一种基于图同构网络的谓词抽取方法
1.本发明涉及信息抽取领域,具体来讲是一种基于图同构网络的谓词抽取方法。
背景技术:
2.信息抽取,即从自然语言文本中,抽取出特定的事实或事实信息,帮助我们将海量内容自动分类、提取和重构。这些信息通常包括实体、关系、事件等等。比如从新闻信息中抽取时间、地点、人物等信息,从病例数据中抽取患者症状、用药情况、疾病等信息。与其他自然语言任务相比,信息抽取任务更具有目的性,并能将抽取到的信息以指定的结构展现出现,从而达到从自然语言中提取用户感兴趣的事实信息的目的,在知识图谱领域中有着广泛的应用。
3.三元组抽取事一种经典的信息抽取任务,常见的三元组抽取结果可以用spo三结构的三元组来表示,即subject、predication和object。例如从文本“胡歌出演了《仙剑奇侠传》”中,可以提取出一个spo三元组(“胡歌”,“出演”,“仙剑奇侠传”)。
4.在三元组抽取中,如何抽取出谓词是一个非常重要的问题。过去常用的谓词抽取方法有人工模板方法、统计生成方法和基于依存的方法。其中,人工模板和统计生成方法都将三元组抽取视为一个整体任务,通过制定模板来匹配文本中存在的三元组。人工模板方法的基本出发点是通过大量人工的统计和总结模式信息,由领域专家定义寻找谓词在上下文中表达的字符、语法特征等,将其作为一种模式与文本进行匹配,最后获取想要的三元组结果。为了减少人们的工作量,统计生成的方法被提出,该方法主要基于搜索引擎进行模板的生成工作,具体来说,该方法将已知的三元组事实作为查询语句,通过搜索引擎返回的前n个结果文档并保留包含该三元组的句子集合,最后将包含三元组的最长字符串作为统计模板并保留置信度较高的模板用于三元组抽取。这两种方法具有较高的准确率,但是它们的适用性有限,难以移植。基于依存句法的方法则是将三元组抽取分成两个步骤,首先通过文本的词性、依存结构等信息抽取谓词,然后再以这个谓词作为出发点,利用句子中各个成分之间的联系和关系构建规则抽取主体和客体。该方法相对于人工模板和统计模板的方法具有更高的准确率,且适用于小规模的数据集,但是它同样存在着耗时耗力、难以维护等问题。
技术实现要素:
5.在综合考量上述问题后,本发明针对现有技术存在的问题,提出一种基于图同构网络的谓词抽取方法。
6.本发明解决其技术问题所采用的技术方案包括如下步骤:
7.步骤(1)使用ddparser工具对输入句子进行解析,得到分词结果、词性和句法依存树信息;
8.步骤(2)根据词性和分词结果,对分词中专有词进行泛化处理。对bert的词嵌入部分进行微调,加入对词性信息的编码。将泛化后的词序列及步骤(1)中的词性数据作为微调
后的bert模型的输入,输出隐藏向量的集合;
9.步骤(3)遍历步骤(1)中的句法依存树中任意两个节点构成的子树,把这棵子树中每条边的信息转换为边向量,然后再将这棵子树的信息以及步骤(2)的隐藏向量输入到gin网络中,获得节点嵌入向量,对节点嵌入向量做池化处理,得到子树的表征向量;
10.步骤(4)利用步骤(3)中的子树表征向量和步骤(2)中的每一个隐藏向量计算注意力权重,再将这个权重乘到步骤(3)中每个节点的嵌入向量中,得到最终的节点嵌入向量集合;
11.步骤(5)将步骤(4)中得到的带有语义信息的节点嵌入向量集合输入到一个二分类器中,得到一个二进制序列,序列中每一个二进制指示对应的词是否为谓词。
12.本发明有益效果如下:
13.本发明提出了一种基于图同构网络的谓词抽取方法。首先,本发明使用了ddparser工具对文本句子进行解析,并利用句子解析后得到的词性结果对分词序列中的专用名词进行泛化,以弱化一些无用语义信息对结果产生影响。于此同时,本发明对bert的嵌入部分做了调整,加入了对词性信息的编码,将泛化后的词序列输入到微调后的bert模型中进行编码。另外,为了强调原本句子中的依存结构信息,本发明使用了gin网络来获取依存树中每一个节点的嵌入向量以及依存子树的表征向量。再这之后通过一层注意力机制,将语义信息还有依存结构信息融合起来得到最终的节点嵌入向量。最后,本发明将最终的词嵌入向量集合输入到一个二分类器中,得到谓词结果。对比现有的技术,本发明使用了深度学习的方式学习句子的结构模板特征,大大减少了人们的工作量,有着较强的跨领域性和适应能力,有效提升了谓词抽取方法的准确性。
附图说明
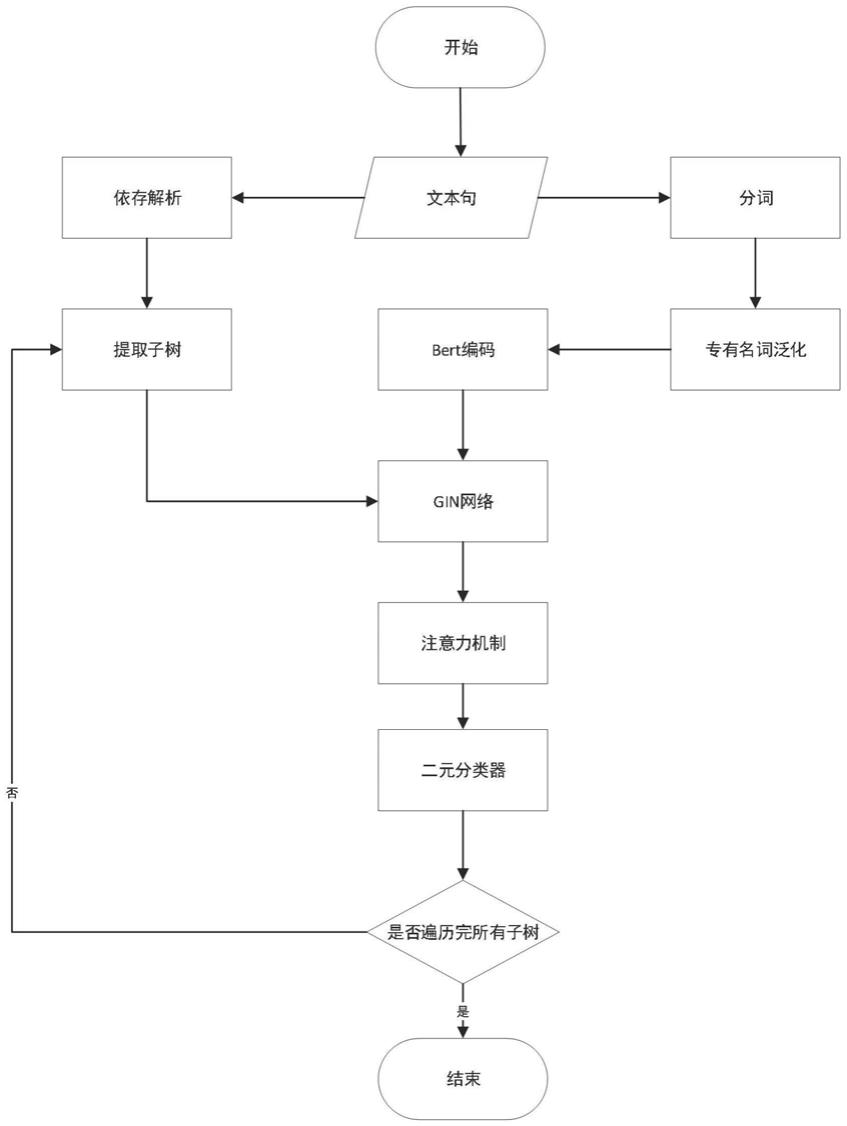
14.图1本发明的整体实施方案流程图
15.图2本发明的模型整体架构图
16.图3本发明的词嵌入构建图
17.图4本发明的注意力机制增强信息图
具体实施方式
18.下面结合附图对本发明作进一步描述。
19.如图1和2所示,一种基于图同构网络的谓词抽取方法,包括以下步骤:
20.一种基于图同构网络的谓词抽取方法,包括如下步骤:
21.步骤(1)使用ddparser工具对输入句子进行解析,得到分词结果、词性和句法依存树信息;
22.步骤(2)根据词性对分词中专有词进行泛化处理,得到泛化处理后输入句子对应的泛化词序列;对bert模型的词嵌入部分进行微调,在词嵌入部分加入词性信息的编码;将泛化词序列及步骤(1)中的词性信息作为微调后的bert模型的输入,输出隐藏向量集合;
23.步骤(3)遍历步骤(1)中句法依存树信息中任意一棵子树,把这棵子树中每条边的信息转换为边向量,然后再将这棵子树的信息以及步骤(2)的隐藏向量集合输入到gin网络中,获得节点嵌入向量,对节点嵌入向量做池化处理,得到子树的表征向量;
24.步骤(4)利用步骤(3)中子树的表征向量和步骤(2)中的每一个隐藏向量计算注意力权重,再将这个注意力权重与步骤(3)中每个节点嵌入向量相乘,得到最终节点嵌入向量集合;
25.步骤(5)将步骤(4)中得到的带有语义信息的最终节点嵌入向量集合输入到一个二分类器中,得到一个二进制序列,序列中每一个二进制指示对应的词是否为谓词。
26.进一步的,所述步骤(1)具体实现过程如下:
27.使用ddparser对文本句子进行解析,得到结果:
28.x=(x1,x2,
…
,xn)
ꢀꢀꢀꢀ
(1)
29.t(x)=(t1,t2,
…
,tn)
ꢀꢀꢀ
(2)
30.d(x)=dependency_parser(x)
ꢀꢀꢀ
(3)
31.其中,x表示分词后的序列,公式(1)中x1,x2,
…
,xn表示分词结果,公式(2)中t1,t2,
…
,tn对应于公式(1)中x1,x2,
…
,xn的词性标注结果,d(x)是句法依存树。
32.进一步的,所述步骤(2)具体实现过程如下:
33.2-1根据词性标注结果t(x)对原序列x进行泛处理,具体的规则内容如下:将词性标注结果为“loc”、“f”、“s”、“《time》”、“《loc》”、“《per》”、“《org》”、“nw”、“nz”的词替换为“pn”标签,得到泛化词序列x':
