一种评分卡建模方法与流程
本发明涉及信贷风控管理领域,具体地说,涉及针对放贷对象所做的一种评分卡建模方法。
背景技术:
在信贷风控领域的传统评分卡构建流程非常复杂,一般分为数据探索、woe计算、变量筛选、相关性分析、分箱调整、模型调参、模型评估、评分卡转换、模型稳定性验证等诸多步骤。传统模型建模流程主要有以下几个问题:
1.建模时间长:由于上述流程十分繁琐,所以评分卡的建立从数据探索到稳定性测试完成往往需要近一个月的时间,这就大大影响了以评分卡为基础的风控系统对市场变化的反应速度。其中,最费时费力的步骤主要集中在变量筛选、分箱调整和模型调参上。这些步骤往往需要反复的迭代测试。
2.模型效果:传统模型在变量筛选时仅依赖两个方面:
a)筛选与因变量相关性较高的自变量,基于如iv/ks/gini值等;
b)为了减少共线性,剔除相关性较高的自变量;
基于以上筛选条件会过度消减训练逻辑回归模型前的入模变量个数,从而影响模型精度。
误操作率高:手动建立传统评分卡在每个步骤上都要做大量的数据分析、数据整理,这就大大增加了出错的可能性。
技术实现要素:
本发明的目的在于提供一种评分卡建模方法,用于解决现有技术中评分卡建模过程中耗时长,不能适应外部市场变化、以及建模模型效果差,错误率高的技术问题。
本发明提供的一种评分卡建模方法包括以下步骤:
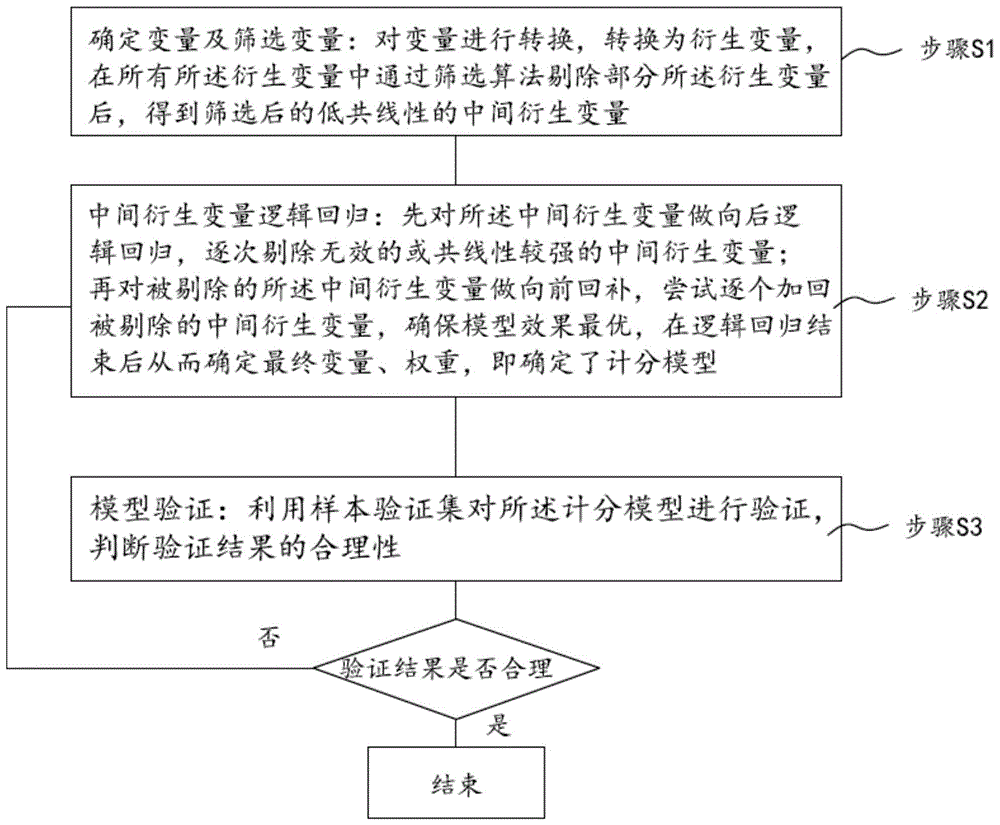
步骤s1,确定变量及筛选变量:对变量进行转换,转换为衍生变量,在所有所述衍生变量中通过筛选算法剔除部分所述衍生变量后,得到筛选后高解释性、低共线性的中间衍生变量;
步骤s2,中间衍生变量逻辑回归:先对所述中间衍生变量做向后逻辑回归,逐次剔除无效的或共线性较强的中间衍生变量;再对被剔除的所述中间衍生变量做向前回补,尝试逐个加回被剔除的中间衍生变量,确保模型效果最优,在向后逻辑回归和向前回补过程结束后确定最终入模变量及其权重,即确定了计分模型;
步骤s3,模型验证:利用样本验证集对所述计分模型进行验证,判断验证结果的合理性;当所述验证结果不合理时,退回执行所述步骤s2。
采用本发明的评分卡建模方法完成计分模型的建模,仅在特定的几个步骤中需要人为介入,采用这种半自动建模方法将现有的建模时间由一个月缩短到了三天的时间,克服了现有技术中建模时间较长的技术问题;除此之外,在对样本训练集中的中间衍生变量逻辑回归的步骤中采用了后逻辑回归及向前回补的两种回归迭代过程,对中间衍生变量中共线性较高的变量再次进行了验证和剔除,同时通过多次迭代后保证确定的各个中间衍生变量的权重最为合理,即便是在实际应用时部分变量缺失情况下,确定的权重也不会影响计分模型的输出结果,能够使得计分模型计分更加的精确,和快速,防止宕机。最后,本发明的评分卡计分模型除过需要人为介入的步骤外,其他的步骤均是标准化封装,其系统自动运行,减少了人工建模出错的可能性。
附图说明
图1是本发明评分卡建模方法的整体流程图;
图2是本发明步骤s1的流程图;
图3是本发明步骤s13的流程图;
图4是本发明的评分卡建模方法的另一种实施方式流程图。
具体实施方式
下面结合具体实施例和说明书附图对本发明做进一步阐述和说明:
请参考图1,本发明公开的一种评分卡建模方法。其方法主要用于对银行金融机构评估客户的消费和信贷还款能力,用于信贷金融机构的风险评估。
具体的所述评分卡建模方法包括:
步骤s1,确定变量及筛选变量:对变量进行转换,转换为衍生变量,在所有所述衍生变量中通过筛选算法剔除部分所述衍生变量后,得到筛选后高解释性、低共线性的中间衍生变量。
在本步骤中,首先需要对数据探索和修正:统计样本训练数据,确定样本训练数据中所需要的变量类型和分布,并人工判断、修正部分错误变量类型。
