面向反应堆堆芯组件数值模拟的有限元撕裂对接法及系统
本发明涉及有限元撕裂对接过程处理技术,特别涉及一种面向反应堆堆芯组件数值模拟的有限元撕裂对接法及系统。
背景技术:
核反应堆里的堆芯组件,在高温、辐照、流体、压力等环境下,会出现堆芯组件变形和燃料棒磨损的情况,从而导致装卸料困难,组件破损、疲劳损伤等一系列问题,影响反应堆的安全运行。又由于堆芯组件排列特殊等问题,理论分析方法十分困难,所以需要采用有限元法对其进行数值模拟。
有限元撕裂对接法(finitetearingandinterconnectingddmethod,feti)是求解反应堆结构力学问题的有效方案,主要用于处理偏微分方程离散化得到的大规模问题,是堆芯组件大规模数值模拟所需的重要方法,同样也适用于电磁学、航空技术和机械制造等领域。有限元撕裂对接法最初是由c.farhart和f.x.roux在结构力学领域提出,它是一种非重叠的区域分解方法,将一个模型划分为许许多多的非重叠子域,并且每个子域都是独立的。为了保证子域之间的连续性,feti方法增加了一组未知量(拉格朗日乘子lm),在实际求解的时候,一般先采用krylov子空间迭代法求得lm,然后在每个子域内求解子域方程。
然而,原始feti方法的计算效率不高。为了解决这个问题,farhat等人在2001年提出了feti-dp方法(adual–primalunifiedfetimethod),它不再需要第二组拉格朗日乘数,并将以前开发的所有一层和两层feti方法统一为一个单一的双重对偶。feti-dp比feti方法更健壮,计算效率更高,适用于求解二阶和四阶问题。2006年,dost′al等人提出了tfeti方法(totalfeti)。该方法是feti方法的变体,其中dirichlet边界条件也和lm(拉格朗日乘数)相互关联,然而粗略问题仍然是制约feti方法可扩展性的重要因素。
为了减少粗略问题的影响,提高可扩展性,klawonn和rheinbach等人在2010年提出了hfeti方法(hybridfetimethod)。该方法结合了feti方法和feti-dp方法,将许多子域聚集到一个群集中,可以看作是三级区域分解方法。首先需要建立一个feti-dp系统来处理所有群集。然后每个群集由多个子域组成,需要使用传统的feti方法来处理每个群集中的子域。同样,在2012年,kozubek等人提出了类似的方法——htfeti方法(hybridtotalfetimethod)。该方法结合了feti方法和tfeti方法,将tfeti方法用于每个群集中的子域,将带有投影的feti方法用于群集。htfeti方法能够有效的降低粗略问题。
然而,在feti的迭代求解中,稀疏矩阵向量操作消耗了大量的时间,因此riha等人在2016年提出了lsc方法(localschurcomplementmethod),将稀疏矩阵向量操作使用更高效的稠密矩阵向量乘法(gemv)代替,相当于一个以空间换时间的策略。这种稠密的blas2级操作具有连续的内存访问权限,因此对于受内存限制的应用程序具有更好的性能。同时,稠密矩阵向量乘适合用gpu加速器来处理。因此vavrik等人在2018年使用cuda编程将稠密矩阵向量乘交由gpu处理。
然而目前的有限元撕裂对接方法,仍然存在下列问题迫切需要解决的问题:1)目前已知的支持异构并行的有限元撕裂对接求解器使用的是cuda编程,然而使用cuda编程实现的求解器只能在nvidiacuda平台上运行,不支持其它类型的gpu加速器;2)当采用gpu计算稠密矩阵向量乘的时候,cpu处于空闲状态,没有充分利用集群的计算资源;3)在实际进行反应堆堆芯组件数值模拟的时候,各进程组装的稠密矩阵内存大小相差很大,甚至计算时间和内存大小相差达6倍,这使得计算量少的进程花了大量时间在等待别的进程,增加了求解时间。
