一种层级对齐结构的问答立场检测方法及装置
knowledge.in:proceedings of the 58th annual meeting of the association for computational linguistics.pp.3188{3197.association for computational linguistics,online(jul 2020))和文献(slovikovskaya,v.,attardi,g.:transfer learning from transformers to fake news challenge stance detection(fnc
‑
1)task.in:proceedings of the 12th language resources and evaluation conference.pp.1211{1218.european language resources association,marseille,france(may 2020)),在多种目标间使用了迁移知识,这些目标主要是实体、声明或短语。
4.问答立场检测是以问答文本中的问题为目标,识别回答文本中的立场。给定一个问题
‑
回答(qa)对,最新的方法提出了一个循环条件注意力网络(yuan,j.,zhao,y.,xu,j.,qin,b.:exploring answer stance detection with recurrent conditional attention.in:the thirty
‑
thirdaaai conference on artificial intelligence,aaai 2019,the thirty
‑
first innovative applications of artificial intelligence conference,iaai 2019,the ninth aaai symposium on educational advances in artificial intelligence,eaai 2019,honolulu,hawaii,usa,january 27
‑
february 1,2019.pp.7426{7433.aaai press(2019)),为问题和回答的关系建模,通过循环阅读调整立场的状态,最终得到回答文本的立场。解决问答立场检测任务,模型不仅要理解问答文本中的语义,还要为问题和回答文本之间的关系进行建模。
5.此外,立场检测子任务谣言立场检测(gorrell,g.,kochkina,e.,liakata,m.,aker,a.,zubiaga,a.,bontcheva,k.,derczynski,l.:semeval
‑
2019task 7:rumoureval,determining rumour veracity and support for rumours.in:proceedings of the 13th international workshop on semantic evaluation.pp.845{854.association for computational linguistics,minneapolis,minnesota,usa(jun 2019))和假新闻立场检测(gorrell,g.,kochkina,e.,liakata,m.,aker,a.,zubiaga,a.,bontcheva,k.,derczynski,l.:semeval
‑
2019task 7:rumoureval,determining rumour veracity and support for rumours.in:proceedings of the 13th international workshop on semantic evaluation.pp.845{854.association for computational linguistics,minneapolis,minnesota,usa(jun 2019))关注文本的语义信息建模,而问答立场检测更关注如何学习qa之间相互关联,为指定目标下的立场表示进行建模。问答立场检测的相关任务还有依赖于目标的情感分析(gorrell,g.,kochkina,e.,liakata,m.,aker,a.,zubiaga,a.,bontcheva,k.,derczynski,l.:semeval
‑
