基于高斯混合模型和标签矫正模型的噪声标签分割方法
1.本发明属于医学图像噪声标签领域,用于处理医学图像中由于各种原因引起的噪声标签问题,具体提出了一种基于高斯混合模型和标签矫正模型的噪声标签分割方法。
背景技术:
2.图像分割是医学图像处理分析中的一个重要步骤,是图像处理、计算机视觉领域中的经典问题。医学图像的噪声标签分割一直是医学图像分析领域的一个新兴热点。噪声标签分割具体指训练数据集的标签存在各种噪声,会对模型的训练产生影响,直接导致模型的精度下降。而在实际生活中,因为专家疲惫或者本身较难区分等原因也确实存在部分漏标、错标等现象,噪声标签分割是真实存在的。因此,如何在没有进一步注释的情况下消除噪声标签对分割任务的干扰是一个值得研究的问题与挑战。
3.目前,医学图像噪声标签的处理方法主要可分为两大类:基于梯度的以及基于模型结构的。前者基于噪声标签在模型训练过程中往往更加难以拟合这一观点,ren等人就通过这一想法寻找噪声标签并为这些标签样本分配了较低的权重。而后者则主要对模型结构进行改进,如goldberger等人设计了一个适应层来模拟潜在真实标签被破坏成嘈杂标签的过程,jiang等人引入mentornet来发现“正确的”样本并更多地关注它们,xue等人设计了一种在线不确定性样本挖掘方法和一种重新加权策略以消除噪声标签的干扰。当然,目前绝大多数研究都集中在分类任务上,因为它是自然图像处理领域中最基本的问题。而分割问题相较于分类问题可以将噪声标签的处理分为两大类:图像级别的以及像素级别的。前者主要为区分带噪声的图片与不带噪声的图片,以zhu等人的标签质量评估策略为代表;而后者则面向像素点直接纠正,如zhang等人的置信学习方法通过混淆矩阵的方法寻找可能标记错误的像素点并进行纠正。
4.而本发明从图像、像素两个级别出发,具体提出了基于高斯混合模型和标签矫正模型的噪声标签分割方法,运用高斯混合模型寻找噪声标签、运用标签矫正模型矫正标签,从而有效较少了噪声标签所带来的精度下降。
技术实现要素:
5.本发明的目的在于针对现有技术的不足,基于高斯混合模型和标签矫正模型的噪声标签分割方法,从而解决了噪声标签背景下的医学图像感兴趣区域的分割问题。本发明通过分割模块、高斯混合模型、标签矫正模块、置信反传模块四个模块相结合,实现了噪声标签下的医学图像感兴趣区域的分割。
6.本发明的基于高斯混合模型和标签矫正模型的噪声标签分割方法,包括以下步骤:
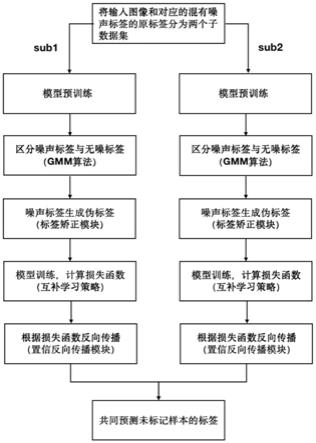
7.(1)将输入图像和对应的混有噪声标签的原标签分为两个子数据集,对每个子数据集分别进行下述步骤(2)-(6);
8.(2)根据输入图像和混有噪声标签的原标签进行简单模型预训练,并使用预训练
模型预测输入图像,得到预测分割结果;
9.(3)计算损失函数,并利用自信预测熵对其进行修正,对修正后的损失函数采用期望最大化(em)算法拟合高斯混合模型,从而对混有噪声标签的原标签进行聚类,区分得到无噪标签和含噪标签;
10.(4)对含噪标签使用标签矫正模块:计算输入图像中每个像素的显著度,以及属于目标区域的概率,根据计算结果判断像素点是否属于目标区域,得到输入图像的伪标签;
11.(5)在训练过程中,采用互补学习策略,将上述两个子数据集训练得到的两个网络互相校对,以剔除确认偏差;
12.(6)在梯度反向传播阶段,运用置信反向传播模块,仅使用低噪声伪标签和无噪的原标签对网络进行反向传播;
13.(7)训练结束后,由来自两个网络的模型共同预测测试样本的标签。
14.上述技术方案中,优选的,所述的步骤2)为:对输入图像和混有噪声标签的原标签的数据集x={x
(t)
,y
(t)
}k运用分割网络训练10-50回合作为预训练模型,并使用预训练模型对输入图像x
(t)
进行预测,得到预测分割结果记做:
[0015][0016]
其中,x
(t)
∈rn×m表示数据集中第t个输入图像,y
(t)
