基于NVM进行AI计算的芯片架构的制作方法
基于nvm进行ai计算的芯片架构
技术领域
1.本发明涉及ai(artificial intelligence,人工智能)技术领域,特别涉及一种基于nvm(non
‑
volatile memory,非易失性存储)进行ai计算的芯片架构。
背景技术:
2.ai的算法来源于人脑的结构的启示。人脑是一个由大量神经元复杂连接的网络,每个神经元通过大量的树突连接大量的其他神经元,接收信息,每一个连接点叫突触(synapse)。在外部刺激积累到一定程度后,产生一个刺激信号,通过轴突传送出去。轴突有大量的末梢,通过突触,连接到大量其他神经元的树突。就是这样一个由简单功能的神经元组成的网络,实现了人类所有的智能活动。人的记忆和智能,普遍被认为存储在每一个突触的不同的耦合强度里。
3.从上世纪60年代兴起的神经网络算法,用一个函数来模仿神经元的功能。函数接受多个来自其他神经元的输入,每个输入有不同的权重,输出是每一个输入与相应的神经元连接权重相乘再求和。函数输出再输入到下一层其他的神经元,组成一个神经网络。
4.常见的ai芯片在算法上针对网络计算优化了矩阵并行计算,但因为ai计算需要极高的存储读取带宽,把处理器和内存、存储分离的架构遇到了读取速度的瓶颈,也受限于外部存储读取功耗。业界已经开始广泛研究存储内计算(in
‑
memory
‑
computing)的架构。
5.目前采用nvm的存储内计算的方案,都是利用nvm采用模拟信号的形式存储神经网络中的权重,把神经网络的计算通过模拟信号加乘的方法实现,具体范例参见公开号为cn109086249a的中国专利申请。这类方案已经有了不少科研成果,但实际应用仍有困难。因为实用的神经网络基本都有很多的层和非常复杂的连接结构,模拟信号在实现神经网络计算过程中在层间的传递、进行各种信号处理时非常不方便,模拟计算阵列结构僵化,不利于支持灵活的神经网络结构。另外,模拟信号的存储、读写与计算中各种噪音和误差会影响到存储的神经网络模型的可靠性和计算的准确性受限。
技术实现要素:
6.本发明的目的是提供一种基于nvm进行ai计算的芯片架构,克服现有的存储内计算的方案利用nvm采用模拟信号的形式存储神经网络中的权重时,模拟信号在实现神经网络计算过程中在层间的传递、进行各种信号处理时非常不方便,模拟计算阵列结构僵化,不利于支持灵活的神经网络结构,以及模拟信号的存储、读写与计算中各种噪音和误差会影响到存储的神经网络模型的可靠性和计算的准确性受限的缺陷,提供一种在突破了外部存储的速度瓶颈及降低外部输入的功耗的同时又具有更好的灵活性、高度的可实施性以及可靠性的基于nvm进行ai计算的芯片架构。
7.为了达到上述目的,本发明提供一种基于nvm进行ai计算的芯片架构,包括通过总线通信连接的nvm阵列、外部接口模块、npu(嵌入式神经网络处理器)和mcu(microcontroller unit,微控制单元);
8.所述nvm阵列用于片内存储数字化的神经网络的权重参数、所述mcu运行的程序以及神经网络模型;
9.所述npu用于神经网络的数字域加速计算;
10.所述外部接口模块用于接收外部的ai运算指令、输入数据以及向外输出ai计算的结果;
11.所述mcu用于基于所述ai运算指令执行所述程序,以控制所述nvm阵列和所述npu对所述输入数据进行ai计算,以得到所述ai计算的结果。
12.本方案提供的芯片架构中npu和nvm相结合进行ai神经网络计算,其中神经网络的权重参数数字化的存储在芯片内部的nvm阵列中,神经网络计算也是数字域计算,具体通过mcu基于外部的ai运算指令控制npu及nvm阵列实现,mcu控制nvm阵列包括加载其内部存储的神经网络的权重参数、所述mcu运行的程序以及神经网络模型来进行ai计算,与现有各类采用nvm进行模拟运算的存算方案相比,数字存储与运算方式运算结构灵活,nvm存储的信息相比于模拟信号的多能级存储可靠性好、精度高、读取准确度高,故此本方案在突破采用片外nvm存储速度瓶颈以及降低外部输入功耗的同时,又具备高度的可实施性、灵活性以及可靠性。
