基于KR积融合多模态信息的神经网络视觉对话模型及方法
本发明涉及视觉对话和多模态融合技术领域,具体讲,涉及针对某一图片、历史对话信息和其对应的问题从候选答案中判断其真实答案的模型及方法。
背景技术:
视觉对话是语言和视觉交叉领域中一个具有挑战性的任务,该任务需要考虑多轮对话的历史信息和图像中的相关信息才能找到当前问题的最佳候选答案。视觉对话在许多应用场景中都会出现,例如帮助盲人理解周围事物、交互式搜索、室内导航等。视觉对话任务中,为了捕获与答案相关的信息,模型需要理解问题,捕获与问题相关的视觉信息和历史信息,同时捕获问题、视觉和历史三者之间潜在的关联信息。随着神经网络的兴起,早期的视觉对话任务采用lf[1]、hre[1]、mn[1]三种encoder方法去编码问题、图片和历史信息,这样的方法提取到的视觉特征和历史特征与问题的关联性不大,导致对问题向量、视觉向量和历史向量进行融合后,预测的答案不够准确;为了更准确地预测答案,一些方法基于注意力机制去获取与问题相关的视觉特征和历史特征,比如bottom-up[2]、attentionmemory[3]、rva[4]、sequentialco-attention[5]等。bottom-up提出了一种自下而上和自上而下的组合注意力机制,视觉对话任务通过fasterr-cnn网络获取图像中的实体特征,利用注意力机制获取与问题相关的视觉特征;attentionmemory提出了一种注意力存储机制,通过利用过去对话中的视觉注意力分布来计算与当前问题相关的视觉注意力分布,从而更好地选择与问题相关的视觉内容;rva提出了一种递归视觉注意力机制,利用历史对话中相关的视觉信息,逐步细化与当前问题相关的视觉注意力分布;sequentialco-attention提出了一种连续的共注意力机制,利用其余两种模态的信息来计算另一模态的注意力得分,有选择地关注图像和历史对话的内容。上述方法将获取到的视觉特征、历史特征与问题特征进行后期融合,利用融合后的向量对候选答案进行预测。然而,在对不同模态的特征进行分别提取后,利用后期融合对不同模态特征进行融合的方法,不能很好地捕获不同模态间的关联信息,使得模型在预测候选答案时不够准确。为了获得更多的有用信息,不同模态信息融合的方法有待改进。
为了实现效果更好的视觉对话模型,目前的主要挑战是:视觉对话任务需要对图像内容和对话历史进行建模,并从问题向量、视觉向量和历史向量中,获取到对答案预测有用的信息。答案的预测不仅需要关注不同模态内的特征信息,还需要关注不同模态间的关联信息,通过对模态内特征信息和模态间关联信息进行捕获,才能更好地预测答案。所以如何更好地捕获不同模态间的关联信息,是视觉对话模型需要解决的问题。
参考文献:
[1]das,a.,kottur,s.,etal.“visualdialog.”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2017.
[2]anderson,peter,etal.“bottom-upandtop-downattentionforimagecaptioningandvisualquestionanswering.”proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,2018.
[3]sigal,leonid,etal.“visualreferenceresolutionusingattentionmemoryforvisualdialog.”advancesinneuralinformationprocessingsystems,vol.30,2018,pp.3719–3729.
[4]niu,yulei,etal.“recursivevisualattentioninvisualdialog.”ieee/cvfconferenceoncomputervisionandpatternrecognition(cvpr),2019,pp.6679–6688.
[5]wu,qi,etal.“areyoutalkingtome?reasonedvisualdialoggenerationthroughadversariallearning.”ieee/cvfconferenceoncomputervisionandpatternrecognition,2018,pp.6106–6115.
