一种基于多任务多视图增量学习的用户行为识别方法
1.本发明属于智能设备用户行为预测技术领域,具体涉及一种基于多任务多视图增量学习的用户行为识别方法。
背景技术:
2.近年来,通过智能感知实现的用户行为识别在学术和工业领域引起了越来越多的研究者的兴趣。各种传感器(如加速度计、陀螺仪等)嵌入强大的智能手机或智能可穿戴设备被用来识别用户行为,广泛应用于医疗服务、商业、安全等领域。用户行为识别旨在检测现实世界中的用户行为,这可以让智能系统帮助个人在医疗保健、智能城市等领域提高的生活质量。在之前的研究中,对特定数据集上的用户行为识别已经取得了较为良好的效果。
3.但是,现有的用户行为识别方法存在以下缺陷:(1)传统的方法在所有时间间隔内从各种传感器中收集数据,建立一个通用的离线模型来识别活动,这消耗了大量的空间来存储大量的训练数据。(2)灾难性遗忘在增量学习中很常见。由于传感器产生的测量速度非常快,当模型在变化阶段接受新活动训练时,模型可能会忘记之前学到的知识。(3)不同的人群和不同类型的传感器通常为相同的活动呈现不同的形式,即任务异构性和视图异构性。传统的增量式学习方法往往忽略了这些问题。
技术实现要素:
4.基于上述问题,本技术提出了一种基于多任务多视图增量学习的用户行为识别方法mtmvis来解决用户行为识别中的上述三大问题。mtmvis首先利用了增量学习的在线方法从而节省了时间和空间;通过将不同人群形式化为不同任务,并将位于身体不同部位的传感器形式化为不同视图,利用多任务多视图学习的思想解决任务异构性和视图异构性;可塑权重巩固(ewc)可以减轻增量学习中灾难性遗忘问题。其技术方案为,
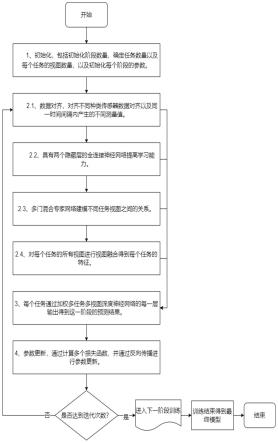
5.一种基于多任务多视图增量学习的用户行为识别方法,包括以下步骤,
6.s1.采集活动姿态数据,将数据划分多个部分即初始化活动阶段数量,并根据参与训练的人员确定任务数量以及每个任务的视图数量,初始化每个阶段的参数;
7.s2.利用多任务多视图深度神经网络为传感器数据提取特征;
8.s3.参数更新,通过计算多个损失函数,并通过反向传播进行参数更新;
9.s4.对s2至s4开展多轮迭代,直到达到迭代轮数范围要求,然后进行下一阶段的训练过程,直至所有的阶段训练结束,得到最终阶段的预测结果。
10.进一步优选的,步骤s1中,活动姿态的种类为ζ,每种姿态都出现的次数γ,且出现的顺序是随机的,活动阶段数量为m=ζ*γ;每个活动阶段出现用户单个活动姿态且每个阶段出现的活动姿态是随机可重复的,并根据参与活动的人员数量以及佩戴传感器的身体部位确定任务数量以及每个任务的视图数量,并且每个阶段的参数具体包括模型参数θm,迭代次数rm,学习率ρm,m∈{1,2,
…
,m}表示第m个活动阶段。
11.进一步优选的,步骤s2中,将传感器采集的数据输出数据对齐层进行数据对齐,步
骤如下,
12.在每个t秒的时间间隔内,身体每个部位共有s个传感器,每个传感器可以生成n条数据,设置传感器的初始数据向量其中n∈{1,2,
…
,n},s∈{1,2,
…
,s},k表示是第k个任务,v表示第v个视图,其中k∈{1,2,
…
k},v∈{1,2,
…
,v},表示第k个用户第v个部位上的第s个传感器在t秒内的产生的第n条数据;数据对齐层包括第一注意层和第二注意层,第一注意层对齐位于身体同一部位的不同传感器的数据,根据位于身体同一部位的不同传感器的重要程度进行加权平均并得到一个固定长度的特征向量第二注意层加权在同一时间间隔内产生的不同测量值,以实现在同一时间间隔内产生的不同数据的对齐,并得到一个固定长度的特征向量
13.进一步优选的,步骤s2中,将数据对齐层输出的特征向量输入全连接层,得到固定长度的特征向量
14.进一步优选的,步骤s2中,将特征向量输入任务视图共享层,并执行mmoe算法,具体过程如下:
15.mmoe网络包含e个专家网络和k*v门控网络,首先将特征向量作为每个专家网络的输入,得到每个专家网络的输出其中e表示第e个专家网络,门控网络通过结合多个专家的输出,每个任务视图都可以获得一个特定的特征向量