∈nn×m表示数据集中第t个原标签,m、n为图片长宽像素点个数,k表示数据集样本数量,f表示特征提取器,c为分类器,c(f(
·
))即为预训练模型。其中,所述分割网络可以任意选取,例如unet、deeplab等。
[0017]
所述的数据集样本数量k约为200-1000个样本,原标签中噪声标签的含量为25%-75%不等。
[0018]
上述技术方案中,优选的,所述的步骤3)为:
[0019]
采用交叉熵损失对输入图像x(i)与标签y(i)计算损失函数,根据预测分割结果计算自信预测熵h,利用自信预测熵h修正损失函数,得到最后,运用高斯混合模型对损失函数的集合进行聚类,并根据概率将其分为无噪标签和含噪标签。
[0020]
更优选的,所述的步骤3)具体为:
[0021]
1)计算损失函数
[0022]
损失函数具体采用交叉熵损失,对于输入图像x
(t)
与原标签y
(t)
,其损失函数为:
[0023][0024]
式中,为预测分割结果中第i行第j列像素点,为原标签中第i行第j列像素点。
[0025]
2)计算网络的自信预测熵:
[0026][0027][0028]
式中,c表示类别,为第c个类别的概率,x为输入图片,θ为模型参数;
[0029]
最后,计算修正后的损失函数:
[0030][0031]
3)区分无噪标签和含噪标签
[0032]
对所有损失函数所构成的集合进行归一化,得到归一化后的集合l
pred_noise
,对l
pred_noise
使用期望最大化(em)算法拟合一个双分量的高斯混合模型。至此,第t个样本标签属于无噪标签和含噪标签的概率为后验概率和
[0033][0034][0035]
式中,表示归一化后的集合l
pred_noise
中第t个样本标签所对应的值;
[0036]
上述高斯混合模型拟合后得到两个高斯分量,其中,g
small
为均值较小的一个高斯分量,g
large
为均值较大的一个高斯分量。对于每个样本标签,当时,我们判定它为无噪标签;反之,我们认为它是含噪标签,并需要对其重新进行标注。
[0037]
优选的,步骤3)中所述的高斯混合模型,具体为:
[0038][0039]
优选的,步骤3)中所述em算法,
[0040]
具体为:
[0041]
1)计算似然函数
[0042][0043]
2)对似然函数取对数
[0044][0045]
式中,n为样本标签和预测分割结果的个数;
[0046]
3)对上式求导,令导数为0,得似然方程;解似然方程,得到参数值μ1,σ1,μ2和σ2。
[0047]
优选的,所述的步骤4)为:从疑似目标区域(即预训练预测分割结果所对应的区域)中挑选出最具代表性的显著区域(显著度较高的区域),并以显著区域的特征作为计算伪标签的特征,经过标签矫正,得到伪标签y’(t)
。
[0048]
优选的,所述的步骤4)中显著区域,计算方法如下:
[0049]
1)对于输入图像x
(t)
,根据预训练所得特征向量计算每个像素的显著度。其中,图像中任意像素点的特征向量指特征提取器f输出结果中第i行第j列的值,即:
[0050][0051]
所述特征提取器f与上述步骤2)中相同;
[0052]
像素点p的显著度的计算方式如下:
[0053][0054]
其中,p,q均为图片上任意像素点,||f(p)||2||f(q)||2代表点p和点q的特征向量之间的欧式距离,r
sus
表示输入图像中与预测分割结果相对应的区域,即疑似目标区域。显著度s(p)衡量了像素点p在疑似目标区域内的显著度,其值越大,p越能够代表整个疑似目标区域。
[0055]
2)根据显著度求解显著区域。我们在显著度的基础上指定阈值σ(本发明中优选σ=0.7),选取s(p)>σ的点p所构成的区域作为显著区域,记做proto={p|s(p)>σ}。
[0056]
优选的,所述步骤4)中伪标签计算步骤,具体如下:
[0057]
1)我们为输入图像x
(t)
中的每个像素点p重新计算属于目标区域的概率:
[0058][0059]
