一种基于体感交互的舞台灯光调控方法及系统与流程
[0001]
本发明涉及一种基于体感交互的舞台灯光调控方法及系统,特别是涉及一种体感交互领域。
背景技术:
[0002]
在互联网技术的大力推进下,随着智能化技术的推进和生活水平提高以及大众对审美提升的追求下,人们对交互式体验的需求也在日益提高。舞台灯光随着表演者的演出推进,改变灯光的颜色和亮度可以更好的烘托出演出的效果和现场气氛。
[0003]
但现有技术中,舞台中灯光的调控效果和方案主要由设计人员根据节目的设定和内容所需的灯光需求,事先通过软件进行方案的制作与设计,前期消耗时间成本和人工成本较大,且互动感不足,沉浸式体验不足。
技术实现要素:
[0004]
发明目的:一个目的是提出一种基于体感交互的舞台灯光调控方法,以解决现有技术存在的上述问题。进一步目的是提出一种实现上述方法的系统。
[0005]
技术方案:一种基于体感交互的舞台灯光调控方法包括以下步骤:
[0006]
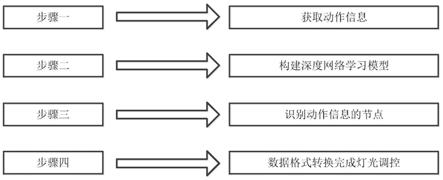
步骤一:获取位于舞台上舞者动作的实时信息;
[0007]
步骤二:建立根据动作节点判断动作信息的深度网络学习模型;
[0008]
步骤三:根据获得动作的实时信息,识别舞者的动作节点并输出;
[0009]
步骤四:转换深度学习网络输出的数据信息格式,将转换信号输入舞台灯,完成动作与灯光实时匹配的调控效果。
[0010]
在进一步的实施例中,所述步骤一进一步为:通过信息采集设备实时获取舞台上正在进行表演的舞者动作信息,并形成深度数据信息;其中所述深度数据为视野范围内的物体到三维空间的距离。
[0011]
在进一步的实施例中,所述步骤二进一步为:建立实现采集图片部分缺失的多特征融合识别深度网络学习模型;所述多特征融合识别深度网络学习模型用于根据接收到的信息缺失图片,实时判断舞台上表演者的动作信息,并将重建出的图片信息输出至步骤四中;其中,所述图片部分缺失为表演者在表演过程中出现表演者部分体征被遮挡物遮挡而出现采集信息不完整的图片;
[0012]
其中所述多特征融合识别深度网络学习模型的建立为:首先,建立用于所述模型训练的数据集;其次,将所述数据集放入建立的多特征融合识别深度网络学习模型中,并训练多特征融合识别深度网络学习模型学习从缺失图像到完整图像的学习映射;再次,将输出重建的图像信息与标签集中的图片信息进行误差进行计算,并更新网络权值;最后,根据完成学习的多特征融合识别深度网络学习模型实现确实图像信息的图片重建;其中所述数据集由包含舞者动作信息的图片构成,其中数据集进一步包含训练集和标签集;所述训练集与标签集一一对应,所述一一对应为训练集为含有缺失图像信息的图片,标签集为对应
的不含缺失图片信息的图片;
[0013]
特征提取为首先通过金字塔网络进行不同尺度特征的加深提取,然后在将各个特征上采样至原图大小,并进行融合;所述神经网络包含的特征提取阶段包含预定个残差模块,所述残差模块用于提取人体姿态的节点图;其中涉及卷积网络采用部分卷积的模式,即采用一个二值化的掩码将卷积分为有效卷积和无效卷积:
[0014][0015]
其中,w
i
表示当前卷积层的特征值,w
i+1
表示下一层的卷积特征值,w表示卷积核,b表示偏置值,m表示与接收图像相同尺寸的二值化掩码,表示对应元素相乘的卷积运算;其中值是0表示该部分为确实的区域,值是1表示部分为保留区域;下一层卷积的更新掩码为:
[0016][0017]
其中,m
i+1
表示下一层的卷积码;用于提取特征的卷积层,通过权重和对比结果进行特征的计算,即:
[0018][0019]
其中,x
j
表示卷积层中第j个特征,x
i
表示卷积层中第i个特征,m
j
表示特征映射集合,k
ij
表示权重,w
j
表示权重;表示卷积相乘运算;对特征进行融合的池化层通过池化层的特征映射和权重实现得到;
[0020]
对于图片缺失部分的预测采用回归方式的损失函数进行权值的优化;其中损失函数为范数优化欧氏距离的损失函数,即:
[0021][0022]
其中,θ表示待优化的表演者动作识别参数,n表示训练集图片的总数,x
i
表示当前学习的表演者样本图片,f
i
表示训练集中用于作为训练集对比,并与之对应的标签集数值。
[0023]
在进一步实施例中,所述步骤三进一步为:利用骨骼追踪技术,从步骤一获得的深度信息并结合步骤二中神经网络对缺失信息的重建中定位人体的骨骼节点信息;所述定位方法为通过确定人体的预定个关节点,对人体动作实时追踪;所述关节点具体信息为建立单位空间立体坐标,以三维坐标来表示每个关节点的位置;其中空间立体坐标中横轴表示水平移动距离,竖轴表示垂直距离,纵轴表示和坐标系原点的距离;
[0024]
其中,对于关键点的定位通过坐标转换将三维坐标系中的节点,进行关键点的几何转变,即:
[0025]
[0026]
其中,h表示骨骼关键点的节点坐标,h
′
表示转换之后的骨骼关键点坐标,a表示采集三维坐标系中节点定位的横坐标数值,b表示采集三维坐标系中节点定位的竖坐标数值,c表示采集三维坐标系中节点定位的纵坐标数值;上述通过对骨骼关键点归一化的处理,进一步使得不同身体比例的姿势骨架具备一致性。
[0027]
在进一步实施例中,所述步骤四进一步为:接收神经网络输出的节点数据格式,并通过信号转换设备完成数据格式的转换,将对应的灯光调控信号传送至舞台灯中,完成灯光调控;其中灯光的调控方法为根据舞台表演者的动作信号标记出节点,其中节点的整体的表现形式对应不同的灯光调控方案;所述灯光调控方案的制定为舞台表演者的左右半边动作信息,各控制预定个舞台灯的调控,定位节点坐标系中的纵轴表示的是表演者与坐标原点的距离,用于控制灯光的照射强度;所述坐标原点为以舞台前方边缘正中间的位置。
[0028]
一种基于体感交互的舞台灯光调控系统,包括:
[0029]
用于采集实时信息的第一模块;
[0030]
用于构建判断动作信息的深度网络学习模型的第二模块;
[0031]
用于获得动作的实时信息,识别舞者的动作节点的第三模块;
[0032]
用于转换数据格式,调控灯光的第四模块。
[0033]
在进一步的实施例中,所述第一模块进一步包括红外摄像头、红外装置、麦克风阵列,通过所述红外摄像头、红外装置、麦克风阵列采集设备实时获取舞台上正在进行表演的舞者动作信息,并形成深度数据信息;其中所述深度数据为视野范围内的被检测到的舞台上表演者到三维空间的距离。
[0034]
在进一步实施例中,所述第二模块进一步建立根据动作节点判断动作信息的深度网络学习模型;其中所述深度网络学习模型进一步为实现采集图片部分缺失的多特征融合识别深度网络学习模型;所述多特征融合识别深度网络学习模型用于根据接收到的信息缺失图片,实时判断舞台上表演者的动作信息,并将重建出的图片信息输出至步骤四中;其中,所述图片部分缺失为表演者在表演过程中出现表演者部分体征被遮挡物遮挡而出现采集信息不完整的图片;
[0035]
