的比例大小,自动调节焦距;
s7:yolov3-mobilenetv3目标检测模型检测分割出的工人图像,得到每个工人的安全帽和制服的穿戴情况;
所述tfpose人体骨架信息提取模型提取分割出的工人图像的人体关键点,并转换成人体向量数据输入到indrnn动作识别模型,识别每个工人的动作异常情况。
进一步地,所述采集工人穿戴制服和安全帽的图像,数据增强后构成第一数据集;包括以下步骤:
s1-1:采集n幅不同工人穿戴制服和安全帽的图像,将图像中有工人的前景图像与没有工人的背景图像分离;
s1-2:单独采集某一定数量的不同工作情形的背景图像,此过程中要避免采集到的其他工人,而且为了提高训练的准确性需要采取一天中不同时间段的图像,不同的时间光线情况不同对准确性会有影响;
s1-3:利用opencv(计算机视觉库)编写程序将分离出的工人的前景图像与采集到的不同工作背景进行图像融合,并让工人的前景图像在背景图像范围内有规律的进行移动,生成更多的合成图像;
s1-4:将合成图像与采集的不同工人穿戴制服和安全帽的图像构成第一数据集,所述第一数据集经过标记工作生成类别位置标签,并划分训练集和测试集。
本发明采用的yolov3-mobilenetv3目标检测模型将mobilenetv3网络作为主体网络替换yolov3中的darknet53网络,对于一张指定的输入图像,首先通过mobilenetv3基础网络进行特征的提取,然后采用多尺度预测的方法,分别在大小为13×13、26×26、52×52的特征图上进行预测。在不同尺度的特征图上继续进行卷积操作,通过上采样层与前一层得到的特征图进行张量的拼接,再经过卷积操作之后,在不同特征图上进行目标检测和位置回归,最后通过yolov3检测层进行坐标和类别结果的输出。多尺度预测和特征融合提高了小目标的识别能力,从而提升整个网络的性能,
mobilenetv3网络主要利用分组卷积和点卷积替换了原来标准卷积,可以极大的消减主体网络中卷积运算的部分,使得网络的整体计算量大大减少,虽然精度上有所降低,但是该算法达到的精度已经满足本文需要而且最重要的是该算法可以大大地提高检测速度。
图2(a)是本发明采用的网络大变焦摄像头,图2(b)是本发明采用的云台;
由于在实际环境中工人距摄像头的距离会很远,这样目标检测与动作识别算法的准确性会降低,所以使用自动变焦摄像头对工人进行监管,利用多目标追踪算法(deepsort)对图像中的工人进行追踪检测,该算法会框出图像中的每个工人并为每个工人分配一个固定的id,再将模型检测出的每个工人图像以及其id信息分别传入目标检测与动作识别模型中进行检测,同时摄像头会根据deepsort算法检测的目标与视野中心图像的偏差自动调节云台的角度位置,再根据工人在图像中所占整张图像的比例大小,自动调节焦距,以便于对工人的目标检测与动作识别。
进一步地,所述再根据工人距摄像头的距离调节焦距的方式如下:
根据工人图像占整张图像的比例,自动调节焦距,具体方法是:设置一个阈值,当工人图像占整张图像的比例小于阈值时,说明工人距离摄像头较远,此时调大焦距,使工人图像变得更加清晰,便于之后的目标检测与动作识别,当工人图像占整张图像的比例大于阈值m时,则调小焦距,当工人图像占整张图像的比例等于阈值m时,则进行图像采集。
图3是本发明采用的deepsort算法的检测效果图;所述deepsort多目标追踪算法基本思想是tracking-by-detection,算法首先要对每一帧图像进行目标检测,后续通过带权值的匈牙利匹配算法对之前的运动轨迹和当前检测对象进行匹配,形成物体的运动轨迹进而对目标进行追踪,权值由点和运动轨迹的马氏距离及图像块的相似性(这里用向量的余弦距离)加权求和得到,kalman滤波在计算马氏距离时,用于预测运动分布的协方差矩阵。因此该算法需要一个检测器来担任目标检测的任务,本发明采用tfpose作为检测器,利用tfpose人体骨架信息提取模型可以得到图像中每个工人的骨骼坐标,对工人的骨骼信息进行处理得到每个工人骨骼在x和y坐标下的最大最小值(xmin,xmax,ymin,ymax)这样就可以得到图像中工人的具体位置。
