一种LSTM神经网络的短期负荷预测方法及系统与流程
一种lstm神经网络的短期负荷预测方法及系统
技术领域
[0001]
本发明涉及电力系统负荷预测研究领域,尤其涉及一种lstm神经网络的短期负荷预测方法及系统。
背景技术:
[0002]
负荷预测是制定电力供应计划和电网电量供需平衡的关键挑战之一,它是电力市场运营的基础工作和电力规划中不可或缺的组成部分。电力系统负荷预测可根据预测的时间长短分为超短期、短期、中期和长期预测。现有技术中,对于负荷预测对方法,多元线性回归法,其优点在于结构形式简单,预测速度快,但描述较复杂的问题时,精度较低;卡尔曼滤波法,该算法能很好的解决数据中的噪声问题,但这样也会造成变化较大的负荷也被筛选出去,对预测结果造成一定的影响;灰色理论法,该方法所需数据量少,计算方便,但未考虑到相关因素之间的联系,故误差偏大;支持向量机,其泛化能力好,预测精度较高,预测但运算时间太长,难以预测大规模数据;随机森林法,可以处理高维数据,其泛化误差小,但对于噪声较大的数据,易出现过拟合现象。
技术实现要素:
[0003]
本发明所要解决的技术问题是针对现有技术的不足,提供一种lstm神经网络的短期负荷预测方法及系统。
[0004]
本发明解决上述技术问题的技术方案如下:一种基于变分模态分解和lstm神经网络的短期负荷预测方法,包括:
[0005]
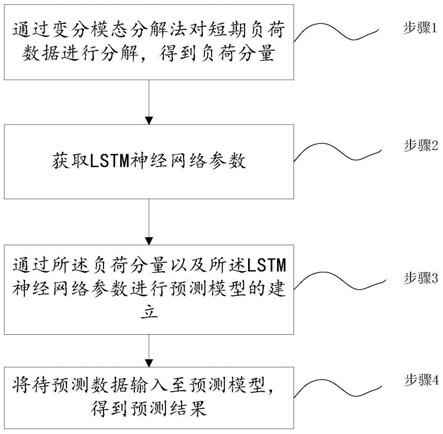
步骤1,通过变分模态分解法对短期负荷数据进行分解,得到负荷分量;
[0006]
步骤2,获取lstm神经网络参数;
[0007]
步骤3,通过所述负荷分量以及所述lstm神经网络参数进行预测模型的建立;
[0008]
步骤4,将待预测数据输入至预测模型,得到预测结果。
[0009]
本发明的有益效果是:通过对负荷数据的分解处理,并将处理后的数据与lstm结合对预测模型进行建立,不仅可以避免模态混叠现象的产生,同时可以避免得到虚假imf,且通过上述方法可以规避对预测精度产生不利的影响因素,进而有效弥补当前算法在负荷预测准确度上的不足。
[0010]
在上述技术方案的基础上,本发明还可以做如下改进。
[0011]
进一步,步骤1之前还包括:
[0012]
对负荷数据进行预处理,得到剔除问题数据后的负荷数据。
[0013]
采用上述进一步方案的有益效果是,通过预处理不仅可以减少数据处理量,提高处理效率,同时还可以有效去除杂质数据,提高数据的纯净度,进而提高预测的准确度。
[0014]
进一步,步骤2还包括:
[0015]
根据粒子群算法对所述lstm神经网络参数进行优化,得到优化后的lstm神经网络参数。
[0016]
采用上述进一步方案的有益效果是,由于lstm神经网络参数的选择对进行时间序列预测的效果有较大的影响,因此对lstm神经网络参数进行优化可以节约计算成本。
[0017]
进一步,步骤3具体为:
[0018]
通过负荷分量得到的负荷数据矩阵以及所述优化后的lstm神经网络参数进行预测模型的建立。
[0019]
采用上述进一步方案的有益效果是,通过数据矩阵以及优化后的lstm神经网络参数进行模型的建立不仅可以实现对电力负荷的预测,同时还能提高预测的精确程度,保证预测的可靠性。
[0020]
进一步,步骤4具体为:
[0021]
将待预测数据输入至所述预测模型中,对待预测数据进行重构,得到预测结果。
[0022]
本发明解决上述技术问题的另一种技术方案如下:一种基于变分模态分解和lstm神经网络的短期负荷预测系统,包括:
[0023]
分解模块,用于通过变分模态分解法对短期负荷数据进行分解,得到负荷分量;
[0024]
获取模块,用于获取lstm神经网络参数;
[0025]
建立模块,用于通过所述负荷分量以及所述lstm神经网络参数进行预测模型的建立;