其中所述多特征融合识别深度网络学习模型的建立为:首先,建立用于所述模型训练的数据集;其次,将所述数据集放入建立的多特征融合识别深度网络学习模型中,并训练多特征融合识别深度网络学习模型学习从缺失图像到完整图像的学习映射;再次,将输出重建的图像信息与标签集中的图片信息进行误差进行计算,并更新网络权值;最后,根据完成学习的多特征融合识别深度网络学习模型实现确实图像信息的图片重建;其中所述数据集由包含舞者动作信息的图片构成,其中数据集进一步包含训练集和标签集;所述训练集与标签集一一对应,所述一一对应为训练集为含有缺失图像信息的图片,标签集为对应的不含缺失图片信息的图片;
[0036]
特征提取为首先通过金字塔网络进行不同尺度特征的加深提取,然后在将各个特征上采样至原图大小,并进行融合;所述神经网络包含的特征提取阶段包含预定个残差模块,所述残差模块用于提取人体姿态的节点图;其中涉及卷积网络采用部分卷积的模式,即采用一个二值化的掩码将卷积分为有效卷积和无效卷积:
[0037][0038]
其中,w
i
表示当前卷积层的特征值,w
i+1
表示下一层的卷积特征值,w表示卷积核,b表示偏置值,m表示与接收图像相同尺寸的二值化掩码,表示对应元素相乘的卷积运算;其中值是0表示该部分为确实的区域,值是1表示部分为保留区域;下一层卷积的更新掩码为:
[0039][0040]
其中,m
i+1
表示下一层的卷积码;用于提取特征的卷积层,通过权重和对比结果进行特征的计算,即:
[0041][0042]
其中,x
j
表示卷积层中第j个特征,x
i
表示卷积层中第i个特征,m
j
表示特征映射集合,k
ij
表示权重,w
j
表示权重;表示卷积相乘运算;对特征进行融合的池化层通过池化层的特征映射和权重实现得到;
[0043]
对于图片缺失部分的预测采用回归方式的损失函数进行权值的优化;其中损失函数为范数优化欧氏距离的损失函数,即:
[0044][0045]
其中,θ表示待优化的表演者动作识别参数,n表示训练集图片的总数,x
i
表示当前学习的表演者样本图片,f
i
表示训练集中用于作为训练集对比,并与之对应的标签集数值。
[0046]
在进一步的实施例中,所述第三模块进一步利用骨骼追踪技术,从第一模块获得的深度信息并结合第二模块中神经网络对缺失信息的重建中定位人体的骨骼节点信息;所述定位方法为通过确定人体的预定个关节点,对人体动作实时追踪;所述关节点具体信息为建立单位空间立体坐标,以三维坐标来表示每个关节点的位置;其中空间立体坐标中横轴表示水平移动距离,竖轴表示垂直距离,纵轴表示和坐标系原点的距离;
[0047]
其中,对于关键点的定位通过坐标转换将三维坐标系中的节点,进行关键点的几何转变,即:
[0048][0049]
其中,h表示骨骼关键点的节点坐标,h
′
表示转换之后的骨骼关键点坐标,a表示采集三维坐标系中节点定位的横坐标数值,b表示采集三维坐标系中节点定位的竖坐标数值,c表示采集三维坐标系中节点定位的纵坐标数值;上述通过对骨骼关键点归一化的处理,进一步使得不同身体比例的姿势骨架具备一致性。
[0050]
在进一步的实施例中,所述第四模块进一步包括用于基于tcp/ip协议的以太网协
议转换器,所述转换器将携带灯光控制信息的网络数据包进行传送;其中控制信息的转换进一步为接收第三模块输出的节点数据格式,并通过所述转换器完成数据格式的转换,将对应的灯光调控信号传送至舞台灯中,完成灯光调控;其中灯光的调控方法为根据舞台表演者的动作信号标记出节点,其中节点的整体的表现形式对应不同的灯光调控方案;所述灯光调控方案的制定为舞台表演者的左右半边动作信息,各控制预定个舞台灯的调控,定位节点坐标系中的纵轴表示的是表演者与坐标原点的距离,用于控制灯光的照射强度;所述坐标原点为以舞台前方边缘正中间的位置。
[0051]
