一种关键词的选取方法及系统与流程
1.本发明涉及数据处理技术领域,尤其涉及一种关键词的选取方法及系统。
背景技术:
2.目前,对于文本中的关键词的选取方法通常是筛选出该文本中所包含的高频词汇,将高频词汇作为关键词以供读者检索使用,然而,仅凭高频词汇这一因素作为关键词的选取条件,往往不能全面地反映出该文本的核心思想,即高频词汇不相当于核心关键词,因此,不利于读者的阅读效果。
技术实现要素:
3.本发明所要解决的技术问题是:提供一种全新的关键词的选取方法及系统,能够更加全面地反映出该文本的核心思想,有助于提升阅读效果。
4.为了解决上述技术问题,本发明采用的一技术方案为:
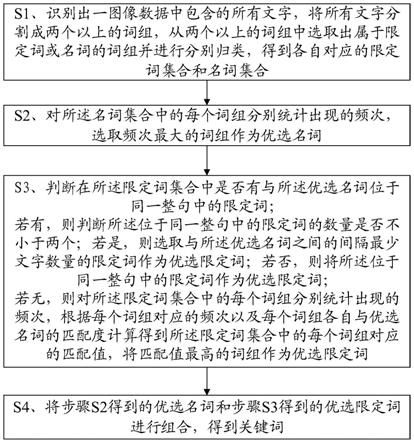
5.一种关键词的选取方法,包括以下步骤:
6.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
7.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
8.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
9.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
10.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
11.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
12.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
13.本发明采用的另一技术方案为:
14.一种关键词的选取系统,包括一个或多个处理器及存储器,所述存储器存储有程序,该程序被处理器执行时实现以下步骤:
15.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
16.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
17.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
18.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
19.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
20.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
21.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
22.本发明的有益效果在于:
23.本发明提供的一种关键词的选取方法,通过将从一图像数据中识别出的包含的所有文字分割成两个以上的词组,再选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;接着分别从限定词集合和名词集合选取出优选名词和优选限定词组成本方案最终的关键词。其中,按照先确定优选名词再确定优选限定词顺序执行选取方法,在选取优选限定词时,先判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词。通过该方式得到的优选限定词能够与优选名词存在较高的关联性,最后通过由该优选名词和优选限定词组成的关键词能够更加全面地反映出该文本的核心思想,有助于提升阅读效果。本发明还提供的一种关键词的选取系统,同样能够达到上述所宣称的技术效果。
附图说明
24.图1为本发明的一种关键词的选取方法的步骤流程图;
25.图2为本发明的一种关键词的选取系统的结构示意图;
26.标号说明:
27.1、一种关键词的选取系统;2、处理器;3、存储器。
具体实施方式
28.为详细说明本发明的技术内容、所实现目的及效果,以下结合实施方式并配合附图予以说明。
29.请参照图1,本发明提供的一种关键词的选取方法,包括以下步骤:
30.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
31.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
32.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
33.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
34.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
35.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
36.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
37.从上述描述可知,本发明的有益效果在于:
38.本发明提供的一种关键词的选取方法,通过将从一图像数据中识别出的包含的所有文字分割成两个以上的词组,再选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;接着分别从限定词集合和名词集合选取出优选名词和优选限定词组成本方案最终的关键词。其中,按照先确定优选名词再确定优选限定词顺序执行选取方法,在选取优选限定词时,先判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词。通过该方式得到的优选限定词能够与优选名词存在较高的关联性,最后通过由该优选名词和优选限定词组成的关键词能够更加全面地反映出该文本的核心思想,有助于提升阅读效果。
39.进一步的,步骤s3中根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
40.根据每个词组对应的频次,查询得到对应的权重值;
41.计算得到每个词组各自与优选名词的匹配度;
42.将每个词组对应的频次乘以对应的权重值后再加上计算得到的每个词组各自与优选名词的匹配度,计算得到所述限定词集合中的每个词组对应的匹配值。
43.由上述描述可知,通过上述方式,能够计算得到所述限定词集合中的每个词组对应的匹配值。
