一种侧重于分类任务的单样本目标检测方法与流程
本发明属于图像单样本目标检测
技术领域:
,具体是涉及一种侧重于分类任务的单样本目标检测方法。
背景技术:
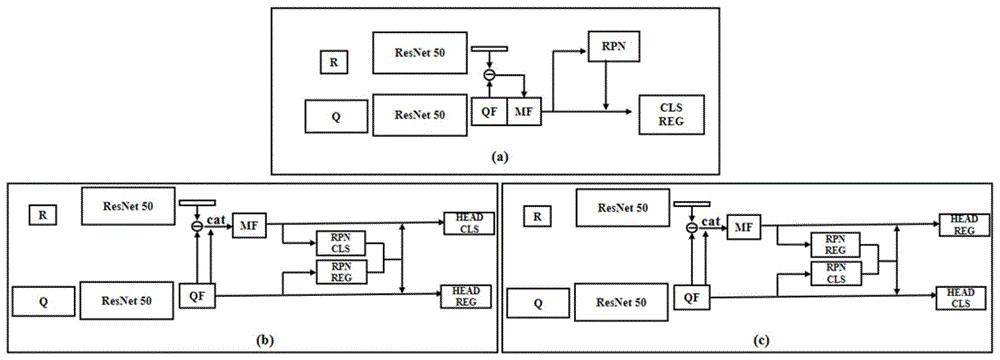
:近年来,基于卷积神经网络的目标检测方法取得了巨大的成功。但是,此成功依赖于由大量标注而成的大规模训练数据集,例如coco数据集。通用的目标检测只能检测出训练集中标注过的物体类别,这使得通用目标检测方法难以扩展新的物体类别。一方面,执行大量的标注工作十分耗时,并且经常会出现错误的标注;另一方面,在某些特殊场景下很难收集大量的新类别图像。因此,当仅提供少量甚至一张实例图片示例时,模型依旧能够在询问图像中检测出和该实例类别一致的物体是有价值且必要的。之前的工作使用孪生网络结构来完成此任务,其中siammask通过在maskr-cnn上添加比较匹配网络层来完成单样本实例分割,coae使用non-local和co-excitation来增强询问实例特征和参考实例特征之间的相关度。技术实现要素:本发明的目的在于针对现有技术的不足,提出一种侧重于分类任务的单样本目标检测方法。通过预实验观察发现,与未在定位分支引入参考实例特征相比,当分类分支未引入参考实例特征时,会由于检测到更多的假正例而导致更明显的性能下降。上述观察激发本发明通过提高单样本目标检测网络的分类能力来降低假正例的数量,从而提高检测性能。本发明提出使用相同交并比阈值的分类级联网络,通过比较多个邻近区域来提高分类的鲁棒性;本发明还提出对询问实例特征和参考实例特征进行分类区域变形的网络,以获得更有效的比较区域。本发明的方法相比于基准方法,在训练过的类别和未训练过的类别两个指标上的准确度均有显著提高。在同一数据设定下,在pascalvoc和coco数据集中实现了顶尖的性能。本发明的目的是通过以下技术方案来实现的:一种侧重于分类任务的单样本目标检测方法,该方法包括如下步骤:步骤1:读取数据集中训练样本的询问图像和参考实例图像,并读取和参考实例图像类别一致的询问图像中实例的类别标签和坐标位置,对输入询问图像和参考实例图像进行保持比例的缩放,并填充到固定大小,构成训练集;步骤2:在基准siamesefasterr-cnn网络的基础上加入分类区域变形网络以及分类级联网络,形成侧重于分类任务的单样本目标检测网络;利用步骤1得到的训练集对单样本目标检测网络进行训练;步骤3:读取测试样本的询问图像和参考实例图像,输入到步骤2中的训练好的单样本目标检测网络中,获得每个检测实例的两个分类置信度和坐标位置;步骤4:将步骤3中每个实例预测的两个分类置信度进行加权作为该实例的最终分类置信度;将每个实例的坐标位置和对应的最终分类置信度输入到非极大抑制算法中对重叠度高于阈值的检测框进行过滤,从而实现单样本目标检测。进一步地,所述步骤1中询问图像中的实例的类别标签设置方式为:把和参考实例图像类别一致的询问图像中的实例的类别标签设置为前景类,其余实例的类别标签设置为背景类。进一步地,所述步骤2中,基准siamesefasterr-cnn网络是通过去掉siammask的语义分支后而生成的。进一步地,所述步骤2中图像处理步骤如下:步骤21:利用基准siamesefasterr-cnn网络中共享权重的孪生resnet网络提取询问图像和参考实例图像的特征图信息;步骤22:利用度量学习网络提取询问特征图和参考特征图之间的相似度特征信息;把相似度特征信息输入到区域提议网络中生成提议区域,作为可能的检测框位置;步骤23:在检测头中,重新计算每个提议区域的相似度特征信息,并将相似度特征信息输入到基准siamesefasterr-cnn网络中的定位分支和分类级联网络构成的分类分支中。进一步地,所述步骤23中重新计算每个提议区域的相似度特征信息的流程如下:(1)将询问特征图中的提议区域作为询问实例特征,将参考特征图作为参考实例特征,将询问实例特征和参考实例特征输入到分类区域变形网络中进行分类区域变形,从而得到更有效的分类比较区域;(2)将经过变形的询问实例特征和参考实例特征输入到度量学习网络中获得更有效的相似度特征图。