13.进一步的,所述芯片架构还包括高速数据读取通道,所述npu通过高速数据读取通道从所述nvm阵列读取所述权重参数。
14.本方案除了包括片内总线之外,在npu和nvm阵列之间还设立高速数据读取通道,用于支持npu进行数字域运算时对于神经网络的权重参数即权重数据的高速读取的带宽要求。
15.进一步的,所述nvm阵列设有读通道,所述读通道为n路,n为正整数,在一个读周期内所述读通道共读取n比特数据,所述npu用于通过所述高速数据读取通道经所述读通道从所述nvm阵列读取所述权重参数。
16.本方案设立读通道,读通道为n路,优选的,n取128~512,一个读周期(通常30
‑
40纳秒)可以读取n比特的数据。npu通过高速数据读取通道经读通道从nvm阵列读取神经网络的权重参数,此带宽远高于片外nvm可支持的读取速度,能够支持常用神经网络推理计算所需的参数读取速度需求。
17.进一步的,所述高速数据读取通道的位宽为m比特,m为正整数;所述芯片架构还包括数据转换单元,所述数据转换单元包括缓存模块和顺序读取模块,所述缓存模块用于按周期依次缓存经所述读通道输出的权重参数,所述缓存模块的容量为n*k比特,k表示周期数;所述顺序读取模块用于将所述缓存模块中的缓存数据转换成m比特位宽后经所述高速数据读取通道输出至所述npu,其中n*k为m的整数倍。
18.本方案还包括一数据转换单元,针对读通道的数量同高速数据读取通道的位宽不一致和/或频率异步的情况,数据转换单元用于把数据转换成同高速数据读取通道相同比特宽度的数据的组合,通常为小宽度(例如32比特)的字的组合。npu以自身的时钟频率(可达1ghz以上)经高速数据读取通道从数据转换单元读取数据。
19.本方案提供的数据转换单元包含一个含n*k比特的缓存和一个一次输出m比特的顺序读取器,n*k是m的整数倍;读通道连接nvm阵列,每个周期内可以输出n比特,缓存内可以存入k个周期数据;高速数据读取通道宽度是m比特。其中,高速数据读取通道可以包含读
写指令(cmd)和回复(ack)信号,与nvm阵列读取控制电路连接。读操作完成后,ack信号通知高速数据读取通道,还可以同时通知芯片内总线,高速数据读取通道通过顺序读取模块分多次异步把缓存中的数据输入npu。
20.进一步的,所述芯片架构还包括sram(static random
‑
access memory,静态随机存取存储器),所述sram通过所述总线与所述nvm阵列、所述外部接口模块、所述npu以及所述mcu通信连接;所述sram用于缓存所述mcu执行所述程序过程中的数据,所述npu运算过程中的数据以及神经网络模型运算的输入输出数据。
21.本方案提供的芯片架构包含一块嵌入式sram,作为芯片内部系统运行与计算所需缓存使用,用于存储输入、输出数据和计算产生的中间数据等。具体可以包括mcu执行程序过程中的缓存,存储mcu运行时的可执行程序、系统配置参数、计算网络结构配置参数等;npu运算缓存,并存储经神经网络模型运算时的输入输出数据。
22.进一步的,所述nvm阵列中存储多种神经网络模型,所述ai运算指令包括算法选择指令,所述算法选择指令用于选择多个所述神经网络模型中的一个作为进行ai计算的算法。
23.本方案中的神经网络模型是数字化的存储在nvm阵列中,且根据应用场景的数量的情况可以为多个,对于多种应用场景对应多种神经网络模型的情况,mcu根据外部输入的算法选择指令能够灵活选择其中的任何一种预存的神经网络模型进行ai计算,克服了现有的存算一体的方案中采用模拟计算阵列结构僵化,不利于支持灵活的神经网络结构的问题。
