一种基于多模态信息学习的专家推荐方法
1.本发明属于数据处理技术领域,特别是涉及一种基于多模态信息学习的专家推荐方法。
背景技术:
2.随着科技的发展等方面大力推进理论创新,各类创新性的项目申请量大幅度增加,进而导致科技项目申请不断增多。其中,在科研项目立项、结项等阶段,存在一个关键步骤——评审专家推荐。评审专家推荐即根据科研项目文档,推荐相关领域的专家进行项目评审,以评估项目的实际意义、可行性及完成质量。这就要求审核专家掌握的技术、擅长的领域与申请书内容相匹配,才能得到较为准确的评审结果。因此,如何准确地检索遴选并推荐出与项目相匹配的评审专家,如何“选好专家、用好专家”变得十分重要和关键。
3.在科研项目申报过程中,当前多采用人工方式进行评审专家遴选,由于人工对领域知识的理解有限,且具有一定的主观性倾向,项目申报数量的增加,专家库信息量庞大,传统的关键词检索与推荐技术存在机械匹配字词、检索与推荐的查全率和查准率偏低的问题,从而造成许多专家所分配到的项目与自己的研究方向毫不相关的问题;同时,仅凭项目管理人员的主观意识判断推荐评审专家是否符合评审标准,导致管理人员的工作量庞大,并且极易导致专家与项目不匹配的情况发生。
4.现有的专家推荐系统,如基于项目研究内容和评审专家研究方向的算法,其通过提取关键词计算文本特征向量的相似度,从而忽略了相关其他信息。然而实际中科研项目与评审专家的选择往往涉及到其他因素,如专家的个人属性等。同时,当新的专家出现时,往往存在专家信息不全的问题,模型无法学习到专家的有效表示,需要评审的项目出现时很难对该专家进行推荐,导致推荐准确率低的问题。
技术实现要素:
5.为了解决上述问题,本发明提出了一种基于多模态信息学习的专家推荐方法,利用爬取的专家数据、项目数据及现有专家库数据,通过多任务学习执行各种自我监督的预训练任务,将丰富的语义和属性信息充分融入到专家的嵌入和模型参数中,提升专家推荐的准确率。
6.为达到上述目的,本发明采用的技术方案是:一种基于多模态信息学习的专家推荐方法,包括步骤:
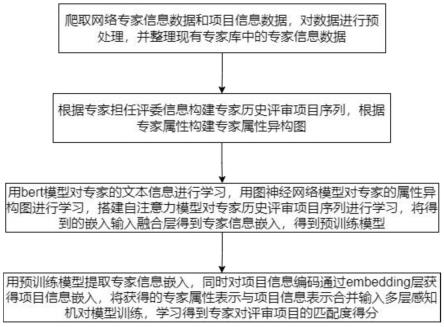
7.s10,爬取网络专家信息数据和项目信息数据,对数据进行预处理,并整理现有专家库中的专家信息数据;
8.s20,根据专家担任评委信息构建专家历史评审项目序列,根据专家属性构建专家属性异构图;
9.s30,用bert模型对专家的文本信息进行学习,用图神经网络模型对专家的属性异构图进行学习,搭建自注意力推荐模型对专家历史评审项目序列进行学习,将得到的嵌入
输入融合层得到专家信息嵌入,得到预训练模型;
10.s40,用预训练模型提取专家信息嵌入,同时对项目信息编码通过embedding层获得项目信息嵌入,将获得的专家属性表示与项目信息表示合并输入多层感知机对模型训练,学习得到专家对评审项目的匹配度得分。
11.进一步的是,在所述步骤s10中,包括:
12.爬取网络专家信息数据,包括专家文本信息;爬取网络中的项目信息数据;对爬取的数据进行预处理;
13.整理现有专家库中的数据,包括专家的姓名、职位、研究领域、工作单位属性信息和评审活动信息。
14.进一步的是,在所述步骤s20中,包括:
15.以时间顺序对专家参与评审项目构建历史评审项目序列;
16.以专家姓名、职位、研究领域和工作单位为节点,以节点间相关关系为边构建专家属性异构图。
17.进一步的是,在所述步骤s30中,包括:
18.将专家文本信息包括文章和个人简介输入bert模型,通过执行遮蔽语言预测任务,对bert模型进行预训练,获得专家文本嵌入;
19.在专家属性异构图上,执行对比预训练任务,预训练用于学习专家属性的图神经网络,获得专家属性嵌入;
