基于多源数据的森林生物量遥感制图方法
本发明属于遥感技术领域,特别是涉及一种基于多源数据的森林生物量遥感制图方法。
背景技术:
全球气候变化已经成为国际社会普遍关注的焦点,而森林碳循环是研究全球气候变化的重要内容之一,陆地生态系统中约77%的植被碳存储在森林中。森林生物量指标能够衡量森林碳储能力,对其进行准确估测可为碳循环、碳交易、碳排放相关研究提供支持,因而具有重要的研究意义。传统的森林生物量调查方法费时费力,且只能获取小范围信息,遥感技术能够客观、快速地获取各个尺度的森林参数,在森林生物量制图上具有巨大的优势。
技术实现要素:
本发明针对现有技术的不足,提供一种基于多源数据的森林生物量遥感制图方法。本发明集成光学遥感数据、雷达遥感数据和地形数据,使用异速生长方程将样地调查数据转换为森林地上生物量,利用逐步回归与随机森林方法对遥感数据的指标进行筛选,建立多元线性回归和随机森林两种森林地上生物量模型,使用十折交叉验证方法得到的决定系数与均方根误差选取最佳模型,使用palsar-2forest/nonforest产品作为掩膜提取研究区森林范围完成森林地上生物量制图。
为了达到上述目的,本发明提供的技术方案是一种基于多源数据的森林生物量遥感制图方法,包括以下步骤:
步骤1,根据历史资料数据,选择n种森林类型作为分层指标;
步骤2,按照步骤1中森林类型对样地每种类型进行分层抽样调查,提取中心坐标、单木位置、密度、树高、冠幅和胸径信息;
步骤3,将步骤2中样地调查获取的树高、冠幅和胸径信息转换为森林地上生物量;
步骤4,计算光学遥感数据的年度物候指标、常用遥感指数、缨帽变换相关指标,基于灰度共生矩阵选取纹理特征;
步骤5,对sar数据进行预处理,获取年均值、中值、标准差和归一化差分指数指标;
步骤6,使用地形特征数据,计算坡度、坡向、高程3个指标;
步骤7,分别使用随机森林和逐步回归方法筛选步骤4、步骤5、步骤6中计算得到的指标,筛选后的指标作为建立森林地上生物量模型的特征变量;
步骤8,使用步骤3计算得到的样地森林地上生物量和步骤7筛选的特征变量构建多元线性回归和随机森林两种森林地上生物量模型;
步骤9,对步骤8得到的两种森林地上生物量模型进行比较,选取最佳模型;
步骤10,利用步骤9得到的最佳模型和森林掩膜绘制研究区森林地上生物量分布图。
而且,所述步骤3中将样地调查获取的树高、冠幅和胸径信息转换为森林地上生物量是利用生物量异速生长方程实现的。
而且,所述步骤4中常用遥感指数指的是evi、evi2、rvi,缨帽变换相关指标指的是亮度、湿度、绿度和湿度绿度差值,选取的纹理特征包括均值、方差、同质性、对比度、异质性、信息熵、二阶矩和相关性共8种。
而且,所述步骤5中预处理包括轨道文件精校、景边噪声去除、热噪声去除、辐射定标、裁切、入射角纠正、多视处理、地形校正。
而且,所述步骤7中使用随机森林和逐步回归方法筛选指标时,将步骤3计算得到的样地森林地上生物量作为参考值。
而且,所述步骤8中是将步骤3计算得到的样地森林地上生物量作为因变量,步骤7筛选的特征变量作为自变量,分别建立多元线性回归模型和随机森林模型。
而且,所述步骤9中最佳模型是根据十折交叉验证方法得到的决定系数与均方根误差两个指标进行评价选取的。
而且,步骤10中的森林掩膜是使用palsar-2forest/nonforest产品作为掩膜提取的研究区森林范围。
与现有技术相比,本发明具有如下优点:光学遥感数据应用广泛、数据量大但是在植被浓密地区存在信号饱和的问题,并且容易受云层干扰,雷达遥感数据具有不受云层干扰并且可以穿透森林冠层的特点,本发明结合两者的优点,使森林地上生物量的估测结果更加准确。同时,本发明在森林生物量建模时,使用十折交叉验证方法得到的决定系数与均方根误差选取最佳模型,可以在应用于不同区域森林生物量估测时相应调整,模型准确性高。本发明这些方面的优点使其有很强的通用性,便于推广使用。
附图说明
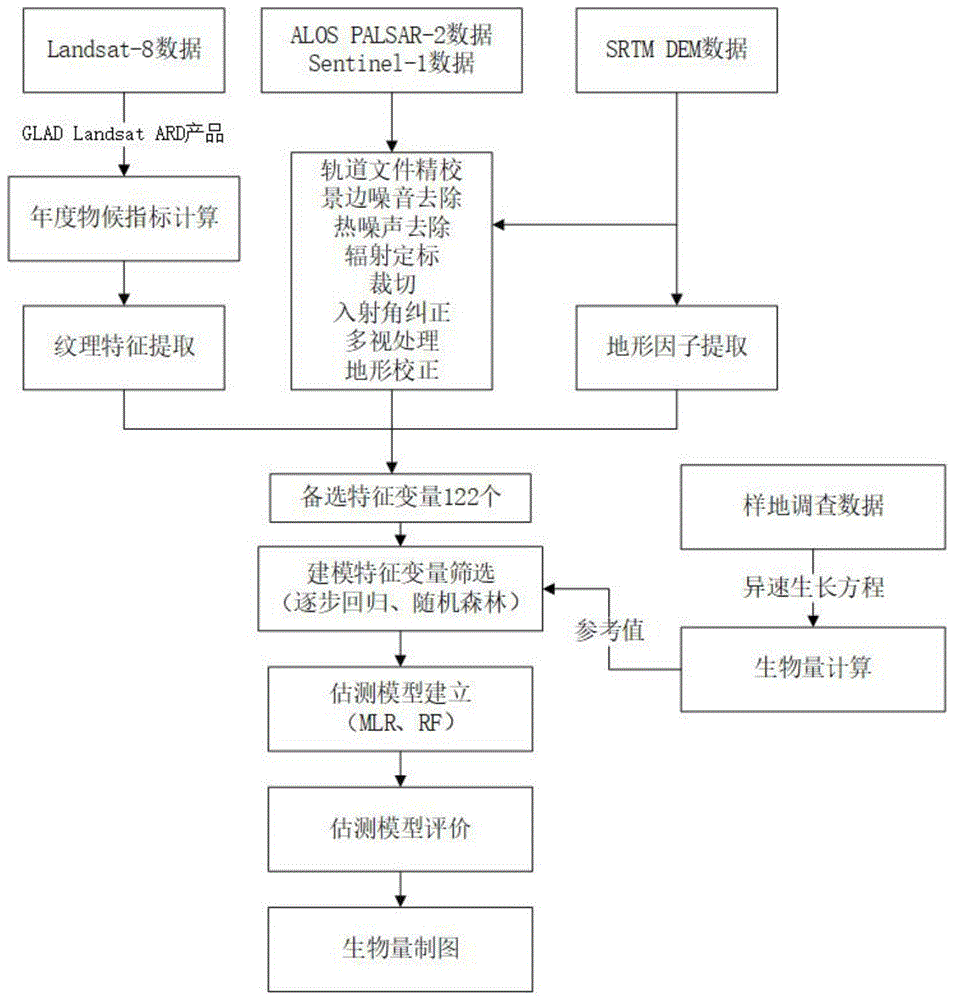