24.进一步的,所述nvm阵列采用闪存工艺、mram(magnetoresistive random access memory,非挥发性的磁性随机存储器)工艺、rram(阻变式存储器)工艺、mtp(multiple time programming,可多次编程)工艺、otp(one time programming,一次性可编程)工艺中的一种,和/或,所述外部接口模块的接口标准为spi(serial peripheral interface,串行外设接口)、qpi(quad spi)以及并行接口中的至少一种。
25.进一步的,所述mcu还用于通过所述外部接口模块接收外部用于操作所述nvm阵列的数据访问指令,所述mcu还用于基于所述数据访问指令完成对所述nvm阵列的基本操作的逻辑控制。
26.进一步的,所述nvm阵列采用sonos(一种闪存工艺)闪存工艺、floating gate(一种闪存工艺)闪存工艺、split gate(一种闪存工艺)闪存工艺中的一种,所述外部接口模块的接口标准为spi和/或qpi;
27.所述数据访问指令为标准的闪存操作指令;所述ai运算指令与所述数据访问指令采用相同的指令格式和规则;所述ai运算指令包括操作码,所述ai运算指令还包括地址部分和/或数据部分,所述ai运算指令的操作码与所述标准的闪存操作指令的操作码不同。
28.本方案提供的芯片架构,在传统闪存芯片架构的基础上进行改进,具体为在闪存芯片内部嵌入mcu以及npu,并通过片内总线通信连接,片内总线可以为ahb(advanced high performance bus,高级高性能总线),也可以为其它符合要求的通信总线,在此不做限定。本方案中npu和nvm相结合,即计算与存储都在片内,其中神经网络的权重参数数字化的存储在nvm阵列中,神经网络计算也是数字域计算,具体通过mcu基于外部的ai运算指令控制npu及nvm阵列实现,由此突破了采用片外nvm存储速度瓶颈以及降低外部输入功耗的同时,
又具备高度的可实施性、灵活性以及可靠性。
29.本方案基于mcu实现了对nvm阵列数字化的操作,具体可以包括读写擦等闪存的基本操作,外部数据访问指令与外部接口可采用标准闪存芯片格式,易于芯片灵活简单地应用。本方案中内嵌的mcu作为nvm的逻辑控制单元,取代了标准闪存中的逻辑状态机,简化了芯片结构,节省了芯片面积。
30.本方案中的nvm阵列除了存储所述神经网络模型、所述权重参数以及所述芯片内部系统运行的程序之外,还可用于存储外部输入的不限于与ai计算相关的数据,即还可以用于存储外部输入的与ai计算相关的其他数据,以及外部输入的与ai计算无关的数据,无关的数据具体包括外部设备或者系统的系统参数、配置和/或代码等信息;所述基本操作除了包括对所述神经网络模型、所述权重参数以及所述内部系统运行的程序的读写擦等操作之外,还包括对存储的外部输入的数据直接在所述nvm阵列中的存储读写及擦除等操作。
31.本方案用于nvm直接操作的指令和用于ai计算处理的指令采用相同的指令格式和规则。以spi和qpi接口为例,在传统的spi、qpi闪存操作指令op_code的基础上,挑选未被闪存操作使用的op_code用于表达ai指令,在地址部分传递更多的信息,在数据交换周期里实施ai数据传递。只需要扩展指令解码器实现接口的复用,以及增加若干状态寄存器和配置寄存器即可实现ai计算。
32.进一步的,所述芯片架构还包括dma(direct memory access,直接存储器访问)通道,所述dma通道用于外部设备直接读写所述sram。
33.本发明的积极进步效果在于:
34.本发明提供的一种基于nvm进行ai计算的芯片架构,采用npu和nvm相结合进行ai神经网络计算,其中神经网络的权重参数数字化的存储在芯片内部的nvm阵列中,神经网络计算也是数字域计算,具体通过mcu基于外部的ai运算指令控制npu及nvm阵列实现,mcu控制nvm阵列加载其内部存储的神经网络的权重参数、mcu运行的程序和神经网络模型来进行ai计算,与现有各类采用nvm进行模拟运算的存算方案相比,数字存储与运算方式运算结构灵活,nvm存储的信息相比于模拟信号的多能级存储可靠性好、精度高、读取准确度高,故此本发明在突破采用片外nvm存储速度瓶颈以及降低外部输入功耗的同时,又具备高度的可实施性、灵活性以及可靠性。
附图说明
35.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
36.图1是现有技术的ai算法中的神经元图;
37.图2是现有技术的三层神经网络图;
38.图3是现有技术的卷积神经网络图;
39.图4是现有技术的采用在标准nvm阵列内添加电路进行ai计算的原理图;
40.图5是本申请的一种基于nvm进行ai计算的芯片架构的示意图;
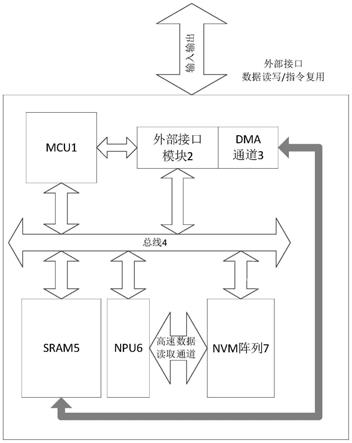
41.图6是本申请的芯片构架的数据转换单元的示意图;
42.图7是本申请的芯片构架调用nvm读写操作的指令运行流程图;
43.图8是基于本申请的芯片架构运行ai运算指令的流程图。
具体实施方式
44.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
45.在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
46.除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中所使用的术语只是为了描述本申请实施例的目的,不是旨在限制本申请。
47.本申请先就神经网络与人工智能、非易失性存储及存储内计算的基本架构与关系进行说明。
48.如前所述:人工智能(ai)算法是模仿人脑结构所产生,通过神经元之间的突触,连接到大量其他神经元的树突,形成具有简单功能的神经元网络,实现了人类所有的智能活动。人的记忆和智能,普遍被认为存储在每一个突触的不同的耦合强度里。
49.从20世纪60年代兴起的神经网络算法,用一个函数来模仿神经元的功能。函数接受多个输入,每个输入有不同的权重,输出是每一个输入与权重相乘再求和,如图1所示的范例性的ai算法中的神经元图。学习训练的过程就是调整各个权重。函数输出到很多其他的神经元,组成一个网络。这类算法,已经取得了丰富的成果,得到广泛应用。实用神经网络都有分层结构,同一层的神经元内部没有交流,每一个神经元的输入连接之前一层的多个或者所有的神经元的输出,如图2所示的三层神经网络图,其包括input layer(输入层)、hidden layer(隐藏层)以及output layer(输出层),输入层和隐藏层分别包括784个和15个neurons(神经元)。神经网络的不同层之间,有着不同的连接方式,此为一种全连接的网络。
50.更常见的是如图3所示的卷积神经网络图,此卷积神经网络在输入(input)、输出(output)都有二维结构(图像),只在临近的点有连接。
51.然而,一个实用的神经网络,往往有很多层组成,其中选择性的包括卷积层、缩减图像尺寸的层、全连接层中一者或多者形成的网络结构。
52.非易失性存储:
53.非易失性存储(nvm)是一种能够在断电后保持内容的半导体存储介质。常见的nvm包括闪存、eeprom(electrically erasable programmable read only memory,带电可擦可编程只读存储器)、mram、rram、feram(ferroelectricram,铁电随机存取存储器)、mtp、otp等。当前应用最为广泛的nvm是闪存(flash memory),其中的nor闪存结构相比nand闪存结构具有更高的可靠性和更快的读取速度,常用于系统代码、参数、算法等的存储。在具体的应用中,系统可以采用外接的独立式nvm或内嵌于系统内的嵌入式nvm。嵌入式nvm通常和