其中,k为显著区域proto内像素点的个数,protoj为显著区域内第j个像素点的特征向量,||f(p)||2||protoj||2表示点p和显著区域内第j个像素点特征向量之间的欧氏距离;
[0060]
2)当score(p)>η时(本发明中优选η=0.7),我们将像素划分为前景点,反之,将其划分为背景点。得到的所有前景点构成目标区域,背景点构成非目标区域。
[0061]
3)对伪标签进行进一步的后处理优化:(1)去除面积过小的连通目标区域,将其作为非目标区域。(2)填充目标区域内部的小孔,将其作为目标区域。根据经验,所述的面积过小的连通目标区域和所述的目标区域内部的小孔,皆选择面积小于原目标区域总面积10%的连通区域。
[0062]
优选的,所述的步骤5)为:在训练过程中,采用互补学习策略,对每个子数据集均进行如下操作:线性组合混有噪声标签的原标签y
(t)
与对于当前子数据集网络下步骤4)中重新生成的伪标签y’(t)
,在步骤3)中由另一个子数据集训练生成网络所产生的干净概率w
(t)
的指导下,对标记样本进行标签协同细化:
[0063][0064]
其中,干净概率w
(t)
即为另一个子数据集在步骤3)中产生的属于无噪标签的概率。
[0065]
优选的,所述的步骤6)为:将协同细化后的伪标签作为目标进行训练,在网络的反向传播过程中,通过拟合一个二分量的高斯混合模型来鉴别伪标签的噪声程度,筛除噪声程度较高的伪标签,不让这部分标签参与网络的梯度计算。
[0066]
更优选的,所述的步骤6)具体为:
[0067]
1)对每张图片根据步骤5)中生成的伪标签计算交叉熵损失:
[0068][0069]
其中,为当前训练网络预测结果。
[0070]
2)将“新生成”的伪标签分为高噪声伪标签和低噪声伪标签
[0071]
对“新生成”的伪标签所构成的损失函数集合的伪标签所构成的损失函数集合进行归一化,得到归一化后的集合l
pse_ce
。对l
pred_ce
使用期望最大化(em)算法拟合一个双分量的高斯混合模型,将对“新生成”的伪标签分为高噪声伪标签和低噪声伪标签,拟合方法与步骤3)中相类似。
[0072]
3)筛除高噪声伪标签,仅对低噪声伪标签和无噪标签进行梯度反向传播。
[0073]
优选的,所述的步骤7)为:使用两个子数据集所训练的模型分别对待分割图像x
test
进行分割,图像x
test
中像素点p属于目标区域的概率为两个模型输出的概率的平均值。
[0074]
本发明还提供一种基于高斯混合模型和标签矫正模型的图像分割系统,该系统由上述方法训练得到。
[0075]
本发明所提出的基于高斯混合模型和标签矫正模型的噪声标签分割方法,与传统的噪声标签分割算法相比,本发明通过高斯混合模型在图片级别区分噪声标签与无噪标签,运用显著区域的方式在像素级别矫正噪声标签,并且提出了互补学习策略、置信反向传播模块等,更为有效地矫正了噪声标签,避免了模型训练中噪声标签过拟合所带来的精度误差,从而大大提高目标区域的分割精度。
附图说明
[0076]
图1是本发明实施的一种基于高斯混合模型和标签矫正模型的噪声标签分割方法流程图;
[0077]
图2是本发明实施的一种基于高斯混合模型和标签矫正模型的噪声标签分割方法模型图(子数据集部分);
[0078]
图3是本发明实施例所述的标签矫正模块示意图;
[0079]
图4是本发明实施例与传统噪声标签分割方法的效果对比图。
具体实施方式
[0080]
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
[0081]
如图1所示是本发明提供的基于高斯混合模型和标签矫正模型的噪声标签分割方法流程图。包括如下步骤:
[0082]
(1)将输入图像和对应的混有噪声标签的原标签分为两个子数据集,对每个子数据集分别进行下述步骤(2)-(6);
[0083]
(2)根据输入图像和混有噪声标签的原标签进行简单模型预训练,并使用预训练模型预测输入图像,得到预测分割结果;
[0084]
