一种面向长尾目标检测的分类对数归一化方法
1.本发明属于计算机软件技术领域,涉及长尾目标检测技术,具体为一种面向长尾目标检测的分类对数归一化方法。
背景技术:
2.在实际的视觉相关问题中,手工收集的大型数据集,在物体检测任务上取得了成功。然而,与来自现实场景的数据相比,它们往往是相对平衡的,因为现实场景往往呈现出长尾的偏斜分布,即少量类别占据绝大多数样本,大量的类别仅有少量的样本。在这个意义上,少数头部类(频繁类)占主导地位,但大量的尾部类(稀有类)被掩盖了。这种标签分布的变化给深度物体检测器带来了相当大的挑战,也就是由训练集训练的目标检测器在实际场景应用中效果下降,同时也促使了解决这个问题的各种技术。最直观的方法,重新取样,但该技术不仅导致了更高的训练复杂性,而且还造成了头部类的欠拟合和尾部类的过拟合问题。现有技术中更多的方法关注于通过在训练中修改分类器输出的logit,即分类对数,对训练目标进行重新加权,或调整分类对数与类的先验,例如标签频率。然而,这些理论上最佳的logit调整往往不能很好地适应目标检测器。同时,在目标检测中,还有一个极端的头部类别,即背景类,会严重偏离前景类别的分类,也会给目标检测带来长尾分布的问题。最近的一些研究方法试图用统计学的方法来动态地适应长尾分布,但它们通常表现为有很多参数的复杂形式。此外,这些方法中仍然缺乏对背景类别的适当处理。
技术实现要素:
3.本发明要解决的问题是:(1)大部分长尾学习方法着重于数据集先验的应用,他们通常将标签频率注入到分类的logit中,因此不能适应配备了各种采样器的目标检测器内部的重新采样的训练标签分布。同时缺少良好的对背景logit的校准。(2)最近的一些研究方法提出利用统计量适应检测器内的动态分布,尽管取得了良好的性能,但它们中的大多数在形式上都很复杂,而且参数化程度过高。
4.本发明的技术方案为:一种面向长尾目标检测的分类对数归一化方法,目标检测中,对分类器的预测分布使用归一化的方式执行矫正,具体为利用分类器已有的分类输出的分类对数计算统计量,来归一化分类网络最终激活值,自我纠正有偏差的预测结果。
5.进一步的,检测目标长尾分布。
6.进一步的,检测任务为对检测目标的分类任务,在构建分类网络并训练后,在测试阶段,测试集数据长尾分布,对于分类器输出的每批c维分类对数向量x∈rc,执行如下的归一化:
[0007][0008]
其中μ(x),σ(x)∈rc表示在训练样本的向量上计算得到的均值和标准差,ε为稳定参数,用于维护标准差的数值稳定性;
[0009]
归一化操作为:首先遍历所有训练样本,通过指数滑动平均从训练集的批量分类统计量中累积全局统计量,得到μ(x)和σ(x),从而获得分类器在每个类别上的预测偏见的近似;分类对数向量x被归一化为后,应用一个arg max函数来获得相应分类标签的近似值,作为分类器的最终预测结果。
[0010]
进一步的,检测任务为对检测目标的分类和定位任务,目标检测网络对应具有分类分支和定位分支,在构建目标检测网络并训练后的测试过程中,测试集数据长尾分布,对于分类分支输出的每批(c+1)维分类对数向量每个向量都包含c个前景类和一个背景类的分类对数,执行如下形式的归一化:
[0011][0012]
其中x∈rc表示分类对数向量的前景子向量;μ(x),σ(x)∈rc表示在训练样本的前景子向量上计算得到的均值和标准差,ε为稳定参数,用于维护标准差的数值稳定性,β∈r是考虑到前景背景样本的悬殊比例,而为前景向量设置的背景校准标量,设置为前景向量的最小值;
[0013]
归一化操作为:通过指数滑动平均从训练集的分类批量统计量中累积全局统计量,逐步聚合每个批训练样本上预测的分类对数的统计量,得到μ(x)和σ(x),从而获得分类分支在每个类别上的预测偏见的近似,在分类对数向量的前景子向量x被归一化为后,分类分支应用一个arg max函数来获得相应标签的近似值,以作为分类分支的预测结果,与定位分支的结果结合,输出目标的类别和位置。
