结合双向切片GRU与门控注意力机制日志异常检测方法与流程
结合双向切片gru与门控注意力机制日志异常检测方法
技术领域
1.本发明属于日志异常检测技术领域,尤其涉及一种结合双向切片gru与门控注意力机制日志异常检测方法。
背景技术:
2.目前:系统运行过程中会产生各种各样的日志,这些日志记录了系统运行时的状态和系统执行的各种操作,是在线监视和异常检测的良好信息来源。因此,将系统中存在的异常日志快速准确的检测出来,对维护系统的安全稳定意义重大。
3.系统日志异常检测一直是异常检测领域中的热门研究课题。系统日志由多种非固定格式的非结构化数据集组成,和统计学、自然语言处理、机器学习等众多学科都有着非常紧密的联系。近些年,各国研究人员应用了不同学科领域的各种方法来进行日志异常检测,并取得了大量杰出的研究成果。现有技术1 利用抽象语法树(abstract syntax tree,ast)和主成分分析(principal componentanalysis,pca)方法来处理经过解析后产生的日志特征集,通过降低特征集的复杂度,取得了较好的异常检测准确率。但是该方法依赖于静态源代码分析来从日志中提取结构,在日志异常检测中的通用性较差。现有技术2提出一种以日志聚类为核心思想的异常检测方法——logcluster。它拥有快速处理大量日志数据的能力,同时也能取得较高的异常检测精度。但是logcluster对日志进行分组时,使用会话窗口的方式,这使得logcluster只能检测带标记符的日志,限制了该方法的通用性。
4.近些年,深度学习的发展势头迅猛,在各个相关领域都取得了较为显著的成果,尤其在自然语言处理领域进展巨大。涌现出了大量以nlp为基础的优秀模型。现有技术3将系统日志中提取出的信息视为自然语言序列,围绕自然语言序列的处理,提出了一种基于lstm的深度学习神经网络模型——deeplog。该模型从正常执行中自动学习日志模型,并通过该模型,对正常执行下的日志数据进行异常监测。当检测到的日志与既定规则产生冲突时,即认定其为异常。实验结果表明,该方法在多个大型日志数据集上取得了非常高的检测精度,总体性能优于其他基于传统数据挖掘的日志异常检测方法。但该方法检测效率较低,理论上仍有一定提升空间。
5.通过上述分析,现有技术存在的问题及缺陷为:现有的日志异常检测方法检测速度慢,准确率不高。
6.解决以上问题及缺陷的难度为:不同行业领域产生的系统日志在内容以及格式方面存在较大差异,且数据量巨大,无法采用某种单一方法进行日志异常检测。对于某些没有标记符的日志,现存的一些基于标记符的日志异常检测方法无法发挥作用,且采用人工对于日志进行标记工作量巨大,难以完成。目前基于深度学习的日志异常检测模型无需对日志进行人工标记,能够自动学习异常日志特征,并基于异常日志特征进行日志异常检测,取得了良好的检测精度。但由于庞大的日志数据量,造成性能的下降以及巨大的时间开销。如何在处理海量日志数据的同时减少时间开销,是一个非常困难的问题。
7.解决以上问题及缺陷的意义为:通过结合双向切片gru与门控注意力机制,减少了
日志异常检测模型的参数数量,在模型上可以双向并行处理经过切片后的日志数据,显著减少了时间开销,同时引入门控注意力机制,使得检测精度得到了进一步的提高。在对于大型信息系统的日志分析中取得了理想的效果,在检测精度以及总体性能开销方面,优于现存大部分日志异常检测方法。在大型信息系统的风险分析以及故障预测领域具有积极影响。
技术实现要素:
8.针对现有技术存在的问题,本发明提供了一种结合双向切片gru与门控注意力机制日志异常检测方法。
9.本发明是这样实现的,一种结合双向切片gru与门控注意力机制日志异常检测方法,所述结合双向切片gru与门控注意力机制日志异常检测方法包括:使用spell在线解析日志,通过提取日志的log key,将日志解析为结构化序列,引入双向切片与门控注意力机制构建日志异常检测模型,并将解析到得到的特征序列作为日志异常检测模型的输入进行日志异常检测模型训练,利用训练好的日志异常检测模型进行日志异常检测。
10.进一步,所述日志异常检测模型包括:
11.输入层、双向gru层、ga
‑
attention层、第二gru层、拼接层和softmax 层;
12.输入层,用于用word2vec方法生成log key单词向量x
m
;并利用x
ij
表示 logkeyx
i
的第j个单词的词向量j∈[1,maxkey];
[0013]