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种基于kr积融合多模态信息的神经网络视觉对话模型及方法,通过分别提取不同模态的信息,利用后期融合的方法融合不同模态内的特征信息,利用khatri-rao(kr)积的方法捕获不同模态间的关联信息,融合这两种特征信息进行候选答案预测,并利用反向传播、随机梯度下降优化方法训练网络模型,得到最优模型在验证集上预测结果,最终得到更加准确的结果。
本发明的目的是通过以下技术方案实现的:
一种基于kr积融合多模态信息的神经网络视觉对话模型,包括模态特征提取模块、不同模态信息融合模块和候选答案预测模块;
所述模态特征提取模块通过提取问题的语义特征,图像的视觉特征和历史对话的历史特征;最终得到问题特征、视觉特征和历史特征;
不同模态信息融合模块用于融合问题特征、视觉特征和历史特征得到最终的融合向量,综合考虑不同模态的信息,便于捕获与候选答案相关的信息;具体包括获取不同模态内的特征信息、提取不同模态间的关联信息、融合模态内与模态间的信息三个步骤;
候选答案预测模块用于对候选答案进行预测,候选答案预测模块的输入为不同模态信息融合模块得到的融合向量,然后与候选答案的特征向量进行内积计算,得到候选答案对应的得分。
进一步的,所述模态特征提取模块中通过对问题文本进行分词,利用glove工具学习单词在word2vec模型中的嵌入表示,每个单词由一个稠密向量表示,然后利用lstm模型获取问题的语义特征即问题特征;
利用fasterr-cnn预训练网络提取图像中的实体特征,每个实体都是由一个稠密向量表示,通过注意力机制获取与问题相关的注意力分布,对实体特征进行加权求和来获取图像的视觉特征;
将历史对话信息进行拼接,对历史信息进行分词,利用glove工具学习单词在word2vec模型中的嵌入表示,利用lstm模型获取历史对话的历史特征。
进一步的,获取不同模态内特征信息的方法中首先将问题特征、视觉特征和历史特征进行拼接,然后经过全连接层融合三者的特征,最后得到不同模态内的特征信息;
提取不同模态间关联信息的方法首先会通过两次kr积计算,得到两个交互矩阵,第一次kr积计算先将问题特征、视觉特征和历史特征按第0维进行拼接,生成一个特征矩阵,对特征矩阵按列进行kr积计算,产生一个三阶张量;对三阶张量进行mask计算,通过卷积操作捕获三阶张量的信息,得到交互后的特征矩阵;第二次kr积计算将交互后得到的特征矩阵和原始的特征矩阵按对应列进行kr积计算,对得到的三阶张量进行卷积操作,产生一个交互后的特征矩阵;然后将两次得到的交互矩阵进行拼接、压缩得到最终的特征,最终的特征包含模态间的关联信息;
最后,将后期融合得到的模态内特征信息与kr积融合得到的模态间关联信息进行拼接,得到最终的融合向量,融合向量中包含模态内的特征信息与模态间的关联信息。
进一步的,候选答案预测模块用于对若干个候选答案进行预测,得到每个候选答案的得分,对比真实答案计算loss,然后利用反向传播算法不断更新神经网络视觉对话模型的参数,最终得到每个候选答案对应的得分。
