一种文本要素抽取方法及系统与流程
1.本发明涉及深度学习技术领域,特别是涉及一种文本要素抽取方法及系统。
背景技术:
2.随着深度学习的不断发展,当面对超过512个字的长文本,现有技术主要是将长文本进行截断然后输入到传统深度学习模型中,导致传统深度学习模型对长文本内容存在天然的语义不足性。而且,在面对要素抽取任务时,现在技术方案是把文本按照字符级进行标注,以句子级文本作为传统深度学习模型的输入,这使得传统深度学习模型无法充分利用句子的上下文信息,导致传统深度学习模型对要素抽取任务产生一定的偏置,从而存在抽取长文本内容不完整,抽取准确率低的问题。
技术实现要素:
3.鉴于以上所述现有技术的缺点,本发明的目的在于提供一种文本要素抽取方法,用于解决现有技术在进行文本要素抽取时抽取不完整和准确率低的问题。
4.为实现上述目的及其他相关目的,本发明提供一种文本要素抽取方法,包括以下步骤:
5.获取待进行文本要素抽取的目标文本,所述目标文本的字数超过预设值;
6.按照预设业务规则对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本;
7.获取每个段落文本的文本内容;其中,每个段落文本的文本内容包括句子和词;
8.利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;
9.通过卷积神经网络从所述编码结果中聚合每个句子的内部信息,获取每个句子的表征;
10.通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到所述目标文本的要素信息。
11.可选地,所述方法还包括:
12.获取符合业务规则的文本语料;
13.对所述文本语料按照句号进行句子划分,得到多个句子级文本;
14.将所述句子级文本的内容按照预先设定的要素标签进行标注,并将标准后的句子级文本转换为训练语料;
15.根据所述训练语料进行训练,生成所述预训练模型。
16.可选地,预先设定的要素标签包括:甲方名称和乙方名称,其中,所述甲方是指提出目标的一方,所述乙方是指实现所述甲方所提出的目标的另一方。
17.可选地,按照预设业务规则对所述目标文本的文本内容进行段落分割的过程包括:
18.按照换行符对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多
个段落文本。
19.可选地,所述预设值为512。
20.本发明还提供一种文本要素抽取系统,包括有:
21.第一采集模块,用于获取待进行文本要素抽取的目标文本,所述目标文本的字数超过预设值;
22.分割模块,用于按照预设业务规则对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本;
23.编码模块,用于获取每个段落文本的文本内容,并利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;其中,每个段落文本的文本内容包括句子和词;
24.聚合表征模块,用于通过卷积神经网络从所述编码结果中聚合每个句子的内部信息,获取每个句子的表征;
25.要素抽取模块,用于通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到所述目标文本的要素信息。
26.可选地,所述系统还包括:
27.获取符合业务规则的文本语料;
28.对所述文本语料按照句号进行句子划分,得到多个句子级文本;
29.将所述句子级文本的内容按照预先设定的要素标签进行标注,并将标准后的句子级文本转换为训练语料;
30.根据所述训练语料进行训练,生成所述预训练模型。
31.可选地,预先设定的要素标签包括:甲方名称和乙方名称,其中,所述甲方是指提出目标的一方,所述乙方是指实现所述甲方所提出的目标的另一方。
32.可选地,按照预设业务规则对所述目标文本的文本内容进行段落分割的过程包括:
33.按照换行符对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本。
34.可选地,所述预设值为512。
35.如上所述,本发明提供一种文本要素抽取方法及系统,具有以下有益效果:
36.本发明首先获取待进行文本要素抽取的目标文本,目标文本的字数超过预设值;按照预设业务规则对目标文本的文本内容进行段落分割,将目标文本拆分为多个段落文本;获取每个段落文本的文本内容;其中,每个段落文本的文本内容包括句子和词;利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;通过卷积神经网络从编码结果中聚合每个句子的内部信息,获取每个句子的表征;通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到目标文本的要素信息。由此可知,本发明提出了基于长文本预训练模型段落级的要素抽取方案,不仅能够解决传统模型输入长度的限制和无法充分利用上下文信息,而且还能够以90%的准确率抽取出长文本要素信息。本发明采用段落级文本内容作为模型输入,使得面对长文本内容能够以较高准确率抽出长文本要素信息。
附图说明
37.图1为一实施例提供的文本要素抽取方法的流程示意图;
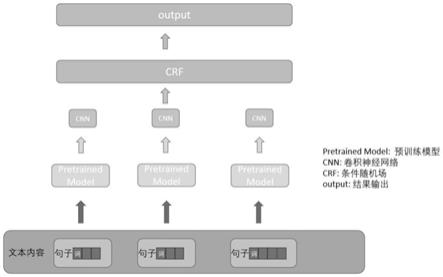
38.图2为一实施例提供的文本要素抽取模型的结构示意图;
39.图3为一实施例提供的文本要素抽取系统的硬件结构示意图。
具体实施方式
40.以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
41.需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
42.请参阅图1,本发明提供一种文本要素抽取方法,包括以下步骤:
43.s100,获取待进行文本要素抽取的目标文本,所述目标文本的字数超过预设值。作为示例,本实施例中的预设值为512。
44.s200,按照预设业务规则对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本。作为示例,按照预设业务规则对所述目标文本的文本内容进行段落分割的过程包括:按照换行符对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本。在本实施例中的业务规则可以预先根据业务需求进行设定。
45.s300,获取每个段落文本的文本内容;其中,每个段落文本的文本内容包括句子和词;
46.s400,利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果。作为示例,本实施例中预训练模型的训练生成过程包括:获取符合业务规则的文本语料;对所述文本语料按照句号进行句子划分,得到多个句子级文本;将所述句子级文本的内容按照预先设定的要素标签进行标注,并将标准后的句子级文本转换为训练语料;根据所述训练语料进行训练,生成所述预训练模型。其中,本实施例中预先设定的要素标签包括:甲方名称和乙方名称,其中,所述甲方是指提出目标的一方,所述乙方是指实现所述甲方所提出的目标的另一方。
47.s500,通过卷积神经网络从所述编码结果中聚合每个句子的内部信息,获取每个句子的表征;
48.s600,通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到所述目标文本的要素信息。
49.在一示例性实施例中,如图2所示,本实施例将一篇文本建模为batch_size*batch_paragraph_num*max_len三维矩阵;其中,batch_size表示批次大小,batch_paragraph_num表示一个篇章的段落数量,max_len表示每段长度。为了把段落内部信息的聚合并且符合预训练模输入的格式,本实施例将上述三维矩阵转为二维矩阵paragraph_
num*max_len;其中,paragraph_num表示所有的段落数量,再将二维矩阵输入到预训练模型中,得到对应的三维矩阵paragraph_num*max_len*hidden_size;其中,hidden_size表示隐层维度。再通过卷积神经网络,利用不同大小的卷积核将最后两个维度进行聚合,得到基于上下文的段落信息。最后将二维矩阵重新转为三维矩阵batch_size*batch_paragraph_num*aggregate_num;其中,aggregate_num表示聚合信息后的维度。最后将生成的三维矩阵输入到全连接层和条件随机场中,得到每个段落的要素信息。
50.综上所述,本发明提供一种文本要素抽取方法,首先获取待进行文本要素抽取的目标文本,目标文本的字数超过预设值;按照预设业务规则对目标文本的文本内容进行段落分割,将目标文本拆分为多个段落文本;获取每个段落文本的文本内容;其中,每个段落文本的文本内容包括句子和词;利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;通过卷积神经网络从编码结果中聚合每个句子的内部信息,获取每个句子的表征;通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到目标文本的要素信息。本方法首先从业务方得到相关语料,然后将文本按照句号进行句子划分得到句子级文本,再根据业务需求预先设定要素标签如:“甲方名称”、“乙方名称”等,将文本按照上述预先设定的标签进行标注,并通过代码转为可训练的语料。其中,标注语料是为了让模型学习相关文本内容知识,以便抽取出不同类型的要素信息。由此可知,本方法提出了基于长文本预训练模型段落级的要素抽取方案,不仅能够解决传统模型输入长度的限制和无法充分利用上下文信息,而且还能够以90%的准确率抽取出长文本要素信息。本方法采用段落级文本内容作为模型输入,使得面对长文本内容能够以较高准确率抽出长文本要素信息。
