一种城市体检指标知识图谱构建方法及系统与流程
1.本发明涉及知识图谱领域,尤其涉及一种城市体检指标知识图谱构建方法及系统。
背景技术:
2.国土空间规划城市体检评估(以下简称“城市体检”),是指按照“一年一体检、五年一评估”的方式,对城市发展阶段特征及总体规划实施效果定期进行分析和评价。传统的通过关系数据库存储城市体检资源条目的方式,难以准确表达指标与安全、创新、协调、绿色、开放、共享城市体检六大维度间的关联强度,不便于指标间关联关系计算。且关系数据库在进行多层嵌套连接检索时,存在耗时长,性能低等问题。
3.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
4.本发明的主要目的在于,解决现有技术中,关系数据库存储城市体检资源条目检索性能低,难以挖掘指标间关联性的问题。
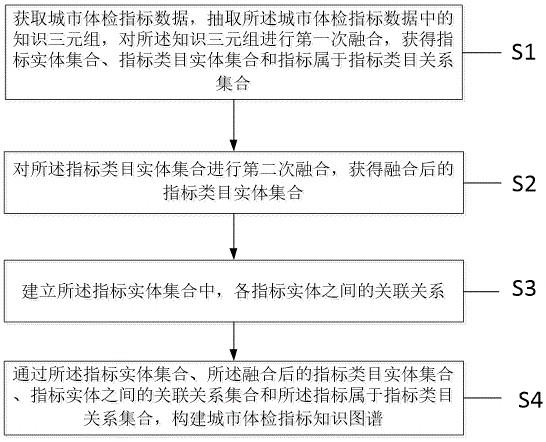
5.为实现上述目的,本发明提供一种城市体检指标知识图谱构建方法,包括:s1:获取城市体检指标数据,抽取所述城市体检指标数据中的知识三元组,对所述知识三元组进行第一次融合,获得指标实体集合、指标类目实体集合和指标属于指标类目关系集合;s2:对所述指标类目实体集合进行第二次融合,获得融合后的指标类目实体集合;步骤s2具体为:s21:计算获取所述指标实体集合的第一分类向量和第二分类向量;s22:通过所述第一分类向量、所述第二分类向量和所述指标属于指标类目关系集合,计算获得所述指标类目实体集合的所有第一向量和所有第二向量;s23:通过所有所述第一向量和所有所述第二向量,对所述指标类目实体集合进行第二次融合,获得所述融合后的指标类目实体集合;s3:建立所述指标实体集合中,各指标实体之间的关联关系;s4:通过所述指标实体集合、所述融合后的指标类目实体集合、指标实体之间的关联关系集合和所述指标属于指标类目关系集合,构建城市体检指标知识图谱。
6.优选地,步骤s21具体为:s211:所述指标实体集合中的各项指标实体的属性包括:指标名称属性、数值大小属性和数值单位属性,将所述指标实体的指标名称属性值分为n=6个分类进行标注;s212:对标注后的指标实体的指标名称属性值进行深度学习训练和模型调优,获得训练好的指标名称分类模型;s213:去除所述训练好的指标名称分类模型的顶层softmax层,对所述指标实体集
合中各指标实体的指标名称进行推理,获得第一分类向量=[x
i1, x
i2
……
x
in
],其中i表示指标实体的编号,x
ij
表示指标实体是第j分类的概率,j为[1,n]之间的整数,n表示分类的总数;s214:获取所述第一分类向量中的最大项,将所述最大项x
ij
对应的j的分类记作第一分类,将所述第一分类向量和第一分类保存至指标实体的属性中;s215:将n设置为23,重复步骤s211-s214,获得所述第二分类向量和第二分类,将所述第二分类向量和第二分类保存至指标实体的属性中。
[0007]
优选地,步骤s22具体为:s221:所述指标类目实体集合记为m(item),包含的指标类目实体个数为n(item),选取某一指标类目实体,通过所述指标属于指标类目关系,获取属于该指标类目实体的所有指标实体及该指标实体的第一分类向量;s222:将所述第一分类向量按行排列为矩阵a,表达式为:其中,m表示指标实体的总数,n表示分类的总数,x
mn
表示指标实体m是第n分类的概率,表示指标实体m的第一分类向量;s223:将该指标类目实体的第一向量记为,表达式为:其中,k表示指标实体的编号的计数;s224:将步骤s221-s223共迭代n(item)次,获取所述指标类目实体集合的所有第一向量;s225:选取某一指标类目实体,通过所述指标属于指标类目关系,获取属于该指标类目实体的指标实体及该指标实体的第二分类向量,重复步骤s222-s224,获取所述指标类目实体集合的所有第二向量。
[0008]
优选地,步骤s23具体为:s231:计算各所述第二向量间的余弦相似度,共执行次余弦相似度计算,获得个指标类目实体之间的第二相似度;s232:对于所述第二相似度大于预设阈值k1的两个指标类目实体,计算两者的第一向量间的余弦相似度作为第一相似度,对于所述第一相似度大于预设阈值k2的两个指标类目实体进行合并,完成所述第二次融合。
[0009]
优选地,步骤s3具体为:s31:将所述指标实体集合记为m(indicator),包含的指标实体的数量记为n(indicator),计算各所述指标实体之间的关联强度;s32:通过所述关联强度获取关联指标对集合m(pair)’;