技术实现要素:
本发明的一个目的是解决现有有限元撕裂对接法存在的问题,提出一种面向反应堆堆芯组件数值模拟的有限元撕裂对接系统,充分利用集群资源,加快求解速度,减少通信等待时间,提高可移植性。
一种面向反应堆数值模拟的有限元撕裂对接系统,包括输入模块、区域划分模块、矩阵组装模块、资源收集模块、负载均衡模块、迭代求解模块、本地求解模块。
所述的输入模块,用于获取网格文件数据,并进行初始化参数设置。
所述的区域划分模块,用于对网格划分为多个区域,并对每个区域划分为多个子区域。
所述的矩阵组装模块,用于在各子区域生成对应的有限元矩阵。
所述的资源收集模块,用于收集各进程的稠密矩阵大小信息,并进行占有内存比较。
所述的负载均衡模块,用于调用负载均衡策略,对各进程的稠密矩阵进行重分配。
所述的迭代求解模块,用于采用现有迭代方法求解各区域边界节点的位移;并调用向量内积加速策略和通信计算重叠策略。
所述的本地求解模块,用于求解各区域内部节点的位移。
n个计算节点中每个计算节点均设有上述有限元撕裂对接系统,每个计算节点拥有g块类gpu加速器。
本发明的另一个目的是提供一种面向反应堆堆芯组件数值模拟的有限元撕裂对接方法,具体步骤如下:
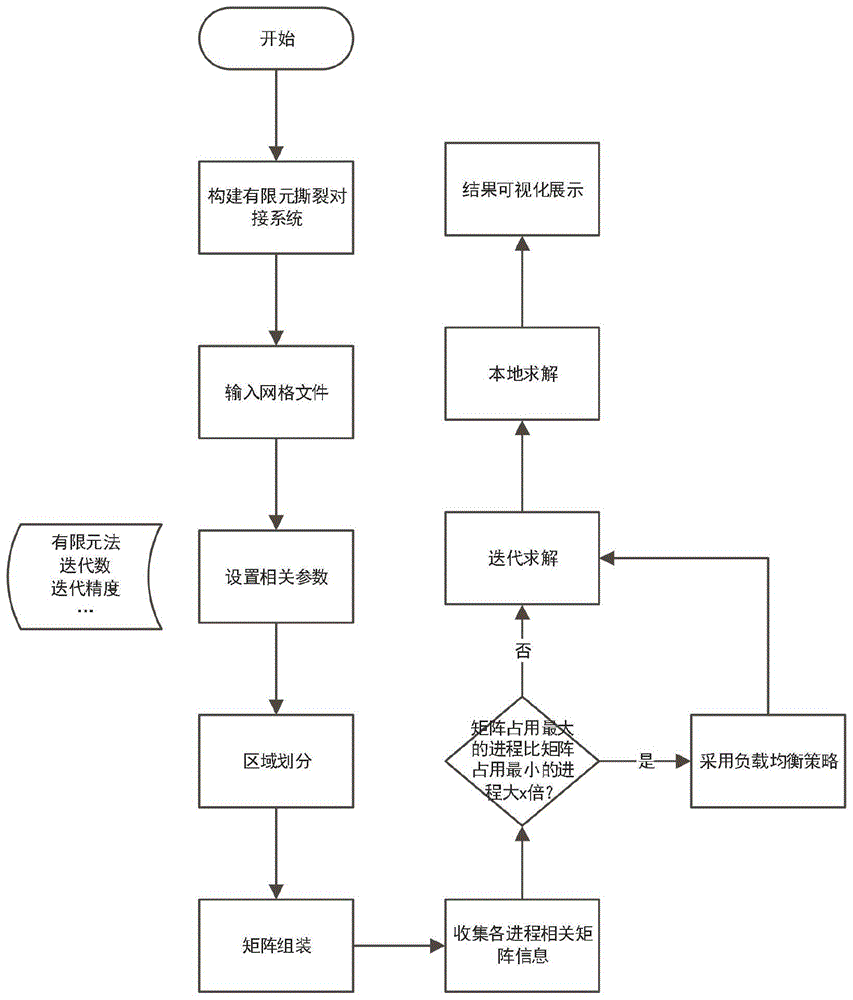
步骤1:获取反应堆堆芯组件的几何模型数据,并将几何模型数据通过现有软件进行网格划分,生成网格文件。
步骤2:每个计算节点通过输入模块获取反应堆堆芯组件的网格文件,初始化相关参数:有限元方法、迭代方法、最大迭代数、迭代精度、堆芯组件材料参数、堆芯组件边界条件等。
所述的有限元方法可以为feti或者htfeti。
步骤3:n个计算节点中每个计算节点开启g个进程,每个进程开启t个线程,通过区域划分模块将输入模块获取的网格划分为g*n个区域,每个区域分配一个进程;同时每个区域进一步划分为s个子区域。
步骤4:各进程根据分配到的区域以及选用的有限元方法,通过矩阵组装模块在各个子域生成对应的有限元矩阵,每个子域均会生成一个稠密矩阵。因此,每个进程会生成s个稠密矩阵。
步骤5:利用资源收集模块收集各进程的稠密矩阵信息,进程i的稠密矩阵占用内存大小为li,令lmin=min{l1,l2,l3...ln*g},lmax=max{l1,l2,l3...ln*g}。如果
步骤6:通过负载均衡模块启用负载均衡策略,将各进程的矩阵占用内存大小,都调整至平均值附近,具体是:
6-1根据各进程的稠密矩阵内存大小,计算出稠密矩阵平均内存大小;
6-2将各进程的稠密矩阵内存大小与平均值相比较,如果大于平均值,则认为该进程的计算量较大,需要别的进程帮助,设为被帮助者;如果小于平均值,则认为该进程的计算量较小,可以帮助别的进程,设为帮助者;
6-3将进程分为两组,帮助者为一组,被帮助者为一组,对每一组按照稠密矩阵内存大小排序,对应选出一个帮助者与一个被帮助者;
6-4被帮助者发送1个稠密矩阵给帮助者;
6-5重复步骤6-4直到当前被帮助者的稠密矩阵内存小于平均值,然后换下一个被帮助者,或者帮助者的稠密矩阵内存大于平均值,然后换下一个帮助者,进入步骤6-4;
6-6重复步骤6-4至6-5,直到所有被帮助者的内存均小于平均值,或者所有帮助者的稠密矩阵内存大于平均值。
步骤7:通过迭代求解模块,使得各进程进行迭代求解,在迭代求解的每一步迭代中向量内积运算采用向量内积加速策略和通信计算重叠策略,稠密矩阵向量乘采用hip(异构计算可移植接口)编程使其在类gpu加速器上计算,并采用动态矩阵分配策略。