20.将专家历史评审序列输入搭建的自注意力推荐模型,执行下一个项目预测任务,对专家历史评审项目序列进行学习,获得专家均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入;
21.将提取不同嵌入进行融合获得专家信息嵌入。
22.进一步的是,将专家文本信息包括文章和个人简介输入bert模型,通过执行遮蔽语言预测任务,对bert模型进行训练,获得专家文本嵌入,包括步骤:
23.s311,通过嵌入矩阵将文本信息中的字转化为词嵌入,为每个字添加相应的段嵌入和位置嵌入,作为bert模型的输入;
24.s312,在遮蔽语言预测任务中,选择与专家研究领域相关的词进行屏蔽和重构;
25.s313,遮蔽语言预测任务损失被定义为交叉熵损失。
26.进一步的是,在专家属性异构图上进行对比预训练任务,训练用于学习专家属性的图神经网络,获得专家属性嵌入,包括步骤:
27.s321,执行关系级预训练任务,对于给定的正例三元组,为其构造不一致关系和不相关节点的负样例队列进行对比学习任务;
28.s322,执行子图级预训练任务,在异构图上生成元图实例来构建正样本,同时生成排队的负样本,并通过对比学习区分正负样本;
29.进一步的是,将专家历史评审序列输入搭建自注意力推荐模型,执行下一个项目预测任务,对专家历史评审项目序列进行学习,获得专家均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入,包括步骤:
30.s331,自注意力推荐模型,他包括随机嵌入、wasserstein自注意力层和bpr loss中的正则化项;
31.s332,在随机嵌入层,通过将项目表示为多维椭圆高斯分布。椭圆高斯分布由均值向量和协方差向量控制。对于所有项目,定义一个均值嵌入表m
μ
∈r
|v|*d
和协方差嵌入表m
∑
∈r
|v|*d
。同时分别为均值嵌入和协方差嵌入引入单独的位置嵌入p
μ
∈r
|v|*d
和p
∑
∈r
|v|*d
由此,得到序列的包括均值(用于基本兴趣)嵌入和协方差(用于兴趣的可变性)嵌入嵌入:
[0032][0033][0034]
s333,在wasserstein自注意力层,给定物品sk和st,对应的随机嵌入分别为d维椭圆高斯分布其中:
[0035][0035][0035]
为可训练矩阵;
[0036]
同时,引入wasserstein距离作为注意力权重来衡量序列中项目之间的成对关系,并采用高斯分布的线性组合特性来聚合历史项目并获得序列表示;
[0037]
s334,将序列表示输入到前馈神经网络中,应用两个带有elu激活的逐点全连接层来在学习随机嵌入中引入非线性,并采用了残差连接、层归一化和dropout层,层输出为物品的均值嵌入和协方差嵌入;
[0038]
s335,执行下一个项目预测任务,预测分数为物品间的wasserstein距离,并使用正则化项提升正负样本间的距离,损失被定义为brp损失,对自注意力推荐模型预训练。
[0039]
进一步的是,将提取不同嵌入进行融合获得专家信息属性,包括:
[0040]
将预训练模型提取的专家文本嵌入、专家评审嵌入和专家属性嵌入输入融合层,获得专家信息嵌入:
[0041]
u'=ln(awa+www+z
μwμ
+z
σwσ
),
[0042]
u=ln(u'+ffn(u'));
[0043]
其中,a代表专家属性嵌入,w代表专家文本嵌入,z
μ
代表专家评审序列的均值嵌入,z
σ
代表专家评审序列的协方差嵌入;wa,ww,w
μ
,w
∑
为可训练矩阵,u为专家的信息嵌入。
[0044]
进一步的是,在所述步骤s40中,包括步骤:
[0045]
s41,用预训练模型提取新专家信息嵌入;
[0046]
s42,对项目信息进行编码,经过映射后获得项目的信息嵌入;
[0047]
s43,根据提取的新专家信息嵌入嵌入与项目的嵌入进行融合,输入多层感知机,根据历史的专家评审信息对多层感知机进行训练;