[0026]
预测模块,用于将待预测数据输入至预测模型,得到预测结果。
[0027]
本发明的有益效果是:通过对负荷数据的分解处理,并将处理后的数据与lstm结合对预测模型进行建立,不仅可以避免模态混叠现象的产生,同时可以避免得到虚假imf,且通过上述方法可以规避对预测精度产生不利的影响因素,进而有效弥补当前算法在负荷预测准确度上的不足。
[0028]
进一步,分解模块之前还包括:
[0029]
预处理模块,用于对负荷数据进行预处理,得到剔除问题数据后的负荷数据。
[0030]
采用上述进一步方案的有益效果是,通过预处理不仅可以减少数据处理的量,提高处理效率,同时还可以有效去除杂质数据,提高数据的纯净度,进而提高预测的准确度。
[0031]
进一步,获取模块具体用于:
[0032]
根据粒子群算法对所述lstm神经网络参数进行优化,得到优化后的lstm神经网络参数。
[0033]
采用上述进一步方案的有益效果是,由于lstm神经网络参数的选择对其进行时间序列预测的效果有较大的影响,因此对lstm神经网络参数进行优化可以节约计算成本。
[0034]
进一步,建立模块具体用于:
[0035]
通过负荷分量得到的负荷数据矩阵以及所述优化后的lstm神经网络参数进行预测模型的建立。
[0036]
采用上述进一步方案的有益效果是,通过数据矩阵以及优化后的lstm神经网络参数进行模型的建立不仅可以实现对电力负荷的预测,同时还能提高预测的精确程度,保证预测的可靠性
[0037]
进一步,预测模块具体用于:
[0038]
将待预测数据输入至所述预测模型中,对待预测数据进行重构,得到预测结果。
[0039]
本发明附加的方面的优点将在下面的描述中部分给出,部分将从下面的描述中变
得明显,或通过本发明实践了解到。
附图说明
[0040]
图1为本发明一种基于变分模态分解和lstm神经网络的短期负荷预测方法的实施例提供的流程示意图;
[0041]
图2为本发明一种基于变分模态分解和lstm神经网络的短期负荷预测系统的实施例提供的结构框架图。
[0042]
附图中,各标号所代表的部件列表如下:
[0043]
100、分解模块,200、获取模块,300、建立模块,400、预测模块。
具体实施方式
[0044]
以下结合附图对本发明的原理和特征进行描述,所举实施例只用于解释本发明,并非用于限定本发明的范围。
[0045]
如图1所示,一种基于变分模态分解和lstm神经网络的短期负荷预测方法,包括:
[0046]
步骤1,通过变分模态分解法对短期负荷数据进行分解,得到负荷分量;
[0047]
步骤2,获取lstm神经网络参数;
[0048]
步骤3,通过负荷分量以及lstm神经网络参数进行预测模型的建立;
[0049]
步骤4,将待预测数据输入至预测模型,得到预测结果。
[0050]
在一些可能的实施方式中,通过对负荷数据的分解处理,并将处理后的数据与lstm结合对预测模型进行建立,不仅可以避免模态混叠现象的产生,同时可以避免得到虚假imf,且通过上述方法可以规避对预测精度产生不利的影响因素,进而有效弥补当前算法在负荷预测准确度上的不足。
[0051]
需要说明的是,本发明主要采用vmd方法对负荷数据进行分解,得到一系列有利于预测的负荷分量,针对预测模型的建立,采用vmd方法对历史数据分解得到的负荷数据矩阵,以及lstm网络参数进行模型的训练。基于训练完成的模型即可实现待预测日模式分量的预测,对待预测日的各预测分量进行重构,即可得到待预测日的负荷预测结果,其中,关于负荷序列分解,电力负荷基于用户习惯性消费信息,受人类活动、气象条件、社会经济和政治因素等不同程度的影响表现出一定的波动性、随机性的特点,为精细研究分析负荷序列特点,本发明采用vmd方法对原始负荷序列进行分解,得到一系列有利于预测的负荷分量。