本发明还提出一种基于kr积融合多模态信息的神经网络视觉对话方法,基于上述神经网络视觉对话模型,包括以下步骤:首先通过后期融合方法捕获不同模态内的特征信息,然后利用kr积的计算方式捕获不同模态间的关联信息,最后将模态内的特征信息与模态间的关联信息进行拼接,得到最终的融合向量;所述后期融合方法是将捕获到的问题特征、视觉特征和历史特征进行拼接,进行线性层融合。
与现有技术相比,本发明的技术方案所带来的有益效果是:
1.提出了一种基于kr积的不同模态信息融合模块,该模块用于捕获不同模态间的关联信息。之前的相关工作大多聚焦于分别捕获与当前问题相关的视觉特征和历史特征,然后通过后期融合的方法将视觉特征、问题特征和历史特征进行融合,但后期融合的方法没有深入考虑不同模态之间的关联。基于kr积的方法,利用张量积的计算方式,组合不同模态间的信息,捕获不同模态间的关联信息。
2.在kr积的基础上提出一种基于mask机制的冗余特征减少方法。在基于kr积的第一层特征组合的过程中,由于输入的特征矩阵是相同的,按列进行张量计算的方式,导致得到的矩阵是对称矩阵,包含重复的组合信息;为了减少不同模态间信息组合所产生的冗余信息,结合mask机制将重复的组合信息进行删减。将第一层组合特征中的冗余特征剔除后,将其用于第二层的特征组合时,可以更加准确地捕获模态间的关联信息;
3.本发明中的神经网络视觉对话模型一方面通过后期融合的方法捕获模态内的特征信息,另一方面通过kr积+mask机制+卷积神经网络的方法捕获模态间的关联信息,进而将这两部分信息通过拼接的方法进行融合。由于kr积计算需要先将视觉特征、问题特征和历史特征映射到同一向量空间中,再通过kr积+mask机制+卷积神经网络的方法捕获模态间的关联信息;这样的方法虽然捕获到了模态间潜在的关联信息,但却损失了不同模态内的特征信息。为了保留不同模态内的特征信息,首先通过后期融合的方法捕获模态内的信息,然后与基于kr的方法捕获的模态间关联信息进行拼接融合,使得最终的融合向量中包含模态内的特征信息与模态间的关联信息。与相关工作相比,融合了模态间关联信息的方法,提高了答案预测的结果。
附图说明
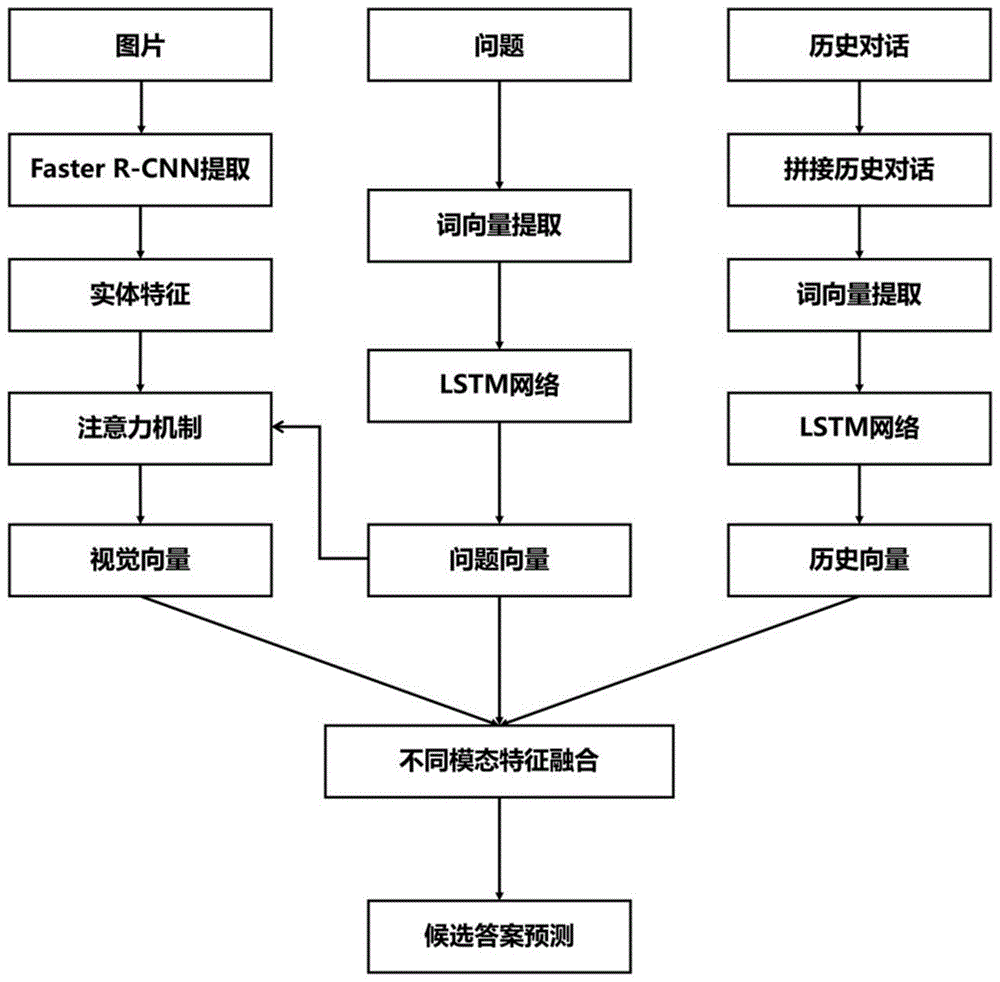
图1为本发明的方法流程图;
图2为基于kr积融合多模态信息的视觉对话模型图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
一种基于kr积融合多模态信息的神经网络视觉对话模型,包括模态特征提取模块、不同模态信息融合模块和候选答案预测模块;
模态特征提取模块用于提取问题的语义特征,图像的视觉特征和历史对话的历史特征。首先通过lstm网络获取问题的向量表示,利用fasterr-cnn网络获取图像的一组实体特征向量,将历史对话信息视为一个整体或每轮对话内容视为一个整体,经过lstm网络获取对话历史的向量表示;然后,通过注意力机制计算与问题相关的视觉注意力分布和历史注意力分布,通过加权求和的方法获得视觉向量和历史向量。
不同模态信息融合模块用于融合问题特征、视觉特征和历史特征。通过模态特征提取模块获得的问题向量、视觉向量和历史向量,利用后期融合方法将三者的信息进行融合,捕获不同模态内的特征信息;通过基于kr积的多模态信息融合的方法对问题向量、视觉向量和历史向量进行特征组合,捕获不同模态间的关联信息;最后,将不同模态内的信息和不同模态间的信息进行拼接,得到最终的融合向量。
