基于自然语言的适航指令问题特征的提取的制作方法
本发明涉及适航审定技术领域,具体的讲是基于自然语言的适航指令问题特征的提取。
背景技术:
在航空器运行全生命周期过程中提取影响安全的设计特征和安全趋势也是适航审查活动的主要开展方式,即适航审定的“监听模式”。监听模式的典型应用是针对设计、制造和使用过程中记录和上报的各类微小偏离和不安全信息。通常情况下,航空器设计、制造和使用环节中会累积大量关于各种偏离和更改的描述信息。这些信息来源、用途以及描述方式各不相同,其中所包含的航空器不安全设计特征往往也并不明显。在数据规模较大的情况下,审查人员无法人工发现和定位与当前活动真正有价值的适航参考信息,从而造成大量有价值的适航辅助信息无法在审查工作中给予审查人员足够的信息支撑。在这种监听模式下,如果能充分利用现有的自然语言处理技术,将相关信息中的不安全特征进行自动提取和推送将极大的改善信息平台中不同业务单元间信息的共享效率。为此设计一种基于自然语言的适航指令问题特征的提取方法是十分有必要的。
技术实现要素:
本发明突破了现有技术的难题,设计了一种基于自然语言的适航指令问题特征的提取方法,能有效的发现不同航空器设计特征和风险因素,具有更高的准确性,在时间消耗方面也比现有的对比方法有更好的表现。
为了达到上述目的,本发明设计了基于自然语言的适航指令问题特征的提取方法,其特征在于:按如下步骤进行提取:
s1提取适航指令背后的问题描述章节,进行文本数据预处理;
s2检测重叠句簇;
s3选择给定数量的句簇
s4提取特征描述符。
进一步的,s1中所述的文本数据预处理为:过滤文本中的噪声描述与单词,然后使用nltk(自然语言处理工具包)进行自然语言处理,并获得一个句子列表,该句子列表由tf-idf(termfrequency–inversedocumentfrequency,是一种用于信息检索与数据挖掘的常用加权技术)向量形式的所有句子组成。
进一步的,s2所述的检测重叠句簇的具体步骤为:
s21建立句子相似性网络;
s22选择种子;
s23判断是否找到种子,是,则进入下一步,否,则确定该句子为重叠句簇;
s24发现句簇成员;
s25识别句簇的关键词;
s26更新句子相似性网络,重新进入s21步骤,直到所有的句子都确认为重叠句簇。
进一步的,s3所述的选择给定数量的句簇的具体方法为:按簇大小和簇关键字的平均权重将所发现的句簇进行重新拍列。
进一步的,使用nltk进行自然语言处理的具体方法为:
(7)句子提取:将产品描述中的各个句子分离;
(8)词汇切分:将句子分割为单词;
(9)词性标注:识别各个单词的词性;
(10)单词选择:只保留动词、名词和形容词;
(11)删除停用词:删除常用的一些不具有特定含义的单词;
(12)词干化:将单词转化词根形式。
进一步的,由tf-idf向量形式形成的句子列表的方式为:将一个类别内的所有文本表述的句子集合为一个文档,使用tf-idf方法计算集合中每个单词的权重,将一个类别内文本描述的所有句子转变为向量,将所有句子向量根据公式
进一步的,建立句子相似性网络的方法为:利用节点之间边的权重来度量句子之间的相似性,利用相似性计算公式获得句子之间的相似性结果,建立句子相似性网络.