vmd方法适合用于非平稳信号的自适应分解,可将复杂的信号分解成k个调频调幅的子信号。其本质为一个自适应维纳滤波器组,可以有效地将测试信号分解成一组有限带宽的中心频率。vmd方法需要设置的参数包括模态函数的个数k、二次惩罚因子α、收敛判据r、以及起始中心频率w。在此参数的组合下,对m天的历史数据进行分解。其中,第d日的负荷序列可由vmd方法分解为k个模态分量,各模态分量可组成集合对于m天的历史负荷数据,每日分解得到的第q个模态分量可以组成分解负荷数据矩阵具体实施过程可参考实施例1。
[0052]
优选地,在上述任意实施例中,步骤1之前还包括:
[0053]
对负荷数据进行预处理,得到剔除问题数据后的负荷数据。
[0054]
在一些可能的实施方式中,通过预处理不仅可以减少数据处理的量,提高处理效率,同时还可以有效去除杂质数据,提高数据的纯净度,进而提高预测的准确度。
[0055]
需要说明的是,由于受负荷数据采集、传输和存贮的影响,负荷的历史数据中存在一定的异常数据,会对预测模型的训练造成影响。本发明在此步骤中对负荷的历史数据进行搜索,定位存在数据点缺失、恒值等情况的日数据,并对其进行剔除。
[0056]
优选地,在上述任意实施例中,步骤2还包括:
[0057]
根据粒子群算法对lstm神经网络参数进行优化,得到优化后的lstm神经网络参数。
[0058]
在一些可能的实施方式中,由于lstm神经网络参数的选择对其进行时间序列预测的效果有较大的影响,因此对lstm神经网络参数进行优化可以节约计算成本。
[0059]
需要说明的是,lstm神经网络参数的选择对其进行时间序列预测的效果有较大的影响,其中最为主要的包括堆叠层数sl参数和隐含层神经元个数hn参数。此外,在lstm神经网络训练的过程中dropout参数d的设定,以及每批处理样本数量b的选择对负荷预测精度均有着显著的影响,若按照网格搜索算法进行参数的优化,其计算成本和时间成本较高,因此,本方法中采用粒子群算法对lstm网络的参数进行优化。
[0060]
粒子群算法即粒子群优化算法,是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法,其核心思想是利用群体中的个体对信息的共享从而使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的最优解。在本研究的方法中,lstm网络基于历史训练集数据进行虚拟预测的平均百分比精度为适应度函数,粒子适应度的计算公式如下。
[0061][0062]
式中,为预测值;y
i
为实际值,n为样本数量。
[0063]
以上述四个参数组成的参数向量x=[sl,hn,d,b]为优化变量进行寻优,最后还原寻优后的最优个体x
opt
,得到优化后的适应于该地区负荷特点的四个lstm网络参数sl
opt
、hn
opt
、d
opt
以及b
opt
。
[0064]
优选地,在上述任意实施例中,步骤3具体为:
[0065]
通过负荷分量得到的负荷数据矩阵以及优化后的lstm神经网络参数进行预测模型的建立。
[0066]
在一些可能的实施方式中,通过数据矩阵以及优化后的lstm神经网络参数进行模型的建立不仅可以实现对电力负荷的预测,同时还能提高预测的精确程度,保证预测的可靠性。
[0067]
需要说明的是,基于vmd方法对历史数据分解得到的负荷数据矩阵采用优化得到的lstm网络参数进行模型的训练,采用负荷数据矩阵训练完成的神经网络记为lstm
q
,共计得到k个训练完成的预测模型。
[0068]
优选地,在上述任意实施例中,步骤4具体为:
[0069]
将待预测数据输入至预测模型中,对待预测数据进行重构,得到预测结果。
[0070]
需要说明的是,基于训练完成的lstm
