基于ELETRIC-BERT的实体抽取方法
基于eletric-bert的实体抽取方法
技术领域
1.本发明涉及一种基于eletric-bert的实体抽取方法,属于自然语言处理技术领域。
背景技术:
2.实体抽取,又称为命名实体识别,主要是识别出文本中实体的命名性指称项,并标明其类别,是信息抽取任务中的一项重要技术任务,在早期,主要是利用基于规则的方法进行实体抽取。基于规则的方法在小规模语料中,效果很好,但是需要人工编写相应规则,所以迁移能力差,通用性不强。后来,传统机器学习模型应用到了命名实体识别领域,以提高其鲁棒性。包括马尔可夫模型、最大熵模型等。基于传统机器学习模型的实体抽取方法,虽然取得了较好的性能,但是依赖于人工设计的特征,并且容易受到现有自然语言处理工具性能的影响。
3.近年来,随着深度学习的蓬勃发展,很多学者提出使用神经网络模型自动地从文本中提取特征,进而完成实体抽取任务,即使用深度学习模型进行实体抽取。基于深度学习的实体抽取模型,包括lample提出的bilstm-crf模型;chiu提出的bilstm-cnn以及zhang提出的latticelstm。这些基于深度学习的实体抽取模型,均取得了优于基于规则或传统机器学习模型的效果,但是需要大量的标注语料。标注大量语料,费时费力,特别是在电力领域这样的垂直领域,组织专家,标注大量语料,难以实现,只能获取到少量标注语料,所以如何利用少量的标注语料,实现准确的实体抽取,是信息抽取技术在电力系统领域应用过程中亟需攻克的一个难题。
技术实现要素:
4.为解决上述问题,本发明提供一种基于eletric-bert的实体抽取方法,在保证抽取准确率的同时,缓解模型对标注语料的依赖。
5.为了达到上述目的,本发明提供如下技术方案:
6.一种基于eletric-bert的实体抽取方法,,包括如下步骤:
7.步骤1:首先采集海量电力领域文本语料作为训练数据集;之后设计合适的预训练任务;最后进行预训练过程,对模型的参数进行更新,得到了蕴含丰富知识的领域预训练模型eletric-bert;
8.步骤2:将步骤1中通过预训练过程得到的领域预训练模型eletric-bert与实体抽取基本模型进行整合,得到基于eletric-bert的实体抽取模型;
9.步骤3:使用模块替换策略,将原模型参数量压缩为原来的一半;使用压缩后的模型,进行实体抽取任务,从文本语料中抽取出领域实体。
10.进一步的,所述步骤1中预训练任务为领域词完型填空,包括:对数据集中的文本语料进行句子级别的遮挡,每个句子随机遮挡其部分领域专有词,若句子中专有词不足,则使用standfordcorenlp进行依存分析,得到相应解析树,然后分析解析树,提取出句子中的
普通词,对这部分普通词进行遮挡,填补专有词的空缺。
11.进一步的,遮挡的专有词字数占总句子的15%。
12.进一步的,所述步骤1预训练过程中,模型对句子中遮挡住的专用词进行预测,基于预测误差计算出的梯度,使用梯度下降算法对模型的参数进行更新。
13.进一步的,所述步骤2中整合过程为:在实体抽取基本模型上叠加领域预训练模型进行训练。
14.进一步的,所述步骤3中模块替换策略使用6个未经训练的transformer encoderblock对eletric-bert中已经训练好的12个transformer encoder block进行学习,压缩之前的eletric-bert模型predecessor包含12个encoderblock,将其分为6个模块,分别为[prd1,prd2,prd3,
…
prd6],每个模块对应两个encoderblock,压缩后模型successor也分为6个模块,各模块分别为[scc1,scc2,scc3…
,scc6],每个模块包含1个encoder block,将successor中的每个模块与predecessor中的每个模块一一对应,在相应的自然语言处理任务驱动下,进行两阶段训练。
[0015]
进一步的,所述两阶段训练包括如下过程:
[0016]
(1)整合训练
[0017]
对于predecessor中的任一模块prdi,通过伯努利分布,采样一个随机变量γi,采样概率为p,即γi为1的概率为p,为0的概率为1-p,如下式所示
[0018]
γi~bernoulli(p)
[0019]
γi为1时,使用对应scci替换掉prdi;为0时,则保持原来的prdi不变;因此整合后的模型中任一个模块的输出yi由下式表示
[0020]
yi=γi*scci(y
i-1
)+(1-γ)*prdi(y
i-1
)
[0021]
模型训练一定次数直至收敛,转入微调训练阶段
[0022]
(2)微调训练
[0023]
将successor各个模块按照顺序串起来,在下游自然语言处理任务的驱动下,进行微调,更新相应参数。