进一步的,选择种子的具体方法为:选择当前与权值最大、且权值大于阈值的边相连的节点作为种子。
进一步的,发现句簇成员的具体方法为:将选择的种子作为新簇的初始质心,然后重叠句簇的发现算法开始迭代考察新簇的每个邻居节点是否可以作为当前句簇的成员;
其中邻居是指相似性网络中的节点,这些节点与当前句簇中的节点有连接。
进一步的,识别句簇的关键词的具体方法为:采用sklearn包中的k-均值算法将簇质心向量中权重大于0的单词分为两组,然后选取平均权重大的一组单词作为关键词。
进一步的,选择给定数量的句簇的具体方法为:计算每个重叠句簇的权重,对各个句簇进行排序;其中计算公式为:
进一步的,提取特征描述符的具体方法为:基于wordnet合并同义词,根据同义词的频率对双词短语进行排序,最后将最频繁的双词短语作为表述特征的描述符。
本发明还设计了基于自然语言的适航指令问题体征提取系统,其特征在于:所述系统包括:数据获取单元,用于获取适航指令的文本信息;
数据处理单元,用于对获取的文本信息进行特征提取处理。
本发明还设计了一种适航指令问题特征提取装置,其特征在于:包括处理器;
用于存储处理器可执行指令的存储器;
其中,处理器被配置为:执行如下方法:首先在文本描述的句子中检测(detect)所有潜在的重叠句簇,然后对发现的句簇进行排序并选择(select)给定数量的句簇,最后从选定的句簇中提取(extract)双词短语作为特征描述。
第一步是过滤文本中的噪声描述和单词,并获得一个句子列表,该句子列表由tf-idf向量形式的所有句子组成。由于文本描述中的一个句子可以描述多于一个特征,所以表示各个特征的句簇之间可能彼此重叠。
第二个步骤开始寻找簇的种子,然后贪婪地检测簇成员。一旦获得了一个句簇,就从句子列表中删除接近簇质心的语句,因为这些句子确定属于这个句簇,而不是任何其他的句簇。这也意味着簇中的其他句子在进一步的检测过程中可以分配给其他的句簇。同时,识别当前句簇的关键词,并从句子列表中的所有剩余句子中删除这些关键字,所识别的簇关键词将被进一步用于选择句簇和提取双词短语。
第三步在选择句簇过程中,按簇大小和簇关键字的平均权重将所发现的句簇进行排序。簇的大小反映了所表示特征的频率,簇关键字的平均权重反映了特征的重要性。在特征描述符提取过程中,将包含簇关键字的最频繁的双词短语选作为特征描述符。
本发明还设计了一种计算机存储介质,其上存储有计算机程序指令,其特征在于:所述计算机程序指令被处理器执行时实现如下方法:首先在文本描述的句子中检测(detect)所有潜在的重叠句簇,然后对发现的句簇进行排序并选择(select)给定数量的句簇,最后从选定的句簇中提取(extract)双词短语作为特征描述。
第一步是过滤文本中的噪声描述和单词,并获得一个句子列表,该句子列表由tf-idf向量形式的所有句子组成。由于文本描述中的一个句子可以描述多于一个特征,所以表示各个特征的句簇之间可能彼此重叠。
第二个步骤开始寻找簇的种子,然后贪婪地检测簇成员。一旦获得了一个句簇,就从句子列表中删除接近簇质心的语句,因为这些句子确定属于这个句簇,而不是任何其他的句簇。这也意味着簇中的其他句子在进一步的检测过程中可以分配给其他的句簇。同时,识别当前句簇的关键词,并从句子列表中的所有剩余句子中删除这些关键字,所识别的簇关键词将被进一步用于选择句簇和提取双词短语。
第三步在选择句簇过程中,按簇大小和簇关键字的平均权重将所发现的句簇进行排序。簇的大小反映了所表示特征的频率,簇关键字的平均权重反映了特征的重要性。在特征描述符提取过程中,将包含簇关键字的最频繁的双词短语选作为特征描述符。