候选答案预测模块通过lstm网络获得100个候选答案的答案向量,与不同模态信息融合模块得到的融合向量进行内积计算,获得100个候选答案的得分。
图1显示了本方法提出的视觉对话方法的流程;图2显示了本实施例设计的神经网络视觉对话模型。本发明方法的具体操作步骤如下:
(1)遍历visdialv1.0数据集(visdialv1.0数据集通过视觉对话官网进行下载,网址为https://visualdialog.org/data)中的所有问题,确定问题输入的固定长度(一般为数据集中的最大句子长度),对数据集中句子长度小于固定长度的句子进行填充,剩余的长度补0,保证所有句子定长,便于神经网络和注意力机制计算。
(2)遍历数据集中的所有答案,确定答案文本的固定长度,对数据集中句子长度小于固定长度的句子进行填充,剩余的长度补0,保证所有句子定长,便于神经网络的计算。
(3)利用glove工具获取300维的词向量wi,用于构建词向量矩阵e=[w1,...,wn],矩阵每一个行表示一个单词,模型初始化阶段直接使用该矩阵作为词向量矩阵,并将词向量矩阵设定为可训练,在模型训练过程中词向量矩阵将会被优化。
(4)使用预训练好的fasterr-cnn网络,提取每张图片对应的特征向量,每张图片生成一个36×2048的矩阵
(5)第t轮的问题向量qt通过lstm网络得到;历史信息由图片标题和历史中每轮问答信息组成,将图片的标题信息与所有问答信息进行拼接,经过lstm网络,获得历史向量ht。
(6)利用注意力机制获得与问题相关的视觉向量vt,计算公式如下:
其中,
(7)利用后期融合的方法对获取到的问题向量、视觉向量和历史向量进行融合,得到包含模态内特征信息的向量
其中,[·]表示拼接操作,向量[qt;vt;ht]∈r3072,矩阵w3∈r3072×512,向量
(8)利用基于kr积的多模态信息融合方法捕获问题向量、视觉向量和历史向量之间的关联信息,得到包含模态间关联信息的向量
其中wmask∈r3×3为上三角数值为1,其余数值为0的mask矩阵,
(9)拼接步骤(7)和步骤(8)的输出,候选答案的向量
其中,向量
计算候选答案分值与真实答案分值之间的交叉熵,然后通过反向传播,不断更新模型的参数。
(10)最后本发明的方法应用于rva和lf模型上,在visdialv1.0数据集上进行训练和测试,测试的评价指标为r@1、r@5、r@10、mean(meanrank)、mrr(meanreciprocalrank)和ndcg(normalizeddiscountedcumulativegain)。从表1的实验结果可以看出,基于后期融合获取多模态信息的方法,对于不同模态间的关联信息捕获不足;本发明利用基于kr积融合多模态信息的方法,捕获不同模态间的关联信息,与不同模态内的特征信息进行拼接,得到最终的融合向量,实验表明通过捕获不同模态间的关联信息可以提高视觉对话模型的整体效果。
表1各模型在visdialv1.0数据集上的结果对比
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!