基于半监督的信息熵主成分分析降维方法
1.本发明属于计算机技术应用领域,涉及一种基于半监督的信息熵主成分分析的降维方法。
背景技术:
2.近年来,随着数据挖掘技术的迅速发展,数据挖掘技术已经在很多领域得到广泛的应用,例如经济、环境、医疗等,但是,随着数据挖掘技术的不断深入,数据的维数也开始增加,从一开始的一维、二维、三维变成几十维、几百维、几千维,人们开始将关注度转到数据的降维方面,因此,也随之产生了许多降维技术。
3.降维方法主要分为线性降维方法和非线性降维两种,其中,线性降维的方法主要有主成分分析(pca),线性判别分析(lda)等,非线性降维的方法主要有核主成分分析(kpca)以及基于流行的局部线性嵌入(lle)等,随着降维技术的不断发展,pca降维方法也出现了许多缺陷,而对于这些缺陷,一些学者们也相继提出了改进的算法,但是改进之后,会由于原始数据的维数太高,信息复杂,而导致分类器的识别度不高。
技术实现要素:
4.鉴于此,本发明主要解决由于原始数据的维数太高,信息复杂,而导致分类器的识别度不高的问题,使得降维后的数据可以在较低内存,用时较少的情况下得以继续分析处理,本发明主要使用了信息熵以及半监督方法,对主成分分析(pca)算法进行了改进,提出了一种基于半监督的信息熵的主成分分析算法。
5.综上,现有的模型很难从自身上来提高对数据中异常值和噪声的鲁棒性。
6.为了达到上述目的,本发明基于半监督以及信息熵对pca算法进行了改进,其算法步骤如下:
7.步骤一:定义待说明的高维数据集
8.步骤二:先使用半监督技术对数据集x中的数据进行标记,标记那些距离较近且对数据集有用的数据,这样就可以区分距离较远的数据以及无用的数据。
9.步骤三:将未标记的数据从数据集x中删除,并将数据集x中的已标记的数据重新进行标记,并将剩余的m个数据放入数据集s中,即s={s1,s2,
…
,s
m
},其中(m<n),这样就使原数据集x中的维数进一步的降低,而不会改变原数据集中的高维数据以及成对约束的结构。
10.步骤四:进一步地,使用k
‑
means聚类方法对重构的数据集s进行聚类处理。
11.步骤五:进一步,计算每个属性的信息熵,信息熵公式如下:步骤五:进一步,计算每个属性的信息熵,信息熵公式如下:
12.步骤六:进行特征筛选,将计算出的信息熵值与阈值δ进行比较,如果信息熵值h(s
i
)>δ,将对应的s
i
放入数据集b中,否则将该数据删除。
13.步骤七:重复第六步,直至将数据集s中的数据比较结束,将数据集s经过进一步筛
选,筛选出一些无用且距离较远的数据,保留了对分析样本有用的数据点集,然后将这些筛选好的数据放入数据集a中。
14.步骤八:分割数据矩阵[b,c]=randomsplit(matrix)//b为训练集,c为检验集。
[0015]
步骤九:样本b矩阵中心化即每一维度减去该维度的均值,计算公式为:x=b
–
repmat(mean(b,2),1,m1)。
[0016]
步骤十:将数据集a中的数据样本矩阵中心化,得到矩阵a。
11.步骤十一:计算矩阵a中每个属性的协方差。
[0018]
步骤十二:将每个属性的协方差放入一个矩阵中,组成协方差矩阵cov。
[0019]
步骤十三:计算协方差矩阵cov的特征值eigenvalue以及特征向量eigenvector。
[0020]
步骤十四:选择最大的k个特征值对应的k特征向量分别作为列向量组成特征向量矩阵v
n*k
。
[0021]
步骤十五:计算降维结果:y=v
t
*x。
[0022]