本发明与现有技术相比,提出了一种从自然语言文本中提取文本特征的方法,通过检测重叠句簇来提取特征和直接从文本描述中选择短语来提取特征的方法具有更高的准确性,同时,在时间消耗方面也比现有技术选择的对比方法有更好的表现,在实际针对适航指令的特征提取中也能够发现适航指令文本所表达的航空器产品的关键设计特征。
附图说明
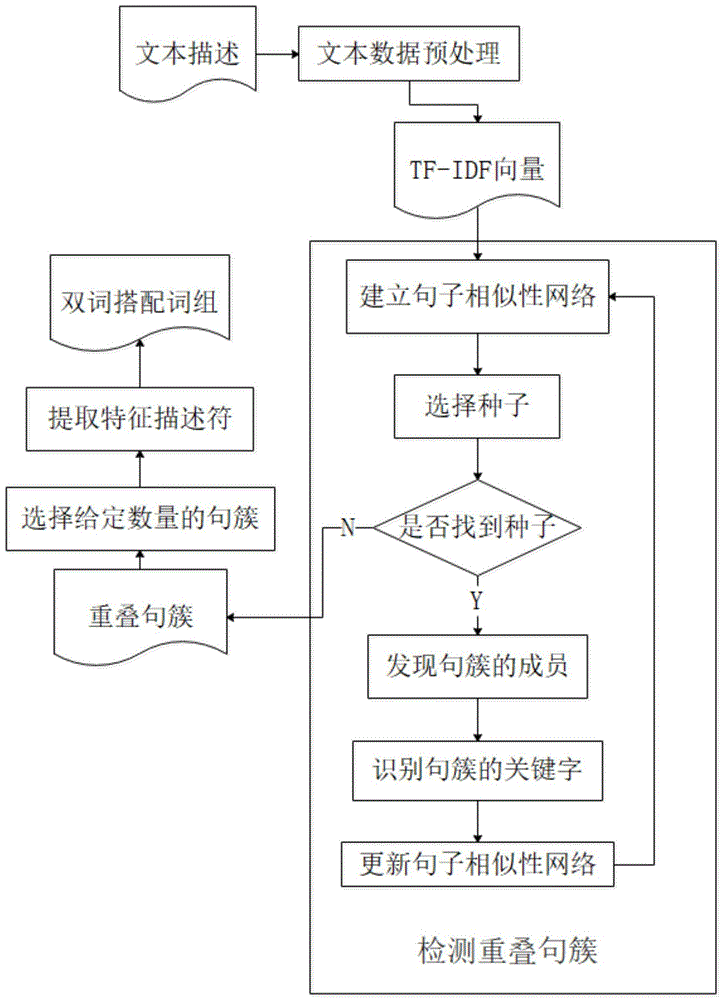
图1为在一具体实施例中基于自然语言的适航指令问题特征的提取方法的流程示意图。
图2为在一具体实施例中基于自然语言的适航指令问题特征的提取方法中最小值参数min和最大值参数max之间的关系。
图3为在一具体实施例中基于自然语言的适航指令问题特征的提取方法与现有技术的精度对比图。
图4为在一具体实施例中基于自然语言的适航指令问题特征的提取方法与现有技术的时间消耗对比图。
图5为在一具体实施例中基于自然语言的适航指令问题特征的提取方法与现有技术的删除最频繁和不频繁词的准确度对比图。
图6为在一具体实施例中基于自然语言的适航指令问题特征的提取方法从softpedia.com抓取的软件文本描述样本图。
具体实施方式
下面结合附图对本发明作进一步描述,但不作为对本发明的限定。
本发明提出了基于自然语言的适航指令问题特征的提取方法,首先在文本描述的句子中检测(detect)所有潜在的重叠句簇,然后对发现的句簇进行排序并选择(select)给定数量的句簇,最后从选定的句簇中提取(extract)双词短语作为特征描述。
一般情况下,社区检测的目标是从一个复杂的网络中检测节点簇,这些节点簇可以相互重叠。为了发现重叠的社区,lmf(localmaximaoffitness,社区检测算法)从不同的种子开始,以贪婪方式探测每个社区的成员。这些种子是随机选择的还未分配给任何社区节点。从一个选定的种子开始,lmf通过最大化社区内节点的适应度来检测一个新的社区。
适应度的计算方式如下:
根据适应度的定义,lmf从种子开始,迭代地访问社区的邻居节点,并通过计算当增加和不增加该邻居节点时社区适应度的变化来计算每个邻居节点对社区适应度的贡献,然后选择最大贡献的邻居并将其添加到社区中。在此之后,由于新节点的加入社区内已存在的节点对社区的适应度的贡献可能为负值,因此lmf在新节点加入社区之后会再次计算该社区中已经存在的节点对社区适应度的贡献,并移除失配节点。当所有邻居的贡献为负时,这种迭代停止,此时检测到了一个新的社区。对于给定α,这个过程最大化了适应度函数值。
参见图1,本发明提出的基于自然语言的适航指令问题特征的提取方法,主要由四个步骤组成:
s1提取适航指令背后的问题描述章节,进行文本数据预处理;
s2检测重叠句簇;
s3选择给定数量的句簇
s4提取特征描述符。
优选的,s1中所述的文本数据预处理为:过滤文本中的噪声描述与单词,即对冗余描述和空描述进行过滤,然后使用nltk进行自然语言处理,并获得一个句子列表,该句子列表由tf-idf向量形式的所有句子组成。
其中,进行自然语言处理的具体方法为:
(1)句子提取:将产品描述中的各个句子分离;
(2)词汇切分:将句子分割为单词;
(3)词性标注:识别各个单词的词性;
(4)单词选择:只保留动词、名词和形容词;
(5)删除停用词:删除常用的一些不具有特定含义的单词;
(6)词干化:将单词转化词根形式。
最后,将一个类别内的所有文本描述的句子集合作为一个文档,使用tf-idf方法计算集合中每个单词的权重,将一个类别内文本描述的所有句子转变为向量,设x是其中的一个向量,x=[x1,x2,……,xn],将所有句子向量根据公式
由于文本描述中的一个句子可以描述多于一个特征,所以表示各个特征的句簇之间可能彼此重叠,为此设计了第二步,即对重叠句簇的检测。
而lmf应用于非加权网络,也不能有效的处理文本描述中的噪声数据,所以不能直接用于检测文本的重叠句簇,因此在具体实施例中设计了重叠句簇发现算法,参见表1。