cmos(complementary metal
‑
oxide
‑
semiconductor,互补金属氧化物半导体)半导体工艺兼容,可以和逻辑计算的芯片集成在一起,在系统内有较快的读取速度。
54.与其他nvm相比,当前闪存在成本与容量上都比较有优势。目前市场上的多种闪存技术已具有存储多比特的能力。闪存擦写速度较慢(毫秒级),但读出的速度快很多(纳秒级),闪存与其他nvm的读取速度可以支撑神经网络计算所需的高带宽。
55.存储内计算(in
‑
memory
‑
computing)
56.因为ai计算需要极高的存储带宽,把处理器和内存/存储分离的架构遇到了读取速度不够的瓶颈。业界已经开始广泛研究存算一体即存储内计算的架构。例如,如图4所示的现有技术的采用在标准nvm阵列内添加电路进行ai计算的原理图,即进行神经网络计算的架构,其是利用非易失存储器来存储神经网络计算需要的权重,用模拟电路进行向量乘法,大规模的乘法和加法可以平行进行,其能够提高运算速度并且节省功耗。
57.现有技术采用nvm的存储内计算,都是利用非易失存储器存储神经网络中的权重,把神经网络的计算通过模拟方法实现,但因为实用的神经网络基本都有很多的层和非常复杂的连接结构,模拟信号在层间的传递、进行各种处理时非常不方便,不利于支持灵活的神经网络结构,造成整体神经元网络模型的实现与应用相当的困难,而且模拟信号的存储、读写与计算中各种噪音和误差明显的影响模型的可靠性和计算的准确性。
58.图5为本发明的一种基于nvm进行ai计算的芯片架构图。如图5所示,本发明的一种基于nvm进行ai计算的芯片架构包括通过总线4通信连接的nvm阵列7、外部接口模块2、sram5、npu6和mcu1。mcu1通过总线4读写sram5和内部nvm阵列7,并与npu6通信。nvm阵列7用于片内存储数字化的神经网络的权重参数、mcu1运行的程序以及神经网络模型。npu6用于神经网络的数字域加速计算。外部接口模块2用于接收外部的ai运算指令、输入数据以及向外输出ai计算的结果。mcu1用于基于外部ai运算指令执行nvm阵列7存储的程序,以控制nvm阵列7和npu6对输入数据进行ai计算,以得到ai计算的结果。
59.sram5作为芯片内部系统运行与计算所需缓存使用,用于存储输入、输出数据和计算产生的中间数据等。具体可以包括mcu1执行程序过程中的缓存,存储mcu1运行时的可执行程序、系统配置参数、计算网络结构配置参数等;npu6运算缓存,并存储经神经网络模型运算时的输入输出数据。
60.本实施例提供的芯片架构中npu6和nvm相结合进行ai神经网络计算,其中神经网络的权重参数数字化的存储在芯片内部的nvm阵列7中,神经网络计算也是数字域计算,具体通过mcu1基于外部的ai运算指令控制npu6及nvm阵列7实现,mcu1控制nvm阵列7包括加载其内部存储的神经网络的权重参数、mcu1运行的程序以及神经网络模型来进行ai计算,与现有各类采用nvm进行模拟运算的存算方案相比,数字存储与运算方式运算结构灵活,nvm存储的信息相比于模拟信号的多能级存储可靠性好、精度高、读取准确度高,故此本实施例提供的方案在突破采用片外nvm存储速度瓶颈以及降低外部输入功耗的同时,又具备高度的可实施性、灵活性以及可靠性。
61.在一个实施例中,神经网络模型通过数字化的方式存储于nvm阵列7中,nvm阵列7中存储的神经网络模型可为多种。外部ai运算指令中包括有算法选择指令,通过算法选择指令选择多个神经网络模型中的一个作为进行ai计算的算法。
62.本实施例中的神经网络模型是数字化的存储在nvm阵列7中,且根据应用场景的数