[0024]
与现有技术相比,本发明具有如下优点和有益效果:
[0025]
本发明方法执行领域专用词完型填空预训练任务,能够训练出能自适应于电力领域的预训练模型,提升任务难度,增加了学到知识的丰富度。本发明采用了联合迁移和主动学习的实体抽取模型,大大减少人工标注样本,并对模型进行压缩,提高模型的训练和推理速度。与现有实体抽取技术相比,本发明可以在实现高准确抽取率的同时,大幅度减少模型对标注语料的依赖。
附图说明
[0026]
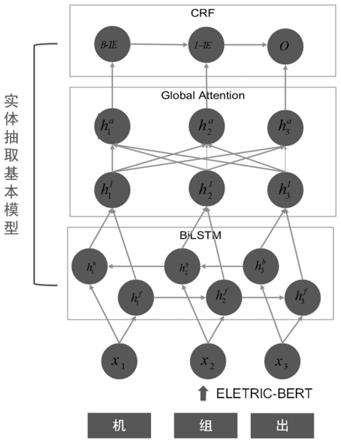
图1为本发明提供的基于eletric-bert的实体抽取方法总体框架图。
[0027]
图2展示了不同类型的遮挡,其中包括原字词、以字为单位的遮挡以及以词为单位的遮挡。
[0028]
图3为eletric-bert压缩示意图。
[0029]
图4为模型替换策略中的示意图,其中(a)为整合训练示意图,(b)为微调阶段示例图。
[0030]
图5为两个实验结果图,其中(a)为实体抽取实验结果图,(b)为模型压缩实验结果图
具体实施方式
[0031]
以下将结合具体实施例对本发明提供的技术方案进行详细说明,应理解下述具体实施方式仅用于说明本发明而不用于限制本发明的范围。
[0032]
本发明提供的一种基于eletric-bert的实体抽取方法,框架如图1所示,包括如下步骤:
[0033]
步骤1,通过预训练过程,得到领域预训练模型eletric-bert
[0034]
主要是在bert模型的基础上,首先采集海量电力领域文本语料作为训练数据集,将训练数据集作为数据支撑,之后设计合适的预训练任务;最后进行预训练过程,对模型的参数进行更新,从而得到蕴含丰富知识的领域预训练模型eletric-bert。
[0035]
执行的预训练任务为领域专用词完型填空,能够训练出能自适应于电力领域的预训练模型。bert是以字为单位进行遮挡,以字为单位进行遮挡,任务难度较易,相应得学到的知识有限,如附图2所示,句子
‘
哈尔滨是黑龙江的省会’,遮挡住字
‘
尔’后,可以通过旁边的
‘
哈’和
‘
滨’两个字,轻易预测出中间的字为
‘
尔’。而以词为单位进行遮挡,任务难度较难,相应得学到的知识更加丰富,遮挡住词
‘
哈尔滨’,必须深层次理解语义,才能预测出句首为词
‘
哈尔滨’。而本发明采用的领域词完形填空首先对数据集中的文本语料进行句子级别的遮挡,主要是以电力领域专有词为单位进行遮挡,预训练模型可以学习到更加深层次电力知识,下游的电力领域自然语言处理任务,在预训练模型的基础上进行微调,性能提升幅度更大。电力领域专有词主要是来自于电力系统长期沉淀出来的高质量词典,词典种类丰富,包括地名、电站名、电厂名、调度中心列表、线路列表等。具体地说,领域词完型填空任务,以领域专有词进行遮挡,对输入的每个句子,随机遮挡其部分专有词,遮挡的词的总字数占句子总字数的15%。如果句子中专有词的字数不足句子总字数的15%,则使用standfordcorenlp进行依存分析,得到相应解析树,分析解析树,随机提取出句子中的普通词补足句子总字数的15%,然后对上述15%的词(包括专有词和普通词)进行遮挡,填补领域专用词的短缺。之后在预训练过程中,模型需要对句子中遮挡住的专用词进行预测,基于预测误差计算出的梯度,使用梯度下降算法对模型的参数进行更新。
[0036]
本实施例中,训练数据为电力系统领域预训练语料,包括操作票、带电作业日志、电气缺陷日志、风险预警、检修单、历史故障日志、事故预案、运行方式调整发文。训练参数如下:epoch为60,batch size为16,learning rate为5e-5。优化器选择adamw优化算法,最后得到的领域预训练模型的困惑度为2.832。
[0037]
步骤2,将通过预训练过程得到的预训练模型eletric-bert与实体抽取基本模型bilstm+globalattention+crf进行整合,得到基于eletric-bert的实体抽取模型,以进行实体抽取。
[0038]
具体地说,就是在实体抽取基本模型上叠加领域预训练模型进行训练。实验数据为通过半自动化标注的电力系统语料数据集。标注的主要是一些典型实体类别,包括厂站、地区、设备、设备属性、指标属性等。实验结果如附图5(a)所示。使用全部训练集训练,模型性能达到最大f1值(0.960)。只使用60%的训练集,f1值(0.948)就达到了模型最高性能的
98.8%,说明联合迁移和主动学习的实体抽取模型可以大大减少人工标注样本。
[0039]
步骤3,由于步骤2得到的实体抽取模型参数量巨大,因此本步骤使用模块替换策略,对基于eletric-bert的实体抽取模型压缩,提高模型的训练和推理速度。最后使用压缩后的模型,进行实体抽取任务,从文本语料中抽取出领域实体。