表1重叠句簇发现算法
结合表1与图1,优选的,重叠句簇的检测步骤为:
s21建立句子相似性网络;
s22选择种子;
s23判断是否找到种子,是,则进入下一步,否,则确定该句子为重叠句簇;
s24发现句簇成员;
s25识别句簇的关键词;
s26更新句子相似性网络,重新进入s21步骤,直到所有的句子都确认为重叠句簇。
优选的,建立句子相似性网络有助于发现用于检测句簇的种子,在该网络中,节点是用tf-idf向量表示的句子,节点之间边的权重是它们之间的相似性。在具体实施例中,使用余弦相似度来度量句子之间的相似性。
设x和y是两个向量,其中x=[x1,x2,……,xn],y=[y1,y2,……,yn],则x和y之间的余弦相似性计算参见公式:
选择种子是lmf算法检测社区的起点。为了发现重叠句簇,选择当前与权值最大、且权值大于阈值(即表1中的参数min)的边相连的节点作为种子,因为连接他们的边权重最大说明这两个句子更有可能划分到同一个句簇。
但是,建立句子相似度网络需要花费一些计算资源。该种子节点的选取过程还可以在种子选择上减少噪声数据影响。在相似性网络中噪声数据要么是孤立的,要么是它们与其他节点连接的权重很小。在这种情况下,它们一般不太可能被选为种子。
此外,种子节点只能从还未被分配给任何句簇的句子集合中选择。当没有候选者被选中,或者所有的剩余句子都不适合选择时,种子的选择就会失败,即这些句子之间边的权重都小于参数min,整个重叠句簇检测过程(即表1的算法)将停止。
优选的,发现句簇成员的具体方法为:将选择的种子作为新簇的初始质心,然后重叠句簇的发现算法开始迭代考察新簇的每个邻居节点是否可以作为当前句簇的成员;
其中邻居是指相似性网络中的节点,这些节点与当前句簇中的节点有连接。
在一次迭代中,如果邻居存在,则选择离簇质心最近的邻居。如果该邻居与簇质心之间的余弦相似度大于阈值(即表1中的参数min),则将该邻居节点添加到簇中。一旦找到簇的新成员,就会重新计算当前句簇的质心。之后,下一次迭代将继续找到新簇的更多成员。当没有邻居节点,或者所有邻居节点都远离簇质心时,算法就停止发现新的句簇成员。
优选的,因为文本描述中的一个句子可能描述多个特征,识别簇关键字的目的是从句子中删除一个已识别的特征,并分离重叠特征,识别句簇的关键词的具体方法为:采用sklearn包中的k-均值算法将簇质心向量中权重大于0的单词分为两组,然后选取平均权重大的一组单词作为关键词。这使得簇关键字的识别能够与簇质心中单词权重的分布相适应。
一旦识别出新的句簇及其簇关键字,将进一步更新句子集合和相似性网络。首先,如图2所示,这些接近簇质心的成员,即与簇质心的余弦相似度大于阈值(即参数max)的成员,将从用于进一步发现句簇的句子集合中删除。这些成员是确定地属于当前句簇,所以不应分配给其他簇。换句话说,在进一步的句簇检测过程中,与簇质心的余弦相似度在(min,max)范围的成员均可以分配给其他簇。
如图2中,图中由红色节点表示的句子是可以分配给其他簇成员的。这也意味着,如果参数max与min相等,那么所有簇成员都将被删除,所有检测到的簇都将没有重叠。同时,当参数max等于1时,则不会删除任何成员。
第二,从未确定地分配给某些簇的句子中,删除当前句簇的关键字,以减少它们对进一步聚类检测的影响。
第三,由于删除簇关键字后,包含簇关键字的句子也会改变,句子相似性网络也将随后被更新。
根据表1所示的算法,我们将从一个类别内的所有文本描述中得到一个重叠句簇的集合。每个重叠句簇代表了不同的文本特征。实际中分析人员可能只对检测到的特征中的一部分感兴趣,例如,前10名的特征而不是所有这些特征。在这种情况下,我们对检测到的簇进行排序,并根据排序结果返回给定数量的簇。
