实木板材的一维排样方法
本发明涉及计算机辅助排样方法,具体涉及实木板材的一维排样方法。
背景技术:
实木板材由于存在一定的缺陷,在经图像识别缺陷种类和尺寸后,通过锯切缺陷将得到数段多规格的实木板材,由于锯切后的实木板材尺寸与加工的标准尺寸不相符,所以为了后续加工的顺利开展,需要将其分割成标准尺寸。
传统的人工经验排样的方法由于缺少统一规划和全局观念,不仅排样效果不能满足生产需求,同时耗费的时间随着待排件数量的增加而上升。
而目前的一维实木板材排样算法大多采用人工智能的方法求解,如遗传算法、模拟退火算法或蚁群算法等,这些算法的局部搜索能力和全局搜索能力很难达到平衡,单独使用则会导致排样时间长和利用率不高等问题的出现,不能获得满意的排样方案。
技术实现要素:
本发明所要解决的技术问题是针对上述现有技术的不足提供一种实木板材的一维排样方法,本实木板材的一维排样方法以改进最大最小蚁群系统的解作为遗传算法的初始种群,克服了随机选择的盲目性;通过改进遗传算法的多次迭代得到的最优解转化为全局信息素的积累,加快了蚁群系统的收敛速度,提高了求解速率,排样时间快,实木板材利用率高;有助于维持种群多样性,减少局部最优和早熟问题的出现,增强了算法的全局搜索能力;采用迭代最优解和全局最优解的动态混合策略,有助于增强算法合理引导搜索的能力。
为实现上述技术目的,本发明采取的技术方案为:
一种实木板材的一维排样方法,包括:
步骤1:读取经切割缺陷后的n段实木板材长度li信息,其中i=1,2,…,n,对所有实木板材从0开始编号,范围为[0,n-1];读取需求量为bj的待排零件的长度lj信息,其中j=1,2,…,s,对所有零件从0开始编号,范围为
步骤2:初始化算法参数;
步骤3:建立实木板材一维排样数学模型:
实木板材经切割缺陷后将得到n段多规格的板材li,需求量为bj的长度分别为lj的零件s种,应满足切割需求:零件的切割量cj需等于需求量bj,且每段实木板材上所排零件总长度需小于等于该段实木板材长度;
以实木板材的利用率u最大为目标函数,具体的数学模型如下所示:
其中aij为在第i段实木板材上排列的第j种零件的数量;;l为排样方案中所选用的实木板材总长度;
步骤4:令迭代次数计数器iter=0;
步骤5:基于改进最大最小蚁群系统的方法生成初始种群:
先选择一段未用实木板材,根据转移概率选择未用零件,当选中零件编号时更新局部信息素,重复此操作直至没有长度小于等于所选实木板材的剩余长度的未用零件存在,重复上述过程,直至所有零件都完成排样,得到m个排样方案;
步骤6:基于改进遗传算法多次迭代得到最优排样方案,即迭代最优解;
步骤7:将改进遗传算法得到的迭代最优解进行记录;
步骤8:根据记录中的至今最优解自适应更新信息素的界限;
步骤9:采用动态混合策略进行信息素更新;
步骤10:判断是否满足迭代终止条件iter≤t,若不满足,迭代次数iter=iter+1,转步骤5;若满足,则输出具有最大适应度值的排样方案,结束算法,其中排样方案的适应度函数为目标函数。
作为本发明进一步改进的技术方案,所述步骤2具体包括:
初始化算法参数,其中算法参数包括种群规模m、改进蚁群算法最大迭代次数t、改进遗传算法最大迭代次数nc、常量q0、实木板材禁忌表、零件禁忌表和信息素矩阵τ,其中q0∈[0,1],信息素矩阵τ为二维矩阵,二维矩阵的行是实木板材的编号,列是零件的编号,令路径(i,j)上的初始信息素τij(0)=τmax(1),其中τmax(1)表示第一次迭代后所计算的最大信息素。