s33:对所述关联指标对集合m(pair)’进行简化,获得简化后的关联指标对集合m(pair);s34:通过所述简化后的关联指标对集合m(pair)建立各所述指标实体之间的关联关系。
[0010]
优选地,步骤s31具体为:s311:对于编号为x和y的两个指标实体,通过深度学习模型获取指标实体x和指标实体y的指标名称语义相似度;获得指标实体x的第一分类向量和第二分类向量,以及指标实体y的第一分类向量和第二分类向量;s312:若指标实体x与指标实体y具有相同的第二分类向量,则指标分类相似度为1;若指标实体x和指标实体y的第二分类向量不同,但第一分类向量相同,则指标分类相似度为0.5;若指标实体x和指标实体y的第一分类向量和第二分类向量均不同,则指标分类相似度为0;s313:将指标实体x的数值大小属性值记为val(x),将指标实体y的数值大小属性值记为val(y),x与y的指标数值大小相似度的计算公式如下:s314:建立中英文映射表,将指标实体x和指标实体y的数值单位属性值转换为中文,将所述转换为中文的数值单位标记为领域,若指标实体x的数值单位和指标实体y的数值单位属于同一领域,则指标数值单位相似度为指标实体x和指标实体y的转换为中文的数值单位间的字符相似度;否则指标数值单位相似度为0;s315:计算获得所述关联强度,计算公式如下:关联强度s(x,y) = a*指标名称语义相似度+b*指标分类相似度+c*指标数值大小相似度+d*指标数值单位相似度其中,a、b、c和d均为预设的权重,a+b+c+d=1,且a,b,c,d∈(0,1)。
[0011]
优选地,步骤s32具体为:s321:将关联指标对集合记为m(pair)’,m(pair)’为若干个指标实体集合m(indicator)的子集的集合,将m(pair)’中包含的m(indicator)的子集个数记作n(m(pair)’);令指标实体的编号为z,z的初始值为1,将第z项指标实体记为mz,mz∈m(indicator);s322:若z的值小于n(indicator)则进入步骤s323,否则输出关联指标对集合m(pair)’;s323:计算mz与m(z+1)~m(n(indicator))之间的关联强度,将其中关联强度大于预设阈值k3的指标实体作为mz的关联指标集合,记作m(pair)’mz
,将关联指标集合m(pair)’mz
存储至m(pair)’中;令z=z+1并返回步骤s322。
[0012]
优选地,步骤s33具体为s331:令指标实体的编号z的初始值为1;关联指标对集合m(pair)’中包含的m(indicator)的子集个数为n(m(pair)’);
s332:若z的值小于或等于n(m(pair)’)则进入步骤s333,否则输出简化后的关联指标对集合m(pair);s333:对于第z项指标实体,从关联指标对集合m(pair)’中获取关联指标集合m(pair)’mz
,若m(pair)’mz
为空则令z=z+1并返回步骤s332;若m(pair)’mz
不为空则进入步骤s334;s334:将关联指标集合m(pair)’mz
中指标实体的数量记为n(m(pair)’mz
);s335:令计数p的初始值为1;s336:若p的值小于n(m(pair)’mz
)则进入步骤s337,否则令z=z+1并返回步骤s332;s337:若m(pair)’mz
中的第p项指标实体为ms,则从m(pair)’中获取m(pair)’ms
,若m(pair)’ms
不为空则进入步骤s338;若m(pair)’ms
为空则令p=p+1并返回步骤s336;s338:如果m(pair)’mz
中的第(p+1)项~第n(m(pair)’mz
)项实体,存在于m(pair)’ms
中,则删除m(pair)’ms
中对应的指标实体,同时更新m(pair)’中的m(pair)’ms
,令p=p+1并返回步骤s336。
[0013]
优选地,步骤s34具体为:s341:对于所述简化后的关联指标对集合m(pair),计m(pair)中m(indicator)子集的个数为n(m(pair));s342:令指标实体的编号z的初始值为1;s343:若z小于或等于n(m(pair))则进入步骤s344,否则完成建立各所述指标实体之间的关联关系;s344:从m(pair)中获取简化后的关联指标集合m(pair)
mz
,若m(pair)
mz
