一种基于深度对抗生成网络的文本生成人脸方法
1.本发明涉及计算机视觉领域,具体涉及基于深度学习的文本到图像生成、人脸生成领域的应用,尤其涉及一种基于深度学习的从文本描述生成人脸图像的应用。
背景技术:
2.近年来,基于深度学习的图像生成技术发展迅速,该技术已经应用到了社会的各个领域中,比如影视媒体、相机美颜、计算机辅助修图、换脸、考古研究和图像修复等。其中从文本描述到图像生成的技术也越来越成熟,出现了attngan、dm-gan、kt-gan等技术在文本描述到图像生成方面取得了较大的突破,这些技术将会逐渐地应用到相关的各个领域。在社会公共安全领域,在对犯罪份子进行追捕时,往往会从目击者对目标人物的描述中获取到面貌的关键信息,甚至需要专业人员根据目击者的描述进行人脸画像。为此,研究从文本描述到人脸的生成技术,不但在公共安全领域有着较大的应用前景,在人脸图像修复、影视娱乐和考古研究等领域都有着较大的应用前景。
3.目前文本到图像的生成技术研究已经越来越成熟,但专注于文本到人脸生成方面的研究非常的少,还处于起步阶段。当前,只根据文本描述要生成与原始人脸相似的人脸图像技术难度高,还需要在技术上不断进步,本发明在该领域进行了创新和取得了一定的突破。
技术实现要素:
4.本发明针对从文本描述到图像生成领域,尤其是从文本描述到人脸生成方面的问题,提供了一种基于深度对抗生成网络的文本生成人脸方法。该方法采用三级对抗生成网络,分别生成64
×
64、128
×
128和256
×
256三种分辨率大小的人脸图像,其中第一级生成人脸质量的好坏直接影响到最后生成人脸的质量,人脸生成任务要尽量做到生成人脸与原始人脸的语义一致性,为此本发明将第一级设计成双通道,一个通道输入为高斯噪声n(0~1)~和文本描述组合的特征向量,另一通道输入为文本描述的特征向量,有效地提升了生成人脸图像的质量。同时,引入感知损失函数(perceptual loss)来引导网络模型根据文本生成更加接近原始人脸的人脸图像,本发明提出了图1所示深度对抗生成网络模型的总体原理框架图。
5.本发明通过以下技术方案来实现上述目的:
6.一种基于深度对抗生成网络的文本生成人脸方法,包括以下步骤:
7.步骤一:数据集制作,在公开人脸数据集上选取人脸图像并对其进行文本描述,然后将描述完成的人脸图像和文本描述数据拆分为训练集和测试集;
8.步骤二:网络模型设计,提出的深度对抗网络采用双通道(dual-channel generative adversarial network,dualgan)模型,同时引入感知损失函数(perceptual loss)来引导网络模型根据文本生成更加逼真的人脸图像;
9.步骤三:网络模型参数训练,将步骤一中的训练数据集输入到步骤二中模型中进
行训练,并根据中间结果不断对网络超参数进行调整和优化;
10.步骤四:网络模型性能测试,将步骤一中的测试数据集输入到步骤三训练好的模型中进行人脸生成测试,引入人脸相似度(face similarity score,fss)和人脸相似度距离(face similarity distance,fsd)来对生成的人脸图像进行评价。
11.作为步骤一中数据集制作说明如下:
12.目前为止还没有公开的从文本描述生成人脸的数据集,为此要完成该任务,首先需要构建相应的数据集供网络模型训练和测试。本发明从公开人脸数据集lfw和celeba中选择1000个人脸图像,首先截取出人脸部分图像,除去多余的背景图案,重置分辨率大小为256
×
256,然后通过人工对每个人脸图像分别用5句话进行描述,文本生成人脸的数据集样例如图2所示。
13.作为步骤二中的双通道对抗生成网络(dual-channel generative adversarial network,dualgan)模型,其说明如下:
14.从文本描述生成人脸的网络采用的是三级对抗生成网络(generative adversarial network,gan),第一级gan生成的人脸图像分辨率大小为64
×
64,第二级gan生成的人脸图像分辨率大小128
×
128,第三级gan生成的人脸图像分辨率大小为256
×