[0048]
最后,得到专家与项目的推荐分数对专家进行推荐。
[0049]
采用本技术方案的有益效果:
[0050]
本发明爬取网络专家信息数据,项目信息,对数据进行预处理,并整理现有专家库中的专家信息数据。将收集到专家的文本信息如论文等输入bert模型进行学习,将收集到属性特征构建属性异构图,用图神经网络模型学习其属性特征,将专家的评审信息建模为
历史评审序列,并搭建自注意力推荐模型学习其评审特征,将不同的特征进行融合,获得专家的信息特征,并对模型进行与训练。在推荐任务中,将预训练好的模型及参数应用于专家信息嵌入嵌入的提取并进行微调,并用提取的专家信息嵌入嵌入及项目信息嵌入训练多层感知机,学习专家与项目的推荐分数。本发明通过多任务学习执行各种自我监督的预训练任务,将丰富的语义、属性信息和评审信息充分融入到专家的嵌入和模型参数中,提升专家推荐的准确率。
[0051]
本发明为处理专家的历史评审序列信息,搭建自注意力推荐模型。他包括随机嵌入、wasserstein自注意力层和bpr loss中的正则化项。将项目建模为具有随机嵌入的高斯分布,包括均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入。在随机嵌入之上,使用距离来测量项目转换,这源于度量学习。提出了一个新颖的wasserstein自注意力层,它将注意力测量为项目之间的缩放wasserstein距离。还在预训练过程中中引入了一个新的正则化术语,以考虑正样本和负样本项目之间的距离以考虑sr中的协作传递性的工作引入随机嵌入来测量用户行为中固有的基本兴趣和兴趣的可变性,并通过额外的正则化来限制正样本和负样本项目之间的距离,提升了推荐效果。
[0052]
本发明提出的专家推荐方法,专注与学习专家的嵌入。为了有效利用专家的各种结构和非结构信息,挖掘潜在的专家信息,将专家属性和专家评审信息建模为专家属性图和专家历史评审序列,将专家的文本信息输入bert模型,提取专家的文本表征,将专家的属性图输入图神经网络模型提取专家的属性表征,将专家历史评审序列输入搭建的自注意力推荐模型学习专家评审表征,将学习到的表征进行融合,得到专家的信息表示,从而的将专家的各种信息融入到了专家的信息表征中,从而获得了更多的知识,因此推荐效果得以提升。
[0053]
本发明为了学习专家的文本信息,属性信息,评审信息,采用了预训练模型对专家的特征进行学习。该模型结合了bert模型、图神经网络模型和自注意力推荐模型。将专家的文本信息输入到bert模型,将专家的属性图输入到图神经网络模型,将专家的历史评审序列输入到自注意力推荐模型,通过执行多任务学习执行各种自我监督的预训练任务,将丰富的语义和属性信息充分融入到专家的嵌入和模型参数中,用训练好的模型提取专家信息嵌入并融合,得到专家的信息特征,提升推荐效果。
附图说明
[0054]
图1为本发明的一种基于多模态信息学习的专家推荐方法流程示意图;
[0055]
图2为本发明实施例中一种基于多模态信息学习的专家推荐方法的原理框架示意图;
[0056]
图3为本发明实施例中搭建的自注意力推荐模型示意图。
具体实施方式
[0057]
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
[0058]
在本实施例中,参见图1和图2所示,本发明提出了一种基于多模态信息学习的专家推荐方法,包括步骤:
[0059]
s10,爬取网络专家信息数据和项目信息数据,对数据进行预处理,并整理现有专家库中的专家信息数据;
[0060]
s20,根据专家担任评委信息构建专家历史评审项目序列,根据专家属性构建专家属性异构图;
[0061]