(3)计算损失函数,并利用自信预测熵对其进行修正,对修正后的损失函数采用期望最大化(em)算法拟合高斯混合模型,从而对混有噪声标签的原标签进行聚类,区分得到无噪标签和含噪标签;
[0085]
(4)对含噪标签使用标签矫正模块:计算输入图像中每个像素的显著度,以及属于目标区域的概率,根据计算结果判断像素点是否属于目标区域,得到输入图像的伪标签;
[0086]
(5)在训练过程中,采用互补学习策略,将上述两个子数据集训练得到的两个网络互相校对,以剔除确认偏差;
[0087]
(6)在梯度反向传播阶段,运用置信反向传播模块,仅使用低噪声伪标签和无噪的原标签对网络进行反向传播;
[0088]
(7)训练结束后,由来自两个网络的模型共同预测测试样本的标签。
[0089]
所述的步骤2)为:对输入图像和混有噪声标签的原标签的数据集x={x
(t)
,y
(t)
}k运用分割网络训练10-50回合作为预训练模型,并使用预训练模型对输入图像x
(t)
进行预测,得到预测分割结果记做:
[0090][0091]
其中,x
(t)
∈rn×m表示数据集中第t个输入图像,y
(t)
∈nn×m表示数据集中第t个原标签,m、n为图片长宽像素点个数,k表示数据集样本数量,f表示特征提取器,c为分类器,c(f(
·
))即为预训练模型。
[0092]
所述的步骤3)为:
[0093]
采用交叉熵损失对输入图像x(i)与标签y(i)计算损失函数,根据预测分割结果计算自信预测熵h,利用自信预测熵h修正损失函数,得到最后,运用高斯混合模型对损失函数的集合进行聚类,并根据概率将其分为无噪标签和含噪标签。
[0094]
更优选的,所述的步骤3)具体为:
[0095]
1)计算损失函数
[0096]
损失函数具体采用交叉熵损失,对于输入图像x
(t)
与原标签y
(t)
,其损失函数为:
[0097][0098]
式中,为预测分割结果中第i行第j列像素点,为原标签y
(t)
中第i行第j列像素点。
[0099]
2)计算网络的自信预测熵:
[0100][0101][0102]
式中,c表示类别,为第c个类别的概率,x为输入图片,θ为模型参数;
[0103]
最后,计算修正后的损失函数:
[0104][0105]
3)区分无噪标签和含噪标签
[0106]
对所有损失函数所构成的集合进行归一化,得到归一化后的集合l
pred_noise
,对l
pred_noise
使用期望最大化(em)算法拟合一个双分量的高斯混合模型。至此,第t个样本标签属于无噪标签和含噪标签的概率为后验概率和
[0107][0108][0109]
式中,表示归一化后的集合l
pred_noise
中第t个样本标签所对应的值;
[0110]
上述高斯混合模型拟合后得到两个高斯分量,其中,g
small
为均值较小的一个高斯分量,g
large
为均值较大的一个高斯分量。对于每个样本标签,当时,我们判定它为无噪标签;反之,我们认为它是含噪标签,并需要对其重新进行标注。
[0111]
步骤3)中所述的高斯混合模型具体为:
[0112][0113]
步骤3)中所述em算法,具体为:
[0114]
1)计算似然函数
[0115]
[0116]
2)对似然函数取对数
[0117][0118]
式中,n为样本标签和预测分割结果的个数;
[0119]
3)对上式求导,令导数为0,得似然方程;解似然方程,得到参数值μ1,σ1,μ2和σ2。
[0120]
所述的步骤4)为:从疑似目标区域(即预训练预测分割结果所对应的区域)中挑选出最具代表性的显著区域(显著度较高的区域),并以显著区域的特征作为计算伪标签的特征,经过标签矫正,得到伪标签y’(t)
。
[0121]
所述的步骤4)中显著区域,计算方法如下:
[0122]
2)对于输入图像x
(t)
,根据预训练所得特征向量计算每个像素的显著度。其中,图像中任意像素点的特征向量指特征提取器f输出结果中第i行第j列的值,即:
[0123][0124]
