一种软件层面的血管内oct三维图像管腔分割方法和装置与流程
本发明涉及神经网络与图像处理领域,具体而言,涉及一种软件层面的血管内oct三维图像管腔分割方法和装置。
背景技术:
光学相干层析成像技术(opticalcoherencetomography,oct)是一种非侵入的探测技术。oct技术现已被广泛应用于生物组织的活体截面结构成像。通过测量与深度有关的散射光,oct可以提供高分辨,高灵敏度的组织结构。
当oct应用于血管成像时,利用可以转动的光学透镜和光纤向血管内表面发射近红外光,利用光干涉仪接收反射回来的光波并成像。因为利用光波成像,oct成像分辨率高,轴向分辨率可以达到10-20μm,可以对斑块表面的成分以及微结构进行成像。但是,由于近红外光波穿透性不强(约1.0-2.5mm),血细胞、红血栓以及斑块的脂质核心或斑块内坏死都会影响oct对血管壁结构的观察和斑块负荷的估计。因为红细胞对红光的散射,过去的oct在成像时需要不断注入造影剂将血液冲刷开。现代的oct系统通过快速旋转回撤等技术部分地减少了红细胞等对成像的干扰,在数秒内完成一段长度血管的成像。
目前,oct图像的斑块及管腔分割的方法主要还是依赖于专业医生的人工标注,标注过程中需要医生的专业知识进行判断,不仅需要大量的重复劳动,而且人工标注效率也不高。
技术实现要素:
本发明的目的在于提供一种软件层面的血管内oct三维图像管腔分割方法和装置,其目的在于全自动的找到并分割出血管内oct三维图像的管腔轮廓。
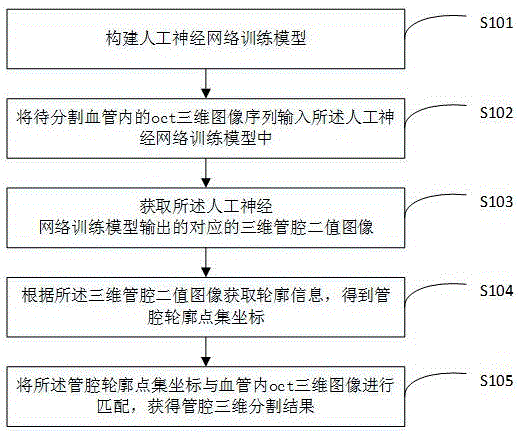
为解决上述技术问题,本发明采用的技术方案是:一种软件层面的血管内oct三维图像管腔分割方法,包括:构建人工神经网络训练模型;将待分割血管内的oct三维图像序列输入所述人工神经网络训练模型中;获取所述人工神经网络训练模型输出的对应三维管腔二值图像;根据所述三维管腔二值图像获取轮廓信息,得到管腔轮廓点集坐标;将所述管腔轮廓点集坐标与血管内oct三维图像进行匹配,获得管腔三维分割结果。
作为优选方案,所述构建人工神经网络训练模型,包括:获取多个血管内的oct三维图像序列;对所述oct三维图像人工标注管腔轮廓,获得管腔轮廓点集的坐标;在全零矩阵中,根据坐标将管腔轮廓点集连接成轮廓,并进行填充,得到管腔的二值图像,作为数据集的标签label;将所述oct三维图像的每一帧添加一层蒙版与原本图像通道叠加,形成多通道,作为数据集的输入input;将所述数据集的标签label和输入input传输至unet网络结构中,进行训练,多次迭代过程后,得到最终人工神经网络训练模型。
作为优选方案,每个oct三维图像序列的第一帧图片采用以图片中心为圆心,一定半径的圆作为蒙版,后续图片用上一帧训练的输出结果作为蒙版。
作为优选方案,训练所使用的损失函数为:
其中,p为unet网络模型训练得到的预测矩阵,y为标签矩阵,yi为y中的一个元素,pi为p中的一个元素,n为y或p中的元素个数,λ为超参数,选取0.5。
作为优选方案,在将所述数据集的标签label和输入input传输至unet网络结构中之前,还包括:对所述数据集进行降采样,所述输入input包括4个通道,每个通道和标签label的图像长宽尺寸转换为原来的1/k。
作为优选方案,对所述oct三维图像人工标注管腔轮廓,包括:创建一个交互界面,人工在血管内oct三维图像上进行手动管腔分割。
作为优选方案,所述三维管腔二值图像包括:管腔内的部分为1,背景部分为0。
作为优选方案,根据所述三维管腔二值图像获取轮廓信息,包括:以像素值为1的所有点集的平均坐标为圆心,每间隔2°向外发射180条射线,射线所处像素值由1变化为0的点即为所采样的轮廓点。
本发明还公开了一种软件层面的血管内oct三维图像管腔分割装置,包括;模型构建模块,用于构建人工神经网络训练模型;三维图像输入模块,用于将待分割血管内的oct三维图像序列输入所述人工神经网络训练模型中;二值图像获取模块,用于获取所述人工神经网络训练模型输出的对应三维管腔二值图像;坐标获取模块,用于根据所述三维管腔二值图像获取轮廓信息,得到管腔轮廓点集坐标;结果获取模块,用于将所述管腔轮廓点集坐标与血管内oct三维图像进行匹配,获得管腔三维分割结果。