有益效果:本发明提出了一种基于体感交互的舞台灯光调控方法及实现该方法的系统,首先,通过红外发射装置、红外摄像头完成所需深度数据的采集;其次,建立深度学习网络模型,对采集到的不同的动作信息以及部分被遮挡部位进行识别和处理;再次将处理后的信号并结合红外投影器,通过骨骼追踪技术定位获得人体关节的各个位置,并将处理后的信号与舞台灯呈现效果结合起来;最后,利用数据转接口实现数据格式的转换,并将调控灯光信号输入舞台灯,达到对舞台灯光效果的控制,从而实现基于人体动作的交互式灯光调控效果。
附图说明
[0052]
图1为本发明的实现方法流程示意图。
[0053]
图2为本发明骨骼节点调控流程图。
具体实施方式
[0054]
本发明通过一种基于体感交互的舞台灯光调控方法及实现该方法的系统,实现针对舞台上表演者的动作需求进而调控舞台灯光的目的。下面通过实施例,并结合附图对本方案做进一步具体说明。
[0055]
在本申请中,我们提出了一种基于体感交互的舞台灯光调控方法及实现该方法的系统,其中包含的一种基于体感交互的舞台灯光调控方法,具体为包括以下步骤:
[0056]
步骤一:获取位于舞台上舞者动作的实时信息;该步骤进一步为通过信息采集设备实时获取舞台上正在进行表演的舞者动作信息,并形成视野范围内的舞台上表演者到三维空间距离的深度数据信息,随后将采集到的图片信息实时传输至步骤二建立的模型中。其中建立用于等同表演者中位置信息的坐标系中,表演者的坐标定位具体以安装在舞台前方边缘中间的信息采集设备为坐标系原点,左右横向为坐标系横轴,上下浮动的高度为坐标系数轴,表演者与坐标系远点的垂直距离为坐标系纵轴。
[0057]
步骤二:建立根据动作节点判断动作信息的深度网络学习模型;具体为建立实现采集图片部分缺失的多特征融合识别深度网络学习模型。该步骤接收步骤一中传输过来的图片信息,进一步利用构建的深度网络学习模型实现图片重建,达到降低因表演者在表演过程中出现表演者部分体征被遮挡物遮挡而出现采集信息不完整,从而出现节点定位识别不完整的目的,并将重建出的图片信息输出至步骤三中。
[0058]
多特征融合识别深度网络学习模型的建立流程为:首先,建立用于所述模型训练的数据集;其次,将所述数据集放入建立的多特征融合识别深度网络学习模型中,并训练多特征融合识别深度网络学习模型学习从缺失图像到完整图像的学习映射;再次,将输出重
建的图像信息与标签集中的图片信息进行误差进行计算,并更新网络权值;最后,根据完成学习的多特征融合识别深度网络学习模型实现确实图像信息的图片重建。
[0059]
其中,模型建立的流程中构建的数据集包括各种场景下含有表演者不同动作状态的训练集和标签集,且训练集与标签集一一对应。训练集为含有缺失图像信息的图片,标签集为对应的不含缺失图片信息的图片。
[0060]
其中,模型建立的流程中涉及的特征提取为首先通过金字塔网络进行不同尺度特征的加深提取,然后在将各个特征上采样至原图大小,并进行融合;所述神经网络包含的特征提取阶段包含预定个残差模块,所述残差模块用于提取人体姿态的节点图;其中涉及卷积网络采用部分卷积的模式,即采用一个二值化的掩码将卷积分为有效卷积和无效卷积:
[0061][0062]
其中,w
i
表示当前卷积层的特征值,w
i+1
表示下一层的卷积特征值,w表示卷积核,b表示偏置值,m表示与接收图像相同尺寸的二值化掩码,表示对应元素相乘的卷积运算;其中值是0表示该部分为确实的区域,值是1表示部分为保留区域;下一层卷积的更新掩码为:
[0063][0064]
其中,m
i+1