[0040]
具体的,eletric-bert实体抽取模型,由12个相同结构的transformer encoder block(下文简称为encoder block)组成,参数量达1.1亿,训练和推理过程中计算量巨大。针对以上问题,本文提出使用模块替换策略,将eletric-bert原来的12个encoder block压缩为6个,压缩过程主要是通过模块替换策略实现的,如附图3所示。模块替换策略主要是使用6个未经训练的encoderblock对eletric-bert中已经训练好的12个encoder block进行学习,通过学习过程,可以学习到eletric-bert中蕴含的知识,从而取代原来的eletric-bert进行实体抽取。下面对模块替换策略进行详细描述。
[0041]
压缩之前的eletric-bert模型称为predecessor,压缩后模型称为successor,原模型与压缩模型均包含相同模块数。predecessor包含12个encoderblock,将其分为6个模块,分别为[prd1,prd2,prd3,
…
prd6],每个模块对应两个encoder block。同样将successor也分为6个模块,各模块分别为[scc1,scc2,scc3…
,scc6],每个模块包含1个encoder block。将successor中的每个模块与predecessor中的每个模块一一对应。在相应的自然语言处理任务驱动下(本文使用实体抽取任务),进行两阶段训练。第一阶段为整合训练,第二阶段为微调训练。
[0042]
整合训练阶段如附图4(a)所示,主要是predecessor与successor整合。predecessor是已经迭代收敛好的模型,参数不变,更新successor参数,也就是说让successor学习predecessor中的知识。整合过程如下:
[0043]
对于predecessor中的任一模块prdi,通过伯努利分布,采样一个随机变量γi,采样概率为p,即γi为1的概率为p,为0的概率为1-p,如下式所示
[0044]
γi~bernoulli(p)
[0045]
γi为1时,使用对应scci替换掉prdi;为0时,则保持原来的prdi不变。所以整合后的模型中任一个模块的输出yi可以由下式表示
[0046]
yi=γi*scci(y
i-1
)+(1-γ)*prdi(y
i-1
)
[0047]
模型训练一定次数收敛后,successor通过替换策略已经从predecessor学到了相应知识,接着转入阶段二,微调训练阶段。整合训练阶段完成后,需要将successor各模块联合起来训练,通过微调训练来实现。主要是将successor各个模块按照顺序串起来,在下游自然语言处理任务的驱动下,进行微调,更新相应参数,如附图4(b)所示。微调训练阶段完成后,successor可以取代predecessor,进行实体抽取。相比于原模型predecessor的12个encoder block,successor只有仅仅6个encoder block,压缩比为2,大大减少了模型参数量,显著提高了模型的训练和推理速度。
[0048]
在本实施例的模块替换策略中,compress ratio(压缩比例)设置为2,即原来领域预训练模型的12层transformer encoder block压缩成6层的transformer encoder block。replacing rate(替换比例)设置为0.5,即有50%概率原来predecessor的每个模块会被successor的对应模块替换。steps for replacing(整合训练阶段训练的步数),设置为一个动态的值,保证整合训练阶段和successor微调阶段所训练的步数相同。具体计算式
如下所示,其中totalepoch为全部样本训练次数,examples为样本数,batchsize为一次训练所选取样本数。
[0049][0050]
最后的结果图如附图5(b)所示,预训练模型参数被压缩为原来一半后,使用全部训练集训练,在测试集中的f1值,仍然能达到0.957,与压缩前模型达到的最大f1(0.960)相差不大,表明了模型压缩的有效性。模型使用70%的训练数据进行训练,f1值为0.945,也达到了的模型最高性能的98.7%,说明压缩后的联合迁移和主动学习的实体抽取模型也可以大大减少人工标注样本。
[0051]
本发明方案所公开的技术手段不仅限于上述实施方式所公开的技术手段,还包括由以上技术特征任意组合所组成的技术方案。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1