作为优选方案,所述模型构建模块,包括:图像序列获取单元,用于获取多个血管内的oct三维图像序列;人工标注单元,用于对所述oct三维图像人工标注管腔轮廓,获得管腔轮廓点集的坐标;标签生成单元,用于在全零矩阵中,根据坐标将管腔轮廓点集连接成轮廓,并进行填充,得到管腔的二值图像,作为数据集的标签label;输入生成单元,用于将所述oct三维图像的每一帧添加一层蒙版与原本图像通道叠加,形成多通道,作为数据集的输入input;训练单元,用于将所述数据集的标签label和输入input传输至unet网络结构中,进行训练,多次迭代过程后,得到最终人工神经网络训练模型。
与现有技术相比,本发明的有益效果包括:通过构建人工神经网络训练模型,并将oct三维图像序列输入其中,获取对应的三维管腔二值图像,进而得到管腔轮廓点集坐标。本发明简化了医生进行手动管腔分割的的重复劳动,提高了医生分析冠脉oct图像的效率,使得医生的劳动力应用到更加专业的判断上,最终使更多的心血管患者获益。
附图说明
参照附图来说明本发明的公开内容。应当了解,附图仅仅用于说明目的,而并非意在对本发明的保护范围构成限制。在附图中,相同的附图标记用于指代相同的部件。其中:
图1为本发明实施例软件层面的血管内oct三维图像管腔分割方法的流程图;
图2为本发明实施例构建人工神经网络训练模型的流程图;
图3为本发明实施例血管内oct三维图像的单独一帧图像;
图4为本发明实施例分割后管腔的二值图像;
图5为本发明实施例单独一帧图像血管管腔最终分割结果;
图6为本发明实施例软件层面的血管内oct三维图像管腔分割装置的结构示意图;
图7为本发明实施例模型构建模块的结构示意图。
具体实施方式
容易理解,根据本发明的技术方案,在不变更本发明实质精神下,本领域的一般技术人员可以提出可相互替换的多种结构方式以及实现方式。因此,以下具体实施方式以及附图仅是对本发明的技术方案的示例性说明,而不应当视为本发明的全部或者视为对本发明技术方案的限定或限制。
根据本发明的一实施方式结合图1示出。一种软件层面的血管内oct三维图像管腔分割方法,包括如下步骤:
s101:构建人工神经网络训练模型。
其中,构建人工神经网络训练模型,包括步骤s1011至s1015,如图2所示。
步骤s1011:获取多个血管内的oct三维图像序列。图像序列是指通过对一根血管从下往上进行类似切片的快速扫描的方法,将“摄像机”深入血管内部并进行快速旋转,每间隔一定时间就扫描一定厚度的血管横截面,获得每个时间点扫描的图像,即同一个血管上不同高度的横截面图像。如图3所示,为血管内oct三维图像的单独一帧图像。
步骤s1012:对oct三维图像人工标注管腔轮廓,获得管腔轮廓点集的坐标。
具体的,对oct三维图像人工标注管腔轮廓,包括:创建一个交互界面,人工在血管内oct三维图像上进行手动管腔分割。
步骤s1013:在全零矩阵中,根据坐标将管腔轮廓点集连接成轮廓,并进行填充,得到管腔的二值图像,作为数据集的标签label,如图4所示。具体的,三维管腔二值图像包括:管腔内的部分为1,背景部分为0。
步骤s1014:将oct三维图像的每一帧添加一层蒙版与原本图像通道叠加,形成多通道,作为数据集的输入input。每个oct三维图像序列的第一帧图片采用以图片中心为圆心,一定半径的圆作为蒙版,后续图片用上一帧训练的输出结果作为蒙版。
优选的,为了加快训练速度,在将数据集的标签label和输入input传输至unet网络结构中之前,还包括:对数据集进行降采样,输入input包括4个通道,每个通道和标签label的图像长宽尺寸转换为原来的1/k。
其中,输入input包括4个通道,即在每一帧图像的rgb三个通道的基础上加上蒙版的第四个通道。
步骤s1015:将数据集的标签label和输入input传输至unet网络结构中,进行训练,多次迭代过程后,得到最终人工神经网络训练模型。