作为本发明进一步改进的技术方案,所述步骤5包括以下步骤:
5.1、将实木板材和零件进行混合,形成n+m个节点,其中n为实木板材的数量,m为零件的数量,各节点代表其编号;
5.2、将所有的未用实木板材编号作为可选节点放入n-code,n-code即为所有实木板材编号与实木板材禁忌表的差集;
5.3、蚂蚁首先从n-code中选择一个实木板材节点ni作为出发点,ni的选择规则如下:min(lmin-(kmax+r))≥0,即所选的未用实木板材的长度lmin与最长未用零件的长度kmax和正随机数r的和的差应最小,r∈[0,lmax-kmax],其中lmax为最长未用实木板材的长度;
5.4、将所有的未用零件编号作为可选节点放入m-code,m-code即为所有零件编号与零件禁忌表的差集;
5.5、选中实木板材节点ni后,根据当前所选实木板材的剩余可排长度ls和可选m-code中各个零件节点对应的零件长度kj计算启发信息ηij,并根据伪随机比例状态转移规则选择零件节点mj;
5.6、当选中零件节点mj后,按照如下公式进行局部信息素更新:
τij(t+1)=(1-χ)*τij(t);
其中χ表示局部信息素挥发系数,χ∈(0,1);τij(t)表示实木板材节点ni和零件节点mj间在第t次信息素浓度;τij(t+1)表示第t+1次信息素浓度;
5.7、将所选实木板材节点ni放入实木板材禁忌表,将所选零件节点mj放入零件禁忌表;
5.8、清空未用实木板材编号集合n-code和未用零件编号集合m-code;
5.9、判断零件禁忌表中是否包含所有零件编号,若是,转5.10;否则,判断是否存在长度小于等于当前实木板材剩余长度的未用零件,若存在,转5.4,若不存在,转5.2;
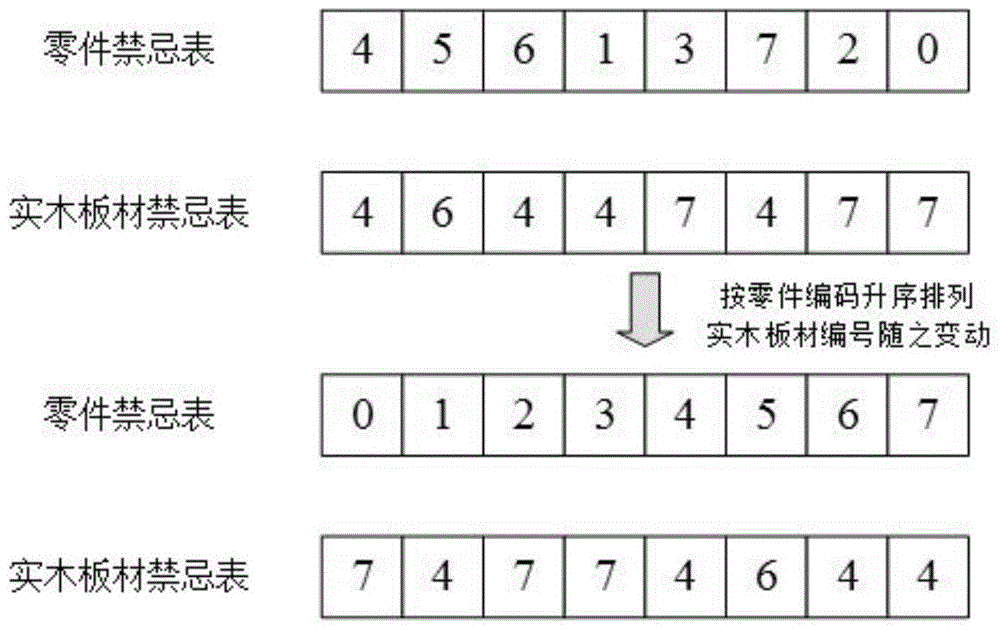
5.10、将所有零件禁忌表中的编号按升序排列,同时实木板材禁忌表中所有实木板材编号按对应位置随之变化,变化后的实木板材禁忌表中的实木板材编号即为一个排样方案;
5.11、清空实木板材禁忌表和零件禁忌表,对下一只蚂蚁重复5.2至5.10,直至遍历所有m只蚂蚁,得到m个排样方案。
作为本发明进一步改进的技术方案,所述步骤5.5中的伪随机比例状态转移规则为:
5.5.1、产生随机数rand,rand∈[0,1];
5.5.2、若rand≤q0,则选择使得[τis]α*[ηis]β最大的零件节点mj,否则转5.5.3;
5.5.3、按下式计算当前实木板材节点ni到可选零件节点a的转移概率pa:
其中,α表示信息启发式因子;β表示期望启发式因子;τia表示实木板材节点ni选择编号为a的零件节点进行排样的信息素浓度,a∈m-code;
5.5.4、根据轮盘赌选择法,从m-code中选取零件节点mj。
作为本发明进一步改进的技术方案,所述步骤6具体包括以下步骤:
6.1、令迭代次数计数器t=0;
6.2、计算每个排样方案的适应度函数,其中适应度函数为步骤3中的目标函数;
6.3、将m个排样方案中适应度最大的排样方案进行记录;
6.4、利用每个排样方案的浓度和适应度计算出被选概率,基于被选概率,重复m次轮盘赌选择,选出进行交叉变异的染色体,所述染色体即为排样方案,其中被选概率fc为:
其中,f(i)为排样方案i的适应度;ci为排样方案i在种群中的浓度;k取负数;δ为相似度阈值,δ∈[0,1];abi,k和abj,k分别为排样方案i和排样方案j的第k位;d为排样方案的长度;s为相似度;
6.5、将m个染色体两两进行两点交叉操作;
6.6、对交叉概率pc进行自适应调整:
其中,pc1和pc2为0至1之间的常数;favg为种群平均适应度;fmax为种群中最大适应度;f为待交叉两个染色体中较大的适应度;a为常量;
6.7、将m个染色体进行单点变异操作,同时需保证替换的实木板材编号满足约束条件:
6.7.1、随机选取一个变异点位置position_m,即在[0,d-1]之间等概率的选取一个整数position_m;
6.7.2、将长度大于等于position_m所对应零件长度的,且和原来编号不相同的实木板材编号放入可选集choose_list中;
6.7.3、判断可选集choose_list是否为空集,若是,转6.7.1;否则,从choose_list中随机选择实木板材的替换编号new_code;
6.7.4、判断原来的排样方案中是否包括new_code,若否,转6.7.5;否则,判断原来排样方案中new_code对应的所有零件长度与position_m对应零件长度之和是否小于等于编号为new_code的实木板材长度,若是,转6.7.5;否则,转6.7.1;
6.7.5、new_code替换排样方案中position_m对应的实木板材编号;
6.8、根据约束条件:每段实木板材上所排零件总长应小于等于该段实木板材的长度,删除不符合该约束条件的染色体并更新适应度;
6.9、相同或相似的个体容易造成后代产生多余信息,影响算法收敛效率,因此,为了保持种群的多样性,结合免疫算法思想,利用相似度阈值δ来消除冗余个体,具体步骤为:
6.9.1、对于相似度s=1的个体,随机删除其中一个;
6.9.2、将其他所有个体相似度大于δ的两个体划为同一区域;
6.9.3、两两比较个体的浓度c,如果c不相等,则删除浓度高的个体,否则转6.9.4;
6.9.4、比较两个体的适应度fit,如果fit不相等,则删除适应度值小的个体,否则转6.9.5;
6.9.5、随机删除其中一个个体;
6.9.6、重复6.9.3至6.9.5,直至区域内的个体都比较过;
6.10、为了达到预先设定的种群规模m,需要产生新个体补充种群,采用步骤5中最大最小蚁群系统的方法生成新的排样方案,将新个体和当前种群内的个体进行相似度比较,如果新个体和种群内任一个体相似度均小于相似度阈值δ,则将新个体加入种群内,否则舍弃;
6.11.将6.3中所记录的最优排样方案替换种群中适应度最差的排样方案;
6.12.判断是否满足迭代终止条件t≤nc,若不满足条件,迭代次数t=t+1,转6.2;若满足条件,则输出具有最大适应度值的最优排样方案,即迭代最优解,结束遗传算法。
作为本发明进一步改进的技术方案,所述的步骤8具体为:
根据记录中的至今最优解自适应更新信息素的界限:
其中,ρ为全局信息素挥发系数,ρ∈(0,1);τmax和τmin分别为信息素的上限和下限;q表示蚂蚁在经过的路径上所释放的信息素总量;n为至今最优排样方案中的节点数;
作为本发明进一步改进的技术方案,所述的步骤9具体为:
采用动态混合策略进行信息素更新:
默认使用迭代最优解进行信息素更新,每隔固定循环次数n就使用至今最优解antbest进行信息素更新,且被限制在区间[τmax,τmin]内以避免算法过早地收敛于最优解:
作为本发明进一步改进的技术方案,所述的步骤9和步骤10之间还需进行局部收敛判断:
由于最大最小蚁群系统的信息素正反馈机制,使得到的最优排样方案可能为局部最优排样方案,当所得至今最优排样方案的适应度连续n次未改变,则为了跳出局部最优排样方案,采用平滑信息素机制和参数自适应两种方法:
(3)平滑信息素机制:
其中,γ为平滑系数,γ∈(0,1);τij(t)和
(4)参数自适应:
为了提高算法的搜索能力和收敛速度,动态调整全局信息素挥发系数:
ρ(t)=max{θ·ρ(t-1),ρmin};
其中,θ为衰减系数,θ∈(0,1);ρmin为最小全局信息素挥发系数;
伪随机比例状态转移规则中的q0的大小影响了蚂蚁接受随机方案的概率,利用下式减小q0,增大接受随机方案的概率,跳出局部最优排样方案:
其中,t为正常数,n是停滞次数,t为设置的最大迭代次数。
与现有技术相比,本方法具有以下有益效果:
(1)采用嵌套式结构,以改进最大最小蚁群系统的解作为遗传算法的初始种群,克服了随机选择的盲目性;通过改进遗传算法的多次迭代得到的最优解转化为全局信息素的积累,加快了蚁群系统的收敛速度,提高了求解速率。
(2)结合免疫算法思想,引入浓度因子对轮盘赌选择法中的被选概率进行调整,并根据相似度阈值消除冗余个体,通过免疫补充维持种群规模,同时交叉概率的自适应化,有助于维持种群多样性,减少局部最优和早熟问题的出现,增强了算法的全局搜索能力。
(3)融合基本最大最小蚁群系统算法有范围限制的全局信息素更新和acs算法的局部信息素更新,同时在全局信息素更新阶段,采用迭代最优解和全局最优解的动态混合策略,有助于增强算法合理引导搜索的能力;信息素平滑机制和参数自适应化加大了算法跳出局部最优的可能。
附图说明
图1为重新编码方式。
图2为本方法所采用的两点交叉操作图。
图3为本方法的算法流程图。
具体实施方式
下面将结合附图对本方法的具体实施方法作进一步详细的说明。
图3是本方法的流程图,如图3所示,实木板材的一维排样方法包括以下步骤:
步骤1、读取经切割缺陷后的n段实木板材长度li(i=1,2,…,n)信息,对所有实木板材从0开始编号,范围为[0,n-1];读取需求量为bj(j=1,2,…,s)的待排零件的长度lj(j=1,2,…,s)信息,对所有零件从0开始编号,范围为
步骤2、初始化算法参数,包括种群规模m、改进蚁群算法最大迭代次数t、改进遗传算法最大迭代次数nc、常量q0(q0∈[0,1])、实木板材禁忌表、零件禁忌表和初始化信息素矩阵τ(二维矩阵,第一维代表n个实木板材,每一维都有m个规格板材),为了增加蚂蚁在初始阶段探索新解的能力,令路径(i,j)上的初始信息素τij(0)=τmax(1)(τmax(1)表示第一次迭代后所计算的最大信息素)。其中二维矩阵的行是指实木板材的编号,列是零件的编号,每个信息素对应的就是[实木板材编号,零件编号],代表当蚂蚁在选中实木板材之后,选择各零件时的信息素浓度,再根据信息素浓度和η计算出该零件被选概率。
步骤3、将实木板材一维排样问题转化为数学问题,建立数学模型:
实木板材经锯切缺陷后将得到n段多规格的板材li(i=1,2,…,n),需求量为bj(j=1,2,…,s)的长度分别为lj(j=1,2,…,s)的零件s种,应能满足切割需求:零件的切割量cj需等于需求量bj(j=1,2,…,s),且每段实木板材上所排零件总长需小于等于该段实木板材长度。
以实木板材的利用率u最大为目标函数,具体的数学模型如下所示:
其中,aij为在第i段实木板材上排列的第j种零件的数量;l为排样方案中所选用的实木板材总长度。
步骤4、令迭代次数计数器iter=0。
步骤5、基于改进最大最小蚁群系统生成初始种群:可描述为先选择一段未用实木板材,根据转移概率选择未用零件,重复此操作直至没有长度小于等于所选实木板材的剩余长度的未用零件存在,重复上述过程,直至所有零件都完成排样。将蚂蚁所寻排样方案进行重新编码作为遗传算法的初始种群。具体步骤为:
5.1、将实木板材和零件进行混合,形成n+m个节点(n为实木板材的数量,m为零件的数量),各节点代表其编号;
5.2、将所有的未用实木板材编号作为可选节点放入n-code,n-code即为所有实木板材编号与实木板材禁忌表的差集;
5.3、蚂蚁首先从n-code中选择一个实木板材节点ni作为出发点,ni的选择规则如下:min(lmin-(kmax+r))≥0,即所选的未用实木板材的长度lmin与最长未用零件的长度kmax和正随机数r的和的差应最小,r∈[0,lmax-kmax](lmax为最长未用实木板材的长度,lmin为所选的未用实木板材的长度,kmax为最长未用零件的长度;r为正随机数);
5.4、将所有的未用零件编号作为可选节点放入m-code,m-code即为所有零件编号与零件禁忌表的差集;
5.5、选中实木板材节点ni后,根据当前所选实木板材的剩余可排长度ls和可选m-code中各个零件节点对应的零件长度kj计算启发信息ηij,并根据伪随机比例状态转移规则选择零件节点mj;
5.6、当选中零件节点mj后,按照如下公式进行局部信息素更新:
τij(t+1)=(1-χ)*τij(t);
其中,χ表示局部信息素挥发系数,χ∈(0,1);τij(t)表示实木板材节点ni和零件节点mj间在第t次信息素浓度;τij(t+1)表示第t+1次信息素浓度。
5.7、将所选实木板材节点ni放入实木板材禁忌表,将所选零件节点mj放入零件禁忌表;
5.8、清空未用实木板材编号集合n-code和未用零件编号集合m-code;
5.9、判断零件禁忌表中是否包含所有零件编号,若是,转5.10;否则,判断是否存在长度小于等于当前实木板材剩余长度的未用零件,若存在,转5.4,若不存在,转5.2。
5.10、如附图1所示,将所有零件禁忌表中的编号按升序排列,同时实木板材禁忌表中所有实木板材编号按对应位置随之变化,变化后的实木板材禁忌表中的实木板材编号即为一个排样方案;
5.11、清空禁忌表,对下一只蚂蚁重复5.2至5.10,直至遍历所有m只蚂蚁,得到m个排样方案。
进一步的,5.5中的伪随机比例状态转移规则为:
(1)产生随机数rand,rand∈[0,1];
(2)若rand≤q0,则选择使得[τis]α*[ηis]β最大的零件节点mj,否则转(3);
(3)按下式计算当前实木板材节点ni到可选零件节点a的转移概率pa:
其中,α表示信息启发式因子;β表示期望启发式因子;τia表示实木板材节点ni选择编号为a的零件节点进行排样的信息素浓度,a∈m-code;
(4)根据轮盘赌选择法,从m-code中选取零件节点mj。
步骤6、基于改进遗传算法多次迭代得到最优排样方案:根据所述优化目标函数对各排样方案进行评估,并利用遗传算法中的遗传操作对其进行优化,通过基于浓度的轮盘赌法选出进行后续操作的染色体,根据自适应交叉概率和固定变异概率,对种群进行两点交叉和单点变异操作,并引入免疫算法思想,利用相似度阈值消除冗余染色体,和步骤5相同方法生成排样方案以维持种群规模,同时对种群进行精英保留操作,当迭代次数大于预设值时终止遗传算法,得到实木板材的最优排样方案。嵌套的改进遗传算法的具体步骤包括:
6.1、令迭代次数计数器t=0;
6.2、计算每个排样方案的适应度函数fit,其中适应度函数为目标函数;
6.3、将m个排样方案中适应度最大的排样方案进行记录;
6.4、利用轮盘赌法选择进行交叉变异的染色体,为了有效留住优秀个体和保持个体多样性,引入浓度概念,对被选概率fc进行改进:
其中,f(i)为排样方案i的适应度;ci为排样方案i在种群中的浓度;k取负数;δ为相似度阈值,δ∈[0,1];abi,k和abj,k分别为排样方案i和排样方案j的第k位;d为排样方案的长度;s为相似度。
6.5、如附图2所示,将m个染色体两两进行两点交叉操作;
6.6、交叉概率是影响算法行为和性能的关键所在,交叉概率pc越大,新个体产生的速度就越快,然而,交叉概率pc过大时,算法模式被破坏的可能性也越大,使得具有高适应度的个体结构很快被破坏,但如果交叉概率过小,会使搜索过程缓慢,以至停滞不前,所以通过如下公式对交叉概率pc进行自适应调整:
其中,pc1和pc2为0至1之间的常数;favg为种群平均适应度;fmax为种群中最大适应度;f为待交叉两个染色体中较大的适应度;a为常量。
6.7、将m个染色体进行单点变异操作,同时需保证替换的实木板材编号满足约束条件:
(1)、随机选取一个变异点位置position_m(即在[0,d-1]之间等概率的选取一个整数position_m);
(2)、将长度大于等于position_m所对应零件长度的,且和原来编号不相同的实木板材编号放入可选集choose_list中;
(3)、判断可选集choose_list是否为空集,若是,转(1);否则,从choose_list中随机选择实木板材的替换编号new_code;
(4)、判断原来的排样方案中是否包括new_code,若否,转(5);否则,判断原来排样方案中new_code对应的所有零件长度与position_m对应零件长度之和是否小于等于编号为new_code的实木板材长度,若是,转(5);否则,转(1);
(5)、new_code替换排样方案中position_m对应的实木板材编号。
6.8、根据约束条件:每段实木板材上所排零件总长应小于等于该段实木板材的长度,删除不符合约束条件的染色体并更新适应度;
6.9、相同或相似的个体容易造成后代产生多余信息,影响算法收敛效率,因此,为了保持种群的多样性,结合免疫算法思想,利用相似度阈值δ来消除冗余个体,具体步骤为:
(1)、对于相似度s=1的个体,随机删除其中一个;
(2)、将其他所有个体相似度大于δ的两个体划为同一区域;
(3)、两两比较个体的浓度c,如果c不相等,则删除浓度高的个体,否则转(4);