优选的,需要计算每个重叠句簇的权重,对各个句簇进行排序;其中计算公式为:
进一步的,s3所述的选择给定数量的句簇的具体方法为:按簇大小和簇关键字的平均权重将所发现的句簇进行重新排列。
簇大小反映簇所表示的特征的频率或支持度。簇关键字的平均权重反映了表示特征的重要性。通过考虑到簇关键字的平均权重,可以提高不频繁但重要的特征在排序中的位置。
对于每个检测到的句簇,最接近质心的语句通常被用作表示特征的描述符。但事实上,当选择的句子有许多单词时,按照这种方式所选择的特征并不容易理解。因此本发明从句簇的句子中提取双词短语作为特征描述符。
如果将双词短语提取为特征描述符,则提取的双词短语应包含簇的关键字。在这种情况下,提取包含簇关键字的双词短语(在5个单词距离以内)来作为特征描述符,这可以避免产生大量的双词短语,但仍可能存在许多词语搭配被提取,其中一些可能是同义词。
故优选的,提取特征描述符的具体方法为:基于wordnet合并同义词,根据同义词的频率对双词短语进行排序,最后将最频繁的双词短语作为表述特征的描述符。
本发明还设计了基于自然语言的适航指令问题体征提取系统,其特征在于:所述系统包括:数据获取单元,用于获取适航指令的文本信息;
数据处理单元,用于对获取的文本信息进行特征提取处理。
本发明还设计了一种适航指令问题特征提取装置,其特征在于:包括处理器;
用于存储处理器可执行指令的存储器;
其中,处理器被配置为:执行如下方法:首先在文本描述的句子中检测(detect)所有潜在的重叠句簇,然后对发现的句簇进行排序并选择(select)给定数量的句簇,最后从选定的句簇中提取(extract)双词短语作为特征描述。
第一步是过滤文本中的噪声描述和单词,并获得一个句子列表,该句子列表由tf-idf向量形式的所有句子组成。由于文本描述中的一个句子可以描述多于一个特征,所以表示各个特征的句簇之间可能彼此重叠。
第二个步骤开始寻找簇的种子,然后贪婪地检测簇成员。一旦获得了一个句簇,就从句子列表中删除接近簇质心的语句,因为这些句子确定属于这个句簇,而不是任何其他的句簇。这也意味着簇中的其他句子在进一步的检测过程中可以分配给其他的句簇。同时,识别当前句簇的关键词,并从句子列表中的所有剩余句子中删除这些关键字,所识别的簇关键词将被进一步用于选择句簇和提取双词短语。
第三步在选择句簇过程中,按簇大小和簇关键字的平均权重将所发现的句簇进行排序。簇的大小反映了所表示特征的频率,簇关键字的平均权重反映了特征的重要性。在特征描述符提取过程中,将包含簇关键字的最频繁的双词短语选作为特征描述符。
本发明还设计了一种计算机存储介质,其上存储有计算机程序指令,其特征在于:所述计算机程序指令被处理器执行时实现如下方法:首先在文本描述的句子中检测(detect)所有潜在的重叠句簇,然后对发现的句簇进行排序并选择(select)给定数量的句簇,最后从选定的句簇中提取(extract)双词短语作为特征描述。
第一步是过滤文本中的噪声描述和单词,并获得一个句子列表,该句子列表由tf-idf向量形式的所有句子组成。由于文本描述中的一个句子可以描述多于一个特征,所以表示各个特征的句簇之间可能彼此重叠。
第二个步骤开始寻找簇的种子,然后贪婪地检测簇成员。一旦获得了一个句簇,就从句子列表中删除接近簇质心的语句,因为这些句子确定属于这个句簇,而不是任何其他的句簇。这也意味着簇中的其他句子在进一步的检测过程中可以分配给其他的句簇。同时,识别当前句簇的关键词,并从句子列表中的所有剩余句子中删除这些关键字,所识别的簇关键词将被进一步用于选择句簇和提取双词短语。
第三步在选择句簇过程中,按簇大小和簇关键字的平均权重将所发现的句簇进行排序。簇的大小反映了所表示特征的频率,簇关键字的平均权重反映了特征的重要性。在特征描述符提取过程中,将包含簇关键字的最频繁的双词短语选作为特征描述符。