图1为本发明实施例森林生物量估测的技术路线图。
图2为本发明实施例不同模型训练集与测试集的表现图,其中图2(a)为不同模型训练集的表现,图2(b)为不同模型测试集的表现。
图3为本发明实施例湘西北区域生物量制图。
具体实施方式
本发明提供一种基于多源数据的森林生物量遥感制图方法,该方法集成光学遥感数据(landsat-8)、雷达遥感数据(alospalsar-2、sentinel-1)和地形数据(srtm),使用异速生长方程将样地调查数据转换为森林地上生物量,利用逐步回归与随机森林方法对遥感数据的指标进行筛选,建立多元线性回归和随机森林两种森林地上生物量模型,使用十折交叉验证方法得到的决定系数(r2)与均方根误差(rmse)选取最佳模型,使用palsar-2forest/nonforest产品作为掩膜提取研究区森林范围,完成森林地上生物量制图。本发明思路清晰直观,利用多源遥感数据,能够快速完成大范围生物量估算,具有较大的应用潜力。
下面结合附图和实施例对本发明的技术方案作进一步说明。
如图1所示,本发明实施例的流程包括如下步骤:
步骤1,根据历史资料数据,选择n种森林类型作为分层指标;
步骤2,按照步骤1中森林类型对样地每种类型进行分层抽样调查,提取中心坐标、单木位置、密度、树高、冠幅和胸径信息;
步骤3,利用生物量异速生长方程将步骤2中样地调查获取的树高、冠幅和胸径信息转换为森林地上生物量;
步骤4,计算光学遥感数据的年度物候指标、常用遥感指数(evi、evi2、rvi)、缨帽变换相关指标(亮度、湿度、绿度、湿度绿度差值),基于灰度共生矩阵选取纹理特征;
步骤5,对sar数据进行预处理,获取年均值、中值、标准差和归一化差分指数指标;
步骤6,使用地形特征数据,计算坡度、坡向、高程3个指标;
步骤7,将步骤3计算得到的样地森林地上生物量作为参考值,分别使用随机森林和逐步回归方法筛选步骤4、步骤5、步骤6中计算得到的指标,筛选后的指标作为建立森林地上生物量模型的特征变量;
步骤8,使用步骤3计算得到的样地森林地上生物量和步骤7筛选的特征变量构建多元线性回归和随机森林两种森林地上生物量模型;
步骤9,通过十折交叉验证方法得到决定系数与均方根误差,利用决定系数和均方根误差两个指标对步骤8得到的两种森林地上生物量模型进行比较,选取最佳模型;
步骤10,使用palsar-2forest/nonforest产品作为掩膜提取研究区的森林范围,利用步骤9得到的最佳模型绘制研究区森林地上生物量分布图。
下面以湖南湘西地区的实验数据为例,进一步阐述本发明的技术方案。
湖南湘西北地区位于东经108°47′-112°05′,北纬24°10′-38°84′之间。该地区属亚热带季风气候,四季分明。年降水量从1200mm到1700mm不等,年平均气温在16℃-18℃之间。
根据历史林业调查数据,选择了10种森林类型作为研究对象。其中,依据第8次全国森林资源清查数据,选择了蓄积量最高的7个树种,包括栎属(quercussp.)、杉木(cunninghamialanceolata)、马尾松(pinusmassoniana)、杨属(populussp.)、柏木(cupressusfunebris)、湿地松(pinuselliottii)、樟(cinnamomumcamphora)。此外,选择了针叶混交林、针阔混交林、阔叶混交林3种森林类型。所选择的10种类型森林占湖南省森林总蓄积量的98%以上。对于每种森林类型,按照5级树高、3级冠层密度所确定的共15个参数等级进行分层抽样调查,每一个等级取4个半径为15m的圆形样地进行调查。样地调查时间在2017年10月15日至2018年4月30日之间,调查数据包括中心坐标、单木位置、密度、树高、冠幅和胸径等信息,筛选后共得到393个可用样地数据。利用生物量异速生长方程将样地调查所获取的树高、冠幅、胸径指标转换为森林地上生物量。