非空则进入步骤s345,否则令z=z+1并返回步骤s343;s345:将指标实体mz插入到m(pair)
mz
的最前面,对更新后的m(pair)
mz
中的各指标实体,依次按顺序在两个相邻指标实体之间建立关联关系,为所述关联关系添加关联强度属性,所述关联强度属性的值为相邻两个指标实体间的关联强度的值,令z=z+1并返回步骤s343。
[0014]
一种城市体检指标知识图谱构建系统,包括:第一次融合模块,用于获取城市体检指标数据,抽取所述城市体检指标数据中的知识三元组,对所述知识三元组进行第一次融合,获得指标实体集合、指标类目实体集合和指标属于指标类目关系集合;第二次融合模块,用于对所述指标类目实体集合进行第二次融合,获得融合后的指标类目实体集合;关联关系构建模块,用于建立所述指标实体集合中,各指标实体之间的关联关系;城市体检指标知识图谱构建模块,用于通过所述指标实体集合、所述融合后的指标类目实体集合、指标实体之间的关联关系集合和所述指标属于指标类目关系集合,构建城市体检指标知识图谱。
[0015]
本发明具有以下有益效果:1、通过图结构存储城市体检指标,提高了城市体检指标检索效率,便于指标推荐,有助于城市体检工作开展;2、通过对指标类目实体集合的第二次融合,提高图谱搜索性能和准确性;
3、通过对关联指标对集合的简化,去除了指标实体间的冗余关系,依靠图数据库的搜索特性,在保证被去除的关系仍能被检索到的前提下,极大提高图数据库关系搜索效率。
附图说明
[0016]
图1为本发明实施例方法流程图;图2为指标实体之间的关联关系简化结构示意图;图3为城市体检指标知识图谱结构示意图;图4为城市体检指标知识图谱实施例图结构示意图;图5为本发明实施例系统结构图;本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0017]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0018]
参照图1,本发明提供一种城市体检指标知识图谱构建方法,包括:s1:获取城市体检指标数据,抽取所述城市体检指标数据中的知识三元组,对所述知识三元组进行第一次融合,获得指标实体集合、指标类目实体集合和指标属于指标类目关系集合;s2:对所述指标类目实体集合进行第二次融合,获得融合后的指标类目实体集合;s3:建立所述指标实体集合中,各指标实体之间的关联关系;s4:通过所述指标实体集合、所述融合后的指标类目实体集合、指标实体之间的关联关系集合和所述指标属于指标类目关系集合,构建城市体检指标知识图谱。
[0019]
本实施例中,步骤s1具体为:s11:城市体检指标数据的来源包括全国国土调查及其年度变更调查、自然资源专项调查、地理国情普查,统计年鉴、统计公报和时空大数据等;对其中非结构化数据采取包括但不限于命名实体识别、实体关系识别、关键词提取、主题分析在内办法,对半结构化数据采取包括但不限于包装器的办法,对结构化数据采取包括但不限于etl(数据仓库技术)的办法,从城市体检指标数据中抽取出知识三元组;s12:知识三元组包括:初始指标实体集合、初始指标类目实体集合和初始指标属于指标类目关系集合;初始指标实体集合至少包括以下属性:指标名称属性、数值大小属性、数值单位属性和指标唯一标识属性;初始指标类目实体集合至少包括以下属性:指标类目唯一标识和指标类目名称;初始指标属于指标类目关系集合表示指标实体与指标类目实体之间的关系;s13:采取包括但不限于语义分析、正则匹配的方式对指标名称属性和指标类目名称属性进行清洗去重,然后采取包括但不限于数据映射、实体匹配和本体融合的方式将不同来源的知识三元组进行知识融合,最终获得指标实体集合、指标类目实体集合和指标属于指标类目关系集合;本实施例中,步骤s2具体为:
s21:计算获取所述指标实体集合的第一分类向量和第二分类向量;s22:通过所述第一分类向量、所述第二分类向量和所述指标属于指标类目关系集合,计算获得所述指标类目实体集合的所有第一向量和所有第二向量;s23:通过所有所述第一向量和所有所述第二向量,对所述指标类目实体集合进行第二次融合,获得所述融合后的指标类目实体集合。
[0020]