所述的向量内积加速策略为多线程并行求解各进程的局部向量内积。
所述的通信计算重叠策略为每个进程使用1个线程用于通信,其余t-1个线程继续参与局部向量内积计算,其中通信线程完成通信后再参与到局部向量内积计算。
所述的动态分配矩阵策略具体是在进行稠密矩阵向量乘时,各进程使用1个线程调用hipblas库,使用一块类gpu加速器进行稠密矩阵向量乘计算,其余t-1个线程调用intelmkl库,使用cpu进行稠密矩阵向量乘计算。每次迭代时根据稠密矩阵向量乘在cpu和类gpu加速器上的计算时间,动态分配矩阵量给cpu和类gpu加速器。具体公式如下:
其中n代表当前进程需要处理的稠密矩阵总数,
步骤8:各进程将上述迭代求解结果,通过本地求解模块求得内部节点的位移,从而得到所有节点的位移。
本发明的又一个目的是提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行上述的方法。
本发明的再一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
本发明的有益效果是:
本发明在使用有限元撕裂对接法进行反应堆堆芯组件数值模拟的时候,采用了负载均衡策略,使得各进程的稠密矩阵内存大小趋于平均值,这样能够充分利用集群资源,加快求解速度。同时,本发明采用了hip编程,使得有限元撕裂对接法能够运行在nvidiacuda平台和amdrocm平台,增加了代码的可移植性。在迭代求解过程的稠密矩阵向量乘阶段中,采用动态分配矩阵策略,使得不同处理器分配到合适的计算量,以充分利用计算资源,加快求解速度。在向量内积阶段,采用了向量内积加速策略和通信计算重叠策略,通过引入通信线程,减少通信等待时间,加快向量内积速度。
附图说明
图1有限元撕裂对接加速方法流程图;
图2稠密矩阵内存占用对比图;
图3稠密矩阵向量乘计算时间对比图。
具体实施方式
以下结合具体实施例对本发明做进一步的分析。
将本发明面向反应堆堆芯组件数值模拟的有限元撕裂对接法应用到反应堆堆芯组件在高温情况下的形变预测。
一种核反应堆里堆芯组件形变预测方法,包括面向反应堆堆芯组件数值模拟的有限元撕裂对接加速方法;通过上述获得的求解结果(即所有节点的位移)即可获知当前堆芯组件的形变情况,从而为堆芯组件的分析设计提供依据。
以下是的具体实施步骤与说明:
一种面向反应堆堆芯组件数值模拟的有限元撕裂对接系统,包括输入模块、区域划分模块、矩阵组装模块、资源收集模块、负载均衡模块、迭代求解模块、本地求解模块。
所述的输入模块,用于获取网格文件数据,并进行初始化参数设置。
所述的区域划分模块,用于对网格划分为多个区域,并对每个区域划分为多个子区域。
所述的矩阵组装模块,用于在各子区域生成对应的有限元矩阵。
所述的资源收集模块,用于收集各进程的稠密矩阵大小信息,并进行占有内存比较。
所述的负载均衡模块,用于调用负载均衡策略,对各进程的稠密矩阵进行重分配。
所述的迭代求解模块,用于采用现有迭代方法求解各区域边界节点的位移;并调用向量内积加速策略和通信计算重叠策略。
所述的本地求解模块,用于求解各区域内部节点的位移。
n个计算节点中每个计算节点均设有上述有限元撕裂对接系统,每个计算节点拥有g块类gpu加速器。
一种面向反应堆堆芯组件数值模拟的有限元撕裂对接法,如图1所示,具体步骤如下:
步骤1:获取反应堆堆芯组件的几何模型数据,并将几何模型数据通过现有软件进行网格划分,生成网格文件。
步骤2:每个计算节点通过输入模块获取反应堆堆芯组件的网格文件,初始化相关参数:有限元方法、迭代方法、最大迭代数、迭代精度、堆芯组件材料参数、堆芯组件边界条件等。