16.进一步优选的,步骤s2中,将特征表示输入视图融合层,通过第三注意力层来融合每个任务的视图特征,得到每个任务的特征向量
17.进一步优选的,步骤s3中,分别将数据对齐层输出的特征向量全连接层输出的特征向量任务视图共享层输出的特征向量经过不同的注意力层得到特征向量特征向量和特征向量将特征向量特征向量将特征向量和特征向量输入自适应输出层进行加权,每个任务得到一个特定的特征向量fk。
18.进一步优选的,步骤s4中,在视图融合阶段通过正则项计算多视图损失l
mv
;预测结果fk与真实值yk计算交叉熵损失l
cl
;并通过同方差不确定性计算多任务损失l
mt
,另外通过ewc算法参数巩固来克服灾难性遗忘问题得到增量损失最终损失函数
[0019][0020]
利用lf计算梯度并对模型进行更新,即
[0021]
其中rm∈(1,2,...rm)。
[0022]
有益效果
[0023]
本发明使用一种基于多任务多视图增量学习的用户行为识别框架来解决真实场景下的用户行为识别问题。现有的方法通常集中式批处理的方式训练数据,这种方式要求一个非常大的存储空间来保存所有的用户行为数据。如果用户单独训练,那么数据量有限是一个极其严峻的问题。通过引入多任务框架,多个用户可以彼此学习,从而学习到一个泛化模型。另外由于各个人的不同身体部位对相同的活动具有异质性,这种多视图问题也是我们研究的重点。本发明在增量学习的框架下利用了多任务多视图学习方法,提出了更先进用户行为预测方法。
[0024]
mtmvis(mt multi-task多任务、mv multi-view多视图、i incremental增量、s streaming data流数据)来解决用户行为识别中的存储空间有限、用户间异构性以及视图异构性三大问题。mtmvis首先利用了增量学习的在线方法从而节省了时间和空间;通过将不同人群形式化为不同任务,并将位于身体不同部位的传感器形式化为不同视图,利用多任务多视图学习的思想解决任务异构性和视图异构性;自适应可塑权重巩固(ewc)可以减轻增量学习中灾难性遗忘问题。
附图说明
[0025]
图1为本发明框架的用户位置预测流程示意图。
[0026]
图2本发明所提出的框架示意图。
[0027]
图3为本发明框架的多任务多视图深度神经网络示意图。
[0028]
图4为本发明框架的仿真结果示意图。
具体实施方式
[0029]
以下将结合附图1-4详细说明本技术。
[0030]
一种基于多任务多视图增量学习的用户行为识别方法,具体步骤如下,
[0031]
s1:初始化。在该步骤中,具体包括:
[0032]
s11.采集活动姿态数据,将数据划分多个部分即初始化活动阶段数量由于活动是顺序执行的,其中具体活动包括站立、躺、走、跑、上楼、下楼、跳,一共七个活动姿态,每种活动姿态都出现三次,且出现的顺序是随机的,所以一共有m=21个活动阶段,对于每个活动阶段所从事的任务都是对这七个具体活动姿态进行预测(实验设置:在训练过程中,对于一开始的几个活动阶段,由于不具备所有活动姿态的标签,默认还未训练过的活动的预测结果为100%。例如,在第一个阶段活动的输入为站立的数据,利用站立的数据训练预测,测试集包含七个活动姿态,其他六个活动姿态的正确率为100%;在第二个阶段的输入为跑的数据,我们利用跑的数据训练预测,其他五个活动姿态的正确率为100%。);用m∈{1,2,
…
,m}表示第m个活动阶段,且每个活动阶段包含tm个时间间隔t,且每个时间间隔设置为2.5秒。
[0033]
s12.确定任务数量以及每个任务的视图数量。为不失一般性,选择4名男性和4名女性进行实验。每项活动同时记录胸部、前臂、头部、小腿、大腿、上臂和腰的加速度。由于7个不同的身体部位被认为是7个视图,因此,总共定义了8个具有7个视图的任务。
[0034]
s13.初始化每个阶段的参数。每个阶段的参数具体包括模型参数θm,迭代次数rm,学习率ρm。