量的情况可以为多个,对于多种应用场景对应多种神经网络模型的情况,mcu1根据外部输入的算法选择指令能够灵活选择其中的任何一种预存的神经网络模型进行ai计算,克服了现有技术中采用存算一体的模拟计算阵列结构僵化,不利于支持灵活的神经网络结构的问题。
63.在一个实施例中,nvm阵列7采用但不限于闪存、mram、rram、mtp、otp中的一种。外部接口模块2的接口标准为spi、qpi以及并行接口中的至少一种。
64.在其他的实施例中,nvm阵列7采用但不限于sonos闪存、floating gate闪存、split gate闪存工艺中的一种。外部接口模块2的接口标准为spi和/或qpi。
65.本实施例提供的芯片架构,在传统闪存芯片架构的基础上进行改进,具体为在闪存芯片内部嵌入mcu1以及npu6,并通过片内总线4通信连接,片内总线4可以为ahb总线,也可以为其它符合要求的通信总线,在此不做限定。本实施例提供的方案中npu6和nvm相结合,即计算与存储都在片内,其中神经网络的权重参数数字化的存储在nvm阵列7中,神经网络计算也是数字域计算,具体通过mcu1基于外部的ai运算指令控制npu6及nvm阵列7实现,由此突破了采用片外nvm存储速度瓶颈以及降低外部输入功耗的同时,又具备高度的可实施性、灵活性以及可靠性。
66.在一个实施例中,除片内的总线4通信外,芯片架构还包括高速数据读取通道;具体为在npu6和nvm阵列7之间设立高速数据读取通道,npu6还用于通过高速数据读取通道从nvm阵列7读取权重参数。本实施例中,高速数据读取通道用于支持npu6进行数字域运算时对于神经网络的权重参数即权重数据的高速读取的带宽要求。高速数据读取通道的位宽为m比特,且m为正整数。
67.此外,nvm阵列7设有读通道,该读通道为n路,n为正整数,在一个读周期内读通道共读取n比特数据,npu6用于通过高速数据读取通道经读通道从nvm阵列7读取权重参数。优选的,n取128~512,在一个读周期内(通常30
‑
40纳秒),npu6以m比特位宽通过高速数据读取通道经读通道从nvm阵列7读取神经网络的权重参数。与现有技术片外nvm可支持的读取速度相比,本发明带宽远远高出,能够支持常用神经网络推理计算所需的参数读取速度需求。
68.在一个实施例中,本芯片架构还包括数据转换单元。数据转换单元针对读通道的数量同高速数据读取通道的位宽不一致和/或频率异步的情况,数据转换单元用于把数据转换成同高速数据读取通道相同比特宽度的数据的组合,通常为小宽度(例如32比特)的字的组合。npu6以自身的时钟频率(可达1ghz以上)经高速数据读取通道从数据转换单元读取数据。
69.图6是本申请的芯片构架的数据转换单元的示意图。如图6所示,数据转换单元包括缓存模块和顺序读取模块,缓存模块用于按周期依次缓存经读通道从nvm阵列7输出的n比特数据,缓存模块的容量为n*k比特,k表示周期数。顺序读取模块用于将缓存模块中的缓存数据转换成m比特位宽后经高速数据读取通道输出至npu6,其中n*k为m的整数倍。
70.其中,数据转换单元包含一个含n*k比特的缓存模块和一个一次输出m比特的顺序读取器,即顺序读取模块,n*k是m的整数倍;读通道连接nvm阵列7,每个周期内可以输出n比特,缓存内可以存入k个周期数据;高速数据读取通道宽度是m比特。高速数据读取通道可以包含读写指令(cmd)和回复(ack)信号,与nvm阵列7读取控制电路连接。读操作完成后,ack
信号通知高速数据读取通道,还可以同时通知芯片内总线,高速数据读取通道通过顺序读取模块分多次异步把缓存中的数据输入npu6。
71.在一个实施例中,mcu1还用于通过外部接口模块2接收外部用于操作nvm阵列7的数据访问指令,mcu1还用于基于数据访问指令完成对nvm阵列7的基本操作的逻辑控制,所述数据访问指令为标准的闪存操作指令;所述ai运算指令与所述数据访问指令采用相同的指令格式和规则;所述ai运算指令包括操作码,所述ai运算指令还包括地址部分和/或数据部分,所述ai运算指令的操作码与所述标准的闪存操作指令的操作码不同。