所述的有限元方法可以为feti或者htfeti。
所述的迭代方法为预处理共轭梯度法,用于求解以下有限元方程:
其中:
f=bk+bt
g=br
d=bk+f
e=rtf
矩阵b是位移协调矩阵,使得相邻子域接触面上的节点位移相等。矩阵k是有限元刚度矩阵。矩阵r是刚度矩阵k的零空间的基,相邻f是载荷向量。λ和α是均是未知量,通过选用预处理矩阵p=i-g(gtg)-1gt,来消除变量α,然后通过预处理共轭梯度法求解得到子域边界节点位移λ。
具体算法描述如下:
步骤3:n个计算节点,每个计算节点开启g个进程,每个进程开启t个线程,通过区域划分模块将输入模块获取的网格划分为g*n个区域,每个区域分配一个进程;同时每个区域进一步划分为s个子区域。
步骤4:各进程根据分配到的区域以及选用的有限元方法,通过矩阵组装模块在各个子域生成对应的有限元矩阵,每个子域均会生成一个稠密矩阵。因此,每个进程会生成s个稠密矩阵。
步骤5:利用资源收集模块收集各进程的稠密矩阵信息,进程i的稠密矩阵占用内存大小为li,令lmin=min{l1,l2,l3…ln*g},lmax=max{l1,l2,l3…ln*g}。如果
步骤6:通过负载均衡模块启用负载均衡策略,将各进程的矩阵占用内存大小,都调整至平均值附近。
所述的负载均衡策略具体是:
a)根据各进程的稠密矩阵内存大小,计算出稠密矩阵平均内存大小;
b)将各进程的稠密矩阵内存大小与平均值相比较,如果大于平均值,则认为该进程的计算量较大,需要别的进程的帮助,设为被帮助者;如果小于平均值,则认为该进程的计算量较小,可以帮组别的进程,设为帮助者;
c)将进程分为两组,帮助者为一组,被帮助者为一组,对每一组按照稠密矩阵内存大小排序,对应选出一个帮助者与一个被帮助者;
d)被帮助者发送1个稠密矩阵给帮助者;
e)重复步骤d)直到当前被帮助者的稠密矩阵内存小于平均值,然后换下一个被帮助者,或者帮助者的稠密矩阵内存大于平均值,然后换下一个帮助者,进入步骤d);
d)重复步骤d)和e),直到所有被帮助者的内存均小于平均值,或者所有帮助者的稠密矩阵内存大于平均值。
步骤7:通过迭代求解模块,使得各进程进行迭代求解,在迭代求解的每一步迭代中向量内积运算采用向量内积加速策略和通信计算重叠策略,稠密矩阵向量乘采用hip编程使其在类gpu加速器上计算,并采用动态矩阵分配策略。
所述的向量内积加速策略为多线程并行求解各进程的局部向量内积。
所述的通信计算重叠策略为每个进程使用1个线程用于通信,其余t-1个线程继续参与局部向量内积计算,当通信线程完成通信时则该线程再参与到局部向量内积计算。具体算法描述如下:
所述的动态分配矩阵策略具体是在进行稠密矩阵向量乘时,各进程使用1个线程调用hipblas库,使用一块类gpu加速器进行稠密矩阵向量乘计算,其余t-1个线程调用intelmkl库,使用cpu进行稠密矩阵向量乘计算。每次迭代时根据稠密矩阵向量乘在cpu和类gpu加速器上的计算时间,动态分配矩阵量给cpu和类gpu加速器。具体公式如下:
其中n代表当前进程需要处理的稠密矩阵总数,
步骤8:各进程将上述迭代求解结果,通过本地求解模块,求得内部节点的位移,从而得到所有节点的位移。
图2展示了负载均衡前后稠密矩阵内存大小的对比,表明本发明通过负载均衡策略,能够将各进程的负载调节至平均值,避免由于负载不均衡而导致过长的通信等待时间,使得集群资源得以充分利用。图3展示了负载均衡前后稠密矩阵向量乘的计算时间,通过对比可以发现,负载均衡策略能够有效地加快求解速度。
- 还没有人留言评论。精彩留言会获得点赞!