进一步地,所述步骤23中分类区域变形的处理方式是:其中qf表示询问实例特征,rf表示参考实例特征;pr和ph分别表示由区域提议网络和检测头预测的检测框的位置,r表示没有经过填充的参考实例的区域位置;是分类区域变形的函数;qfr和qfh分别表示经过分类区域变形后的用于分类级联网络两个阶段的询问实例特征,rfd表示经过分类区域变形后的参考实例特征;是roi-align操作;其中的公式形如:其中表示对pr中的每个网格进行循环,g(x,y)表示第(x,y)坐标的网格,p表示网格中每个像素的位置,nxy表示网格中的像素数量;γ是用来调制偏移量幅度的预定义标量;是获得偏移量的函数,它是一个三层全连接网络,三个输出层的通道为{c1,c2,nxnx2};(w,h)是pr的宽度和高度;表示双线性插值函数。进一步地,所述步骤2中度量学习网络的表示方式是:其中⊙指的是串联操作,gap是全局平均池化;convs,表示核大小为s、输出通道为k的卷积层;mfr和mfh分别表示输入到分类级联网络两个阶段的特征,表示输入到定位分支的特征。进一步地,所述步骤23中将相似特征图信息输入到定位分支和分类分支的具体处理方式如下:(1)为了减少定位分支对分类分支的影响,将分类分支和定位分支共享权重的部分进行解耦,并且在分类分支中使用全连接层,在定位分支中使用卷积层;(2)把mfr和mfh输入到相同交并比阈值的分类级联网络中进行两次分类,把输入到定位分支中进行一次位置预测,公式表示为:其中和分别为第一阶段和第二阶段分类函数,它是三层全连接的网络,是定位函数;s1和s2分别表示第一阶段和第二阶段分类得分。进一步地,所述步骤2中训练采用的损失函数为:其中由和组成,分别使用smoothl1损失函数和二值化交叉熵函数;和是检测头中的损失函数,使用smoothl1损失函数,和均使用二值化交叉熵函数。综上所述,本发明提出的一种基于侧重于分类的单样本目标检测方法,通过对询问实例特征和参考实例特征进行分类区域变形,以及固定交并比阈值的分类级联头增强了单样本目标检测的分类能力,从而降低了检测到的假正例的数量,进一步提高了单样本目标检测的性能。本发明相比于现有技术具有以下优点:本发明通过预实验证明单样本目标检测网络性能欠佳的一个主要原因是由于检测到大量的假正例导致的,本发明旨在通过提高单样本目标检测网络的分类能力来解决假样本过多的问题,通过对询问实例特征和参考实例特征进行分类区域变形,以及使用相同交并比阈值的分类级联网络的方法,在训练过的类别和未训练过的类别两个指标上的准确度均有显著提高,且在同一数据设定下,在pascalvoc和coco数据集中实现了顶尖的性能。附图说明图1为本发明的预实验中使用的不同网络的结构图,(a)为基准siamesefasterr-cnn网络,(b)为将基准网络修改成定位分支无参考实例特征的网络,(c)为将基准网络修改成分类分支无参考实例特征的网络。图2为本发明的预实验中假正例数量和精度结果的比较图。图3为本发明的网络结构图。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图对本发明的具体实施方式做详细的说明。在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。本发明公开了一种侧重于分类任务的单样本目标检测方法,通过预实验观察发现,与未在定位分支引入参考实例特征相比,当分类分支未引入参考实例特征时,会由于检测到更多的假正例而导致更明显的性能下降。图1是本发明的预实验中不同网络的结构图,其中(a)为基准线网络siamesefasterr-cnn,通过移除siammask中的语义分支获得,(b)和(c)分别是将基准网络修改成定位分支和分类分支无参考实例特征的网络,其中我们将区域提议网络和检测头的分类分支和定位分支解耦,以消除分类分支和定位分支的共享参数带来的影响。图2为本发明的预实验中假正例数量和精度结果的比较图,其中(a)显示了不同置信度范围下的假正例的数量的比较,(b)显示了在不同交并比评估值下的map的结果比较。通过预实验结果表明:(1)假正例较少的单样本检目标检测网络具有较高的精度。(2)参考实例特征在分类任务中比在定位任务中起着更重要的作用。(3)本发明的方法可以通过减少假正例的数量来提高检测的准确性。