表示下一层的卷积码;当网络满足深度为预设定深度时,任何破损的区域都会逐渐减小至消失,随后通过解码器便可以完成重建并修复图像。用于提取特征的卷积层,通过权重和对比结果进行特征的计算,即:
[0065][0066]
其中,x
j
表示卷积层中第j个特征,x
i
表示卷积层中第i个特征,m
j
表示特征映射集合,k
ij
表示权重,w
j
表示权重;表示卷积相乘运算;对特征进行融合的池化层通过池化层的特征映射和权重实现得到。
[0067]
对于图片缺失部分的预测采用回归方式的损失函数进行权值的优化;其中损失函数为范数优化欧氏距离的损失函数,即:
[0068][0069]
其中,θ表示待优化的表演者动作识别参数,n表示训练集图片的总数,x
i
表示当前学习的表演者样本图片,f
i
表示训练集中用于作为训练集对比,并与之对应的标签集数值。
[0070]
步骤三:根据获得动作的实时信息,识别舞者的动作节点并输出;该步骤进一步为利用骨骼追踪技术,从步骤一获得的深度信息并结合步骤二中神经网络对缺失信息的重建中定位人体的骨骼节点信息;所述定位方法为通过确定人体的预定个关节点,对人体动作实时追踪;所述关节点具体信息为建立单位空间立体坐标,以三维坐标来表示每个关节点的位置;其中空间立体坐标中横轴表示水平移动距离,竖轴表示垂直距离,纵轴表示和坐标
系原点的距离;
[0071]
其中,对于关键点的定位通过坐标转换将三维坐标系中的节点,进行关键点的几何转变,即:
[0072][0073]
其中,h表示骨骼关键点的节点坐标,h
′
表示转换之后的骨骼关键点坐标,a表示采集三维坐标系中节点定位的横坐标数值,b表示采集三维坐标系中节点定位的竖坐标数值,c表示采集三维坐标系中节点定位的纵坐标数值;上述通过对骨骼关键点归一化的处理,进一步使得不同身体比例的姿势骨架具备一致性。
[0074]
步骤四:转换深度学习网络输出的数据信息格式,将转换信号输入舞台灯,完成动作与灯光实时匹配的调控效果;该步骤进一步为接收步骤三中输出的节点数据格式,并通过信号转换设备完成数据格式的转换,将对应的灯光调控信号传送至舞台灯中,完成灯光调控;其中灯光的调控方法为根据舞台表演者的动作信号标记出节点,其中节点的整体的表现形式对应不同的灯光调控方案;所述灯光调控方案的制定为舞台表演者的左右半边动作信息,各控制预定个舞台灯的调控,定位节点坐标系中的纵轴表示的是表演者与坐标原点的距离,用于控制灯光的照射强度;所述坐标原点为以舞台前方边缘正中间的位置。
[0075]
基于上述方法,可以构建一种用于实现上述方法的系统,该实现系统包含:
[0076]
用于采集实时信息的第一模块;该模块进一步包括红外摄像头、红外装置、麦克风阵列,其中红外设备通过借助红外线触发所述设备的运作。当表演者处于舞台中时,红外摄像头利用红外技术进行表演者的实时拍摄定位,并形成用于方法流程中步骤一种涉及到的深度数据。其中所述深度数据为视野范围内的被检测到的舞台上表演者到三维空间的距离。
[0077]
用于构建判断动作信息的深度网络学习模型的第二模块;该模块进一步包括根据动作节点判断动作信息的深度网络学习模型;其中所述深度网络学习模型进一步为实现采集图片部分缺失的多特征融合识别深度网络学习模型,用于根据接收到的信息缺失图片,实时判断舞台上表演者的动作信息,并将重建出的图片信息输出至第三模块中;
[0078]
其中模型的建立进一步包括:数据集模块、模型训练模块、权值修正模块。数据集模块进一步分为训练集模块和标签集模块,且两个模块中的图片数据一一对应。训练集模块包含表演者多种不同动作信息的缺失图片,用于作为模型训练模块的输入数据;标签集模块包含表演者多种不同动作信息的完整图片,用于作为模型训练模块的对比数据。其中,所述图片部分缺失为表演者在表演过程中出现表演者部分体征被遮挡物遮挡而出现采集信息不完整的图片。