2019task 7:rumoureval,determining rumour veracity and support for rumours.in:proceedings of the 13th international workshop on semantic evaluation.pp.845{854.association for computational linguistics,minneapolis,minnesota,usa(jun 2019)),后者的目标是学习目标相关的表示,而前者还需要找到与整个问题相关的目标和证据信息。
6.现有的技术应用在问答立场检测任务中都忽略了以下两个问题。第一,在问答立场检测中,立场与问题文本中概念相关的目标有关,但出现在问题和回答文本中表示相同概念的词可能不一致,应进行目标对齐。第二,回答文本中可能包含不止一个概念相关的目标,额外的目标信息会对识别立场产生干扰,应进行上下文对齐,设法找到可以支持问题文本的内容,即证据相关的上下文。
技术实现要素:
7.本发明提出了一种层级对齐结构的问答立场检测方法及装置,通过概念相关的目标对齐和证据相关的上下文对齐的方法,解决了问答立场检测任务中qa对中与概念相关的目标和与证据相关的上下文可能不一致的问题,并对立场进行了由粗到精的向量表示,可以有效地提升问答立场检测任务效果,准确地识别qa对中针对问题的回答文本所携带的立场。
8.为了实现上述目的,本发明提供了如下的技术方案:
9.一种层级对齐结构的问答立场检测方法,其步骤包括:
10.1)分别将问题文本与回答文本转换为问题序列与回答序列;
11.2)拼接问题序列与回答序列,得到问题回答序列;
12.3)将问题序列、回答序列及问题回答序列输入层次对齐模型,得到问答立场检测结果;
13.其中,通过以下步骤获取问答立场检测模型:
14.a)分别将若干样本问题文本与若干样本回答文本转换为样本问题序列与样本回答序列,并拼接样本问题序列与相应的样本回答序列,得到若干样本问题回答序列;
15.b)分别编码各样本问题序列、样本回答序列及样本问题回答序列,得到若干的问题序列表示s
q
、回答序列表示s
a
及粗粒度立场表示s
qa
;
16.c)以问题序列表示s
q
作为查询且将相应的回答序列表示s
a
作为键和值,获取若干的依赖于问题的回答表示m
q
→
a
,以回答序列表示s
a
作为查询且将相应的回答序列表示s
q
作为键和值,获取若干的依赖于回答的问题表示m
a
→
q
,并连接依赖于问题的回答表示m
q
→
a
与相应的依赖于回答的问题表示m
a
→
q
,得到若干细粒度表示d
qa
;
17.d)基于多头注意力机制,对齐细粒度表示d
qa
与相应的粗粒度立场表示s
qa
之间证据相关的句子含义,得到若干的由粗到精立场向量表示o;
18.e)通过对若干的由粗到精立场向量表示o进行分类,获取层次对齐模型。
19.进一步地,编码样本问题序列、样本回答序列及样本问题回答序列的方法包括:使用预训练bert模型。
20.进一步地,通过以下步骤获取依赖于问题的回答表示m
q
→
a
:
21.1)以问题序列表示s
q
作为查询且将相应的回答序列表示s
a
作为键和值,获取第一个回答
‑
问题匹配块的输出,其步骤包括:
22.a)得到第i个头的输出其中其中是的维度,d为样本问题文本与样本回答文本转换为样本问题序列与样本回答序列的嵌入尺寸,h为头的数量,是可学习的参数,1≤i≤h;
23.b)拼接h个头的输出,并对拼接结果进行线性投影运算,得到运算结果
24.matt(s
q
,s
a
)=[att1(s
q
,s
a
),att2(s
q
,s
a
),...,att
h
(s
q
,s
a
)w
o
,其中是可学习的参数;
[0025]
c)在问题序列表示s
q
与运算结果matt(s
q
,s
a
)之间进行残差连接,得到结果z=ln
(s
q
+matt(s
q
,s
a
)),其中ln为层次归一化操作;
[0026]
d)将结果z接入一个前馈网络与另一个残差连接层,得到第一个transformer编码器的输出tim1(s
q
,s
a
)=ln(z+mlp(z)),其中mlp为前馈网络;
[0027]
2)通过堆积l
m
个回答
‑
问题匹配块,获取依赖于问题的回答表示问题匹配块,获取依赖于问题的回答表示
[0028]
进一步地,由粗到精立场向量表示i=matt
′
(d
qa
,s
qa
)=[att
′1(d
qa
,s
qa
),...,att
′
h
′
(d
qa
,s
qa
)]w
′
o
,其中
[0029][0029]
是可学习的参数,1≤j≤h
′
。
[0030]
进一步地,通过对若干的由粗到精立场向量表示o进行分类:
[0031]
1)利用softmax函数,计算由粗到精立场向量表示o属于每一类立场的概率;