在具体实施中,如图6所示,从softpedia.com抓取的软件文本描述来作为实验数据,总共获得了25类产品的文本描述,并删除重复和存在缺陷的文本描述,由于一些类别如多媒体等有数以千计的产品,并且需要人工从描述中识别软件特征来获取用于参考对比的准确的特征集合,因此本实施例从多于100个产品的类别中随机抽取了100种产品用于实验分析。
本实施例选择了antivirus和compresstool两大类的软件文本描述,用于人工分析以获得准确的特征集合。
其中antivirus类产品描述包含了1716句描述,compresstool类产品描述包含了1476句描述。对于每一类软件文本描述,首先选择不同的研究人员独立地从产品描述中识别出软件特征,然后讨论他们的结果以得到可供参考的特征集合。由于不同的设计人员在编写产品描述时可能会使用不同的词或模板来描述相同的软件特征,因此只选择一个合适的短语来描述一个特性是不容易的。因此,在人工分析过程中,我们选择一组有代表性的短语来作为特征的描述符。
实验1:以现有技术的k均值法作为对照组1,将其与本发明进行对比实验,首先使用k-均值对文本描述中的句子进行聚类,然后从每个簇中提取短语作为特征。为了使比较有意义,在实验中令本发明和k-均值方法取得相同数目的聚类(k=20)。
此外,使用本发明的短语提取方法来从k-均值得到的每个簇中提取特征。也就是说,当根据k-均值方法获得句簇时,首先计算每个簇的质心,找出每个簇的关键词,并提取包含簇关键字的频繁双词短语作为特征的描述符。
实验2:以现有技术中bakaretal.等人提出的特征提取方法作为对照组2,将其与本发明进行对比实验。
首先采用潜在语义分析(lsa)方法,然后对从lsa获得的数据运行聚类算法,以找到评论簇。由于这种方法以词性模板作为特征模板,而本发明则以双词短语作为特征模板,为了使得两种方法的比较具有意义,在根据bakaretal.[85]等人的方法中获得簇集之后,要按照本发明的方法提取双词短语作为特征。另外,由于bakaretal.等人提议使用模糊c-均值聚类算法对lsa数据进行聚类,所以在实验中为了保持变量一致,也采用了这种聚类算法对数据进行聚类。此外,在实验中也是从这两种方法中选择了相同数量的句簇进行比较。
实验3:以现有技术中的idc方法(增量扩散聚类算法)作为对照组3,将其与本发明进行对比实验。
idc迭代地对实验中选取的所有句子进行k次聚类,每次选择一个最佳句簇,并每次从描述的所有句子中识别和删除所选的簇关键字。每个选定簇中最接近质心的句子被视为特征描述符。k的数目意味着将检测到k个重叠句簇,并选择k个句子作为k个特征的描述符。
本发明采取了不同的方法来获得给定数量的句簇。它首先检测描述中所有潜在的重叠句簇,并选择给定数量的簇。为了将本发明与idc进行比较,选择了与idc相同数量的句簇以进行比较。
此外,考虑到idc和本发明都有许多参数,这些参数对提取结果有影响,因此需要在实验中改变它们,并尝试不同的值组合以获得最佳的比较结果。考虑到参数搜索空间的大小,我们采用固定步长(例如0.1)来改变一个参数的值,并赋予其他参数典型值的方式来搜索参数的适当值。
实验4:在idc方法的基础上应用本发明提取特征描述符的方法,将其作为idc+方法,进一步比较本发明与idc方法在采用相同的提取特征描述符的方式和不同的检测重叠句簇的方式时,二者的差异。
实验5:以现有技术中guzman和maalej提出的特征提取方法作为对照组4,将其与本发明进行对比实验。
首先从文本数据中提取频繁的双词短语,并将同义词聚在一起。对于每组同义词,选择最频繁的双词短语作为特征描述符。为了比较,我们从这两种方法中都选择了代表不同特征的相同数量的双词短语。
