面向边缘网络的分布式神经网络协同优化方法与流程
本发明涉及了一种面向边缘网络的分布式神经网络协同优化方法,属于计算机人工智能领域。
背景技术:
深度神经网络(dnn)的最新进展大大提高了计算机视觉和视频分析的准确性和速度,为新一代智能应用创造了新的途径。云计算技术的成熟,加上tpu、gpu等功能强大的硬件,成为此类计算密集型dnn任务的典型选择。例如,在一个自动驾驶汽车应用程序中,摄像头连续监控周围的场景并将其传输到服务器,然后服务器进行视频分析并将控制信号反馈给踏板和方向盘。在增强现实应用程序中,智能玻璃不断记录当前视图并将信息流传输到云服务器,而云服务器执行对象识别并发回上下文增强标签,以便无缝显示在实际场景上。
实现智能应用的一个障碍是视频流的大量数据量。例如,谷歌的自动驾驶汽车每秒可产生高达750兆字节的传感器数据,但现有最快解决方案4g的平均上行链路速率仅为5.85mbps。当用户快速移动或网络负载重时,数据速率显著降低。为了避免网络的影响,将计算放在数据源附近,边缘计算应运而生。作为一种无网络的方法,它提供随时随地可用的计算资源。例如,awsdeeplens相机可以运行深卷积神经网络(cnns)来分析视觉图像。然而,边缘设备本身受到计算能力和能量的限制,边缘设备通常不能完全支持推理计算的大工作量。
dnn的协作计算,它是将dnn划分到不同的层,然后在多个异构设备上分配分区,以形成分布式dnn(d-dnn)。通过这种方式,可以充分利用边缘设备中的本地资源来运行dnn分区。此外,由于保留了dnn架构,因此不会牺牲准确性。
技术实现要素:
本发明所要解决的技术问题是针对当前单个边缘设备不能完全支持处理整个深度神经网络的情况,提出一种面向边缘网络的分布式神经网络协同优化方法。
本发明为解决上述技术问题采用以下技术方案:
本发明提出一种面向边缘网络的分布式神经网络协同优化方法,具体包括以下步骤:
步骤一、将神经网络通过建模得到有向图gn;
步骤二、将边缘设备部署图映射成相应的边缘网络图ge;
步骤三、将步骤一中得到的有向图gn和步骤二中得到的边缘网络ge,通过建模得到特定的辅助图gd;
步骤四、在步骤三中得到的辅助图gd上找到迭代中的最小s-t割集;其中,在gd上切割一组边使得源点s和汇点t被分割在两个不相交的集合中,这组边构成的集合就是s-t割集c;s-t的值就是集合中所有边的权重之和;
步骤五、根据步骤四得到的最小s-t割集,得到该s-t割集对应的面向边缘网络的分布式神经网络协同计算策略;
步骤一的具体步骤包括:
步骤1.1、对于一个具有n层的神经网络架构,将其中每一层神经网络li映射成有向图gn中的一个节点vi;
步骤1.2、将具有计算依赖性的li层和lj层神经网络对应的节点vi和vj相连,其中若是先计算li层再计算lj层,那么构造由vi指向vj的边(vi,vj),反之,构造边(vj,vi);
步骤二的具体步骤包括:
步骤2.1、将边缘设备部署图映射成相应的边缘网络图ge=(u,l);
其中u表示边缘节点集合u={u1,...,ul},l表示边缘网络图中的边集;
令(ui,uj)∈l代表边缘节点ui和uj互相直接通信;
令d(ui,uj)表示边缘节点ui和uj之间的通信延迟;如果边缘节点ui和uj在ge中不是邻居节点,那么令d(ui,uj)表示边缘节点ui和uj在ge上的最短通信延迟;
步骤2.2、对于一个神经网络,假设它的所有网络层可以在ge上的任意边缘节点上进行计算,则:
令σ(vi)=uj表示神经网络节点vi被分配到了边缘节点uj上进行计算;则σ表示所有神经网络层在ge上进行计算的分配方案;对于神经网络层vi∈v,令它在边缘节点ui∈u上的计算时间用
如果两个相邻的神经网络层vi和vj被分配到同一个边缘节点uk上进行计算,则忽略这两者之间的通信延迟;否则,vi和vj之间的通信延迟被设置成vi和vj对应的边缘节点σ(vi)和σ(vj)之间的通信延迟;
步骤2.3、定义所有神经网络层分配到边缘网络之后进行协同计算所需要的时间tn;
其中,tn(σ,gn)表示对于图gn在σ映射下的总延迟;
步骤三的具体步骤包括:
步骤3.1、对于初始分配σ,以
步骤3.2、在步骤3.1的初始分配σ的前提下构造图gd=(wd,εd);图gd的结点集wd,边集εd;步骤3.2的步骤包括:
步骤3.2.1、对于每一层神经网络vi∈v,在图gd的结点集wd中添加对应节点wi;将节点wi分别与源点s和汇点t相连得到边集合ε1中的边(s,wi)和(wi,t);如果
步骤3.2.2、对于有向图gn的每条边(vi,vj),创建其对应的水平边;
步骤四的具体步骤包括:
步骤4.1、对于神经网络层vi,如果辅助图gd中的一个割c经过了边(s,wi),则将神经网络层vi分配到边缘节点ui上进行计算;如果割c经过了边(wi,t),那么神经网络层vi的分配策略保持不变;得到割c的新分配方案σ';
步骤4.2、令uk是边缘节点集合u中的第k个节点,1≤k≤|u|;
步骤4.3、对于边缘节点uk∈u,利用最大流最小割的方法得到当前的最小割cmin;根据最小割cmin和步骤4.1得到σ',σ'表示cmin对应的分配方案;如果σ'的代价小于σ,那么就令σ=σ',u=u\{uk};
步骤4.4、重复步骤4.2和4.3,直到u=φ,即u中的节点为空;
步骤4.5、根据步骤4.1~4.4,得到最终的σ';
所述步骤五中,以步骤四得到最终σ'对应的分布式神经网络为最优的分布式神经网络;
步骤3.2.2中,包括四种不同情况:
情况一:如果σ(vi)=σ(vj)=uk,即神经网络层vi和vj都分配到边缘节点uk上进行计算,那么wi和wj之间没有水平边;
情况二:如果在神经网络层vi和vj中只有一个被分配到边缘节点uk上进行计算,那么创建边(wi,wj),并设置其权重为c(wi,wj)=d(σ(vi),σ(vj));
情况三:如果神经网络层vi和vj被分配到了两个不同的边缘节点上进行计算,且σ(vi)≠uk,σ(vj)≠uk,即这两个边缘节点都不是uk,则在wi和wj之间创建一个辅助节点o(wi,wj);将o(wi,wj)分别和wi、wj创建双向边(wi,o(wi,wj))和(o(wi,wj),wj),同时设置它们的权重分别为c(wi,o(wi,wj))=d(σ(vi),uk),c(o(wi,wj),wj)=d(uk,σ(vj));将节点o(wi,wj)和汇点t相连创建第三条边(o(wi,wj),t),同时设置它的权重是c(o(wi,wj),t)=d(σ(vi),σ(vj));
情况四:如果神经网络层vi和vj都被分配到同一个边缘节点um上进行计算,且uk≠um,则创建边(wi,wj),同时设置它的权重为c(wi,wj)=d(uk,um)。
本发明采用以上技术方案与现有技术相比,具有以下优点:
1.将单个深度神经网络分配到多个边缘设备上进行计算处理。对分割单个神经网络得到的多个子任务根据各边缘设备的计算资源、处理性能等属性进行分配,能有效减少计算整个神经网络的总延迟。
2.本发明针对边缘网络提出了高效分布式神经网络协同计算方法。对于边缘网络和神经网络通过利用图理论构造辅助图最终得到高效的分布式协同计算方案。
附图说明
图1是本发明整体的流程图
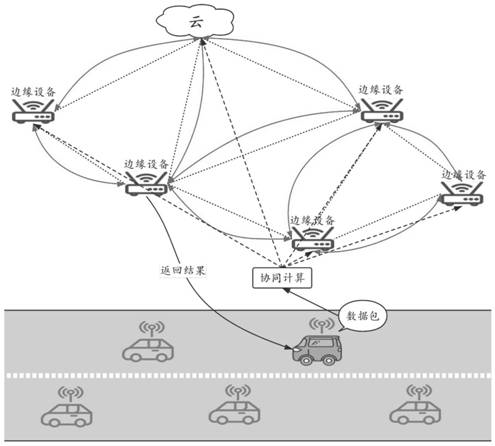
图2是本发明的应用场景示意图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本技术领域技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
在以上条件之下,对于边缘网络找到高效的分布式神经网络协同优化方法的步骤如图1所示。具体包括以下步骤:
步骤一、将神经网络通过建模得到有向图gn;
步骤1.1、对于一个具有n层的神经网络架构,将其中每一层神经网络li映射成有向图gn中的一个节点vi;
步骤1.2、将具有计算依赖性的li层和lj层神经网络对应的节点vi和vj相连,其中若是先计算li层再计算lj层,那么构造由vi指向vj的边(vi,vj),反之,构造边(vj,vi);
步骤二、将边缘设备部署图映射成相应的边缘网络图ge;
步骤2.1、将边缘设备部署图映射成相应的边缘网络图ge=(u,l);
其中u表示边缘节点集合u={u1,...,ul},l表示边缘网络图中的边集;
令(ui,uj)∈l代表边缘节点ui和uj互相直接通信;
令d(ui,uj)表示边缘节点ui和uj之间的通信延迟;如果边缘节点ui和uj在ge中不是邻居节点,那么令d(ui,uj)表示边缘节点ui和uj在ge上的最短通信延迟;