256。其中,最关键的是第一级gan生成人脸图像质量的好坏,将直接影响到最后生成人脸图像的质量。为此本发明创新地在第一级gan采用双通道对抗生成网络(dual-channel generative adversarial network,dualgan)来提升生成的人脸图像质量,从而有效地提升后面两级gan生成人脸图像的质量。为了使得生成人脸图像更加逼近原始人脸图像,将第三级gan生成的人脸图像和对应的原始人通过图像编码器进行编码转化成特征向量,计算它们的欧式距离(euclidean metric)也即感知损失(perceptual loss),其计算方法如公式1所示,并将该损失函数反向传播到网络中,通过计算梯度下降来引导模型训练,最终有效地提升了生成的人脸图像与原始图像的相似度。
[0015][0016]
其中m为训练batch-size的值,为原始人脸图像的特征图谱,为生成人脸图像的特征图谱。
[0017]
作为步骤三网络模型参数训练,其说明如下:
[0018]
dualgan网络模型在训练过程中,需要对总损失函数和学习率等的超参数进行调整,通过实验不断地验证和调整,最后得到相对较优的超参数。
[0019]
作为步骤四网络模型性能测试,其说明如下:
[0020]
为了验证模型的性能,需要对生成的人脸进行定量和定性的评价。由于从文本生成人脸目前还没有公开的定量评价指标,根据该任务的特点,引入人脸相似度(face similarity score,fss)和人脸相似度距离(face similarity distance,fsd)来对生成的人脸进行定量评价。同时对生成的人脸与公开方法生成的人脸做了对比,其生成人脸对比结果如图3所示。
附图说明
[0021]
图1是本发明的深度对抗生成网络模型的总体原理框架图。
[0022]
图2是本发明的文本生成人脸的数据集样例。
[0023]
图3是本发明提出方法与其他方法生成人脸的对比结果。
具体实施方式
[0024]
基于基于深度对抗生成网络的文本生成人脸,主要分为四个步骤进行:数据集制作,网络模型设计,网络模型参数训练,网络模型性能测试。
[0025]
在数据集制作中,本发明基于公开人脸数据集lfw和celeba中选取1000张人脸,对其进行预处理裁减掉背景,并提取出人脸部分的图像,然后由5个不同人的对其进行独立描述,然后将这个5个描述便为该人脸的文本描述,最终分为训练集800张,测试集200张,其样例如图2所示。
[0026]
将准备好的训练数据集800张人脸及对应的文本描述输入到设计的网络模型进行训练,在训练过程不断调整总损失函数的超参数和学习率,如公式2的超参数,通过大量的实验证明,当超参数λ1=1.0,λ2=0.2和生成器的学习率为lr=0.00001时模型的性能相对较优。
[0027]
lg=l
g1
+l
g2
+l
g3
+λ1l
damsm
+λ2pl
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0028]
其中,lg为总的损失函数,l
g1
为第一级生成器的损失函数,l
g2
为第二级生成器的损失函数,l
g3
为第三级生成器的损失函数,l
damsm
为deep attentional multimodal similarity model模型计算的损失函数,pl为感知损失函数,λ1和λ2为超参数。
[0029]
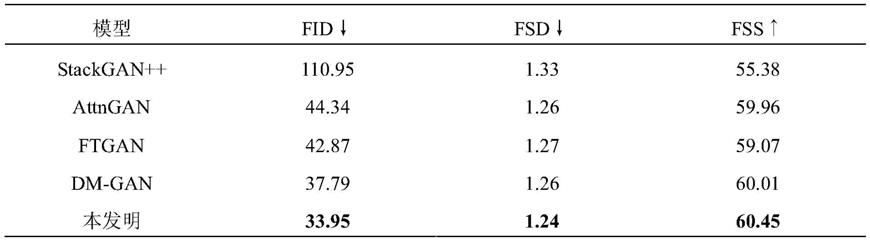
网络模型训练好后,将测试数据集200张人脸的文本描述输入到网络模型中进行人脸生成的测试,其直观定性的对比结果如图3所示,本发明设计网络模型的性能要优于其他算法,定量客观的对比结果如表1所示,与stackgan++,attngan,ftgan,dm-gan四种现有的算法相比,本发明提出的dual-gan在fr
é
chet inception distance(fid),fsd,fss三个评价指标上都达到了当前最优。
[0030]
表1生成人脸评价指标对比
[0031]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1