双向gru层,用于对经过word2vec方法生成的输入序列在两个方向分别进行处理;
[0014]
ga
‑
attention层,用于为每个logkey中经过筛选的单词分配权重;
[0015]
第二gru层,用于对于ga
‑
attention层的输出序列在两个方向进行处理;
[0016]
拼接层,用于将计算得到顶层输出与进行拼接;
[0017]
softmax层,用于基于拼接结果计算得到一个n维向量,每一维度的值代表 logkey表中的每个元素出现在当前位置的概率,并得到每个logkey出现的概率。
[0018]
进一步,所述日志异常检测模型损失函数为:
[0019]
loss=
‑
∑logp
dj
;
[0020]
其中,d表示每条logkey,j表示标签。
[0021]
进一步,所述结合双向切片gru与门控注意力机制日志异常检测方法包括以下步骤:
[0022]
步骤一,利用spell从日志数据中解析出logkey,并利用word2vec工具训练log key向量;此步骤的作用是将logkey转化为转为计算机可以理解的稠密向量。
[0023]
步骤二,将logkey转换成固定长度的索引,每个索引对应一个logkey序列向量;将logkey序列向量拼接成logkey序列矩阵,作为模型的嵌入层权重;此步骤的作用是产生模型的嵌入层权重。
[0024]
步骤三,将日志解析出的logkey分别进行切片处理作为b i
‑
ssgru
‑
ga
‑
attention模型的输入;此步骤的作用是将解析出的logkey进行切片,便于在模型中双向同步处理,减少模型的时间开销。
[0025]
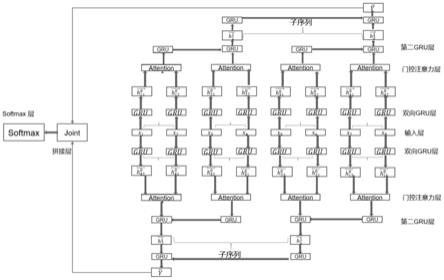
步骤四,将log key最小子序列索引表示输入嵌入层,再输入bi
‑
ssgru层,提取log key子序列层次特征;此步骤的作用是利用bi
‑
ssgru层,提取log key 子序列层次特征,用
于后续的异常分析。
[0026]
步骤五,将每个子序列经过bi
‑
ssgru提取到的特征输入到ga
‑
attention 层,分配相应的logkey序列向量权重;此步骤的作用是选择性的赋予logkey序列向量一定的权重,使正常日志或异常日志的序列特征更加明显,提高日志异常检测的准确率。
[0027]
步骤六,经过多个网络层获取整个log key序列的特征表示,作为下一可能 logkey概率表示;此步骤的作用是得到一个logkey概率表示。
[0028]
步骤七,将logkey表按照输出的概率值从大到小排列,选取其中前b个组成集合;若系统当前时刻输出日志的logkey存在于集合中,则判断所述日志是正常的,否则即视为异常。此步骤的作用是判断概率值是否在预先设定的可信概率集合中,从而判断日志为正常或异常。
[0029]
进一步,步骤一中,所述利用spell从日志数据中解析出logkey包括:
[0030]
(1)初始化lcsobject、lcsseq、lineids以及存放所有日志对象的列表 lcsmap;
[0031]
(2)流式读取日志,当读取到一个新的日志条目之后,遍历lcsmap,寻找该日志与所有lcsobject的最大公共子序列,如果子序列的长度大于日志序列长度的一半,则认为该日志该与日志键匹配;如果找到匹配的日志对象,跳转步骤(4);如果没有,或者lcsmap为空,则跳转步骤(3);
[0032]
(3)将该行日志初始化为一个新的lcsobject,放入列表lcsmap中;
[0033]
(4)将该行日志更新到匹配的lcsobject的行数列表lineids中,并且更新 lcsseq;
[0034]
(5)跳转至步骤(2),直到日志读取完毕。
[0035]
进一步,所述利用word2vec工具训练log key向量包括:
[0036]
采用word2vec方法生成logkey单词向量x
m
,并利用x
ij
表示x
i
的第j个单词的词向量j∈[1,maxkey],令每个logkey的长度由maxkey个单词向量构成,则每一个logkeyx
i
可以表示为:
[0037][0038]
其中,x
i
表示logkey,i∈[1,s],s表示总的logkey数量。
[0039]
进一步,所述将日志解析出的logkey分别进行切片处理包括:
[0040][0041][0042]
i,j分别表示处理方向上的第i个最小子序列的第j个输入。
[0043]