应理解,unet网络结构主要分为三部分:下采样,上采样以及跳跃连接,首先将该网络分为左右部分来分析,左边是压缩的过程,即encoder。通过卷积和下采样来降低图像尺寸,提取一些浅显的特征。右边部分是解码的过程,即decoder。通过卷积和上采样来获取一些深层次的特征,其中卷积采用的valid的填充方式来保证结果都是基于没有缺失上下文特征得到的,因此每次经过卷积后,图像的大小会减小。中间通过concat的方式,将编码阶段获得的featuremap同解码阶段获得的featuremap结合在一起,结合深层次和浅层次的特征,细化图像,根据得到的featuremap进行预测分割。
训练所使用的损失函数l为交叉熵(bce)与diceloss结合使用:
其中,p为unet网络模型训练得到的预测矩阵(即二值图像),y为标签矩阵,yi为y中的一个元素,pi为p中的一个元素(即像素点),n为y或p中的元素个数,λ为超参数,选取0.5。
迭代训练过程中:unet网络输出一个预测结果,通过损失函数计算预测结果与已有标签的差值(即误差),并基于反向传播算法(bp,backpropagation)将误差传递到网络结构中的每一个隐藏层,将每一层的参数进行修正,修正的数值基于bp算法传递的误差,如此反复,直到误差小于一定数值或迭代次数超过一定次数。
s102:将待分割血管内的oct三维图像序列输入人工神经网络训练模型中。
s103:获取人工神经网络训练模型输出的对应三维管腔二值图像。
s104:根据三维管腔二值图像获取轮廓信息,得到管腔轮廓点集坐标。
具体的,根据三维管腔二值图像获取轮廓信息,包括:以像素值为1的所有点集的平均坐标为圆心,每间隔2°向外发射180条射线,射线所处像素值由1变化为0的点即为所采样的轮廓点。
s105:将管腔轮廓点集坐标与血管内oct三维图像进行匹配,获得管腔三维分割结果,如图5所示。
具体的,管腔轮廓点集与血管内oct三维图像的匹配方法,包括:将管腔轮廓点集坐标等比例放大,变为原来的k倍,复原成压缩前的尺寸,将每一帧的对应轮廓坐标像素值设为(255,255,255),相邻像素所连直线上的像素点也设为(255,255,255)。
如图6所示,本发明还公开了一种软件层面的血管内oct三维图像管腔分割装置,包括;
模型构建模块101,用于构建人工神经网络训练模型。
三维图像输入模块102,用于将待分割血管内的oct三维图像序列输入人工神经网络训练模型中。
二值图像获取模块103,用于获取人工神经网络训练模型输出的对应三维管腔二值图像。
坐标获取模块104,用于根据三维管腔二值图像获取轮廓信息,得到管腔轮廓点集坐标。
结果获取模块105,用于将管腔轮廓点集坐标与血管内oct三维图像进行匹配,获得管腔三维分割结果。
如图7所示,上述模型构建模块101,包括:
图像序列获取单元1011,用于获取多个血管内的oct三维图像序列;
人工标注单元1012,用于对oct三维图像人工标注管腔轮廓,获得管腔轮廓点集的坐标;
标签生成单元1013,用于在全零矩阵中,根据坐标将管腔轮廓点集连接成轮廓,并进行填充,得到管腔的二值图像,作为数据集的标签label;
输入生成单元1014,用于将oct三维图像的每一帧添加一层蒙版与原本图像通道叠加,形成多通道,作为数据集的输入input;
训练单元1015,用于将数据集的标签label和输入input传输至unet网络结构中,进行训练,多次迭代过程后,得到最终人工神经网络训练模型。
所属领域的技术人员可以清楚地了解到,为了描述的方便和简洁,上述描述的系统、装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
综上所述,本发明的有益效果包括:通过构建人工神经网络训练模型,并将oct三维图像序列输入其中,获取对应的三维管腔二值图像,进而得到管腔轮廓点集坐标。本发明简化了医生进行手动管腔分割的的重复劳动,提高了医生分析冠脉oct图像的效率,使得医生的劳动力应用到更加专业的判断上,最终使更多的心血管患者获益。
本发明的技术范围不仅仅局限于上述说明中的内容,本领域技术人员可以在不脱离本发明技术思想的前提下,对上述实施例进行多种变形和修改,而这些变形和修改均应当属于本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!