[0014]
本发明的分类对数归一化方法logn,在形式上接近常见的归一化方法,这保证了通用性,即通过在训练后分类器输出的分类对数上执行归一化,本发明方法能够被广泛便捷地、即插即用地移植到任何检测器和数据分布之上,并且无需任何训练和调节过程。但是,和现有常见的归一化方法不同的是,现有技术通常使用特征统计量来归一化分类网络的中间激活值,从而加速网络的训练;而本发明的方法则是利用在网络输出的分类对数上计算的统计量,来归一化分类网络的最终激活值,从而改善分类网络在长尾分布上的学习。此外,现有技术通常同时在训练和测试阶段执行归一化,这是因为两阶段的输入数据分布是一致的;而本发明的方法不参与网络训练,直接在训练好的网络上进行,例如仅在测试阶段执行,或在实际场景检测时执行,能够应对实际检测目标和训练样本在输入数据的标签分布上的不一致性。最后,本发明logn并没有现有常规归一化方法中的仿射变换过程,这是因为在常规的长尾设置中,测试集合通常保持均匀的标签分布,而logn归一化后的测试数据在标签分布通常也是均匀的,无需再向特定分布迁移变换。
[0015]
本发明提出了一种分类对数归一化方法来对长尾分布下的目标检测器的分类输出执行自我矫正。本发明即插即用,仅需要在训练好的模型中对分类器使用,即可解决检测数据长尾分布的问题,同时如果检测数据不存在长尾问题,也不影响目标检测结果。本发明同时在长尾目标检测和分类任务上展现了有效性和通用性,本发明方法无需训练或调节网络参数,即不需要额外的训练、调参过程,同网络模型和分布无关,对不同种类的检测器和训练集具有通用性。
[0016]
本发明与现有技术相比有如下优点
[0017]
本发明方法用训练后计算的统计数据对logit进行归一化,能够动态地适应这种改变的标签分布。此外,类似批归一化的表述使得本发明方法成为一种自我校准方法,因此也比部分基于先验的方法灵活。最后,本发明方法还对背景logit进行了校准,为其提供了一个自适应的调整,从而避开了对背景logit校准的调整。此外,本发明方法在分类的logit上执行后验的批归一化,无需任何训练或调整程序就能自我纠正有偏差的检测结果。
附图说明
[0018]
图1是本发明在目标检测任务上实现的伪代码。
[0019]
图2展示本发明在lvis 1.0数据集样例上和现有工作比较的结果。
[0020]
图3展示本发明在imagenet-lt数据集样例上和现有工作比较的结果。
[0021]
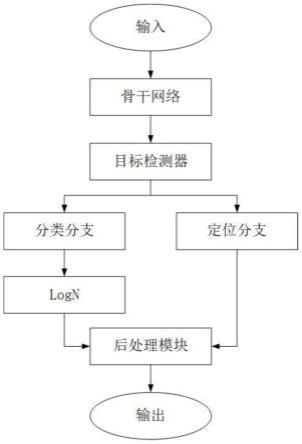
图4为本发明的在长尾目标检测任务上总体流程示意图。
[0022]
图5为本发明的在长尾图像分类任务上总体流程示意图。
具体实施方式
[0023]
对于目标检测,待测图像中往往有很多物体,目标检测目的是判断出物体出现的位置与类别,通常的阶段包括特征提取和分类器分类及目标定位,图4图5中所示的骨干网络用于特征提取,通过目标检测器确定物体目标,分类分支/分类器对物体分类,定位分支确定物体位置,分类分支和定位分支的结果叠加,最后输出待测图像中检测的物体及其位置。
[0024]
本发明提出的面向长尾目标检测的分类对数归一化方法,无需训练或调节,同目标检测模型和训练数据分布无关,即插即用,仅需要在测试阶段使用。更重要的是,它同时在长尾目标检测和长尾分类任务上展现了有效性和通用性。本发明方法能够同时应用于目标检测和一般分类任务中,下面分别说明目标检测任务设计、分类任务设计,以及在目标检测任务和分类任务上的执行阶段设计。
[0025]
1)目标检测任务设计:长尾目标检测任务的流程如图4所示,在构建目标检测网络并训练后的测试过程中,或实际检测中,对于输出的每批(c+1)维分类对数向量每个向量都包含c个前景类和一个背景类的分类对数,n表示批大小,执行如下形式的归一化:
[0026][0027]
其中x∈rc表示输出分类对数向量的前景子向量;μ(x),σ(x)∈rc表示在训练样本的前景子向量上计算得到的均值和标准差,在实践中首先遍历所有训练样本,并和批归一化类似,使用指数滑动平均来逐步聚合在已有目标检测器在每个批训练样本上预测分类对数上计算的统计量,从而以鲁棒高效的方式获得长尾检测器在每个类别上的预测偏见的近似;ε为稳定参数,用于维护标准差的数值稳定性;β∈r是考虑到前景背景样本的悬殊比例因而为前景向量设置的背景校准标量,在实践中被设置为前景向量的最小值。在输出分类对数向量的前景子向量x被归一化为后,网络应用一个arg max函数来获得相应标签的近似值,以作为分类分支的预测结果输出。
[0028]
2)分类任务设计:分类任务的网络流程如图5所示,在构建分类网络并训练后的测试过程中,或实际检测中,对于分类器输出的每批c维分类对数向量x∈rc,执行如下的归一化:
[0029][0030]
归一化后,应用一个arg max函数来获得相应标签的近似值,以作为分类网络的预测结果输出。由于一般分类任务仅预测前景类别,因此不再执行背景校准,并且归一化和arg max过程在均全部分类对数向量上顺序执行。
[0031]
3)执行阶段设计:如图1所示,本发明方法首先遍历训练数据,使用指数滑动平均(ema)的方法,来逐步聚合目标检测器在每个批样本上预测的分类对数向量上计算的统计量,最终得到每个类别包含的所有样本预测结果的统计量,即均值、方差,作为现有长尾目标检测器在每个类别上的预测偏见的近似;在获得全局的训练样本的前景类别的分类对数统计量后,首先将均值向量中每个元素均减去全局最小值,以实现自适应的背景校准;最后在预测过程中,遍历测试数据,对于每个批次的预测样本,目标检测器的分类分支首先给出预测分类对数输出,而后执行1)中的中提出的归一化操作,并将归一化后的分类对数向量提交用于预测。对于分类任务的执行,除了不再执行背景校准,其他与目标检测任务相同。
[0032]
所使用的测试指标在不同任务的数据集上不同:在长尾目标检测任务上,ap(average precision)被作为评估指标,其定义为预测正确的样本数占所有预测为真值的样本数的比例。特别是,所有的类别根据它们在训练集中出现的图像数量分为三组:罕见(1-10张)、常见(11-100张)和频繁(》100张)。因此,为了评估算法在每个组的效果,除了常用的指标apb(目标检测平均精准率)和ap(实例分割平均精准率)之外,还报告了细粒度的指标,包括apr(稀有类别目标检测平均精准率)、apc(常见类别目标检测平均精准率)和apf(频繁类别目标检测平均精准率)。在长尾图像分类任务上,准确率被作为评估指标。
[0033]
如图2所示,本发明可以适用于各种目标检测器,在lvis 1.0数据集上,当使用cascade mask r-cnn r101作为目标检测器并使用rfs均衡采样时,本发明方法的平均准确率有33.8%,比最优方法高1.0%。当mask r-cnn r101作为目标检测器并使用rfs均衡采样时,本发明方法的平均准确率有29.8%,比最优方法高0.8%。当使用cascade mask r-cnn r101作为目标检测器并使用随机采样时,本发明方法的平均准确率有33.5%,比最优方法高0.8%。当mask r-cnn r101作为目标检测器并使用随机采样时,本发明方法的平均准确率有28.4%,比最优方法高0.5%。
[0034]
为了显示本发明方法的通用性,本发明也验证了在长尾分类上的结果,使用imagenet-lt数据集进行试验。如图3所示,在该数据集上,本发明方法有51.6%的总体准确率,比基线模型高7.2%。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1