在本步骤中样本训练数据主要对象是面向银行的个人或者企业机构,其样本训练数据包括用于描述这些个人或者企业机构的数据,例如:个人年龄、性别、信用等级、贷款金额、还款期限、婚姻、工作岗位性质、收入情况、贷款途径、名下财产等多个变量。
当银行确定了样本训练数据后,在模型建模前需要对样本训练数据的这些变量进行检验,修正,修改其中异常的变量格式或者数值,这样才能为后边进一步的样本训练数据建模提供条件。
在本步骤中,接着需要变量确定:对所述变量进行转换,转换为衍生变量,在所有所述衍生变量中通过筛选算法剔除部分衍生变量后,得到筛选后高解释性、低共线性的中间衍生变量。
变量确定是指要从银行提供的对象的总的变量中通过筛选算法选出影响评分的最关联变量,且这些变量之间尽量不具有共线性,这样才能保证最终的计分模型输出的结果尽可能的精确而稳定,受外界其他变量影响较小。
参阅图2,具体的,确定变量并将所述变量转化为衍生变量的方法包括:
步骤s11:对银行提供的变量分别做证据权重(woe,weightofevidence)计算、重编码(recode)计算,得到两组所述衍生变量。
其中,证据权重(woe,weightofevidence)计算能够对总的变量进行分析,确定这些总的变量中对评分结果影响大的变量有哪些。而重编码(recode)计算是指对部分的样本中某个变量缺失、变量异常以及特殊值进行处理后,通过recode函数进行修改,修改为连续变量,从而能够保证所有的变量在证据权重计算后都不存在缺失、数值异常等情况。相较于传统的仅针对变量进行证据权重计算的情况来说,保留了更多的变量,虽然在计分模型的构建中复杂度增加了,但是增加的复杂度在可接受的范围内,最主要的是引入recode计算后能够提高构建的计分模型的精确度和稳定性。
步骤s12:对两组所述衍生变量的计算结果做相关性以及基于因子分析的变量聚类分析,剔除高共线性的所述衍生变量。
共线性是指某一个变量对计分结果的影响与另一变量对计分结果的影响相似或者相同,此时基于两个变量进行模型构建后形成的计分模型稳定性差;当共线性变量比较多完成模型构建后,计分模型的通用性急剧恶化,甚至不能适应实际的需要,所以在模型构建的时候尽可能的保证各个变量之间不具有共线性,从多个维度上描述并拟合出计分模型,这样的计分模型更加稳定。
如图3,其中,在做相关性和变量聚类分析时还包括以下方法:
首先,步骤s121:基于所述衍生变量的个数确定若干备选分簇数;
接着,步骤s122:基于因子分析以及主成分分析(pca,principalcomponentanalysis)算法将衍生变量按照备选分簇数分簇;
之后,步骤s123:评估不同备选分簇数下分簇的结果对整个衍生变量的样本训练集的解释度,选取具有最大解释度的分簇方式作为分簇结果;
再有,步骤s124:从最终所述分簇方式的每个分簇中选取若干个最优衍生变量,选取最优衍生变量时,当所述分簇中具有woe变量和recode变量时优先选取woe变量;
在本步骤中,选取的若干个最优变量包括:
每个分簇中拟合系数率(coefficientofdeterminationratio)最小的衍生变量;
每个分簇中柯尔莫哥洛夫-斯米诺夫(ks,kolmogorov-smirnov)检验值最高的衍生变量;
当分簇中拟合系数(coefficientofdetermination)小于0.3的衍生变量具有多个时,选择所述衍生变量中柯尔莫哥洛夫-斯米诺夫(ks,kolmogorov-smirnov)检验值最高的衍生变量。
最后,步骤s125:汇总每个分簇中选取的多个所述衍生变量,如果同一个变量衍生出的woe变量和recode变量同时存在时,优先选择woe变量,从而最终筛选出所述中间衍生变量。