[0035]
s2:对于每一个阶段,如图3所示,利用多任务多视图深度神经网络为传感器数据
提取特征。在该步骤中,具体包括:
[0036]
s21.数据对齐:将传感器采集的数据输出数据对齐层进行数据对齐,首先在每个t秒的时间间隔内,身体每个部位共有s个传感器,每个传感器可以生成n条数据,设置传感器的初始数据向量其中n∈{1,2,
…
,n},s∈{1,2,
…
,s},k表示是第k个任务,v表示第v个视图,其中k∈{1,2,
…
k},v∈{1,2,
…
,v},表示第k个用户第v个部位上的第s个传感器在t秒内的产生的第n条数据。
[0037]
数据对齐层包括第一注意层和第二注意层,在第一注意层,对齐位于身体同一部位的不同传感器的数据,根据位于身体同一部位的不同传感器的重要程度进行加权平均并得到一个固定长度的特征向量在第二注意层,我们加权在同一时间间隔内产生的不同测量值,以实现在同一时间间隔内产生的不同数据的对齐,并得到一个固定长度的特征向量
[0038]
s22.为了提高模型的学习能力,使用了一个具有两个隐藏层的全连接神经网络,使用步骤s21中得到的的特征向量作为输入,得到固定长度的特征向量
[0039]
s23.为建模不同任务视图之间的关系,在任务视图共享层中,使用步骤s22中得到的特征向量作为输入,并执行mmoe算法,具体过程如下:mmoe网络包含e个专家网络和k*v门控网络即每个任务视图都有属于自己特有的门控网络),其中每个任务视图的门控网络通过不同的最终输出权值实现了对专家的选择性使用。首先使用步骤s22中得到的特征向量作为每个专家网络的输入,得到每个专家网络的输出其中e表示第e个专家网络。门控网络通过结合多个专家的输出,每个任务视图都可以获得一个定制的特征向量
[0040]
s24.获得每个任务视图的特征表示,为了得到属于每个任务的特有的特征表示,需要对每个任务的所有视图进行视图融合。具体地,在视图融合层,使用步骤s23中得到的的特征向量作为输入,使用第三注意力层来融合每个任务的视图特征,得到每个任务的特征向量
[0041]
s3:每个任务通过加权多任务多视图深度神经网络的每一层输出得到这一阶段的预测结果。在该步骤中,如图2所示,具体包括:
[0042]
s31.将数据对齐层输出的特征向量全连接层输出的特征向量任务视图共享层输出的特征向量分别经过不同的注意力层(第五注意力层、第六注意力层、第七注意力层)得到特征向量特征向量和特征向量
[0043]
s32.对于每个任务,将特征向量特征向量特征向量和特征向量输入自适应输出层(第四注意力层)进行加权,每个任务得到一个特定的特征向量fk。
[0044]
s4:参数更新。在该步骤中,具体包括:
[0045]
s41.在视图融合阶段通过正则项计算多视图损失l
mv
;预测结果fk与真实值yk计算交叉熵损失l
cl
;并通过同方差不确定性计算多任务损失l
mt
,即其中σk为作为第k个任务的噪声的高斯分布的标准差,λ
mt
是一个超参数;另外通过ewc算法参数巩固来克服灾难性遗忘问题得到增量损失,即其中为第k个任务第m阶段训练后计算的对角费雪矩阵的第p个对角值,表示第m+1个阶段的参数,得到总损失
[0046]
s42.利用lf计算梯度并对模型进行更新,即其中rm∈(1,2,...rm)。
[0047]
对s2-s4开展多轮迭代,直到达到迭代轮数范围要求,然后进行下一阶段的训练过程,直至所有的阶段训练结束,得到最终阶段的预测结果。
[0048]
通过图4证明,在四个衡量指标下,我们的技术都取得优异的效果。随着阶段的不断进行,由于灾难性遗忘问题,所有指标都下降,但我们的机制有克服灾难性遗忘的能力,所以下降速度比较慢,另外由于我们每种活动都进行了3次,多次训练可以巩固相关活动的参数,提高模型效果。auc指roc曲线下方的面积大小(roc指接收者操作特征曲线)。
[0049]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1