步骤2.2、对于一个神经网络,假设它的所有网络层可以在ge上的任意边缘节点上进行计算,则:
令σ(vi)=uj表示神经网络节点vi被分配到了边缘节点uj上进行计算;则σ表示所有神经网络层在ge上进行计算的分配方案;对于神经网络层vi∈v,令它在边缘节点ui∈u上的计算时间用
如果两个相邻的神经网络层vi和vj被分配到同一个边缘节点uk上进行计算,则忽略这两者之间的通信延迟;否则,vi和vj之间的通信延迟将会被设置成vi和vj对应的边缘节点σ(vi)和σ(vj)之间的通信延迟;
步骤2.3、定义所有神经网络层分配到边缘网络之后进行协同计算所需要的时间tn;
其中,tn(σ,gn)表示对于图gn在σ映射下的总延迟;
步骤三、将步骤一中得到的有向图gn和步骤二中得到的边缘网络ge,通过建模得到特定的辅助图gd;
步骤3.1、对于初始分配σ,以ruk表示分配到边缘节点uk进行计算的神经网络层的集合;
步骤3.2、在步骤3.1的初始分配σ的前提下构造图gd=(wd,εd);图gd的结点集wd,边集εd;步骤3.2的步骤包括:
步骤3.2.1、对于每一层神经网络vi∈v,在图gd的结点集wd中添加对应节点wi;将节点wi分别与源点s和汇点t相连得到边集合ε1中的边(s,wi)和(wi,t);如果
步骤3.2.2、对于有向图gn的每条边(vi,vj),创建其对应的水平边;
步骤3.2.2中,包括四种不同情况:
情况一:如果σ(vi)=σ(vj)=uk,即神经网络层vi和vj都分配到边缘节点uk上进行计算,那么wi和wj之间没有水平边;
情况二:如果在神经网络层vi和vj中只有一个被分配到边缘节点uk上进行计算,那么创建边(wi,wj),并设置其权重为c(wi,wj)=d(σ(vi),σ(vj));
情况三:如果神经网络层vi和vj被分配到了两个不同的边缘节点上进行计算,且σ(vi)≠uk,σ(vj)≠uk,即这两个边缘节点都不是uk,则在wi和wj之间创建一个辅助节点o(wi,wj);将o(wi,wj)分别和wi、wj创建双向边(wi,o(wi,wj))和(o(wi,wj),wj),同时设置它们的权重分别为c(wi,o(wi,wj))=d(σ(vi),uk),c(o(wi,wj),wj)=d(uk,σ(vj));将节点o(wi,wj)和汇点t相连创建第三条边(o(wi,wj),t),同时设置它的权重是c(o(wi,wj),t)=d(σ(vi),σ(vj));
情况四:如果神经网络层vi和vj都被分配到同一个边缘节点um上进行计算,且uk≠um,则创建边(wi,wj),同时设置它的权重为c(wi,wj)=d(uk,um);
步骤四、在步骤三中得到的辅助图gd上找到迭代中的最小s-t割集;其中,在gd上切割一组边使得源点s和汇点t被分割在两个不相交的集合中,这组边构成的集合就是s-t割集c;s-t的值就是集合中所有边的权重之和;
步骤4.1、对于神经网络层vi,如果辅助图gd中的一个割c经过了边(s,wi),则将神经网络层vi分配到边缘节点ui上进行计算;如果割c经过了边(wi,t),那么神经网络层vi的分配策略保持不变;得到割c的新分配方案σ';
步骤4.2、令uk是边缘节点集合u中的第k个节点,1≤k≤|u|;
步骤4.3、对于边缘节点uk∈u,利用最大流最小割的方法得到当前的最小割cmin;根据最小割cmin和步骤4.1得到σ',σ'表示cmin对应的分配方案;如果σ'的代价小于σ,那么就令σ=σ',u=u\{uk};
步骤4.4、重复步骤4.2和4.3,直到u=φ,即u中的节点为空;
步骤4.5、根据步骤4.1~4.4,得到最终的σ';
所述步骤五中,以步骤四得到最终σ'对应的分布式神经网络为最优的分布式神经网络。
在本发明应用场景中,以智能交通为例,在自动驾驶应用程序中,车辆首先收集视频流和传感信息的现场数据,之后将收集的数据输入深度神经网络框架进行推理计算。针对当前单个边缘设备不能完全支持处理整个深度神经网络的情况,我们可以利用本发明解决。如图2所示,云端和多个边缘设备构成了一个云-边缘网络,车辆将数据包发送给该云-边缘网络并利用本发明中提出的算法得到高效的分布式神经网络协同计算策略,经过协同计算后,边缘设备将决策结果返回给车辆。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!