(4)、比较两个体的适应度fit,如果fit不相等,则删除适应度值小的个体,否则转(5);
(5)、随机删除其中一个个体;
(6)、重复(3)至(5),直至区域内的个体都比较过。
6.10、为了达到预先设定的种群规模m,需要产生新个体补充种群,采用与步骤5中最大最小蚁群系统的方法生成新的排样方案,为了开拓新的搜索范围和避免新个体和种群内的个体相似,将新个体和当前种群内的个体进行相似度比较,如果新个体和种群内任一个体相似度均小于相似度阈值δ,则将新个体加入种群内,否则舍弃;
6.11、将6.3中所记录的最优排样方案替换种群中适应度最差的排样方案;
6.12、判断是否满足迭代终止条件t≤nc,若不满足条件,迭代次数t=t+1,转6.2;若满足条件,则输出具有最大适应度值的最优排样方案(迭代最优解),结束遗传算法;
步骤7、将改进遗传算法得到的迭代最优解进行记录;
步骤8、根据记录中的至今最优解自适应更新信息素的界限:
其中,ρ为全局信息素挥发系数,ρ∈(0,1);τmax和τmin分别为信息素的上限和下限;q表示蚂蚁在经过的路径上所释放的信息素总量;n为至今最优排样方案中的节点数;
步骤9、为了避免单纯使用迭代最优引起的盲目性,以及单纯使用至今最优解丧失的探索性,通过以下公式更新全局信息素,采用动态混合策略:默认使用迭代最优解进行信息素更新,每隔固定循环次数n就使用至今最优解antbest进行信息素更新,且被限制在区间[τmax,τmin]内以避免算法过早地收敛于最优解:
其中edge(i,j)∈antbest表示选中的最优排样方案里存在编号[实木板材编号i,对应零件编号j]。
步骤10、判断是否满足迭代终止条件iter≤t,若不满足,迭代次数iter=iter+1,转步骤5;若满足,则输出具有最大适应度值的排样方案,结束算法。
进一步的,步骤9和步骤10之间还需进行局部收敛判断,即当在一定数量的迭代中不再有更优排样方案出现时,采用信息素平滑机制并自适应部分参数:
由于最大最小蚁群系统的信息素正反馈机制,使得到的最优排样方案可能为局部最优排样方案,当所得至今最优排样方案的适应度连续n次未改变,则为了跳出局部最优排样方案,采用平滑信息素机制和参数自适应两种方法:
(1)、平滑信息素机制:
其中,γ为平滑系数,γ∈(0,1);τij(t)和
(2)、参数自适应:
为了提高算法的搜索能力和收敛速度,动态调整全局信息素挥发系数:
ρ(t)=max{θ·ρ(t-1),ρmin};
其中,θ为衰减系数,θ∈(0,1);ρmin为最小全局信息素挥发系数。
伪随机比例状态转移规则中的q0的大小直接影响了蚂蚁接受随机方案的概率,利用下式减小q0,增大接受随机方案的概率,跳出局部最优。
其中,t为正常数,n是停滞次数,t为设置的最大迭代次数,q0的初始值为设置的[0,1]的定值。
本实施例中的迭代最优解是本次迭代得到具有最大利用率的排样方案,至今最优解是从第一次迭代到当前迭代得到的所有迭代最优解中具有最大利用率的排样方案,全局最优解即为至今最优解。
本发明的保护范围包括但不限于以上实施方式,本发明的保护范围以权利要求书为准,任何对本技术做出的本领域的技术人员容易想到的替换、变形、改进均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!