72.本实施例中用于nvm直接操作的指令和用于ai计算处理的指令采用相同的指令格式和规则。以spi和qpi接口为例,在传统的spi、qpi闪存操作指令op_code的基础上,挑选未被闪存操作使用的op_code用于表达ai指令,在地址部分传递更多的信息,在数据交换周期里实施ai数据传递。只需要扩展指令解码器实现接口的复用,以及增加若干状态寄存器和配置寄存器即可实现ai计算。
73.mcu1实现了对nvm阵列7数字化的操作,具体可以包括读写擦等闪存的基本操作,外部数据访问指令与外部接口可采用标准闪存芯片格式,易于芯片灵活简单地应用。本芯片内嵌的mcu1作为nvm的逻辑控制单元,取代了标准闪存中的逻辑状态机,简化了芯片结构,节省了芯片面积。
74.本实施例中的nvm阵列7除了存储神经网络模型、权重参数以及芯片内部系统运行的程序之外,还可用于存储外部输入的不限于与ai计算相关的数据,即还可以用于存储外部输入的与ai计算相关的其他数据,以及外部输入的与ai计算无关的数据,无关的数据具体包括外部设备或者系统的系统参数、配置和/或代码等信息;基本操作除了包括对神经网络模型、权重参数以及内部系统运行的程序的读写擦等操作之外,还包括对存储的外部输入的数据直接在nvm阵列7中的存储读写及擦除等操作。
75.具体实施过程中,mcu1接受外部用于nvm阵列7读写等操作的指令,完成nvm基本操作的逻辑控制。这些基本操作包括对ai运算模型算法、参数得存储读写,也可以用于系统参数、配置、代码等直接在nvm阵列7中得存储读写。mcu1还接受外部ai运算指令,控制内部运算逻辑与输入输出,同时还用于内部控制ai的算法逻辑。
76.图7是本申请的芯片构架调用nvm读写操作的指令运行流程图。如图7所示,指令运行流程如下:
77.步骤s101、外部设备启动nvm所在芯片,mcu1上电。
78.步骤s102、无需外部指令,mcu1运行所需代码与参数从nvm阵列7载入sram5,芯片处于待机状态。
79.步骤s103、外部设备发送nvm操作指令,mcu1接受并处理该指令,nvm操作指令格式及处理方式与传统标准nvm相同。
80.在一个实施例中,芯片架构还包括dma通道3,dma通道3用于外部设备直接读写sram5。外部接口模块2实现了数据和指令的复用,通过dma通道3实现了外部设备对芯片内sram5的直接读写操作,提高了数据传输效率。外部设备也可以通过dma通道3将sram5作为系统内存资源进行调用,增加了芯片应用的灵活性。
81.图8是基于本申请的芯片构架运行ai运算指令的流程图。如图8所示,ai运算指令运行流程包括:
82.步骤s201、外部设备启动nvm所在芯片,mcu1上电。
83.步骤s202、无需外部指令,mcu1运行所需代码与参数从nvm阵列7载入sram5,芯片处于待机状态。
84.步骤s203、外部设备发送算法选择指令选择存储在芯片的nvm阵列7中的某个神经网络模型。
85.步骤s204、mcu1处理该指令,内部相应存储模块上电、寻址。
86.步骤s205、外部设备发送ai运算指令与输入数据,该数据被缓存在sram5中。
87.步骤s206、mcu1启动npu6,根据ai运算指令对输入数据进行识别处理。
88.步骤s207、npu6从nvm阵列7中读取神经网络模型对应的权重参数数据用于计算。
89.步骤s208、外部设备通过外部接口模块2从芯片中读取ai计算的结果。
90.其中,步骤s205~s208可以往复循环,连续进行数据输入、计算与输出。
91.尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1