进一步,所述提取logkey子序列层次特征包括:
[0044]
首先,对于每个最小序列,根据上一层输出h
ij
,输入单层感知机mlp以获得h
ij
的隐含表示μ
ij
;
[0045]
然后,使用μ
ij
和μ
w
的相似度衡量单词的重要性,并通过softmax函数得到一个归一化的重要性权重矩阵α
ij
;
[0046]
最后,计算词向量的加权和得到每个最小子序列新的表示s
i
,进行logkey 级别的局部关键特征关注。
[0047]
进一步,所述logkey概率表示包括:
[0048][0049]
其中,c表示输入的历史序列,x
t
表示目标logkey,v
′
(x)表示softmax层中的输出词向量。
[0050]
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明的日志异常检测算法,具有参数简单,收敛速度快的优点,在减少了运行时间的同时,取得了较高的准确率,解决了现存日志异常检测方法中存在的参数复杂、时间开销大以及精准度不高的问题。在对于大型信息系统的日志分析中取得了较为理想的效果。
[0051]
本发明在基于gru神经网络的日志异常检测算法的基础上,结合循环神经网络(rnn)提出了一种基于双向切片门控循环单元和门控注意力机制 (bi
‑
ssgru
‑
ga
‑
attention)的日志异常检测算法。针对海量不定格式的非结构化日志,通过提取日志的log key,将日志解析为结构化序列,将解析到得到的特征序列作为模型的输入,用来训练bi
‑
ssgru
‑
ga
‑
attention神经网络模型用以检测日志异常,具有参数简单,收敛速度快的优点,在提升了运行速度的同时取得了较高检测精度。
[0052]
本发明基于双向切片gru与门控注意力机制相结合的日志异常检测方法,使用spell在线解析日志,使用基于logkey的日志解析方法,引入双向切片与门控注意力机制,实现了gru在训练过程中并行性的可能,节约了模型的训练时间,同时提升了检测精度。实验结果表明,本发明算法在hdfs等大型日志数据集上取得了良好的表现,准确率、召回率以及时间成本均好于当前主流的一些日志异常检测方法。本发明能为今后相关工作提供算法参考和模型构建基准,具有一定理论指导意义。
附图说明
[0053]
图1是本发明实施例提供的结合双切片gru与门控注意力机制的日志异常检测模型示意图。
[0054]
图2是本发明实施例提供的结合双向切片gru与门控注意力机制日志异常检测方法流程图。
[0055]
图3是本发明实施例提供的标准rnn结构示意图。
[0056]
图4是本发明实施例提供的标准gru结构示意图。
[0057]
图5是本发明实施例提供的sgru具体结构示意图。
[0058]
图6是本发明实施例提供的辅助网络示意图。
[0059]
图7是本发明实施例提供的骨干网络示意图。
[0060]
图8是本发明实施例提供的四中方法在准确率、精确率、召回率、f值四个指标上的效果对比图。
具体实施方式
[0061]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于
限定本发明。
[0062]
针对现有技术存在的问题,本发明提供了一种结合双向切片gru与门控注意力机制日志异常检测方法,下面结合附图对本发明作详细的描述。
[0063]
本发明实施例提供的结合双向切片gru与门控注意力机制日志异常检测方法包括:
[0064]
使用spell在线解析日志,通过提取日志的log key,将日志解析为结构化序列,引入双向切片与门控注意力机制构建日志异常检测模型,并将解析到得到的特征序列作为日志异常检测模型的输入进行日志异常检测模型训练,利用训练好的日志异常检测模型进行日志异常检测。
[0065]
如图1所示,本发明实施例提供的日志异常检测模型包括:
[0066]
输入层、双向gru层、ga
‑
attention层、第二gru层、拼接层和softmax 层;
[0067]
输入层,用于用word2vec方法生成log key单词向量x
m
;并利用x
ij
表示 logkeyx
i
的第j个单词的词向量j∈[1,maxkey];
[0068]
双向gru层,用于对经过word2vec方法生成的输入序列在两个方向分别进行处理;
[0069]
ga
‑
attention层,用于为每个logkey中经过筛选的单词分配权重;
[0070]