51.如图3所示,本发明还提供一种文本要素抽取系统,包括有:
52.第一采集模块m10,用于获取待进行文本要素抽取的目标文本,所述目标文本的字数超过预设值。作为示例,本实施例中的预设值为512。
53.分割模块m20,用于按照预设业务规则对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本。作为示例,按照预设业务规则对所述目标文本的文本内容进行段落分割的过程包括:按照换行符对所述目标文本的文本内容进行段落分割,将所述目标文本拆分为多个段落文本。在本实施例中的业务规则可以预先根据业务需求进行设定。
54.编码模块m30,用于获取每个段落文本的文本内容,并利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;其中,每个段落文本的文本内容包括句子和词。作为示例,本实施例中预训练模型的训练生成过程包括:获取符合业务规则的文本语料;对所述文本语料按照句号进行句子划分,得到多个句子级文本;将所述句子级文本的内容按照预先设定的要素标签进行标注,并将标准后的句子级文本转换为训练语料;根据所述训练语料进行训练,生成所述预训练模型。其中,本实施例中预先设定的要素标签包括:甲方名称和乙方名称,其中,所述甲方是指提出目标的一方,所述乙方是指实现所述甲方所提出的目标的另一方。
55.聚合表征模块m40,用于通过卷积神经网络从所述编码结果中聚合每个句子的内部信息,获取每个句子的表征。
56.要素抽取模块m50,用于通过条件随机场从每个句子的表征中获取对应句子的上
下文信息,得到所述目标文本的要素信息。
57.在一示例性实施例中,本实施例将一篇文本建模为batch_size*batch_paragraph_num*max_len三维矩阵;其中,batch_size表示批次大小,batch_paragraph_num表示一个篇章的段落数量,max_len表示每段长度。为了把段落内部信息的聚合并且符合预训练模输入的格式,本实施例将上述三维矩阵转为二维矩阵paragraph_num*max_len;其中,paragraph_num表示所有的段落数量,再将二维矩阵输入到预训练模型中,得到对应的三维矩阵paragraph_num*max_len*hidden_size;其中,hidden_size表示隐层维度。再通过卷积神经网络,利用不同大小的卷积核将最后两个维度进行聚合,得到基于上下文的段落信息。最后将二维矩阵重新转为三维矩阵batch_size*batch_paragraph_num*aggregate_num;其中,aggregate_num表示聚合信息后的维度。最后将生成的三维矩阵输入到全连接层和条件随机场中,得到每个段落的要素信息。
58.综上所述,本发明提供一种文本要素抽取系统,首先获取待进行文本要素抽取的目标文本,目标文本的字数超过预设值;按照预设业务规则对目标文本的文本内容进行段落分割,将目标文本拆分为多个段落文本;获取每个段落文本的文本内容;其中,每个段落文本的文本内容包括句子和词;利用预训练模型对每个段落文本中的句子进行编码,得到对应的编码结果;通过卷积神经网络从编码结果中聚合每个句子的内部信息,获取每个句子的表征;通过条件随机场从每个句子的表征中获取对应句子的上下文信息,得到目标文本的要素信息。本系统首先从业务方得到相关语料,然后将文本按照句号进行句子划分得到句子级文本,再根据业务需求预先设定要素标签如:“甲方名称”、“乙方名称”等,将文本按照上述预先设定的标签进行标注,并通过代码转为可训练的语料。其中,标注语料是为了让模型学习相关文本内容知识,以便抽取出不同类型的要素信息。由此可知,本系统提出了基于长文本预训练模型段落级的要素抽取方案,不仅能够解决传统模型输入长度的限制和无法充分利用上下文信息,而且还能够以90%的准确率抽取出长文本要素信息。本系统采用段落级文本内容作为模型输入,使得面对长文本内容能够以较高准确率抽出长文本要素信息。
59.上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1