44.进一步的,步骤s3中根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
45.识别出所述图像数据中位于标题位上的文字,所述图像数据为通过拍摄处于阅读状态下的纸质读物而获取;
46.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值。
47.由上述描述可知,在关键词的匹配上进一步考虑文本标题的重要性,因而在上述方式中,结合位于标题位上的文字,综合计算得到所述限定词集合中的每个词组对应的匹配值,有助于更加全面且精准反映出该文本的核心思想。
48.进一步的,还包括:
49.获取阅读者在预设时段内的阅读数据;所述阅读数据包括历史关键词、阅读时段和阅读力数据;
50.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
51.根据每个词组对应的频次、每个词组各自与优选名词的匹配度、位于标题位上的文字以及所述阅读数据计算得到所述限定词集合中的每个词组对应的匹配值。
52.由上述描述可知,再进一步结合阅读者在预设时段内的阅读数据,更加综合地计算得到所述限定词集合中的每个词组对应的匹配值。
53.参阅图2,本发明还提供一种关键词的选取系统1,包括一个或多个处理器2及存储器3,所述存储器3存储有程序,该程序被处理器2执行时实现以下步骤:
54.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
55.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
56.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
57.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
58.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
59.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
60.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
61.从上述描述可知,本发明的有益效果在于:
62.本发明提供的一种关键词的选取系统,通过将从一图像数据中识别出的包含的所有文字分割成两个以上的词组,再选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;接着分别从限定词集合和名词集合选取出优选名词和优选限定词组成本方案最终的关键词。其中,按照先确定优选名词再确定优选限定词顺序执行选取方法,在选取优选限定词时,先判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词。通过该方式得到的优选限定词能够与优选名词存在较高的关联性,最后通过由该优选名词和优选限定词组成的关键词能够更加全面地反映出该文本的核心思想,有助于提升阅读效果。
63.进一步的,该程序被处理器执行时具体实现以下步骤:
64.根据每个词组对应的频次,查询得到对应的权重值;
65.计算得到每个词组各自与优选名词的匹配度;
66.将每个词组对应的频次乘以对应的权重值后再加上计算得到的每个词组各自与优选名词的匹配度,计算得到所述限定词集合中的每个词组对应的匹配值。
67.由上述描述可知,通过上述方式,能够计算得到所述限定词集合中的每个词组对应的匹配值。
68.进一步的,该程序被处理器执行时具体实现以下步骤:
69.识别出所述图像数据中位于标题位上的文字,所述图像数据为通过拍摄处于阅读状态下的纸质读物而获取;
70.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值。
71.由上述描述可知,在关键词的匹配上进一步考虑文本标题的重要性,因而在上述方式中,结合位于标题位上的文字,综合计算得到所述限定词集合中的每个词组对应的匹配值,有助于更加全面且精准反映出该文本的核心思想。
72.进一步的,该程序被处理器执行时还实现以下步骤:
73.获取阅读者在预设时段内的阅读数据;所述阅读数据包括历史关键词、阅读时段和阅读力数据;
74.根据每个词组对应的频次、每个词组各自与优选名词的匹配度、位于标题位上的文字以及所述阅读数据计算得到所述限定词集合中的每个词组对应的匹配值。
75.由上述描述可知,再进一步结合阅读者在预设时段内的阅读数据,更加综合地计算得到所述限定词集合中的每个词组对应的匹配值。
76.请参照图1,本发明的实施例一为:
77.本发明提供的一种关键词的选取方法,包括以下步骤:
78.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
79.在步骤s1之前还包括:判断阅读者是否处于阅读状态,即本方案配置一智能阅读桌,智能阅读桌上搭载有智能系统以及架设在预设识别区域上方的摄像装置,摄像装置竖直向下设置且朝向预设识别区域,阅读者将纸质读物置于预设识别区域内并通过智能系统登入个人账号系统,智能阅读桌通过阅读者是否登入个人账号系统以及是否将纸质读物置于预设识别区域内以此来判断是否处于阅读状态,当进入阅读状态时,摄像装置拍摄纸质读物即得到上述的图像数据,通过ocr识别即可通过该图像数据识别出所包含的所有文字,并且还能够识别出文字在该文本中的位置,以此来为后续判定标题文字作基础。
80.其中,需要说明的是:限定词为形容词等起到限定、修饰作用的文字。名词为被限定、被修饰的文字。
81.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
82.在本实施例中,可按照频次由大至小的顺序对所有的名词集合中的每个词组进行排序,将按照第二位的词组作为备选名词,若后续过程中,选取的优选名词不存在有与之匹配的限定词,则选择备选名词作为优选名词,此时将位于优选名词之后一位的词组作为当
前备选名词,以此类推。
83.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
84.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
85.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