使用马里兰大学全球地表分析与发现(globallandanalysisanddiscovery,glad)团队所提供的landsatard产品作为光学遥感数据源。共下载了研究区域内2016-2017年276景影像用以进行指标计算,并利用glad软件包中所提供的年度物候指标(类型b)计算工具计算了2017年度的86个指标,分为按原值与按参考值排序计算的两类指标。其中,按原值排序计算指标是指按照原始波段或光谱指数对数据进行排序及统计,共得到了50个指标,具体见表1。按参考值排序指标,按照给定的参考值(ndvi、ns2、lst)对数据进行排序及统计,提取对应的原始波段或光谱指数值,共得到36个指标,具体见表2。
表1光学遥感数据指标(按原值排序)
注:avmin25指最小值-较小四分位数取平均,av75max指较大四分位数-最大值取平均,av2575指较小四分位数-较大四分位数取平均,svvi为光谱变异植被指数(spectralvariabilityvegetationindex),按式(a)计算。
svvi=σ(μblue,μgreen,μred,μnir,μswir1,μswir2)-σ(μnir,μswir1,μswir2)+10000(a)
式中,σ为标准差,μ为归一化表面反射率。
表2光学遥感数据指标(按参考值排序)
在上述指标基础上,根据相关文献,还补充计算了其他常用的遥感指数(evi、evi2、rvi)、缨帽变换相关指标(亮度、湿度、绿度、湿度绿度差值),并基于灰度共生矩阵(glcm,greylevelco-occurrencematrices)选取均值(mean)、方差(variance)、同质性(homogeneity)、对比度(contrast)、异质性(dissimilarity)、信息熵(entropy)、二阶矩(secondmoment)和相关性(correlation)共8种纹理特征。
选择sentinel-1与alospalsar-2作为sar数据源,分别提供了c、l波段信息。sentinel-1数据经过一系列的预处理,包括辐射定标(calibration)、噪音去除(noiseremoval)、多视(multi-look)和地形校正(terraincorrection)等,获得包括年均值、中值、标准差和归一化差分指数(npdi)在内的7个指标具体见表3。alospalsar-2指标包括官方提供的双极化年均值,经计算得到归一化差分指数(npdi)。
表3sar数据指标
使用glad团队所提供的与landsatard格式一致的地形数据,其源数据来自nasa航天飞机雷达地形测绘任务(shuttleradartopographymission,srtm),经重新投影、剪裁为标准ard瓦片格式,含高程(dem)、坡度(slope)和坡向(aspect)3个指标。
分别使用两种方法对上述计算得到的相关指标进行筛选,对于使用机器学习算法建立的模型,利用随机森林算法选择出特征指标作为模型变量,最终选择15个变量具体见表4;对于多元线性回归模型,使用逐步回归算法选择出特征指标作为模型变量,最终选择19个显著变量具体见表5。
表4随机森林方法筛选特征变量结果
表5逐步回归方法筛选特征变量结果
将地面实测计算得到的森林生物量信息作为因变量,上述两种方法提取的特征变量作为自变量,分别建立多元线性回归模型和随机森林模型。采用决定系数与均方根误差评价模型的精度,图2(a)为不同模型训练集的表现,图2(b)为不同模型测试集的表现,不同模型的精度评价结果见表6。
表6不同模型的精度评价结果
总体来说,随机森林方法相比于多元线性回归方法,在训练集和测试集上rmse都更小,r2也都更接近1,因此本研究使用随机森林模型完成区域生物量制图。利用训练后的随机森林模型实现森林生物量的反演,使用palsar-2forest/nonforest产品作为掩膜提取了研究区的森林范围,制作了湘西北地区的生物量地图,见图3。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!