第二gru层,用于对于ga
‑
attention层的输出序列在两个方向进行处理;
[0071]
拼接层,用于将计算得到顶层输出与进行拼接;
[0072]
softmax层,用于基于拼接结果计算得到一个n维向量,每一维度的值代表 logkey表中的每个元素出现在当前位置的概率,并得到每个logkey出现的概率。
[0073]
本发明实施例提供的日志异常检测模型损失函数为:
[0074]
loss=
‑
∑logp
dj
;
[0075]
其中,d表示每条logkey,j表示标签。
[0076]
实施例
[0077]
如图1至图8所示为本发明的结合双向切片gru与门控注意力机制日志异常检测方法的实施例,包括以下步骤:
[0078]
s101,利用spell从日志数据中解析出logkey,并利用word2vec工具训练 log key向量;
[0079]
s102,将logkey转换成固定长度的索引,每个索引对应一个logkey序列向量;将logkey序列向量拼接成logkey序列矩阵,作为模型的嵌入层权重;
[0080]
s103,将日志解析出的logkey分别进行切片处理作为b i
‑
ssgru
‑
ga
‑
attention模型的输入;
[0081]
s104,将log key最小子序列索引表示输入嵌入层,再输入bi
‑
ssgru层,提取log key子序列层次特征;
[0082]
s105,将每个子序列经过bi
‑
ssgru提取到的特征输入到ga
‑
attention层,分配相应的logkey序列向量权重;
[0083]
s106,经过多个网络层获取整个log key序列的特征表示,作为下一可能 logkey概率表示;
[0084]
s107,将logkey表按照输出的概率值从大到小排列,选取其中前b个组成集合;若系统当前时刻输出日志的logkey存在于集合中,则判断所述日志是正常的,否则即视为异
常。
[0085]
下面结合具体实施例对本发明的技术方案作进一步说明。
[0086]
本实施例仅需使用spell方法对日志进行解析提取出logkey,并经过 word2vec工具训练log key向量,将训练后的log key向量作切片处理后,即可作为bi
‑
ssgru
‑
ga
‑
attention模型的输入,输出的结果即为对日志正常或异常的判断。bi
‑
ssgru
‑
ga
‑
attention模型引入双向切片与门控注意力机制,实现了 gru在训练过程中并行性的可能,节约了模型的训练时间,同时提升了检测精度。
[0087]
步骤s101中,利用spell从日志数据中解析出logkey,具体步骤包括:
[0088]
(1)初始化lcsobject、lcsseq、lineids以及存放所有日志对象的列表 lcsmap;
[0089]
(2)流式读取日志,当读取到一个新的日志条目之后,遍历lcsmap,寻找该日志与所有lcsobject的最大公共子序列,如果子序列的长度大于日志序列长度的一半,则认为该日志该与日志键匹配;如果找到匹配的日志对象,跳转步骤(4);如果没有,或者lcsmap为空,则跳转步骤(3);
[0090]
(3)将该行日志初始化为一个新的lcsobject,放入列表lcsmap中;
[0091]
(4)将该行日志更新到匹配的lcsobject的行数列表lineids中,并且更新 lcsseq;
[0092]
(5)跳转至步骤(2),直到日志读取完毕。
[0093]
本发明将所有的logkey定义为x
i
,i∈[1,s],s为总的logkey数量。采用 word2vec方法生成log key单词向量x
m
,x
m
纬度本发明设定为100,m∈[1,z],z 为x
i
中所有不重复的logkey的个数,在本发明中,本发明采用word2vec中的 cbow模型实现上述操作。然后,本发明使用x
ij
来表示x
i
的第j个单词的词向量 j∈[1,maxkey],本发明令每个logkey的长度由maxkey个单词向量构成,则每一个logkeyx
i
可以表示为:
[0094]
步骤s102中,将logkey转换成固定长度的索引,每个索引对应一个logkey 序列向量;将logkey序列向量拼接成logkey序列矩阵,作为模型的嵌入层权重;
[0095]
步骤s103中,如图1和图3所示,将日志解析出的logkey分别进行切片处理作为bi
‑
ssgru
‑
ga
‑
attention模型的输入;