34.x'=(x'1,x'2,
…
,x'n)
ꢀꢀꢀ
(4)
35.其中,x'1,x'2,
…
,x'n表示泛化后的词汇;
36.2-2如图3所示,对bert模型的embedding结构做微调,在原来embedding结构中加入了postag embedding层用以添加词性信息;对泛化词序列x'做词嵌入处理,将泛化词序列x'送入token embedding层从而将每一个词转换为向量形式,将泛化词序列x'送入position embedding层获取每个词的顺序特征,将词性标注结果t(x)送入postag embedding层获取每个词的词性特征,最后将这三个结果进行拼接输入到bert模型中得到最终的词嵌入,得到输出隐藏向量集合;
37.词嵌入过程可以表达为如下式:
38.h=bert(x',t(x))={h1,h2,
…
,hn}
ꢀꢀꢀ
(5)
39.其中,h为输出的隐藏向量ⅰ集合,h1,h2,
…
,hn为隐藏向量。
40.进一步的,所述步骤(3)具体实现过程如下:
41.3-1遍历依存树中的任意两个节点,计算这两个节点的最近公共祖先节点,获得以公共祖先节点为根、两个节点为叶的子树d(x);把子树d(x)中所有边信息转换为边向量,得到结果:
42.e={e1,e2,
…
,eq}
ꢀꢀꢀ
(6)
43.其中q表示当前子树中边的总数;
44.3-2将隐藏向量集合h和子树d(x)输入到gin网络中获取节点嵌入信息,其中,gin网络由m层图同构卷积层组,每一层的计算过程如下式:
[0045][0046]
其中,表示节点i在第k层图同构卷积层输出的隐藏向量,在第1层图同构卷积层
中为步骤(2)中bert输出的隐藏向量,ε是一个可学习参数,n(i)表示节点i的所有邻接节点的集合,e(i)表示节点i的所有邻接边的集合,e
p
为对应边的边嵌入,mlp是多层感知机算法;
[0047]
3-3对步骤3-2中得到的最终节点嵌入向量做最大池化处理,获取子树的表征向量:
[0048][0049]
其中,h
child-tree
表示子树的表征向量,表示节点嵌入向量。
[0050]
进一步的,如图4所示,步骤(4)具体实现过程如下:
[0051]
4-1采用注意力机制对表征向量中的有效信息进行增强,将子树表征向量h
child-tree
作为q,bert模型输出的隐藏向量集合{h1,h2,
…
,hn}作为k,gin网络输出的节点嵌入向量作为v,首先利用q和k计算注意力权重wi,详细计算过程如下式:
[0052][0053]
接下来,模型将注意力权重pi应用对应的v中,得到最终节点嵌入向量oi,详细计算过程如下式:
[0054][0055]
进一步的,所述步骤(5)具体实现过程如下:
[0056]
将最终的隐藏向量输入到一个二元分类器中,对每一个词分配一个二进制标签,该标签指示当前词是否为谓词,详细计算过程如下式:
[0057]
pi=σ(woi+b)
ꢀꢀꢀꢀ
(11)
[0058]
其中w和b都是可学习参数,σ是sigmoid函数;
[0059]
训练过程中,损失函数定义为:
[0060]
loss=ce(p,y)
ꢀꢀꢀꢀꢀ
(12)
[0061]
其中p表示对标签的预测结果,y表示真实标签,ce表示交叉熵损失函数。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1