基于预实验的发现,本发明提出了一种侧重于分类任务的单样本目标检测方法,该方法包括如下步骤:步骤1:读取数据集中训练样本的询问图像和参考实例图像,并读取和参考实例图像类别一致的询问图像中实例的类别标签和坐标位置,对输入询问图像和参考实例图像进行保持比例的缩放,并填充到固定大小,构成训练集;步骤2:在基准siamesefasterr-cnn网络的基础上加入分类区域变形网络以及分类级联网络,形成侧重于分类任务的单样本目标检测网络;利用步骤1得到的训练集对单样本目标检测网络进行训练;步骤3:读取测试样本的询问图像和参考实例图像,输入到步骤2中的训练好的单样本目标检测网络中,获得每个检测实例的两个分类置信度和坐标位置;步骤4:将步骤3中每个实例预测的两个分类置信度进行加权作为该实例的最终分类置信度;将每个实例的坐标位置和对应的最终分类置信度输入到非极大抑制算法中对重叠度高于阈值的检测框进行过滤,从而实现单样本目标检测。进一步地,所述步骤1中询问图像中的实例的类别标签设置方式为:把和参考实例图像类别一致的询问图像中的实例的类别标签设置为前景类,其余实例的类别标签设置为背景类。输入图像缩放的具体参数为:在保持原图长宽比不变的前提下,最大限度地将询问图像的短边和长边缩放到小于或等于1024,最大限度地将参考实例图像的短边和长边缩放到小于或等于192。填充的具体参数为:将缩放后的询问图像的短边填充到1024,将缩放后的参考实例图像短边填充到192。进一步地,所述步骤2中,基准siamesefasterr-cnn网络是通过去掉siammask的语义分支后而生成的进一步地,所述步骤2中图像的具体处理步骤如下:步骤21:利用基准siamesefasterr-cnn网络中共享权重的孪生resnet网络提取询问图像和参考实例图像的特征图信息;步骤22:利用度量学习网络提取询问特征图和参考特征图之间的相似度特征信息;把相似度特征信息输入到区域提议网络中生成提议区域,作为可能的检测框位置;步骤23:在检测头中,重新计算每个提议区域的相似度特征信息,并将相似度特征信息输入到基准siamesefasterr-cnn网络中的定位分支和分类级联网络构成的分类分支中。进一步地,所述步骤23中重新计算每个提议区域的相似度特征信息的流程如下:(1)将询问特征图中的提议区域作为询问实例特征,将参考特征图作为参考实例特征,将询问实例特征和参考实例特征输入到分类区域变形网络中进行分类区域变形,从而得到更有效的分类比较区域;(2)将经过变形的询问实例特征和参考实例特征输入到度量学习网络中获得更有效的相似度特征图。进一步地所属步骤23中分类区域变形的处理方式是:其中qf表示询问实例特征,rf表示参考实例特征;pr和ph分别表示由区域提议网络和检测头预测的检测框的位置,r表示没有经过填充的参考实例的区域位置;是分类区域变形的函数;qfr和qfh分别表示经过分类区域变形后的用于分类级联网络两个阶段的询问实例特征,rfd表示经过分类区域变形后的参考实例特征;是roi-align操作;其中的公式形如:其中表示对pr中的每个网格进行循环,g(x,y)表示第(x,y)坐标的网格,p表示网格中每个像素的位置,nxy表示网格中的像素数量;γ是用来调制偏移量幅度的预定义标量;是获得偏移量的函数,它是一个三层全连接网络,三个输出层的通道为{256,256,7x7x2};(w,h)是pr的宽度和高度;表示双线性插值函数。进一步地,所述步骤2中度量学习网络的表示方式是:其中⊙指的是串联操作,gap是全局平均池化;convs,表示核大小为s、输出通道为k的卷积层;mfr和mfh分别表示输入到分类级联网络两个阶段的特征,表示输入到定位分支的特征。进一步地,所述步骤23中将相似特征图信息输入到定位分支和分类分支的具体处理方式如下:(1)为了减少定位分支对分类分支的影响,将分类分支和定位分支共享权重的部分进行解耦,并且在分类分支中使用全连接层,在定位分支中使用卷积层;(2)把mfr和mfh输入到相同交并比阈值(阈值可以取0.5)的分类级联网络中进行两次分类,把输入到定位分支中进行一次位置预测,公式表示为:其中和分别为第一阶段和第二阶段分类函数,它是三层全连接的网络,每层输出的通道数为{1024,1024,2},是定位函数;s1和s2分别表示第一阶段和第二阶段分类得分。进一步地,所述步骤2中训练采用的损失函数为:其中由和组成,分别使用smoothl1损失函数和二值化交叉熵函数;和是检测头中的损失函数,使用smoothl1损失函数,和均使用二值化交叉熵函数。