[0096]
步骤s104中,对经过word2vec方法生成的输入序列,本发明在两个方向分别进行处理: i,j分别表示处理方向上的第i个最小子序列的第j个输入。
[0097]
步骤s105中,为每个logkey中经过筛选的单词分配权重,首先,对于每个最小序列,根据上一层输出h
ij
,输入单层感知机mlp以此获得h
ij
的隐含表示μ
ij
,然后使用μ
ij
和μ
w
的相似度来衡量单词的重要性,此处的μ
w
是一个经过初始化用以表示上下文的向量。在衡量完单词的重要性之后,通过softmax函数得到一个归一化的重要性权重矩阵α
ij
,最后,求词向量的加权和来得到每个最小子序列新的表示s
i
,以此实现logkey级别的局部关键特征关注。
[0098]
步骤s106中,如图1所示,在这一层中,本发明对于ga
‑
attention层的输出序列同样在两个方向进行处理:
其中表示第一层第t个logkey子序列的隐含表示;p0表示最小子序列个数,p1表示第一层的log key子序列个数;l0表示最小子序列长度。在第层和第层(n>1):与第二gru层同理,本发明可以推理出第n层输出的隐含表示如下::与第二gru层同理,本发明可以推理出第n层输出的隐含表示如下::与第二gru层同理,本发明可以推理出第n层输出的隐含表示如下:表示第n层gru第t个子序列的隐含表示;p
n
表示n 层子序列的个数,见,l
n
表示第n层子序列长度。
[0099]
步骤s107中,由第层和第层本发明可以计算出顶层将与进行拼接操作,将拼接后的结果作为softmax层的输入,通过softmax层计算得到一个n维向量,每一维度的值代表logkey表中的每个元素出现在当前位置的概率,所有概率之和为1。计算过程的数学形式如下:由此可得出每个logkey出现的概率:其中c表示输入的历史序列,x
t
代表目标logkey,v
′
(x)为softmax层中的输出词向量。本发明采用的损失函数为:loss=
‑
∑logp
dj
。其中,d表示每条logkey,j表示标签。将logkey表按照输出的概率值从大到小排列,选取其中前b个组成集合。若系统当前时刻输出日志的logkey存在于集合中,则认为该日志是正常的,否则即视为异常。
[0100]
实验评估
[0101]
实验数据集
[0102]
本实验选取了两个具有典型代表性的公开日志数据集。hdfs数据和bgl 数据,这两个数据集都是从生产系统收集的,共有15923592条日志消息和365298 个异常样本,hdfs数据包含11175629条日志消息,这些消息是从亚马逊ec2 平台收集的。hdfs日志记录每个数据块操作(如分配、写入、复制、删除)的唯一数据块id。因此,日志中的操作可以更自然地被会话窗口捕获,如iii
‑
b中所介绍的,因为每个唯一的块id可以用来将日志分割成一组日志序列。然后,本发明从这些日志序列中提取特征向量,并生成575061个事件计数向量。其中, 16838个样本被标记为异常。bgl数据包含4747963条日志信息,由lawrencelivermore国家实验室(llnl)的bluegene/l超级计算机系统记录。与hdfs 数据不同,bgl日志没有记录每个作业执行的标识符。因此,本发明必须使用固定窗口或滑动窗口将日志切片为日志序列,然后提取相应的事件计数向量。但是窗口的数量取决于选择的窗口大小(和步长)。在bgl数据中,348460条日志消息被标记为故障,如果该序列中存在任何故障日志,则日志序列被标记为异常。因此,本发明将这些标签(异常与否)作为准确性评估的基础事实依据。在数据集上进行多角度的对比实验用以评估算法的性能。
[0103]
实验环境
[0104]
实验环境具体配置如下:处理器为intel corei7
‑
10750h(5.0ghz),显卡为nvidia geforce gtx1650ti(4gb),32gb ram(2133mhz),操作系统为ubuntu 16.04(64位),编程环境为python3.6.5。深度学习框架采用tensorflow。
[0105]
模型参数
[0106]
词嵌入维度代表了词语的特征,特征越多越能够更加准确的将词与词区分开来,但是在实际应用中维度太多会导致模型训练的开销增大,且维度越多词与词之间的关系也就越被淡化,这与本发明训练词向量的目的是相反的。因此本实验中,本发明设置词嵌入维度为200,batch_size设置为1024,不同方向的隐藏层节点数设置为100,采用的优化器为adam,迭代次数为10次。模型参数如表1所示:
[0107]
表1模型参数
[0108][0109]
实验过程
[0110]
本实验具体实施步骤如下:
[0111]
b)使用word2vec工具训练log key向量;
[0112]
c)将logkey转换成固定长度的索引,每个索引对应一个logkey序列向量;
[0113]
e)将logkey序列向量拼接成logkey序列矩阵,作为模型的嵌入层权重;
[0114]
f)将日志解析出的logkey分别进行切片处理作为bi
‑
ssgru
‑
ga
‑
attention 模型的输入;
[0115]
g)log key最小子序列索引表示输入嵌入层,再输入bi
‑
ssgru层,提取 log key子序列层次特征;
[0116]
h)将每个子序列经过bi
‑
ssgru提取到的特征输入到ga
‑
attention层,分配相应的logkey序列向量权重;
[0117]
i)经过多个网络层获取整个log key序列的特征表示;作为下一可能logkey 概率表示。
[0118]
为了验证双向切片gru与门控注意力机制结合的日志异常检测模型的速度提升,本次实验选取包含11175629条数据的亚马逊大型hdfs日志作为此次对比实验数据集,对比实验共分为3组,在maxkey为6时1种切片方式:sgru (3,2);在maxkey为9时1种切片方式:sgru(3,3);在maxkey为 12时1种切片方式:sgru(4,3)。对比切片与不切片方式下的运行速度。表2 给出了不同输入长度下两种切片方式的运行速度对比,从表中可以看出,不同序列
长度下的切片gru模型相较于原模型的速度均有显著提升。对比不同序列长度下的性能提升幅度,可以看到序列长度越长,双向切片gru与门控注意力机制结合模型相较于原模型速度提升越大。
[0119]
表2切片模型与原模型在不同序列长度下运行速度对比
[0120][0121]
对比实验
[0122]
在对比实验中,本发明选取了三种目前被广泛采用的异常检测算法:主成分分析(principal component analysis,pca)、deeplog和基于gru的深度学习异常检测算法(引用)与本发明算法进行对比。其中pca是离线检测算法,使用会话窗口(session windows)对日志进行分块(本发明使用滑动窗口),从而提取出logkey,对logkey序列执行异常检测。现有技术实现了此种方法,相关开源代码可在github上找到。deeplog使用lstm神经网络构建模型,能够实现对日志异常的在线检测。基于gru的深度学习异常检测算法在deeplog 算法的基础上做了改进,采用gru单元代替lstm单元,具有参数少,训练快的优点,能够完成对日志异常的在线检测。实验首先对比pca、deeplog、gru 三种方法的检测精度,然后对比gru与bi
‑
ssgru
‑
ga
‑
attention这两种在线检测方法的检测速度,从多方面综合评价本发明算法。
[0123]
本发明对比实验采用的日志数据集为203个亚马逊ec2节点运行38.7小时产生的hdfs日志数据集。该数据集中存在11175629条日志数据,包括575062 个事件跟踪(eventtrace),对应着575062个具有不同block_id的hdfs文件块。所有的block_id均由hadoop领域专家标记为正常或异常,其中异常数据数量约占总数据量的2.9%。现有技术构造了此数据集,并且在日志异常检测领域被广泛使用,该数据集开源并可在loghub获取。表3给出了训练集和测试集的具体信息。
[0124]
表3训练集与测试集数据信息
[0125][0126]
实验采用的评估指标有准确率(accuracy)、假阳性(false positives,fp)、假阴性(false negatives)、精确率(precision)、召回率(recall)、f值(f
‑
measure) 六个指标。将正确检测出一个异常定义为一个正类,则fn和fp分别代表正常日志和异常日志的误报数
量。准确率计算公式为:
[0127][0128]
表示被正确分类的正常日志和异常日志占总日志的百分比。精确率的计算公式为:
[0129][0130]
表示真异常在所有检测到的异常中所占的比例。召回率计算公式为:
[0131][0132]