在对样本训练数据中的变量进行以上操作后,就获得了中间衍生变量,所述中间衍生变量是录入后边的逻辑回归模型中,作为基本变量从而确定变量权重的基础。
步骤s2:中间衍生变量逻辑回归:先对所述中间衍生变量做向后逻辑回归,逐次剔除无效的或共线性较强的中间衍生变量;再对被剔除的所述中间衍生变量做向前回补,尝试逐个加回被剔除的中间衍生变量,确保模型效果最优,在向后逻辑回归和向前回补过程结束后确定最终入模变量及其权重,即确定了计分模型;
在执行步骤s2之前,为了能够更加快速的得到逻辑回归模型,优选的还可以增加确定权重方向:确定所述中间衍生变量的权重方向,确定的所述权重方向能够使得利用所述中间衍生变量和所述权重的计算结果符合样本训练集的评分趋势。
具体的,所述向后逻辑回归为:从全部的所述中间衍生变量中每次剔除满足第一条件的一个变量,并对每次剔除后剩余的中间衍生变量做逻辑回归迭代运算,直至在所有的所述中间衍生变量中不存在任何一个变量满足所述第一条件;
所述第一条件包括:
woe衍生变量权重值为负值或recode衍生变量的权重方向错误;或
p-value值过大的衍生变量,即变量权重均位于沃尔德(wald)置信区间外;或
衍生变量权重的方差膨胀系数(vif,varianceinflationfactor)过大。
在本实施方式中,通过woe计算的变量的权重均为正值,当某一个变量的权重值为负值说明,在woe计算的过程中存在某一个或者几个变量的共线性较高,而权重为负值的变量就是共线性较高的变量中的一个,所以此时应该剔除所述变量;
p-value值过大是指某一个权重数值在整个权重分布中处于不可信的区间,即权重值偏移量过大,此时为保证计分模型的精确性直接将该变量剔除后重新逻辑回归迭代;
变量权重的方差膨胀系数(vif,varianceinflationfactor)过大是指对所有变量中的某一个变量的权重分析,该变量的权重相对于所有变量的权重的方差膨胀系数大,即离散性太强,偏离分布区间的情况,此时这个变量也应该被剔除后重新逻辑回归的迭代计算权重。
在本步骤s2的方法中还包括向前回补,向前回补是指逐个将所述向后逻辑回归中剔除的中间衍生变量加回到向后逻辑回归的总入模变量中,并对加回后的整体的所述中间衍生变量做逻辑回归迭代运算,根据所述运算结果是否满足第二条件,如果满足则确定加回剔除的所述中间衍生变量,直至所有所述向后逻辑回归中剔除的中间衍生变量均检测完毕。
所述第二条件包括:
加回的所述中间衍生变量使得所述权重系数依然正确;且
加回的所述中间衍生变量的p-value值大小合理,且位于沃尔德(wald)置信区间内;且
加回的所述中间衍生变量使得整个所述中间衍生变量的权重的方差膨胀系数(vif,varianceinflationfactor)在合理范围内。
在本发明的实施方式中,当将剔除的中间衍生变量加回整体所述中间验证变量后,如果加回的变量使得第二条件成立的,此时则认为加回的变量是有效变量,并没有影响到计分模型的稳定性和精确度,此时增加上所述变量后能够进一步地提高计分模型的精度和稳定性。
步骤s3,模型验证:利用样本验证集对所述计分模型进行验证,判断验证结果的合理性;当所述验证结果不合理时,退回执行所述步骤s2。在本步骤中,当验证结果不合理时,则认为在步骤s2中变量确定存在问题,例如删除了部分影响较大的变量,或者确定的变量里存在部分共线性高的变量,此时最根本的方式是重新回到步骤s2中完成变量确定,并再执行后续步骤。
具体的,步骤s3模型验证的方法包括:分别将所述样本训练集以及样本验证集输入中间衍生变量逻辑回归后形成的计分模型,并通过所述计分模型计算所述样本训练集以及样本验证集的柯尔莫哥洛夫-斯米诺夫(ks,kolmogorov-smirnov)检验值并验证所述检验值的合理性。