s30,用bert模型对专家的文本信息进行学习,用图神经网络模型对专家的属性异构图进行学习,搭建自注意力推荐模型对专家历史评审项目序列进行学习,将得到的嵌入输入融合层得到专家信息嵌入,得到预训练模型;
[0062]
s40,用预训练模型提取专家信息嵌入,同时对项目信息编码通过embedding层获得项目信息嵌入,将获得的专家属性表示与项目信息表示合并输入多层感知机对模型训练,学习得到专家对评审项目的匹配度得分。
[0063]
作为上述实施例的优化方案:
[0064]
专家信息数据包括专家的文章等文本信息,项目信息数据包括项目的文档等描述信息,专家库中包括专家属性信息和历史评审信息。在实际运用中,由于存在数据稀疏的问题,无法很好的得到专家嵌入,所以对专家属性信息、评审信息搭建异构图,采用预训练的方式,对专家信息进行学习,更好的提取专家信息嵌入,将学到的知识用于现有推荐系统。
[0065]
通过爬取网络专家信息数据,包括专家文本信息;爬取网络中的项目信息数据;对爬取的数据进行预处理;
[0066]
同时,整理现有专家库中的数据,包括专家的姓名、职位、研究领域、工作单位属性信息和评审活动信息。
[0067]
作为上述实施例的优化方案:所述构建专家属性异构图和专家历史评审序列,包括:
[0068]
以时间顺序对专家参与评审项目构建历史评审项目序列;
[0069]
以专家姓名、职位、研究领域和工作单位为节点,以节点间相关关系为边构建专家属性异构图。
[0070]
作为上述实施例的优化方案,用bert模型和图神经网络模型对专家的各种信息进行学习,包括:
[0071]
将专家文本信息包括文章和个人简介输入bert模型,通过执行遮蔽语言预测任务,对bert模型进行训练,获得专家文本嵌入;
[0072]
在专家属性异构图上,在专家属性异构图上进行对比预训练任务,训练用于学习专家评审项目的图神经网络,获得专家评审嵌入;
[0073]
将专家历史评审序列输入搭建的自注意力推荐模型,执行下一个项目预测任务,对专家历史评审项目序列进行学习,获得专家均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入;
[0074]
将提取不同嵌入进行融合获得专家信息属性。
[0075]
其中,将专家文本信息包括文章和个人简介输入bert模型,通过执行遮蔽语言预测任务,对bert模型进行训练,获得专家文本嵌入,包括步骤:
[0076]
s311,通过嵌入矩阵将文本信息中的字转化为词嵌入,为每个字添加相应的段嵌入和位置嵌入,作为bert模型的输入;
[0077]
s312,在遮蔽语言预测任务中,选择与专家研究领域相关的词进行屏蔽和重构;
[0078]
s313,遮蔽语言预测任务损失被定义为交叉熵损失:
[0079][0080]
其中,sm是被屏蔽位置的集合,和wj是预测词和原始词。
[0081]
其中,在专家属性异构图上进行对比预训练任务,训练用于学习专家属性的图神经网络,获得专家属性嵌入,包括步骤:
[0082]
s321,执行关系级预训练任务,对于图中给定的正例三元组<u,r,v>∈p
rel
,为其构造不一致关系负样例<u,r-,w>构成的队列和不相关节点<u,*,v->的负样例队列进行对比学习任务。
[0083]
s322,执行子图级预训练任务,对于给定的一个元图m∈m和源节点u,构建一个元图实例m∈i(m)作为节点u的符合元图m的集合,其中i(m)表示为元图m所有实例的集合。训练过程中先基于之前的正样本,本文通过添加最近的阳性样本并移除最早队列尾端来生成负样本,进行对比训练任务。
[0084]
其中,将专家历史评审序列输入搭建的自注意力推荐模型如图3所示,执行下一个项目预测任务,对专家历史评审项目序列进行学习,获得专家均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入,包括步骤:
[0085]
s331,自注意力推荐模型,他包括随机嵌入、wasserstein自注意力层和bpr loss中的正则化项;
[0086]
s332,在随机嵌入层,通过将项目表示为多维椭圆高斯分布;椭圆高斯分布由均值向量和协方差向量控制;对于所有项目,定义一个均值嵌入表m
μ
∈r
|v|*d
和协方差嵌入表m
∑
∈r
|v|*d
;同时分别为均值嵌入和协方差嵌入引入单独的位置嵌入p
μ
∈r
|v|*d
和p
∑
∈r
|v|*d
;由此,得到包括均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入:
[0087][0088][0089]
s333,在wasserstein自注意力层,给定物品sk和st,对应的随机嵌入分别为d维椭圆高斯分布其中:
[0090][0090][0090]
为可训练矩阵。
[0091]
引入wasserstein距离作为注意力权重来衡量序列中项目之间的成对关系,并且采用高斯分布的线性组合特性来聚合历史项目并获得序列表示。
[0092]
物品sk与st间权重a定义为负的2-wasserstein距离w2,测量为:
[0093][0094]
序列每个位置的项目的输出嵌入是来自先前步骤的嵌入的加权和,其中权重是归一化的注意力值
[0095][0096]
每个项目都表示为具有均值和协方差的随机嵌入,采用高斯分布的线性组合特性对项目聚合,如下:
[0097][0098]
其中,w为可训练矩阵。
[0099]
输出为序列的随机嵌入:
[0100]
s334,在前馈神经网络中,应用两个带有elu激活的逐点全连接层来在学习随机嵌入中引入非线性。并采用了残差连接、层归一化和dropout层,层输出为项目的均值嵌入和协方差嵌入;
[0101]
s335,执行下一个项目预测任务,预测分数为物品间的wasserstein距离,并使用正则化项提升正负样本间的距离,对自注意力推荐模型预训练,损失被定义为brp损失:
[0102][0103]
其中[x]+=max(x,0)是标准铰链损失,j
+
为真实的下一个项目,j-为随机选取负样本。
[0104]
作为上述实施例的优化方案,将提取不同嵌入进行融合获得专家信息属性,包括:
[0105]
将预训练模型提取的专家文本嵌入、获得专家均值(用于基本兴趣)和协方差(用于兴趣的可变性)嵌入,和专家属性嵌入输入融合层,获得专家信息嵌入:
[0106]
u'=ln(awa+www+z
μwμ
+z
σwσ
),
[0107]
u=ln(u'+ffn(u'));
[0108]
其中,a代表专家属性嵌入,w代表专家文本嵌入,z
μ
代表专家评审序列的均值嵌入,z
σ
代表专家评审的序列的协方差嵌入;wa,ww,w
μ
,w
∑
为可训练矩阵,u为专家的信息嵌入;
[0109]
根据专家信息嵌入嵌入,对专家评分进行预测,学习专家的信息嵌入更好的表示,预测分数为r'=wu+b,w、b为可训练参数,损失函数定义为:
[0110][0111]
作为上述实施例的优化方案,用预训练模型提取专家信息嵌入,同时对项目信息编码获得项目信息嵌入,将获得的专家属性表示与项目信息表示输入多层感知机(mlp)对模型训练,得到专家与项目的推荐分数,包括步骤:
[0112]
s41,用预训练模型提取新专家信息嵌入;
[0113]
s42,对项目信息进行编码,经过映射后获得项目的信息嵌入;
[0114]
s43,根据提取的新专家信息嵌入嵌入与项目的嵌入进行融合,输入多层感知机,根据历史的专家评审信息对多层感知机进行训练,损失函数为:
[0115][0116]
最后,得到专家与项目的推荐分数对专家进行推荐。
[0117]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1