q
模型即可实现待预测日第q个模式分量的预
测,预测结果记为对待预测日的各预测分量进行重构,即可得到待预测日的负荷预测结果重构方法的具体公式如下:
[0071][0072]
如图2所示,一种基于变分模态分解和lstm神经网络的短期负荷预测系统,包括:
[0073]
分解模块100,用于通过变分模态分解法对短期负荷数据进行分解,得到负荷分量;
[0074]
获取模块200,用于获取lstm神经网络参数;
[0075]
建立模块300,用于通过负荷分量以及lstm神经网络参数进行预测模型的建立;
[0076]
预测模块400,用于将待预测数据输入至预测模型,得到预测结果。
[0077]
在一些可能的实施方式中,通过对负荷数据的分解处理,并将处理后的数据与lstm结合对预测模型进行建立,不仅可以避免模态混叠现象的产生,同时可以避免得到虚假imf,且通过上述方法可以规避对预测精度产生不利的影响因素,进而有效弥补当前算法在负荷预测准确度上的不足。
[0078]
需要说明的是,本发明主要采用vmd方法对负荷数据进行分解,得到一系列有利于预测的负荷分量,针对预测模型的建立,采用vmd方法对历史数据分解得到的负荷数据矩阵,以及lstm网络参数进行模型的训练。基于训练完成的模型即可实现待预测日模式分量的预测,对待预测日的各预测分量进行重构,即可得到待预测日的负荷预测结果,其中,关于负荷序列分解,电力负荷基于用户习惯性消费信息,受人类活动、气象条件、社会经济和政治因素等不同程度的影响表现出一定的波动性、随机性的特点,为精细研究分析负荷序列特点,本发明采用vmd方法对原始负荷序列进行分解,得到一系列有利于预测的负荷分量。vmd方法适合用于非平稳信号的自适应分解,可将复杂的信号分解成k个调频调幅的子信号。其本质为一个自适应维纳滤波器组,可以有效地将测试信号分解成一组有限带宽的中心频率。vmd方法需要设置的参数包括模态函数的个数k、二次惩罚因子α、收敛判据r、以及起始中心频率w。在此参数的组合下,对m天的历史数据进行分解。其中,第d日的负荷序列可由vmd方法分解为k个模态分量,各模态分量可组成集合对于m天的历史负荷数据,每日分解得到的第q个模态分量可以组成分解负荷数据矩阵具体实施过程可参考实施例1。
[0079]
优选地,在上述任意实施例中,分解模块之前还包括:
[0080]
预处理模块,用于对负荷数据进行预处理,得到剔除问题数据后的负荷数据。
[0081]
在一些可能的实施方式中,通过预处理不仅可以减少数据处理的量,提高处理效率,同时还可以有效去除杂质数据,提高数据的纯净度,进而提高预测的准确度。
[0082]
需要说明的是,由于受负荷数据采集、传输和存贮的影响,负荷的历史数据中存在一定的异常数据,会对预测模型的训练造成影响。本发明在此步骤中对负荷的历史数据进行搜索,定位存在数据点缺失、恒值等情况的日数据,并对其进行剔除。
[0083]
优选地,在上述任意实施例中,获取模块200具体用于:
[0084]
根据粒子群算法对所述lstm神经网络参数进行优化,得到优化后的lstm神经网络
参数。
[0085]
在一些可能的实施方式中,由于lstm神经网络参数的选择对其进行时间序列预测的效果有较大的影响,因此对lstm神经网络参数进行优化可以节约计算成本。
[0086]
需要说明的是,lstm神经网络参数的选择对其进行时间序列预测的效果有较大的影响,其中最为主要的包括堆叠层数sl参数和隐含层神经元个数hn参数。此外,在lstm神经网络训练的过程中dropout参数d的设定,以及每批处理样本数量b的选择对负荷预测精度均有着显著的影响,若按照网格搜索算法进行参数的优化,其计算成本和时间成本较高,因此,本方法中采用粒子群算法对lstm网络的参数进行优化。
[0087]