86.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
87.其中,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
88.根据每个词组对应的频次,查询得到对应的权重值;其中,预设一映射表,映射表内存储有多个频次范围以及每个频次范围各自对应的权重值,频次范围以及各自对应的权重值可根据不同大小、不同种类的书籍进行相应设置。
89.计算得到每个词组各自与优选名词的匹配度;这里采用的匹配度计算是采用现有技术,主要是通过现有的大数据分析而来,并且具有不断的自学习功能。
90.将每个词组对应的频次乘以对应的权重值后再加上计算得到的每个词组各自与优选名词的匹配度,计算得到所述限定词集合中的每个词组对应的匹配值。
91.为进一步提升匹配精度,步骤s3中根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
92.识别出所述图像数据中位于标题位上的文字,所述图像数据为通过拍摄处于阅读状态下的纸质读物而获取;
93.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值。
94.上述匹配值的计算方法为将每个参数均乘以对应的权重值后相加,即可得到匹配值。
95.另外,还包括:
96.获取阅读者在预设时段内的阅读数据;所述阅读数据包括历史关键词、阅读时段和阅读力数据;预设时段可任意设置,一般可根据阅读的阅读频次来决定,一般是5
‑
10天。其中历史关键词为阅读者之前搜索过的关键词,阅读时段是指在一天中的哪个具体时间段,阅读力数据是指专注力和理解力,专注力可通过阅读一页内容所花的时长来判定,理解力可通过检索关键词的数量来判定。
97.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值,具体为:
98.根据每个词组对应的频次、每个词组各自与优选名词的匹配度、位于标题位上的文字以及所述阅读数据计算得到所述限定词集合中的每个词组对应的匹配值。
99.上述匹配值的计算方法为将每个参数均乘以对应的权重值后相加,即可得到匹配值。
100.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
101.通过上述关键词,可结合场景灯呈现出对应的阅读氛围,形成新型阅读图书馆。例
如,场景灯设有多种灯光效果,通过关键词分析出对应的类型,根据类型选择对应的灯光效果,如激情的篝火晚会,此时,灯光效果可以为火红色的灯光加上一定频率的闪烁,以达到营造阅读氛围的效果。
102.请参照图2,本发明的实施例二为:
103.本发明还提供一种关键词的选取系统1,包括一个或多个处理器2及存储器3,所述存储器3存储有程序,该程序被处理器2执行时实现以下步骤:
104.s1、识别出一图像数据中包含的所有文字,将所有文字分割成两个以上的词组,从两个以上的词组中选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;
105.s2、对所述名词集合中的每个词组分别统计出现的频次,选取频次最大的词组作为优选名词;
106.s3、判断在所述限定词集合中是否有与所述优选名词位于同一整句中的限定词;
107.若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;
108.若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;
109.若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词;
110.s4、将步骤s2得到的优选名词和步骤s3得到的优选限定词进行组合,得到关键词。
111.进一步的,该程序被处理器执行时具体实现以下步骤:
112.根据每个词组对应的频次,查询得到对应的权重值;
113.计算得到每个词组各自与优选名词的匹配度;
114.将每个词组对应的频次乘以对应的权重值后再加上计算得到的每个词组各自与优选名词的匹配度,计算得到所述限定词集合中的每个词组对应的匹配值。
115.进一步的,该程序被处理器执行时具体实现以下步骤:
116.识别出所述图像数据中位于标题位上的文字,所述图像数据为通过拍摄处于阅读状态下的纸质读物而获取;
117.根据每个词组对应的频次、每个词组各自与优选名词的匹配度以及位于标题位上的文字计算得到所述限定词集合中的每个词组对应的匹配值。
118.进一步的,该程序被处理器执行时还实现以下步骤:
119.获取阅读者在预设时段内的阅读数据;所述阅读数据包括历史关键词、阅读时段和阅读力数据;
120.根据每个词组对应的频次、每个词组各自与优选名词的匹配度、位于标题位上的文字以及所述阅读数据计算得到所述限定词集合中的每个词组对应的匹配值。
121.综上所述,本发明提供的一种关键词的选取方法,通过将从一图像数据中识别出的包含的所有文字分割成两个以上的词组,再选取出属于限定词或名词的词组并进行分别归类,得到各自对应的限定词集合和名词集合;接着分别从限定词集合和名词集合选取出优选名词和优选限定词组成本方案最终的关键词。其中,按照先确定优选名词再确定优选限定词顺序执行选取方法,在选取优选限定词时,先判断在所述限定词集合中是否有与所
述优选名词位于同一整句中的限定词;若有,则判断所述位于同一整句中的限定词的数量是否不小于两个;若是,则选取与所述优选名词之间的间隔最少文字数量的限定词作为优选限定词;若否,则将所述位于同一整句中的限定词作为优选限定词;若无,则对所述限定词集合中的每个词组分别统计出现的频次,根据每个词组对应的频次以及每个词组各自与优选名词的匹配度计算得到所述限定词集合中的每个词组对应的匹配值,将匹配值最高的词组作为优选限定词。通过该方式得到的优选限定词能够与优选名词存在较高的关联性,最后通过由该优选名词和优选限定词组成的关键词能够更加全面地反映出该文本的核心思想,有助于提升阅读效果。本发明还提供的一种关键词的选取系统,同样能够达到上述所宣称的技术效果。
122.以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等同变换,或直接或间接运用在相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1