[0079]
模型训练模块用于接收数据集模块中拥有的训练集图片,通过金字塔网络进行不同尺度特征的加深提取,然后在将各个特征上采样至原图大小,并进行融合;所述神经网络包含的特征提取阶段包含预定个残差模块,所述残差模块用于提取人体姿态的节点图;其中涉及卷积网络采用部分卷积的模式,即采用一个二值化的掩码将卷积分为有效卷积和无效卷积:
[0080][0081]
其中,w
i
表示当前卷积层的特征值,w
i+1
表示下一层的卷积特征值,w表示卷积核,b表示偏置值,m表示与接收图像相同尺寸的二值化掩码,表示对应元素相乘的卷积运算;其中值是0表示该部分为确实的区域,值是1表示部分为保留区域;下一层卷积的更新掩码为:
[0082][0083]
其中,m
i+1
表示下一层的卷积码;用于提取特征的卷积层,通过权重和对比结果进行特征的计算,即:
[0084][0085]
其中,x
j
表示卷积层中第j个特征,x
i
表示卷积层中第i个特征,m
j
表示特征映射集合,k
ij
表示权重,w
j
表示权重;表示卷积相乘运算;对特征进行融合的池化层通过池化层的特征映射和权重实现得到。
[0086]
权值修正模块通过损失函数的调用实现网络模型的权值修正。进一步为对于图片缺失部分的预测采用回归方式的损失函数进行权值的优化;其中损失函数为范数优化欧氏距离的损失函数,即:
[0087][0088]
其中,θ表示待优化的表演者动作识别参数,n表示训练集图片的总数,x
i
表示当前学习的表演者样本图片,f
i
表示训练集中用于作为训练集对比,并与之对应的标签集数值。
[0089]
用于获得动作的实时信息,识别舞者的动作节点的第三模块;该模块利用骨骼追踪技术,从第一模块获得的深度信息并结合第二模块中神经网络对缺失信息的重建中定位人体的骨骼节点信息;所述定位方法为通过确定人体的预定个关节点,对人体动作实时追踪;所述关节点具体信息为建立单位空间立体坐标,以三维坐标来表示每个关节点的位置;其中空间立体坐标中横轴表示水平移动距离,竖轴表示垂直距离,纵轴表示和坐标系原点的距离。
[0090]
其中,对于关键点的定位通过坐标转换将三维坐标系中的节点,进行关键点的几何转变,即:
[0091][0092]
其中,h表示骨骼关键点的节点坐标,h
′
表示转换之后的骨骼关键点坐标,a表示采集三维坐标系中节点定位的横坐标数值,b表示采集三维坐标系中节点定位的竖坐标数值,c表示采集三维坐标系中节点定位的纵坐标数值;上述通过对骨骼关键点归一化的处理,进
一步使得不同身体比例的姿势骨架具备一致性。
[0093]
用于转换数据格式,调控灯光的第四模块;该模块进一步包括用于基于tcp/ip协议的以太网协议转换器,所述转换器将携带灯光控制信息的网络数据包进行传送;其中控制信息的转换进一步为接收第三模块输出的节点数据格式,并通过所述转换器完成数据格式的转换,将对应的灯光调控信号传送至舞台灯中,完成灯光调控;其中灯光的调控方法为根据舞台表演者的动作信号标记出节点,其中节点的整体的表现形式对应不同的灯光调控方案;所述灯光调控方案的制定为舞台表演者的左右半边动作信息,各控制预定个舞台灯的调控,定位节点坐标系中的纵轴表示的是表演者与坐标原点的距离,用于控制灯光的照射强度;所述坐标原点为以舞台前方边缘正中间的位置。
[0094]
如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1