本实施例中,步骤s21具体为:s211:所述指标实体集合中的各项指标实体的属性至少包括:指标名称属性、数值大小属性和数值单位属性,将所述指标实体的指标名称属性值分为td/t 1063-2021中规定的n个指标分类维度进行标注,根据现行规定,n=6,分别是安全、创新、协调、绿色、开放、共享;具体实现中,例如指标实体集合中的某一个指标实体为:指标唯一标识:1指标名称属性:常住人口数目数值大小属性:2189数值单位属性:万人指标记录时间:2020年指标地域:北京市;s212:对标注后的指标实体的指标名称属性值进行深度学习训练和模型调优,获得训练好的指标名称分类模型;具体实现中,采用textcnn或bert+sigmoid模型进行训练;s213:去除所述训练好的指标名称分类模型的顶层softmax层,对所述指标实体集合中各指标实体的指标名称进行推理,获得第一分类向量=[x
i1, x
i2
……
x
in
],其中i表示指标实体的编号,x
ij
表示指标实体是第j分类的概率,j为[1,n]之间的整数,n表示分类的总数;s214:获取所述第一分类向量中的最大项,将所述最大项x
ij
对应的j的分类记作第一分类,将所述第一分类向量和第一分类保存至指标实体的属性中;s215:将n设置为td/t 1063-2021中规定的n个指标二级分类,根据现行规定,n=23,重复步骤s211-s214,获得所述第二分类向量和第二分类,将所述第二分类向量和第二分类保存至指标实体的属性中。
[0021]
本实施例中,步骤s22具体为:s221:所述指标类目实体集合记为m(item),包含的指标类目实体个数为n(item),选取某一指标类目实体,通过所述指标属于指标类目关系,获取属于该指标类目实体的所有指标实体及该指标实体的第一分类向量;s222:将所述第一分类向量按行排列为矩阵a,表达式为:其中,m表示指标实体的总数,n表示分类的总数,x
mn
表示指标实体m是第n分类的概率,表示指标实体m的第一分类向量;
s223:将该指标类目实体的第一向量记为,表达式为:其中,k表示指标实体的编号的计数;s224:将步骤s221-s223共迭代n(item)次,获取所述指标类目实体集合的所有第一向量;s225:选取某一指标类目实体,通过所述指标属于指标类目关系,获取属于该指标类目实体的指标实体及该指标实体的第二分类向量,重复步骤s222-s224,获取所述指标类目实体集合的所有第二向量。
[0022]
本实施例中,步骤s23具体为:s231:计算各所述第二向量间的余弦相似度,共执行次余弦相似度计算,获得个指标类目实体之间的第二相似度;s232:对于所述第二相似度大于预设阈值k1的两个指标类目实体,计算两者的第一向量间的余弦相似度作为第一相似度,对于所述第一相似度大于预设阈值k2的两个指标类目实体进行合并,完成所述第二次融合。
[0023]
参考图2,本实施例中,通过步骤s3获得的指标实体之间的关联关系,依靠图数据库的搜索特性,在保证被去除的关系仍能被检索到的前提下,可极大提高图数据库关系搜索效率;步骤s3具体为:s31:将所述指标实体集合记为m(indicator),包含的指标实体的数量记为n(indicator),计算各所述指标实体之间的关联强度;s32:通过所述关联强度获取关联指标对集合m(pair)’;s33:对所述关联指标对集合m(pair)’进行简化,获得简化后的关联指标对集合m(pair);s34:通过所述简化后的关联指标对集合m(pair)建立各所述指标实体之间的关联关系。
[0024]
本实施例中,步骤s31具体为:s311:对于编号为x和y的两个指标实体,通过深度学习模型获取指标实体x和指标实体y的指标名称语义相似度;获得指标实体x的第一分类向量和第二分类向量,以及指标实体y的第一分类向量和第二分类向量;s312:若指标实体x与指标实体y具有相同的第二分类向量,则指标分类相似度为1;若指标实体x和指标实体y的第二分类向量不同,但第一分类向量相同,则指标分类相似度为0.5;若指标实体x和指标实体y的第一分类向量和第二分类向量均不同,则指标分类相似度为0;s313:将指标实体x的数值大小属性值记为val(x),将指标实体y的数值大小属性