[0032]
2)取最高概率的类别,作为该由粗到精立场向量表示o的分类。
[0033]
进一步地,计算由粗到精立场向量表示o属于每一类立场的概率之前,使用一个线性层,减少各由粗到精立场向量表示o的维度数目。
[0034]
进一步地,训练层次对齐模型的损失函数其中是预测的结果,n为样本问题文本或样本回答文本的数量,|c|为立场类别集合的数目大小。
[0035]
进一步地,立场类别集合c包括:赞成、反对和中立。
[0036]
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置为运行时执行上述所述的方法。
[0037]
一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机以执行上述所述的方法。
[0038]
与现有技术相比,本发明具有以下优势:
[0039]
本发明与上述循环条件注意力网络的方案相比,都是通过注意力编码策略显式地为目标依赖信息建模。不同的是,条件注意和提取过程仅模拟了qa对之间的相互作用,没有在编码阶段学习到特征丰富的文本表示,也没有显式地进行目标和上下文对齐,而本发明先使用了bert预训练模型得到粗粒度的立场表示,然后从qa对中的问题和回答两方面进行了概念级别的目标对齐和证据级别的信息对齐,得到了由粗到精的立场表示。实验证明本申请的技术方法在问答立场检测任务上可以获得更高的准确率和f1值。
附图说明
[0040]
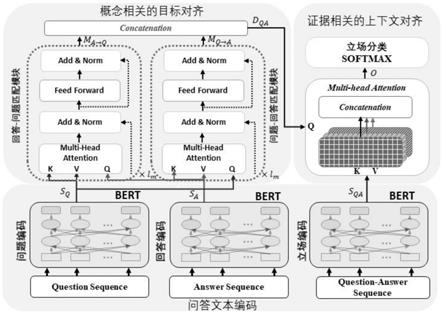
图1是本发明的层次对齐(hat)模型架构图。
具体实施方式
[0041]
为了使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的目的、特征和优点能够更加明显易懂,下面结合附图和事例对本发明中技术核心作进一步详细的说明。
[0042]
本发明的问答立场检测方法,提出了一种新的问答立场检测模型,即基于transformer的层级对齐(hat)模型,如图1所示,该模型可以对齐问答对中概念相关的目标和证据相关的上下文,学习到由粗到精的立场表示,从而应用于问答立场检测中。hat模型主要包含三个模块:问答文本编码模块、概念相关的目标对齐模块、证据相关的上下文对齐模块。首先,本发明使用预训练模型bert(devlin,j.,chang,m.w.,lee,k.,toutanova,k.:bert:pre
‑
training of deep bidirectional transformers for language understanding.in:proceedings of the 2019 conference of the north american chapter of the association for computational linguistics:human language technologies,volume 1(long and short papers).pp.4171{4186.association for computational linguistics,minneapolis,minnesota(jun 2019))计算出问答文本的基本特征,提取出有意义的特征。然后,引入一个qa相互作用匹配块,从两个方向对与概念相关的目标进行对齐,获得依赖于问题的回答表示和依赖于回答的问题表示。最后,使用多头注意力机制对齐证据相关的上下文,为问答立场检测学习到较好的立场表示。
[0043]
本方法主要分为以下四个部分:问答文本编码,目标对齐,上下文对齐,立场分类。
[0044]
1.问答文本编码
[0045]
对于问题文本,本发明将文本序列转换为序列表示x={x1,x2,...,x
n
},其中是词嵌入、分段嵌入与位置嵌入的总和,n是问题序列里的长度,d是嵌入的尺寸,同时d也是用于获取文本表示的预训练模型bert的维度大小。编码后的文本为bert编码器最后一层的输出,即问题序列表示使用相同的方法可以得到回答序列表示接着,本发明拼接了问题序列和回答序列,将它们输入预训练好的bert模型,得到一个粗粒度的立场表示,记为其中(n+1+m)多出的一个维度是q和a序列之间的分隔符[sep]。
[0046]
2.目标对齐
[0047]
概念相关的目标对齐模块的作用是从qa对中的问题和回答两个方面对齐概念相关的目标,学习出依赖于回答的问题表示和依赖于问题的回答表示。因此利用自注意力机制,构造qa相互作用匹配模块,从两个方面对齐概念级别的目标。我们提出了两种qa相互作用匹配块:问题
‑
回答匹配块和回答
‑
问题匹配块。