表示检测到的异常占数据集中总异常的百分比。f值的计算公式为:
[0133][0134]
f值为精确率和召回率的加权调和平均,是一种基于精确率和召回率的综合评价指标。表4给出了四种算法在假阳性(false positives,fp)、假阴性(falsenegatives)、两个指标上的性能表现,可以看出,pca算法在假阳性指标上表现优异,说明pca算法在异常误报率方面控制的很好,但却得到了较多的假阴性,说明pca算法倾向于将异常日志判别为正常,相比之下,deeplog与gru 算法均取得了较少的假阳性与假阴性,本发明算法在假阳性与假阴性方面表现略优于deeplog算法与gru算法。在性能方面取得了一定程度的提升。
[0135]
表4 pca、deeplog,gru、本文算法性能对比
[0136][0137]
图8在准确率(accuracy)、精确率(precision)、召回率(recall)、f值 (f
‑
measure)四个指标上对比了以上四种算法。从图中本发明可以看出,在精确率与f值方面,本发明算法略低于deeplog,但在准确率与召回率两个指标中取得了最高成绩,整体性能与deeplog相当,略优于gru算法,明显好于pca 算法。
[0138]
为了验证本发明算法在运行速度上的提升,本发明将本发明算法与gru算法单独进行对比试验。运行速度通过总运行时间以及平均每条日志所需的检测时间这两个指标来衡量。表5展示了gru算法与本发明算法在hdfs日志测试数据集上的运行速度:
[0139]
表5 gru算法与本文算法运行速度对比
[0140][0141]
结合上表可以看到,在取得近似检测精度的前提下,本发明算法在运行速度上取得了较大的领先,相比gru算法,运行总时间节约了8.9%,平均运行时间节约了8.2%。在实时性方面体现出了本发明算法的优越性。
[0142]
综合来看,本发明算法优于pca算法,同时在时间开销上优于deeplog 算法与gru算法,检测速度更快。在面对日志数量巨大且实时性要求较高的情境下,本发明算法有着较高的应用价值和实际意义。
[0143]
结语
[0144]
当前日志异常检测领域中涉及到神经网络与注意力机制的研究相对较少。本发明算法针对日志异常检测领域的不足之处,提出了一种基于双向切片gru 与门控注意力机制相结合的日志异常检测算法,使用spell在线解析日志,使用基于logkey的日志解析方法,引入双向切片与门控注意力机制,实现了gru在训练过程中并行性的可能,节约了模型的训练时间,同时提升了检测精度。实验结果表明,本发明算法在hdfs等大型日志数据集上取得了良好的表现,准确率、召回率以及时间成本均好于当前主流的一些日志异常检测方法。本发明研究目的是为今后相关工作提供算法参考和模型构建基准,具有一定理论指导意义。
[0145]
证明部分(具体实施例/实验/仿真/药理学分析/能够证明本发明创造性的正面实验数据等)
[0146]
在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上;术语“上”、“下”、“左”、“右”、“内”、“外”、“前端”、“后端”、“头部”、“尾部”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”等仅用于描述目的,而不能理解为指示或暗示相对重要性。
[0147]
应当注意,本发明的实施方式可以通过硬件、软件或者软件和硬件的结合来实现。硬件部分可以利用专用逻辑来实现;软件部分可以存储在存储器中,由适当的指令执行系统,例如微处理器或者专用设计硬件来执行。本领域的普通技术人员可以理解上述的设备和方法可以使用计算机可执行指令和/或包含在处理器控制代码中来实现,例如在诸如磁盘、cd或dvd
‑
rom的载体介质、诸如只读存储器(固件)的可编程的存储器或者诸如光学或电子信号载体的数据载体上提供了这样的代码。本发明的设备及其模块可以由诸如超大规模集成电路或门阵列、诸如逻辑芯片、晶体管等的半导体、或者诸如现场可编程门阵列、可编程逻辑设备等的可编程硬件设备的硬件电路实现,也可以用由各种类型的处理器执行的软件实现,也可以由上述硬件电路和软件的结合例如固件来实现。
[0148]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所
作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1