进一步地,所述步骤4中将每个实例预测的两个分类置信度进行加权作为该实例的最终分类分类置信度中使用的加权权重是0.5。进一步地,所述步骤4中过滤重叠度高于阈值的检测框的步骤如下:步骤41:使用0.05置信度阈值过滤掉类别置信度低于该值的检测框;步骤42:对类别置信度分数排序,选择出前1000的置信度检测框;步骤43:将选择出的检测框输入到0.5阈值的非极大抑制算法中,保留最多100个检测框。为了体现本发明提出方法的进步性,在coco数据集和pascalvoc数据集上进行了对比试验,为了公平的比较,实验数据的设定和coae中的数据设定一致。为了获得稳定的测试结果,我们对所有网络进行了五次评估,为了节省训练时间,除了和顶尖的coae进行对比实验是在所有的4个split的coco数据集上进行对比之外,其余的消融实验都是在cocosplit2上进行的。我们首先针对提出网络的主要部分进行了消融对比实验,接着又对提出的分类区域变形网络进行了细致的消融研究,最后又将本发明提出的完整方法与目前已有的代表性的单阶段检测方法在coco和pascalvoc上进行了比较。目前目标检测方法大多采用ap作为评估指标,ap越大说明检测精度越高,效果越好。ap50是在iou>0.5时的ap指标。表1表1是在cocovalsplit2上进行的对主要成分的消融验证实验。其中baseline是指基准siamesefasterr-cnn网络,doublehead指的是在分类分支使用全连接层,在定位分支使用卷积层,ccd指的是本发明提出的用相同交并比阈值的分类级联网络,crd指的是对询问实例特征和参考实例特征使用分类区域变形网络,seen指的是对训练过的类进行评估,unseen指的是对未训练过的类进行评估。可以看出相比于原方法,分类级联网络在训练过的类的指标和未训练过的类的指标上各有1.1%和0.6%的提升。分类区域变形网络在训练过的类的指标和未训练过的类的指标上各有0.7%和0.6%的提升。可以证明我们所提出的方法的有效性。表2表2是在cocovalsplit2上进行的对分类区域变形方法的进一步实验。其中query是指是否对询问实例特征进行分类区域变形,reference是指是否对参考实例特征进行分类区域变形。可以看出,对询问实例特征应用分类区域变形,可以在训练过的类和未训练过的类的指标上分别提升0.6%/0.2%ap和0.8%/0.6%ap50。更进一步的对参考实例特征应用分类区域变形网络,可以在未训练过的类的指标上有0.4%ap和0.3%ap50的提升。表3表3是将本发明提出的完整的方法与目前已有的代表性的单样本目标检测方法coae以及基准方法在coco上的就训练过的类的指标进行性能对比。值得注意的是,由于更好的训练策略和执行流程我们的基准方法已经比coae高出了10.4%ap和12.0ap50。另外和基准方法相比,我们的方法能够获得1.8%ap和0.7%ap50的性能提升。表4表4是将本发明提出的完整的方法与coae以及基准方法在coco上的就未训练过的类的指标进行性能对比。我们的方法相比于基准线方法能够获得1.3%ap和0.8%ap50的性能提升。表5modelseenunseensiamfc15.113.3siamrpn9.614.2compnet52.752.1coae55.163.8ours66.269.1表5是将本发明提出的完整的方法与目前已有的代表性的单样本目标检测方法在pascalvoc上性能的对比。可以看出我们的方法在训练过的类和未训练过的类的指标上都大幅超过已有的方法。例如:我们的方法在训练过的类的指标上超过了coae11.1%ap,在未训练过的类的指标上超过了5.3%ap。另外,可以看出在pascalvoc数据集上我们的方法对未训练过的类的性能甚至超过了训练过的类的性能,可以表明我们的方法可以很容易的检测出未训练过的类。以上所述仅是本发明的优选实施方式,虽然本发明已以较佳实施例披露如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何的简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1