图4是本发明采用的动作识别网络图,其中所述特征提取模块包括六个网络块;所述网络块依次顺序连接;
所述网络块包括fc全连接层、indrnn层、bn层和dp遗忘层;
所述fc全连接层、所述indrnn层、所述bn层和所述dp遗忘层依次顺序连接。
特征提取模块的主干由六层全连接层和indrnn层组成,并在每层之后加入bn层与遗忘层(简称dp),bn层可以在训练模型时使梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度,dp层可以防止发生过拟合。随着网络层数的增加,能够自动从骨骼的低层次特征学习到与跌倒和打电话动作相关的高层次特征,随着网络层数的增加,能够自动从骨骼的低层次特征学习到与跌倒和打电话动作相关的高层次特征,行为检测模块使用全连接层(简称fc)和归一化指数函数(softmax)对动作序列进行分类。对于样本x,网络将其识别为动作y的概率为:
z=wx+b(2)
式中,c为动作种类数,w、b和z分别是全连接层的权重矩阵、偏置矩阵和输出。
图5是本发明采用的tfpose网络模型提取人体关键点以及人体向量的示意图,其中:鼻子-0,脖子-1,右肩-2,右肘-3,右手腕-4,左肩-5,左肘-6,左手腕-7,右髋-8,右膝盖-9,右脚踝-10,左髋-11,左膝盖-12,左脚踝-13,右眼-14,左眼-15,右耳-16,左耳-17;
tfpose人体骨架信息提取模型,能够对于每帧图像的每个人物,提取其18个关节点的二维坐标,通过tfpose人体骨架信息提取模型多次连续采集20帧工人打电话以及摔倒动作的关节点坐标,作为数据集2,并划分训练集和测试集。利用搭建的动作识别网络进行训练,该网络由三个模块组成:数据增强模块、特征提取模块和行为检测模块。
所述数据增强模块对tfpose人体骨架信息提取模型的关节点坐标进行处理,取18个人体关键点坐标按两两组合生成17个人体向量数据,将人体关键点的数据转换成人体向量数据进行训练,以提高网络的鲁棒性;将数据增强后的数据传给所述特征提取模块;
所述特征提取模块接收数据增强模块输入的人体向量数据,通过深度网络自动学习出打电话和摔倒的行为相关的时序特征并传送给所述行为检测模块;
所述行为检测模块将特征提取模块输出的特征进行加权融合,提高识别准确率,识别出每个工人的动作异常情况。
所用17个人体向量数据转换公式为:
an=(xj-xi,yj-yi)(3)
式中,a为人体向量,n为向量的序号,i与j为对应的两个人体关键点xi、yi与xj、yj为其坐标。
进一步地,针对工人制服的目标识别,通过颜色判断条件来提高检测的准确性,具体方法是当目标检测模型检测并框出工人的制服区域,在该区域内随机选取n个点,通过hsv颜色检测方法,检测该n个点的hsv值与实际制服的颜色比较,当n个点的颜色值正确率达到一定阈值则断定该工人穿有制服。具体的过程是:
式中xhmin、xhmax分别为真实制服的hsv颜色中色调h的最小与最大值,xsmin、xsmax分别为真实制服的hsv颜色中饱和度s的最小与最大值,xvmin、xvmax分别为真实制服的hsv颜色中明度v的最小与最大值,
骨架信息与目标检测结合作为判断条件,当目标检测模型检测出工人的安全帽以及制服,但是可能存在工人并没有正常穿戴,而是手拿等情况,通过骨架信息作为判断条件,检测安全帽位置是否在人体头部关键点坐标值区域,即当检测到安全帽位置在人体头部关键点坐标值区域,则判断工人戴了安全帽,当检测到安全帽位置不在人体头部关键点坐标值区域,则判断工人没有戴安全帽;
图6是本发明实现的安全帽的检测效果;
图7是本发明实现的制服的检测效果;
图8是本发明实现的打电话动作的识别效果;
图9是本发明实现的摔倒动作的识别效果。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!