步骤十六:对矩阵c进行中心化。
[0023]
步骤十七:计算结果。
附图说明
[0024]
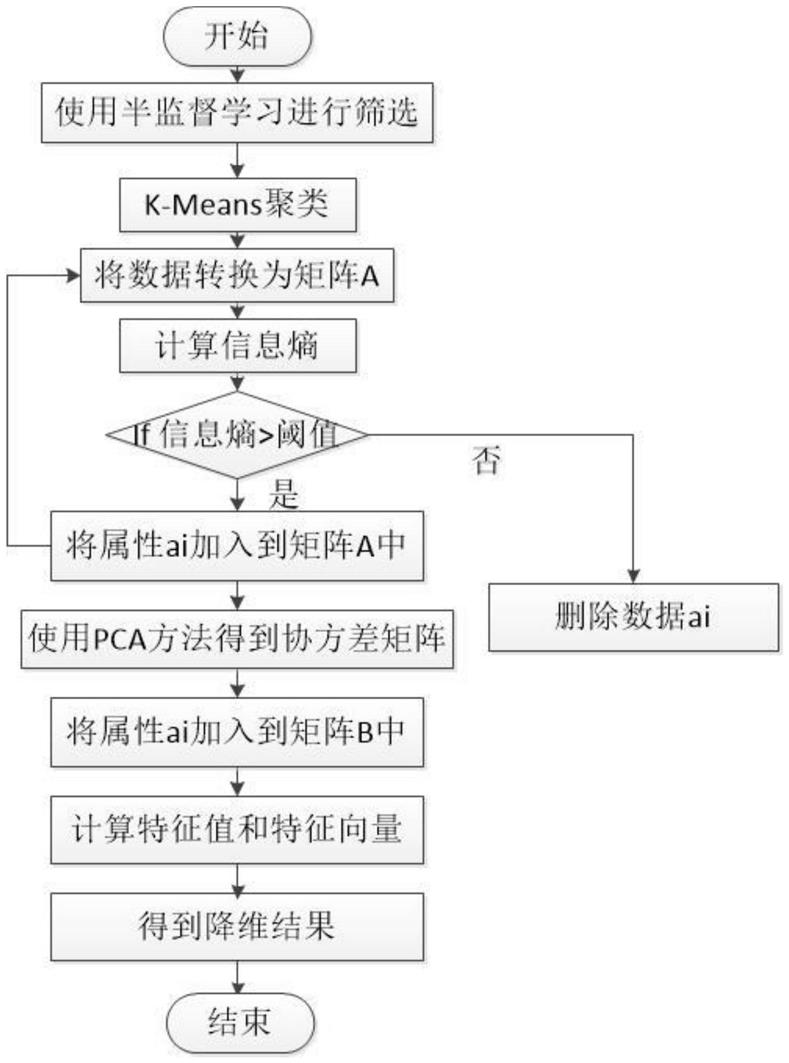
图1为本发明基于半监督的信息熵主成分分析的流程图。
具体实施方式
[0025]
下面将结合本发明实施的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实例仅仅是本发明一部分实施例子,而不是全部实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026]
如图1所示,本发明提供了一种基于半监督的信息熵主成分分析降维方法,其基本实现过程如下:
[0027]
1、输入数据预处理。
[0028]
输入高维数据集其中表示数据的维数(一般情况下,n表示数据样本总数。
[0029]
2、半监督标记。
[0030]
先使用半监督技术对数据集x中的数据进行标记,标记那些距离较近且对数据集有用的数据,这样就可以区分距离较远的数据以及无用的数据。
[0031]
将未标记的数据从数据集x中删除,并将数据集x中的已标记的数据重新进行标记,并将剩余的m个数据放入数据集s中,即s={s1,s2,
…
,s
m
},其中(m<n),这样就使原数据集x中的维数进一步的降低,而不会改变原数据集中的高维数据以及成对约束的结构。
[0032]
3、k
‑
means方法进行聚类。
[0033]
使用k
‑
means聚类方法对重构的数据集s进行聚类处理。
[0034]
4、构建基于信息熵主成分分析降维的模型。
[0035]
计算每个属性的信息熵,信息熵公式如下:
[0036]
进行特征筛选,将计算出的信息熵值与阈值δ进行比较,如果信息熵值h(s
i
)>δ,将对应的s
i
放入数据集b中,否则将该数据删除。
[0037]
重复上述步骤,直至将数据集s中的数据比较结束,将数据集s经过进一步筛选,筛选出一些无用且距离较远的数据,保留了对分析样本有用的数据点集,然后将这些筛选好的数据放入数据集a中。
[0038]
5、数据降维。
[0039]
分割数据矩阵[b,c]=randomsplit(matrix)//b为训练集,c为检验集。
[0040]
样本b矩阵中心化即每一维度减去该维度的均值,计算公式为:
[0041]
x=b
–
repmat(mean(b,2),1,m1)
[0042]
将数据集a中的数据样本矩阵中心化,得到矩阵a。
[0043]
计算矩阵a中每个属性的协方差。
[0044]
将每个属性的协方差放入一个矩阵中,组成协方差矩阵cov。
[0045]
计算协方差矩阵cov的特征值eigenvalue以及特征向量eigenvector。
[0046]
选择最大的k个特征值对应的k特征向量分别作为列向量组成特征向量矩阵v
n*k
。
[0047]
计算降维结果:y=v
t
*x。
[0048]
对矩阵c进行中心化。
[0049]
计算结果。
[0050]
信息熵处理之后的数据进入pca处理流程,首先样本中心化,在计算不同属性之间的协方差,形成协方差矩阵,再计算协方差矩阵的特征值和特征向量,计算各特征值的贡献率f确定k值,进而确定主成分个数,抽取最大的k个特征值对应的k个特征向量作为变化基,将原始数据进行降维,最后得到结果v
k*m
,以便后续分析计算。
[0051]
综上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1