值记为val(y),x与y的指标数值大小相似度的计算公式如下:s314:建立中英文映射表,将指标实体x和指标实体y的数值单位属性值转换为中文,将所述转换为中文的数值单位标记为领域,若指标实体x的数值单位和指标实体y的数值单位属于同一领域,则指标数值单位相似度为指标实体x和指标实体y的转换为中文的数值单位间的字符相似度;否则指标数值单位相似度为0;具体实现中,例如建立如表1所示的中英文映射表表1处理前的数值单位处理后的数值单位%百分比cm3立方厘米斤/亩斤每亩将数值单位标记为领域,领域包括长度、重量、面积、数目、金额和比率等,采取正则匹配领域关键字的方式对数值单位进行标记,对于混合数值单位,分别标记分子和分母所属的领域;如“公斤/公顷”,对其标记分子“公斤”所属的领域“重量”和分母“公顷”所属的领域“面积”;对于指标实体x和指标实体y,若二者属于同一领域(对于混合数值单位,分子或分母所属领域与另一指标实体的数值单位领域相同即认为二者属于同一领域),则指标数值单位相似度为中文的数值单位间的字符相似度,字符相似度计算方法这里不做特殊限定;否则为0,计算公式如下所示:s315:计算获得所述关联强度,计算公式如下:关联强度s(x,y) = a*指标名称语义相似度+b*指标分类相似度+c*指标数值大小相似度+d*指标数值单位相似度其中,a、b、c和d均为预设的权重,a+b+c+d=1,且a,b,c,d∈(0,1)。
[0025]
本实施例中,步骤s32具体为:s321:将关联指标对集合记为m(pair)’,m(pair)’为若干个指标实体集合m(indicator)的子集的集合,将m(pair)’中包含的m(indicator)的子集个数记作n(m(pair)’);令指标实体的编号为z,z的初始值为1,将第z项指标实体记为mz,mz∈m(indicator);s322:若z的值小于n(indicator)则进入步骤s323,否则输出关联指标对集合m(pair)’;s323:计算mz与m(z+1)~m(n(indicator))之间的关联强度,将其中关联强度大于预设阈值k3的指标实体作为mz的关联指标集合,记作m(pair)’mz
,将关联指标集合m(pair)’mz
存储至m(pair)’中;令z=z+1并返回步骤s322。
[0026]
具体实现中,例如n(indicator)=5,执行s321-s323,计算得到mz(z∈[1,5),z为整数)的关联指标集合如下:m1的关联指标集合m(pair)’m1
为:m2、m3;m2的关联指标集合m(pair)’m2
为:m3;m3的关联指标集合m(pair)’m3
为:m4、m5;m4的关联指标集合m(pair)’m4
为:m5;则关联指标对集合m(pair)’如下所示:本实施例中,步骤s33具体为s331:令指标实体的编号z的初始值为1;关联指标对集合m(pair)’中包含的m(indicator)的子集个数为n(m(pair)’);s332:若z的值小于或等于n(m(pair)’)则进入步骤s333,否则输出简化后的关联指标对集合m(pair);s333:对于第z项指标实体,从关联指标对集合m(pair)’中获取关联指标集合m(pair)’mz
,若m(pair)’mz
为空则令z=z+1并返回步骤s332;若m(pair)’mz
不为空则进入步骤s334;s334:将关联指标集合m(pair)’mz
中指标实体的数量记为n(m(pair)’mz
);s335:令计数p的初始值为1;s336:若p的值小于n(m(pair)’mz
)则进入步骤s337,否则令z=z+1并返回步骤s332;s337:若m(pair)’mz
中的第p项指标实体为ms,则从m(pair)’中获取m(pair)’ms
,若m(pair)’ms
不为空则进入步骤s338;若m(pair)’ms
为空则令p=p+1并返回步骤s336;s338:如果m(pair)’mz
中的第(p+1)项~第n(m(pair)’mz
)项实体,存在于m(pair)’ms
中,则删除m(pair)’ms
中对应的指标实体,同时更新m(pair)’中的m(pair)’ms
,令p=p+1并返回步骤s336。
[0027]
具体实现中,例如:(1)第一次执行s331-s338;z=1;从m(pair)’中获取m(pair)’m1
=[m2,m3],m(pair)’m1
不为空;n(m(pair)’m1
)=2;令p=1;m(pair)’m1
的第1项指标实体为m2,从m(pair)’中获取m(pair)’m2
=[m3]为非空;m(pair)’m1
中的第2~2项实体是m3,m3存在于m(pair)’m2
中,删除m(pair)’m2
中的m3,同时更新m(pair)’为;(2)第二次执行s331-s338;z=2;此时从m(pair)’中获取m(pair)’m2
=[],m(pair)’m2
为空集合;
(3)第三次执行s331-s338;z=3;此时从m(pair)’中获取m(pair)’m3
=[m4,m5],m(pair)’m3
不为空;n(m(pair)’m3
)=2;令p=1;m(pair)’m3