[0048]
问题
‑
回答匹配块将问题序列表示s
q
作为查询,将回答序列表示s
a
作为键和值。相反地,回答
‑
问题匹配块将回答序列表示s
a
作为查询,将回答序列表示s
q
作为键和值。这样,模型就会从问题和回答两方面更加关注概念相关的目标,从而获取依赖于回答的问题表示和依赖于问题的回答表示。
[0049]
具体来说,问题
‑
回答匹配块的第i个头计算公式为:
[0050][0051]
其中,是的维度,是可学习的参数,h为头的数量。
[0052]
接着,将h个头的输出拼接在一起,作线性投影运算,公式如下:
[0053]
matt(s
q
,s
a
)=[att1(s
q
,s
a
),att2(s
q
,s
a
),...,att
h
(s
q
,s
a
)]w
o
[0054]
其中,是可学习的参数。
[0055]
然后,在s
q
和matt(s
q
,s
a
)之间作残差连接,计算公式为:
[0056]
z=ln(s
q
+matt(s
q
,s
a
))
[0057]
其中ln是层次归一化操作。在这之后,再将z接入一个前馈网络(mlp)和另一个残差连接层,得到第一个transformer编码器的输出:
[0058]
tim(s
q
,s
a
)=ln(z+mlp(z))
[0059]
其中即为第一个问题
‑
回答匹配块的输出。
[0060]
我们堆积l
m
个匹配块,获取依赖于问题的回答表示即最后一层的输出,记为m
q
→
a
,在这里l
m
是一个表示匹配块个数的超参数。
[0061]
与问题
‑
回答匹配块的计算类似,我们同样可以堆积l
m
个匹配块通过计算回答
‑
问题匹配块,获得依赖于回答的问题表示记为m
a
→
q
。
[0062]
最后,我们将两种表示m
q
→
a
和m
a
→
q
进行连接,得到细粒度表示d
qa
,作为概念相关的目标对齐模块的输出。
[0063]
3.上下文对齐
[0064]
与证据相关的对齐模块旨在对qa对的证据上下文进行对齐,并为问答立场分类积累由粗粒度到细粒度的立场表示。为了实现这样的目标,本发明采用多头注意力层,以对齐qa的细粒度表示d
qa
与粗粒度的立场表示s
qa
之间的证据相关的句子含义。
[0065]
具体地,计算多头注意力:
[0066][0067]
matt
′
(d
qa
,s
qa
)=[att
′1(d
qa
,s
qa
),...,att
′
h
′
(d
qa
,s
qa
)]w
′
o
[0068]
其中,h’是注意力头的数量。这里记最后的由粗到精的立场向量表示为o=matt
′
(d
qa
,s
qa
),至此完成了上下文对齐的过程。
[0069]
4.立场分类
[0070]
得到了立场的向量表示后,进行最终的立场分类。在立场分类部分,先使用一个线性层减少维度数目,再使用softmax函数计算属于每一类立场的概率,此处取最高概率的类别作为给定qa对的立场类别。本部分用公式表示为:
[0071][0072]
训练时的损失函数为:
[0073][0074]
其中,是预测的结果,代表第j类类别的概率;当第j类是样本i的真实标签时,为1,否则为0;n是训练数据的数据量大小;|c|是立场类别集合的数目大小,在这里立场类别集合c={favor,against,neutral}。
[0075]
(三)积极效果
[0076]
为验证本方法的效果,在实验过程中,本发明使用了上述循环条件注意力网络方案中提出的一个开源数据集,该数据集包含若干中文问答对。问答对数据收集于百度知道、搜狗问问、明医网三个网站,其概念相关的目标主要包括怀孕、食品安全、疾病等。训练数据集的大小为10598,测试大小为2993,训练集和测试集的每一种立场类别的数据量大小如表1所示。
[0077]
本方法的评估指标为准确率(accuracy)、f1
‑
macro、f1
‑
macro、f1
‑
favor、f1
‑
against,其中f1
‑
favor是在立场标签为支持的样本上的f1值、f1
‑
against是在立场标签为反对的样本上的f1值。将本方法(hat模型)与一些主流方法作对比,具体结果如表2所示。
[0078]
表1数据集统计量
[0079][0080]
表2实验结果
[0081][0082][0083]
可以看到本发明提出的模型在每个评价指标上都达到了最优,超过了许多主流模型的性能,证明了本发明提出方法的有效性。
[0084]
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修
改,均应涵盖在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1