实验6:同样选择idc方法,但是本次实验是在在一台具有3.3gcpu和8g内存的pc机上进行,并记录了不同参数下本发明和idc方法的平均时间消耗,用于对比本发明与现有技术的时间消耗。
实验7:本实验的目的是观察本发明在删除产品描述中一些最频繁和最不频繁的一些单词时准确性的变化,本实验只考虑了两种情况,首先,删除频率小于0.01×产品数量和大于0.99×产品数量的单词;然后删除频率小于0.05×产品数量和大于0.95×产品数量的单词。
经过上述6个实验,分别获得图3~5。
参见图3,通过比较,可以看出,与现有方法相比,本发明取得了更高的精度。而且与idc+的比较结果表明,即使在idc采用与本发明相同的特征描述符提取方法时,本发明也会在准确度上有更好的表现。这也表明,本发明能够更好地识别表征文本特征的重叠句簇。
参见图4,可以看出,本发明花费更少的时间,这是由于idc需要遍历文本描述的所有句子k次,生成k个句簇,每次使用球形k-平均值方法对句子进行聚类,而本发明虽然我们的方法也需要检测所有潜在的重叠句簇,但只需遍历部分句子来生成一个句簇。
图5显示了移除一些最频繁和不频繁的单词的结果,des-0.01是指本发明在删除频率小于0.01×产品数量和大于0.99×产品数量的词时的准确性。des-0.05是指本发明在删除频率低于0.05×产品数量和大于0.95×产品数量的词时的精度。
从图5可以看出,去除一些最频繁和不频繁的词并不能提高特征提取的准确性。相反,它会因为删除一些重要的单词而降低准确性。
以美国联邦航空管理局faa近六年共计2293条的适航指令文件为实施例,利用本发明对上述适航指令问题描述中的频繁特征进行提取,提取结果如表2所示。
表2faa全部适航指令中问题描述的特征提取结果
从上述结果可以看出,适航指令的问题描述中涉及比较多的是nprmpropose(noticeofproposedrulemaking)、engine故障、hpt、gps、hydraulicpanel和screwpedal等。另一类就是涉及诸如damage、crack和affect的相关描述。
从上述集合中选取了同一个时间段内,美国联邦航空局(faa)颁布的针对波音737系列型号,以及空客a320系列型号相关的适航指令。其中,自2013年11月以来涉及737系列型号的适航指令共有161条,a320系列型号179条。对上述两个数据集合中全部适航指令问题描述部分的频繁特征进行提取,结果如表3和表4所示。
表3737系列型号2013年以来适航指令中问题描述的特征提取结果
表4a320系列型号2013年以来适航指令中问题描述的特征提取结果
经过对比,737系列型号中相比a320型号明显多出了fuelsystem以及fuelconduct等特征;而a320系列的特征相比737系列明显多出了反映mlgdoor(主起落架舱门)的特征信息。
由此可知,737系列型号的燃油系统存在不安全的隐患,而a320系列型号则由于起落架舱门经常动作的原因,出现了起落架舱门的风险因素。
由此可见,本发明还能有效的发现不同航空器设计特征和风险因素。
本领域普通技术人员可以理解上述实施例方法中的全部或部分流程,是可以通过计算机程序指令相关的硬件来完成,所述程序可存储于一个计算机可读存储介质中,如本发明的实施例中,该程序可存储于计算机系统的存储介质中,并被该计算机系统中的至少一个处理器执行,以实现包括如上述各方法的实施例的流程。其中所述存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明的范围限制,应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!