的第1项指标实体为m4,从m(pair)’中获取m(pair)’m4
=[m5]为非空;m(pair)’m3
中的第2~2项实体是m5,m5存在于m(pair)’m4
中,删除m(pair)’m4
中的m5,同时更新m(pair)’为;(4)第四次执行s331-s338;z=4;此时从m(pair)’中获取m(pair)’m4
=[],m(pair)’m4
为空集合;输出简化后的关联指标对集合为:。
[0028]
本实施例中,步骤s34具体为:s341:对于所述简化后的关联指标对集合m(pair),计m(pair)中m(indicator)子集的个数为n(m(pair));s342:令指标实体的编号z的初始值为1;s343:若z小于或等于n(m(pair))则进入步骤s344,否则完成建立各所述指标实体之间的关联关系;s344:从m(pair)中获取简化后的关联指标集合m(pair)
mz
,若m(pair)
mz
非空则进入步骤s345,否则令z=z+1并返回步骤s343;s345:将指标实体mz插入到m(pair)
mz
的最前面,对更新后的m(pair)
mz
中的各指标实体,依次按顺序在两个相邻指标实体之间建立关联关系,为所述关联关系添加关联强度属性,所述关联强度属性的值为相邻两个指标实体间的关联强度的值,令z=z+1并返回步骤s343。
[0029]
具体实现中,例如:(1)第一次执行s341-s345;z=1;从m(pair)中获取m(pair)
m1
=[m2,m3],m(pair)
m1
非空;将m1插入到m(pair)
m1
的最前面,将m(pair)
m1
更新为[m1,m2,m3],依次建立m1与m2,以及m2与m3之间的关联关系;(2)第二次执行s341-s345;z=2;从m(pair)中获取m(pair)
m2
=[],m(pair)
m2
为空集合;(3)第三次执行s341-s345;
z=3;从m(pair)中获取m(pair)
m3
=[m4,m5],m(pair)
m3
非空;将m3插入到m(pair)
m3
的最前面,将m(pair)
m3
更新为[m3,m4,m5],依次建立m3与m4,以及m4与m5之间的关联关系;(4)第四次执行s341-s345;z=4;从m(pair)中获取m(pair)
m4
=[],m(pair)
m4
为空集合;完成建立各所述指标实体之间的关联关系。
[0030]
参考图3,为本实施例步骤s4构建的城市体检指标知识图谱结构示意图;参考图4,为本实施例步骤s4构建的城市体检指标知识图谱实例局部图,可以清晰的表现出指标实体之间的关联关系,以及指标实体与指标类目实体之间的从属关系;本发明的优点如下:(1)通过建立城市体检指标知识图谱,构建指标数据资源与安全、创新、协调、绿色、开放、共享六大维度及其二级分类间的关系,使得基于图谱的指标搜索结果与六大维度间强关联,搜索结果更符合对指标体系的规定,有利于城市体检工作的开展。
[0031]
(2)通过建立城市体检指标知识图谱,建立指标数据资源间的链路关系,有助于挖掘指标关联性,有助于指标探查与指标推荐,提升城市体检过程中指标体系构建步骤的工作效率。
[0032]
(3)通过去除指标实体间的冗余关系后,依靠图数据库的搜索特性,在保证被去除的关系仍能被检索到的前提下,极大提高图数据库关系搜索效率。
[0033]
参考图5,本发明提供一种城市体检指标知识图谱构建系统,包括:第一次融合模块10,用于获取城市体检指标数据,抽取所述城市体检指标数据中的知识三元组,对所述知识三元组进行第一次融合,获得指标实体集合、指标类目实体集合和指标属于指标类目关系集合;第二次融合模块20,用于对所述指标类目实体集合进行第二次融合,获得融合后的指标类目实体集合;关联关系构建模块30,用于建立所述指标实体集合中,各指标实体之间的关联关系;城市体检指标知识图谱构建模块40,用于通过所述指标实体集合、所述融合后的指标类目实体集合、指标实体之间的关联关系集合和所述指标属于指标类目关系集合,构建城市体检指标知识图谱。
[0034]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0035]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
[0036]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1