所述特征提取器f与上述步骤2)中相同;
[0125]
像素点p的显著度的计算方式如下:
[0126][0127]
其中,p,q均为图片上任意像素点,||f(p)||2||f(q)||2代表点p和点q的特征向量之间的欧式距离,r
sus
表示输入图像中与预测分割结果相对应的区域,即疑似目标区域。显著度s(p)衡量了像素点p在疑似目标区域内的显著度,其值越大,p越能够代表整个疑似目标区域。
[0128]
2)根据显著度求解显著区域。我们在显著度的基础上指定阈值σ(本发明中优选σ=0.7),选取s(p)>σ的点p所构成的区域作为显著区域,记做proto={p|s(p)>σ}。
[0129]
所述步骤4)中伪标签计算步骤,具体如下:
[0130]
1)我们为输入图像x
(t)
中的每个像素点p重新计算属于目标区域的概率:
[0131][0132]
其中,k为显著区域proto内像素点的个数,protoj为显著区域内第j个像素点的特征向量,||f(p)||2||protoj||2表示点p和显著区域内第j个像素点特征向量之间的欧氏距离;
[0133]
2)当score(p)>η时(本发明中优选η=0.7),我们将像素划分为前景点,反之,将其划分为背景点。得到的所有前景点构成目标区域,背景点构成非目标区域。
[0134]
3)对伪标签进行进一步的后处理优化:(1)去除面积过小的连通目标区域,将其作为非目标区域。(2)填充目标区域内部的小孔,将其作为目标区域。根据经验,所述的面积过
小的连通目标区域和所述的目标区域内部的小孔,皆选择面积小于原目标区域总面积10%的连通区域。
[0135]
所述的步骤5)为:在训练过程中,采用互补学习策略,对每个子数据集均进行如下操作:线性组合混有噪声标签的原标签y
(t)
与对于当前子数据集网络下步骤4)中重新生成的伪标签y’(t)
,在步骤3)中由另一个子数据集训练生成网络所产生的干净概率w
(t)
的指导下,对标记样本进行标签协同细化:
[0136][0137]
其中,干净概率w
(t)
即为另一个子数据集在步骤3)中产生的属于无噪标签的概率。
[0138]
所述的步骤6)为:将协同细化后的伪标签作为目标进行训练,在网络的反向传播过程中,通过拟合一个二分量的高斯混合模型来鉴别伪标签的噪声程度,筛除噪声程度较高的伪标签,不让这部分标签参与网络的梯度计算。
[0139]
步骤6)具体为:
[0140]
1)对每张图片根据步骤5)中生成的伪标签计算交叉熵损失:
[0141][0142]
其中,为当前训练网络预测结果。
[0143]
2)将“新生成”的伪标签分为高噪声伪标签和低噪声伪标签
[0144]
对“新生成”的伪标签所构成的损失函数集合的伪标签所构成的损失函数集合进行归一化,得到归一化后的集合l
pse_ce
。对l
pred_ce
使用期望最大化(em)算法拟合一个双分量的高斯混合模型,将对“新生成”的伪标签分为高噪声伪标签和低噪声伪标签,拟合方法与步骤3)中相类似。
[0145]
3)筛除高噪声伪标签,仅对低噪声伪标签和无噪标签进行梯度反向传播。
[0146]
所述的步骤7)为:使用两个子数据集所训练的模型分别对待分割图像x
test
进行分割,图像x
test
中像素点p属于目标区域的概率为两个模型输出的概率的平均值。
[0147]
本发明能较准确地实现噪声标签背景下的医学影像分割问题,从图片级别与像素级别分别考虑,更好地修正了噪声标签,从而提高了模型精度。如图4所示,采用本发明方法相对于传统噪声背景下的分割方法,具有更高的精度和准确率。
[0148]
以上实施方式仅用于说明本发明,而并非对本发明的限制,有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型,因此所有等同的技术方案也属于本发明的范畴,本发明的专利保护范围应由权利要求限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1