粒子群算法即粒子群优化算法,是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法,其核心思想是利用群体中的个体对信息的共享从而使整个群体的运动在问题求解空间中产生从无序到有序的演化过程,从而获得问题的最优解。在本研究的方法中,lstm网络基于历史训练集数据进行虚拟预测的平均百分比精度为适应度函数,粒子适应度的计算公式如下。
[0088][0089]
式中,为预测值;y
i
为实际值,n为样本数量。
[0090]
以上述四个参数组成的参数向量x=[sl,hn,d,b]为优化变量进行寻优,最后还原寻优后的最优个体x
opt
,得到优化后的适应于该地区负荷特点的四个lstm网络参数sl
opt
、hn
opt
、d
opt
以及b
opt
。
[0091]
优选地,在上述任意实施例中,建立模块300具体用于:
[0092]
通过负荷分量得到的负荷数据矩阵以及优化后的lstm神经网络参数进行预测模型的建立。
[0093]
在一些可能的实施方式中,通过数据矩阵以及优化后的lstm神经网络参数进行模型的建立不仅可以实现对电力负荷的预测,同时还能提高预测的精确程度,保证预测的可靠性。
[0094]
需要说明的是,基于vmd方法对历史数据分解得到的负荷数据矩阵采用优化得到的lstm网络参数进行模型的训练,采用负荷数据矩阵训练完成的神经网络记为lstm
q
,共计得到k个训练完成的预测模型。
[0095]
优选地,在上述任意实施例中,预测模块400具体用于:
[0096]
将待预测数据输入至预测模型中,对待预测数据进行重构,得到预测结果。
[0097]
需要说明的是,基于训练完成的lstm
q
模型即可实现待预测日第q个模式分量的预测,预测结果记为对待预测日的各预测分量进行重构,即可得到待预测日的负荷预测结果重构方法的具体公式如下:
[0098][0099]
实施例1,选用某地区2019年6月16日至6月30日之间的负荷数据,采样间隔15min,共计采样点1440个,以前面12天的数据作为训练样本,即m取值为3,后面3天的数据作为测
试样本。vmd方法中k取值为5,二次惩罚因子α取值为1000,收敛判据r取值为10-6,起始中心频率w取值为0。经过粒子群算法优化后,得到lstm网络优化后的参数向量取值为x
opt
=[2,50,0.65,16]。采用当前常用方法中的lstm模型、emd-lstm模型以及本研究提出的基于vmd方法和lstm神经网络的负荷预测模型进行对比,基于平均绝对百分误差(mean absolute percentage error,mape)来评估模型优劣,mape指标的计算公式如下:
[0100][0101]
式中,为预测值;y
i
为实际值,n为样本数量。
[0102]
从待预测日的mape误差指标平均值角度分析,vmd-lstm方法的三天平均mape为0.62%,emd-lstm方法的三天平均mape为0.79%,lstm模型三天平均mape为1.49%,本研究提出的方法具有更低的准确率,验证了该方法的优越性。
[0103]
可以理解,在一些实施例中,可以包含如上述各实施例中的部分或全部可选实施方式。
[0104]
需要说明的是,上述各实施例是与在先方法实施例对应的产品实施例,对于产品实施例中各可选实施方式的说明可以参考上述各方法实施例中的对应说明,在此不再赘述。
[0105]
上述方法如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分,或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0106]
以上,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1