参阅图4,在本发明的另外一些实施方式中,本发明的评分卡建模方法还包括:
步骤s4,评分转化及调整转换参数:对所述验证结果转化为评分,判断所述评分的合理性,并手动修正转化过程中的转化参数,从而输出最终评分。
其中,所述步骤s4的评分转化及调整转换参数的方法包括:将所述计分模型计算的结果进行中心化和标准化映射,使所述计分模型计算的结果转化为一个区间内;在转化时人为根据抽样情况以及计分模型计算时剔除的部分样本训练数据做转化参数的微调,从而使的最终计分值更贴合实际应用。
例如,计分模型计算出的结果值在0~1之间,将计分结果转化到更适合人类分析观察的分布区间中,例如1~1000内,在转化的同时,还需要考虑之前剔除的特殊的样本情况,或者对样本的抽样计算情况,从而尽可能的使转换贴合实际需要。
步骤s5,模型稳定性验证:对所述计分模型初步应用,并验证所述计分模型的稳定性,适时做出模型微调。
在本步骤中,所述计分模型已经建模完成,此时进入应用阶段,在应用阶段需要将所述计分模型直接应用于金融机构及银行等,用于分析客户的消费和信贷还款能力,仅在出现某个或者一些较大偏差的时候才需要后期介入修改计分模型的部分变量以及权重。
进一步地,所述计分模型在运行后能自动提供验证和测试报告,验证和测试包括以下的至少一种:针对样本训练集和/或验证数据集运行的ks值、提升度以及各个分箱的统计量;样本训练集与验证数据集的对比测试;样本训练集的评分分布以及稳定性验证;计分模型的变量稳定性验证。
采用本发明的评分卡建模方法完成计分模型的建模,仅在特定的几个步骤中需要人为介入,采用这种半自动建模方法将现有的建模时间由一个月缩短到了三天的时间,克服了现有技术中建模时间较长的技术问题;除此之外,在对样本训练数据中的中间变量逻辑回归的步骤中采用了后逻辑回归及前逻辑回归的两种回归迭代过程,对中间变量中共线性较高的变量再次进行了验证和剔除,同时通过多次迭代后保证确定的各个变量的权重最为合理,即便是在实际应用时部分变量缺失情况下,确定的权重也不会影响计分模型的输出结果,能够使得计分模型计分更加的精确。最后,本发明的评分卡计分模型除过需要人为介入的步骤外,其他的步骤均是标准化封装,其系统自动运行,减少了人工建模出错的可能性。
利用本发明的方法还具有以下有益效果:
维度覆盖面更广:
a)本算法同时引进了woe(weightofevidence)变量以及recode变量(处理了空值、特殊值、异常值的变量),进而从稳定性和精确性两方面构建和筛选变量。
b)本算法创新性地引入了基于因子分析和pca(主成分分析)算法的聚类分析,将自变量按其主成分分簇,并在每个分簇中各选取若干变量,从而最大限度地保留了维度的解释度和覆盖面。
拟合精确度高:
c)由于本算法同时引入了woe和recode变量,且采用聚类分析筛选变量以增加其覆盖面,所以本算法的逻辑回归入模变量一般多于传统建模过程,其精确度也相对较高。
d)本算法在传统的向后逻辑回归算法基础上,创新性地加入了向前回补过程——将之前剔除的变量逐个加回到逻辑回归迭代中再次判断其有效性,从而最大限度地保留了有效变量,提高模型精度。
建模时间短:本算法分为多个主要模块,各模块可以独立运行。发明者将实现各个功能的最优方法及流程集成到模块之中,从而减少了手动建模过程中为实现某一功能反复调试的过程,用户仅需要在少数几个步骤介入人工判断,这也就大大的缩短了建模时间。
不易出错:由于大部分功能已经实现自动化,人工介入较少,所以在缩短建模时间的同时还可以减少人工数据分析时出错的可能性。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!